](https://deep-paper.org/en/paper/2511.03506/images/cover.png)
我们都曾有过这样的经历。你正与一个AI助手进行一场漫长且细致的对话——分享你的偏好、生活事件和项目进展。你感觉它终于懂你了。然后,在之后的一次聊天中,它自信地提到一个你从未告诉过它的“事实”,或忘记了你们深入讨论过的内容。这不仅仅是一个小故障——这被称为记忆幻觉 , 是构建可信赖、长期AI伙伴的主要障碍。
为了让AI不止停留在一次性的问答工具,而是成为真正的长期伙伴,它们需要可靠的记忆系统。这些系统让AI能够记住你的偏好、追踪你的目标,并在成千上万次互动中维持一致的理解。但当记忆出现缺陷时,AI可能会编造事实、记错细节或者未能更新知识——从而导致令人困惑甚至有害的结果。
直到最近,研究人员大多将AI记忆测试视作一次期末考试: 提出问题,检查答案是否正确。这种“端到端”方法可以揭示错误发生,但无法说明原因或位置。到底是AI未能记录信息,还是错误地应用了更新?或是它检索到了正确记忆,却仍给出了不准确的回答?
一项新研究——HaluMem: 评估智能体记忆系统中的幻觉——提出了一种突破性的方法来回答这些疑问。研究者们发布了HaluMem , 这是首个如“诊断测试”般专门面向AI记忆系统的基准。它能准确定位幻觉产生的操作阶段,让研究人员得以“深入内部”,探索AI记忆的提取、更新与问答运作机制。
理解AI如何记忆
在深入了解HaluMem之前,先了解AI系统内部的记忆工作原理会很有帮助。
大型语言模型 (LLM) 拥有一种内置的、参数化的记忆: 它们在训练时所学习的知识被编码在神经网络的权重中。这种内部记忆帮助模型回忆一般性事实,但不易被访问、更新或删除。它是静态的——一旦被学习,修改起来就十分困难。
为了解决这一问题,开发者们创建了外部记忆系统 。 一个常见的例子是检索增强生成 (RAG) : AI在生成答案之前,会从外部数据库中检索相关文档。这种方法增强了事实的依据,也允许在无需重新训练整个模型的情况下进行更新。
如今,更先进的系统如 MemO、Supermemory 和 Zep 已经出现,为AI智能体提供持久化、个性化的记忆层——这些工具能记录用户的细节、事件和不断变化的偏好。

表1: 各种现代记忆系统都旨在提供可管理的长期记忆,尽管它们在设计和能力上有所不同。
虽然这些系统是迈向个性化、终身AI的重要一步,但它们仍然容易出现幻觉。评估这类幻觉一直是一项挑战。现有测试主要依赖端到端的答案评估——这种方法在判断结果方面有效,但在定位内部错误方面表现不佳。
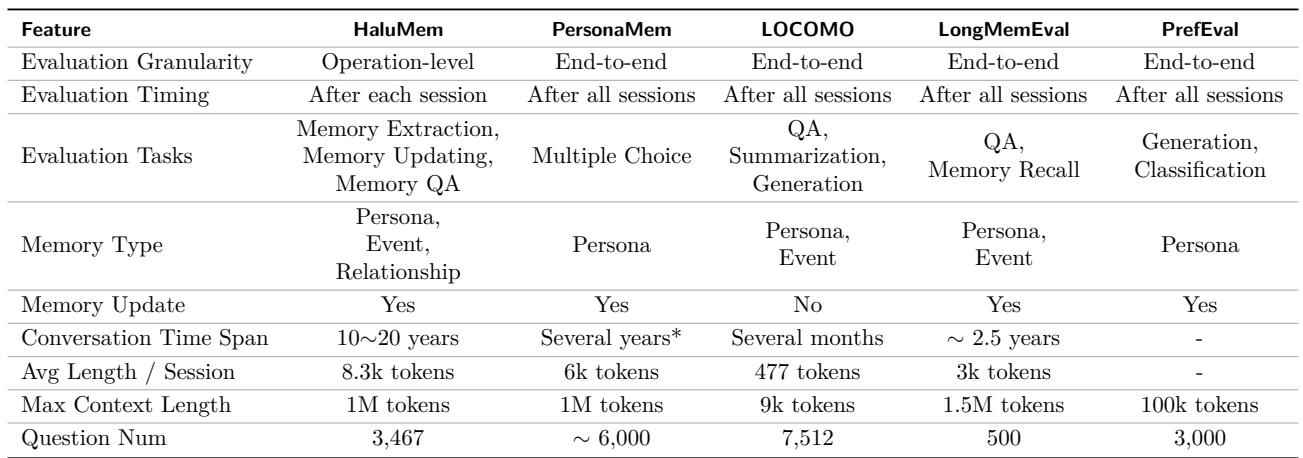
表2: HaluMem通过从端到端评估转向细粒度的操作级分析,从而在以往的基准测试中脱颖而出。
HaluMem改变了这一范式,使研究人员能够剖析记忆处理的每个阶段,并识别错误发生的位置。
打开黑匣子: 从期末考试到根因分析
一个AI记忆系统在对话过程中会执行几个关键操作:
- 记忆提取 (E): 从对话中提取新的、关键的事实——称为记忆点。
- 记忆更新 (U): 根据新信息修改或删除已有记忆。
- 记忆检索 (R): 在回答问题时查找相关记忆。
- 记忆问答 (Q): 利用检索到的信息生成最终的答案。
传统的评估将这整条链视作一个黑匣子:
\[ \hat{M} = U(E(D)), \quad \hat{R}_j = R(\hat{M}, q_j), \quad \hat{y}_j = A(\hat{R}_j, q_j) \]这里,\(D\) 是对话,\(q_j\) 是问题,而 \(A\) 是生成答案的AI模型。其正确性通过以下计算:
\[ \operatorname{Acc}_{e2e} = \frac{1}{J}\sum_{j=1}^{J} \mathbb{I}[\hat{y}_j = y_j^*] \]如果一个答案错误,这只说明某个环节出了问题——但无法判断错误来自提取、更新还是推理。

图2: HaluMem的评估流程 (左) 检查记忆操作的各个阶段,而传统方法只关注最终结果。
HaluMem引入了阶段特定的黄金标准——即针对每一环节的真实数据集。研究人员现在可以评估是否正确提取记忆 \((E)\)、是否适当更新 \((U)\)、以及是否成功用于问答 \((Q)\):
\[ \hat{M}^{\text{ext}} = E(D), \quad \hat{G}^{\text{upd}} = U(\hat{M}^{\text{ext}}, D), \quad \hat{y}_j = A(R(\hat{M}, q_j), q_j) \]这种透明度最终使得能够在记忆流程中定位幻觉成为可能。
构建HaluMem: 为AI“生活”和学习打造世界
构建这样一个可用于精细分析的数据集并非易事。你需要包含多轮对话的数据,这些对话中有不断变化的事实、矛盾的更新以及复杂的推理。HaluMem团队设计了一个六阶段流水线来生成这些数据。
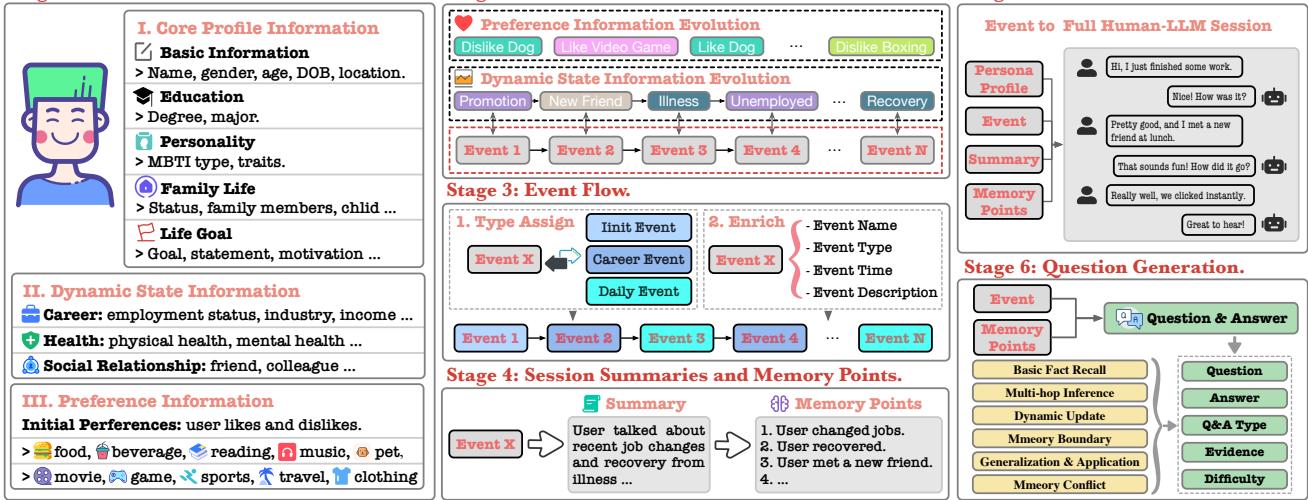
图3: HaluMem的构建流程产生了逼真的、复杂的用户–AI互动,并带有精确标注的记忆点。
- 阶段1 – 人物构建: 创建合成人物,包括核心档案 (如背景、教育) 、动态状态 (职业或健康) 以及不断变化的偏好。
- 阶段2 – 生活骨架: 构建包含主要事件和更新的时间线,形成用户的“传记”,为后续会话提供结构。
- 阶段3 – 事件流: 将骨架转化为叙事事件链——例如晋升、疾病、友情变化或兴趣爱好。
- 阶段4 – 会话摘要与记忆点: 每个事件生成一个真实的对话摘要,并定义出预期被提取或更新的黄金标准记忆。
- 阶段5 – 会话生成: 生成完整对话,并插入干扰记忆——虚假但看似合理的事实,用于测试抗幻觉能力。
- 阶段6 – 问题生成: 超过3400个问题,用于测试事实回忆、推理和冲突解决能力。
最终得到了两个基准:
- HaluMem‑Medium — 真实的中等长度会话 (约16万词元/用户) 。
- HaluMem‑Long — 超长上下文 (超过100万词元/用户) ,模拟多年对话。
人工标注验证内容质量,达到了95.7%的正确率——这是合成对话数据中极高的标准。
HaluMem评估框架: 测量系统中的每个齿轮
数据集准备完毕后,研究者们构建了一个评估框架,用于考察幻觉在三个关键阶段的形成。
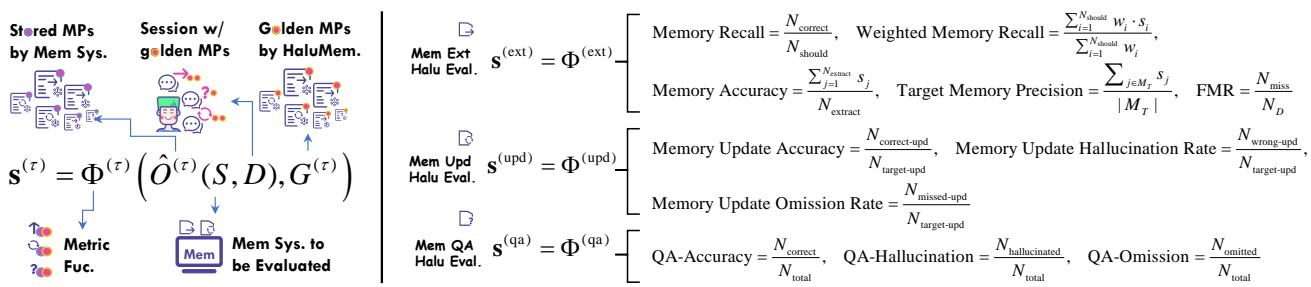
图4: HaluMem的评估过程展示了黄金记忆点如何支持在记忆提取、更新和问答环节中的细粒度测量。
1. 记忆提取评估
目标: 检查系统是否正确捕获对话中的新事实。
记忆完整性 (抗遗忘)
\[ \text{Memory Recall} = \frac{N_{\text{correct}}}{N_{\text{should}}}, \quad \text{Weighted Recall} = \frac{\sum w_i \cdot s_i}{\sum w_i} \]衡量遗漏情况及捕获记忆的重要性。
记忆准确性 (抗幻觉)
\[ \text{Memory Accuracy} = \frac{\sum s_j}{N_{\text{extract}}}, \quad \text{Target Precision} = \frac{\sum_{j \in M_T}s_j}{|M_T|} \]评估存储信息的事实正确性。
伪记忆抵抗力 (FMR)
\[ FMR = \frac{N_{\text{miss}}}{N_D} \]测试系统忽略误导性“干扰”内容的能力。
2. 记忆更新评估
目标: 评估系统是否在出现新数据时正确修改旧记忆。
\[ \begin{array}{r} \text{Update Accuracy} = \frac{N_{\text{correct-upd}}}{N_{\text{target-upd}}}, \\ \text{Hallucination Rate} = \frac{N_{\text{wrong-upd}}}{N_{\text{target-upd}}}, \\ \text{Omission Rate} = \frac{N_{\text{missed-upd}}}{N_{\text{target-upd}}} \end{array} \]高遗漏率表示系统存在“隐形更新”——即使在应当记录的情况下也未执行更新。
3. 记忆问答评估
目标: 测量记忆操作之后的端到端可靠性。
\[ \begin{array}{r} \text{QA Accuracy} = \frac{N_{\text{correct}}}{N_{\text{total}}}, \\ \text{QA Hallucination} = \frac{N_{\text{hallucinated}}}{N_{\text{total}}}, \\ \text{QA Omission} = \frac{N_{\text{omitted}}}{N_{\text{total}}} \end{array} \]较低的准确率或较高的幻觉/遗漏率意味着上游记忆管理存在问题。
结论: 当今AI记忆仍漏洞频出
通过该方法,研究者在两个HaluMem基准上评测了主流记忆系统——Mem0、Memobase、Supermemory 和 Zep 。
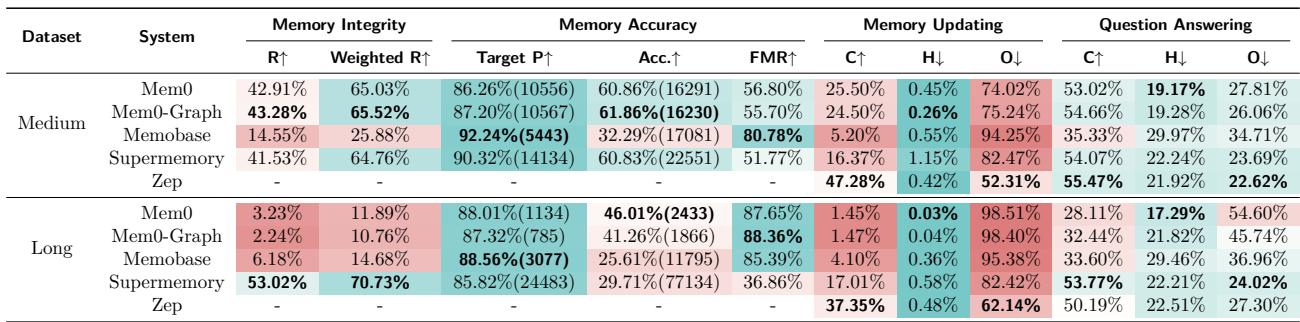
表3: HaluMem总体结果。绿色代表性能更强;红色警示表现较弱——尤其在长上下文场景下。
关键洞察
长对话破坏记忆。 几乎所有系统在HaluMem‑Long上的性能都显著下降。随着上下文增长,不相关细节淹没了记忆,真实信息逐渐消失。
提取是薄弱环节。 没有系统的召回率超过60%,意味着近半关键信息未被存储。即便成功提取,事实准确性也有限——系统常保存错误或幻觉条目。
更新被提取错误放大。 更新准确率总体低于50%。若最初事实遗漏,系统便无法在之后正确更新。早期错误会层层传递。
记忆不良导致回答不佳。 问答准确性与提取和更新阶段质量高度相关。早期失败的系统在后期产生幻觉或不完整回答——典型的“垃圾进,垃圾出”效应。
系统最容易忘记的内容: 角色 vs. 事件 vs. 关系
HaluMem的细粒度数据可以按记忆类型进行分类分析。
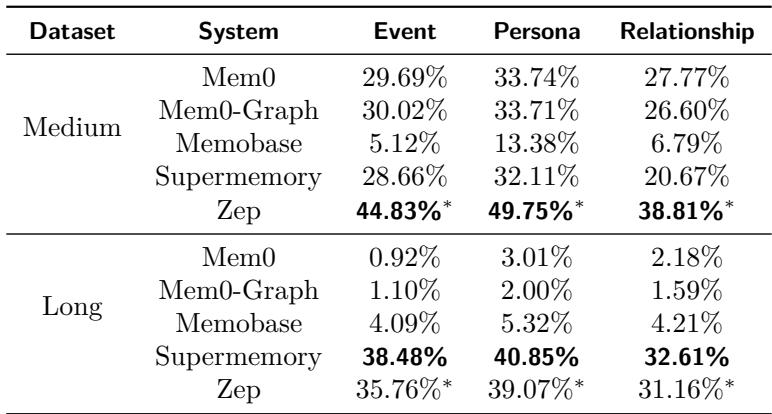
表4: 系统通常能更好地保留静态的角色数据,而对动态事件或关系信息的记忆表现较差。
静态的“角色”记忆——如用户的兴趣爱好——更容易被AI维持,而动态变化的事件或社交关系事实常引发混乱。持续追踪随时间变化的记忆仍是未解决的问题。
当问题需要真正思考时
接着,团队分析了在不同问题类型上的表现。
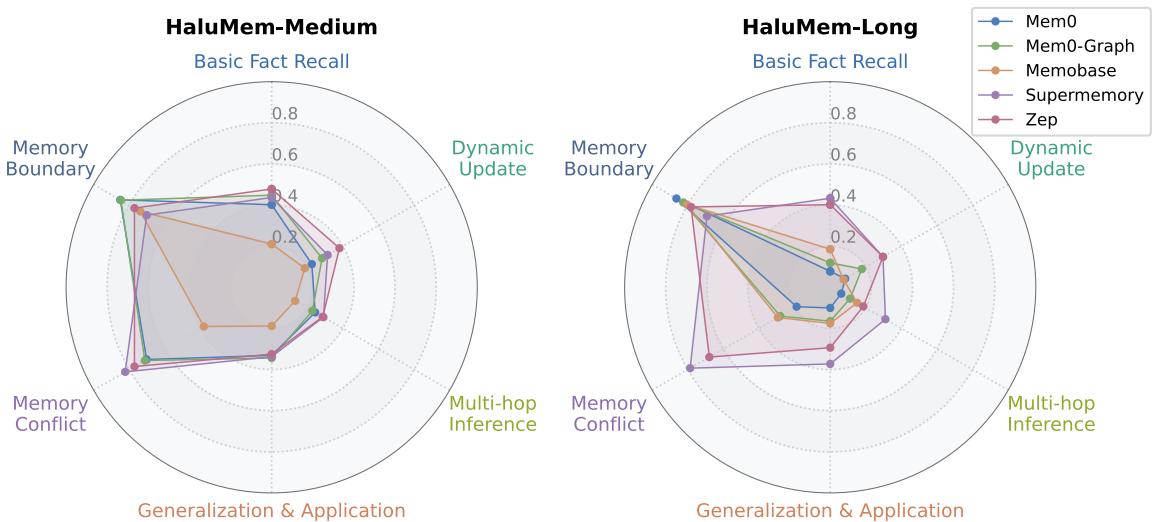
图5: 系统对直接事实回忆任务的处理优于高推理任务,如多跳推理和动态更新。
所有系统在复杂推理类问题上都表现不佳——尤其是多跳推理、动态更新和泛化任务。尽管多数系统能识别自身记忆的边界 (知道自己“不知道”) ,但它们依旧难以跨上下文连接或应用已有记忆。
效率: 写入比读取更难
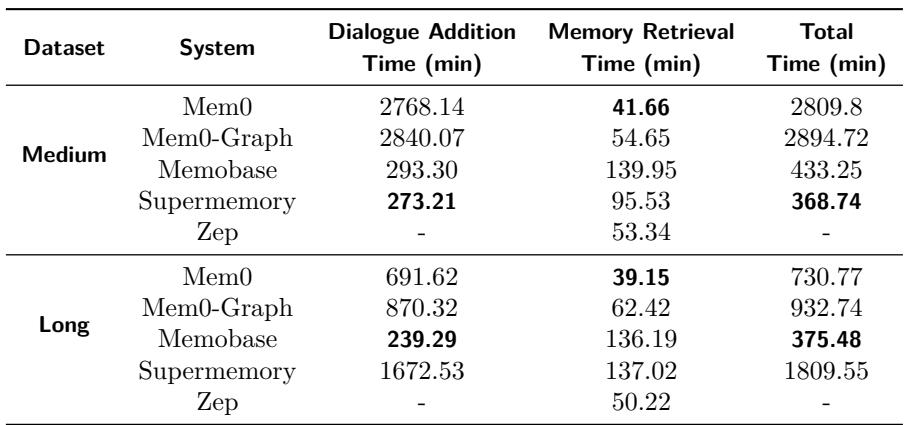
表5: 写入 (对话摄取和记忆提取) 远比读取 (检索) 慢,凸显关键优化目标。
在实验中,插入新记忆所用时间远长于检索现有记忆,表明主要的效率瓶颈在提取和更新阶段。改进这些步骤可显著提升具备记忆能力的AI响应速度。
结论: HaluMem开启透明记忆评估新时代
当前多数基准将AI记忆系统视作黑匣子,仅以最终答案为依据进行评判。 HaluMem首次提供操作级视角——揭示幻觉如何在记忆提取与更新过程中产生,而不仅是是否出现在最终回答中。
结果令人警醒: 今天的长期记忆系统仍不稳定、易出错,并容易被长上下文干扰。它们在早期阶段会遗漏关键信息,无法刷新过时内容,并积累幻觉,这些幻觉在后续互动中不断放大。
但HaluMem提供了前进方向。通过在每个阶段进行诊断,研究者可据此设计出更具可解释性、稳定且可靠的记忆架构——不仅能存储信息,还能在时间推移中保持真实性、一致性和上下文。
简而言之,AI记忆的未来不仅取决于训练更大的模型或更多数据,而是理解记忆本身的工作机制。像HaluMem这样的工具正在引领方向,让我们的数字伙伴真正做到正确、忠实地“记得”。