](https://deep-paper.org/en/paper/2511.06221/images/cover.png)
在人工智能领域,*“越大越好”*长期以来一直是主流哲学。诸如 DeepSeek R1 (671B 参数) 和 Kimi K2 (超过一万亿参数) 这样的巨头定义了最前沿的推理能力,并推动了一场向规模化发展的军备竞赛。普遍的信念是: 复杂的推理是巨型模型的专属领域,而小模型根本无法竞争。
但如果这种假设是错误的呢?
如果一个小型而灵活的模型能够以其庞大对手同等的逻辑能力进行思考呢?
来自新浪微博 AI 的一份新技术报告挑战了这种传统认知,推出了 VibeThinker-1.5B——一个仅用 15 亿参数 构建的、结构异常紧凑的模型,其后训练成本低于 8,000 美元 。 尽管体量小巧,它在高级数学和编程基准测试中却超越了比它大数百倍的模型,甚至可与 OpenAI 的 o3-mini 和 Anthropic 的 Claude Opus 等商业巨头相媲美。
这不是一个关于暴力扩展的故事,而是一个关于智能、高效训练的故事。 其秘诀在于一种名为 从谱到信号原则 (Spectrum-to-Signal Principle, SSP) 的新方法论——一个从第一性原理出发,重新构思后训练过程的全新范式。
在本文中,我们将解析 VibeThinker-1.5B 背后的核心理念,解释 SSP 的工作原理,并探讨为何这一突破可能重新定义推理模型的未来。
背景: 推理模型的构建基础
在探究 SSP 的创新之前,我们需要理解模型后训练的两个主要支柱: 监督式微调 (Supervised Fine-Tuning, SFT) 和 强化学习 (Reinforcement Learning, RL) 。 这两个阶段将通用模型转化为具有强推理能力的模型。
监督式微调 (SFT)
监督式微调通过使用带标签的示例 (如数学题及其分步解答) 让预训练模型适应特定任务。其目标是最小化交叉熵损失,从而有效地教会模型生成高概率的正确回答。
\[ \mathcal{L}_{\mathrm{SFT}}(\theta) = \mathbb{E}_{(x,y)\sim \mathcal{D}}\left[ -\log \pi_{\theta}(y|x) \right] \]其中,\( \pi_{\theta}(y|x) \) 表示模型在给定输入 \( x \) 时输出正确答案 \( y \) 的概率。
强化学习与 GRPO
当 SFT 阶段建立了基本能力后,强化学习 (RL) 通过试错与奖励机制进一步优化模型。模型生成候选输出,通过奖励函数为它们评分,并更新参数以偏好高奖励结果。
VibeThinker 使用了一种名为 组相对策略优化 (Group Relative Policy Optimization, GRPO) 的变体。与传统的“评论家模型”不同,GRPO 在模型自身分布中抽样出一组响应进行比较。每个响应获得一个相对于组均值奖励的优势值:
\[ A_{i,t}(q) = \frac{r_i - \mu_G}{\sigma_G} \]这样可减少方差并稳定训练,使得模型在无需外部评论家网络的情况下也能稳步提升。
衡量进展: Pass@K 与多样性
复杂推理任务常常存在多种可能的解法。为评估模型的探索能力,研究人员采用 Pass@K——即在生成的 \( K \) 个答案中至少有一个正确的概率。
\[ \operatorname{Pass}@K = \mathbb{E}_{x \sim \mathcal{D}, \{y_i\}_{i=1}^k \sim \pi_{\theta}(\cdot | x)}\!\left[\max\{R(x,y_1), \ldots, R(x,y_k)\}\right] \]较高的 Pass@K 表明模型探索了更多的推理路径——这是多样性的直接体现。 一个能产生多样化假设的模型学习得更快,也更容易发现优质解法。
核心理念: 从谱到信号原则 (SSP)
传统流程往往在 SFT 阶段优化准确率 (Pass@1),再通过 RL 进一步提升这一指标。其结果通常是短视优化——模型记住了狭隘的解题模式,难以应对新颖的推理任务。
从谱到信号原则彻底重构了这种关系。
谱阶段 (SFT): SFT 阶段不再局限于单一正确解,而是培养一个包含多样推理路径的丰富谱。训练目标从 Pass@1 转向明确地最大化 Pass@K,为创造性和多元问题求解方式奠定基础。
信号阶段 (RL): 强化学习深入这一谱,识别出最有效的模式——即信号——并通过奖励将其放大。RL 算法学习哪些推理路径能够成功并提高它们的生成概率。
最终结果是: RL 可在更丰盈的候选解空间中运行,使模型性能远超传统流程。
VibeThinker-1.5B 训练管线
这一理念被封装在一个精密的双阶段训练框架中,如下图所示。
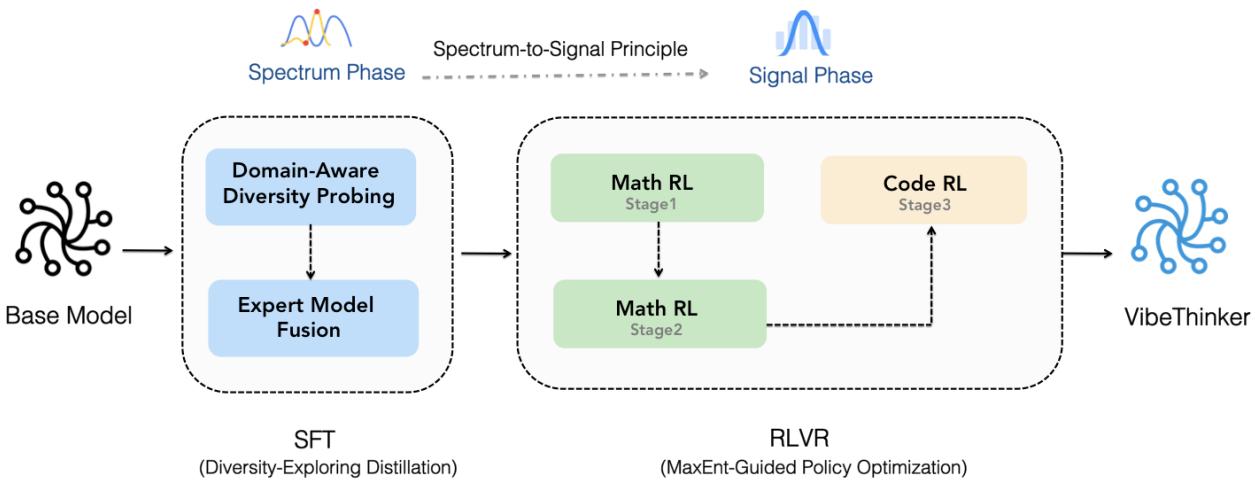
图 3. 从谱到信号的训练管线: 在 SFT 阶段构建多样化的解空间谱,再在 RL 阶段聚焦放大关键信号。
阶段一: 多样性探索蒸馏 —— 构建谱
此阶段的目标是训练一个具备丰富多样性的模型。
领域感知的多样性探索 数学分为多个子领域——代数、几何、微积分、统计学。团队在这些子领域上对基础模型进行微调,并保存中间检查点。每个检查点通过 Pass@K 进行评估,以确定最佳的多样性捕获能力:
\[ M_i^* = \arg\max_t P_i(t) \]最终得到多个“专家”模型,每个模型都专注于在特定领域中捕获多样化推理。
专家模型融合 这些专家模型通过参数平均进行合并,形成统一的 SFT 模型:
\[ \mathbf{M}_{\mathrm{Merge}}^{\mathrm{SFT}} = \sum_{i=1}^{N} w_i M_i^*, \quad w_i = \tfrac{1}{N} \]合并后的模型保留了各子领域中最丰富的多样性能力——一个为 RL 阶段准备好的宽广谱。
阶段二: 最大熵引导的策略优化 —— 放大信号
谱阶段构建完毕后,RL 使用 最大熵引导的策略优化 (MaxEnt-Guided Policy Optimization, MGPO) 进一步优化。这是一种有原则的方法,用于定位模型最能学习的问题。
在不确定性的边缘学习
最有价值的训练问题是那些模型正确率 \( p_c(q) \) 约为 50% 的问题——即模型最不确定的部分。太简单的问题没有学习意义,而太难的问题没有信号。MGPO 利用这一特征优先选取信息量最高的样本。
\[ p_c(q) = \frac{1}{G}\sum_{i=1}^{G}\mathbb{I}(r_i = 1) \]熵偏差正则化
为衡量与理想不确定性 (0.5) 的接近程度,研究者计算了最大熵偏差距离 :
\[ D_{\text{ME}}(p_c(q) \| p_0) = p_c(q)\log \frac{p_c(q)}{p_0} + (1-p_c(q))\log \frac{1-p_c(q)}{1-p_0}, \quad p_0=0.5 \]然后给每个问题分配权重:
\[ w_{\text{ME}}(p_c(q)) = \exp(-\lambda \cdot D_{\text{ME}}(p_c(q)\|p_0)) \]正确率接近 50% 的问题获得更高权重,而接近 0% 或 100% 的问题权重降低。调整后的优势值为:
\[ \mathcal{A}'_{i}(q) = w_{\mathrm{ME}}(p_{c}(q)) \cdot \mathcal{A}_{i}(q) \]这相当于建立了一个隐式课程 , 使模型自动聚焦于自身不确定性边缘地带——推理能力提升最快的区域。
结果: 小模型的巨大飞跃
前所未有的成本效益
训练 VibeThinker-1.5B 的总成本不足 8,000 美元——仅耗费 3,900 GPU 小时 (NVIDIA H800) 。相比之下,同类大型推理模型的训练成本通常超过 250,000 美元 。

图. VibeThinker 以极低成本实现顶尖推理表现,彰显了高效设计的成果。
这种节约并未牺牲能力。该模型在 AIME 2025 中取得 74.4 分,超过 DeepSeek R1 (671B) 的 70.0 分,而计算量仅为后者的不到 2%。
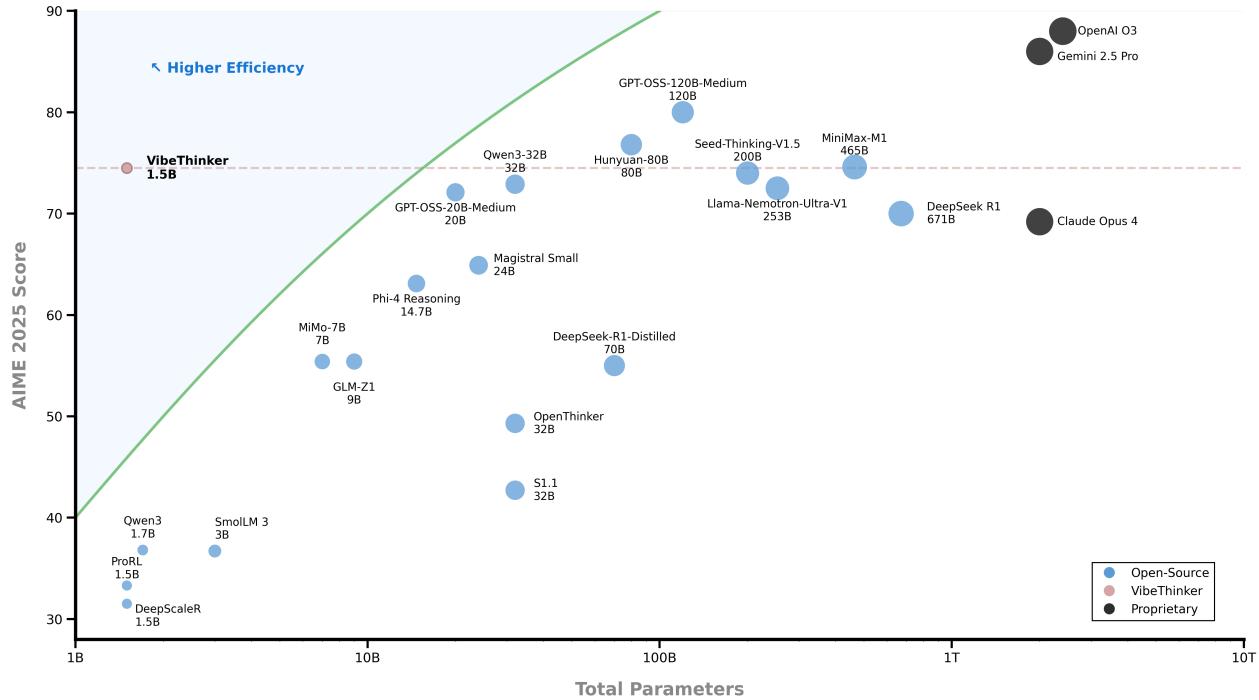
图 2. 性能与规模对比——VibeThinker 处于“高效率”区间,超越了比它大数百倍的模型。
称霸小模型领域
在参数量低于 30 亿的推理模型中,VibeThinker-1.5B 重新定义了“小模型”的上限。与其基础模型 Qwen2.5‑Math‑1.5B 相比,分数显著提升:
- AIME25: 4.3 → 74.4
- HMMT25: 0.6 → 50.4
- LiveCodeBench: 0.0 → 51.1
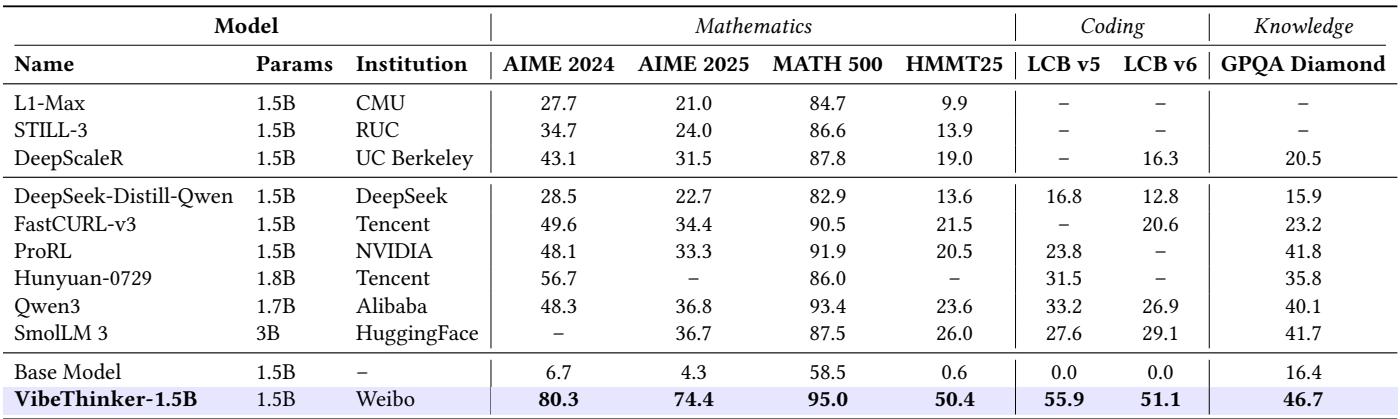
图. VibeThinker 超越所有低于 3B 参数的推理模型,证明精心的训练设计可媲美单纯的规模扩展。
挑战巨头
与行业领头模型相比,VibeThinker‑1.5B 的表现令人惊叹。
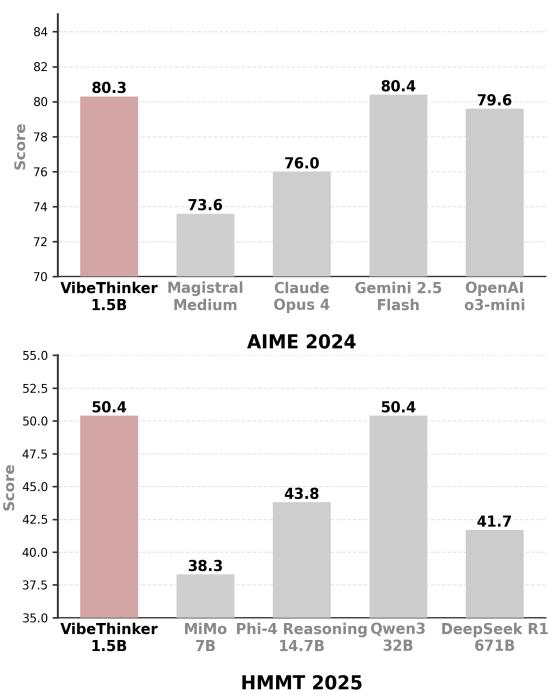
图 1. 在 AIME 和 LiveCodeBench 任务上的基准对比——VibeThinker 表现与大型推理模型相当甚至更优。
它在所有主要数学基准上均超越 DeepSeek R1,并与 Magistral Medium 和 Claude Opus 4 等商业推理模型相媲美甚至略优。
- AIME24: 80.3 vs. 79.8 (DeepSeek R1)
- AIME25: 74.4 vs. 70.0
- HMMT25: 50.4 vs. 41.7
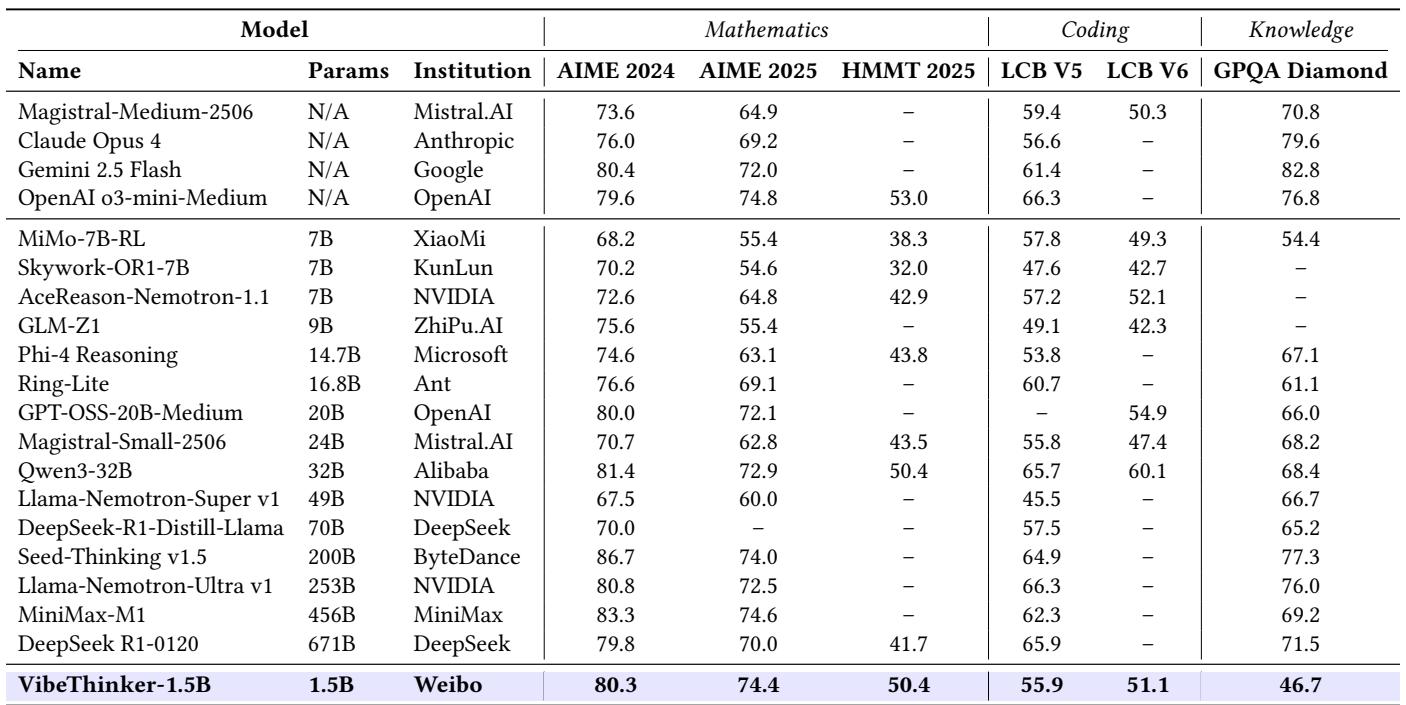
图. 尽管设计紧凑,VibeThinker 的推理表现依旧与远大于它的系统持平或更佳。
即便与非推理领域的巨头——如 Kimi K2 (1 万亿参数) 和 GPT‑4.1——相比,VibeThinker 仍在数学与编码基准上保持领先。
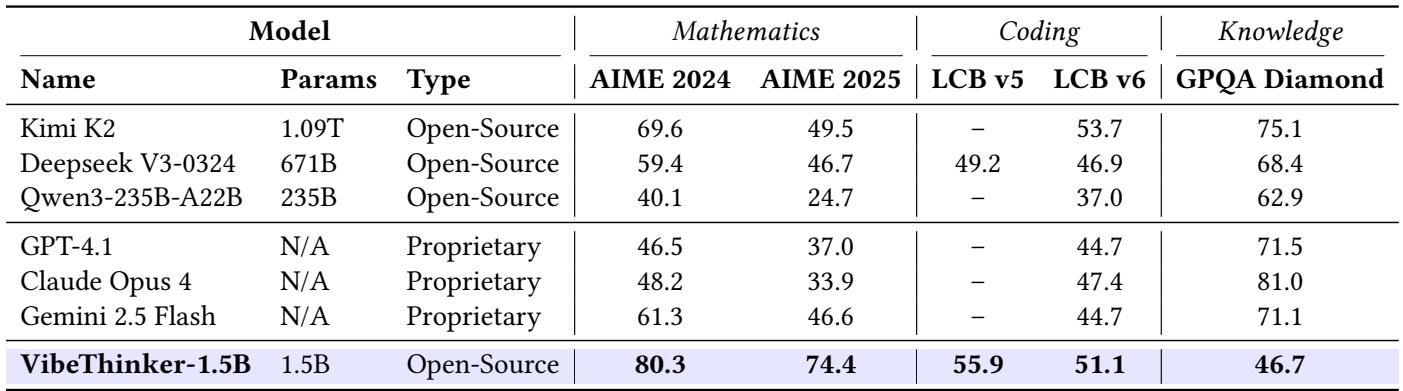
图. 在数学与代码任务上,VibeThinker 的表现超越数百倍规模的通用模型。
局限性与未来展望
VibeThinker 的强项在于结构化推理。在类似 GPQA 的百科类知识任务中,它比大型模型低约 20–40 分,反映出推理深度与广泛事实覆盖之间的固有关联。
然而,作者强调,算法创新可在很大程度上弥补规模劣势。未来的小模型或将集成检索机制与模块化记忆系统,以缩小知识覆盖的差距。
结论: 迈向新的路径
VibeThinker‑1.5B 不仅是技术上的成功,也是一次思想上的革新。 它证明了智能算法设计能唤醒原本被认为仅属于万亿参数模型的推理能力。
关键启示:
重新定义扩展定律: 推理能力不再与规模线性相关。像 SSP 这样的理念开辟了无需指数级计算即可提升能力的新途径。
AI 研究的民主化: 以不到 8 千美元实现顶尖性能,使高级推理研究首次对全球的高校、初创企业与独立实验室开放。
高效且普惠的 AI: 小模型大幅降低推理成本,让强大的推理任务能在本地或边缘设备上运行——如手机、汽车及嵌入式系统。
VibeThinker‑1.5B 预示着一个新时代的来临: 一个巧妙设计胜于纯粹规模的时代。 它提醒我们,在 AI 推理的世界里, 强大的逻辑并不取决于庞大的参数规模。