](https://deep-paper.org/en/paper/2511.06251/images/cover.png)
从静态模型到可运行的原型
想象一下,你是一名前端开发者,被交付了一份精美的设计稿。将这张图片转换成一个功能完备的网站——HTML 用于结构、CSS 用于样式、JavaScript 用于行为——常常是一项繁琐的重复性工作。现代的视觉语言模型 (VLM) 已经可以生成看起来正确的标记语言,但它们生成的大部分只是视觉上的“外壳”: 按钮看似可点击、菜单看似下拉、表单看似可填写——实际上却不会响应用户操作。
WebVIA,这一最新的研究成果,正面应对了这一差距。它并没有将 UI 到代码的任务视作一次性的图像到标记生成问题,而是引入了智能体机制: 一个探索智能体首先与界面交互以发现状态与转换,一个 UI2Code 模型利用这些多状态观察结果合成可执行的交互式代码,最后一个验证模块自动测试生成的界面。最终结果是——代码不仅看起来像设计稿,也能像设计那样运行。
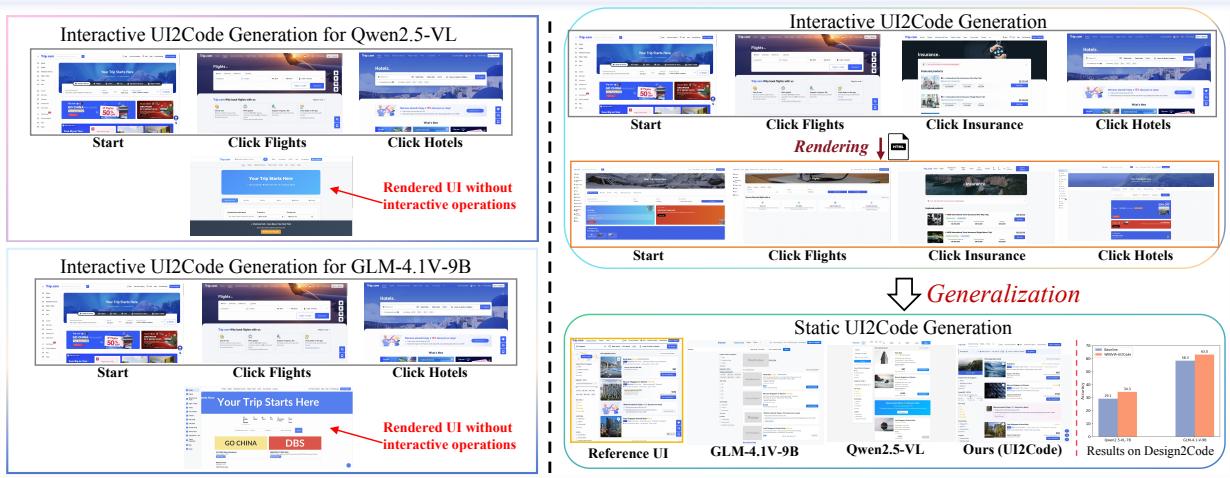
图 1: 激励性示例说明了静态与交互式代码生成的差距。静态生成器复现外观但不复现行为;WebVIA 致力于同时捕捉两者。
本文将深入解读 WebVIA 的理念、设计决策、数据集与实验结果。如果你从事 UI 构建或模型驱动的代码生成,这篇文章将向你展示为何“探索 + 多模态监督”是实现交互式、可验证 UI 合成的可行路径。
为什么静态输出无法满足需求
大多数 UI-to-code 系统被训练来重建单张截图。这种方法能实现良好的像素保真度和看似合理的标记语言,但无法学习事件绑定和多状态行为: 例如打开模态框、切换选项卡、显示或隐藏元素、或者在表单提交后更新内容。
与此不同的是,人类在构建 UI 时会与界面交互,观察结果,并推理其背后的状态机。WebVIA 模拟了这一过程: 让模型进行探索、捕捉状态图、学习状态与代码的映射关系,并最终验证生成的代码是否支持相同的状态转换。
WebVIA 流水线——探索、生成、验证
WebVIA 是一个端到端的框架,包含三个紧密耦合的组件:
- 探索智能体 (WebVIA-Agent) —— 与网页交互以发现 UI 状态和转换。
- UI2Code 模型 (WebVIA-UI2Code) —— 接收交互图 (多状态截图 + DOM 快照 + 操作) ,并生成可执行的 HTML/CSS/JavaScript (在作者的设置中为 React/Tailwind) 。
- 验证模块 —— 运行生成的页面,并重放交互轨迹以确认行为一致性。
其流程如下所示。
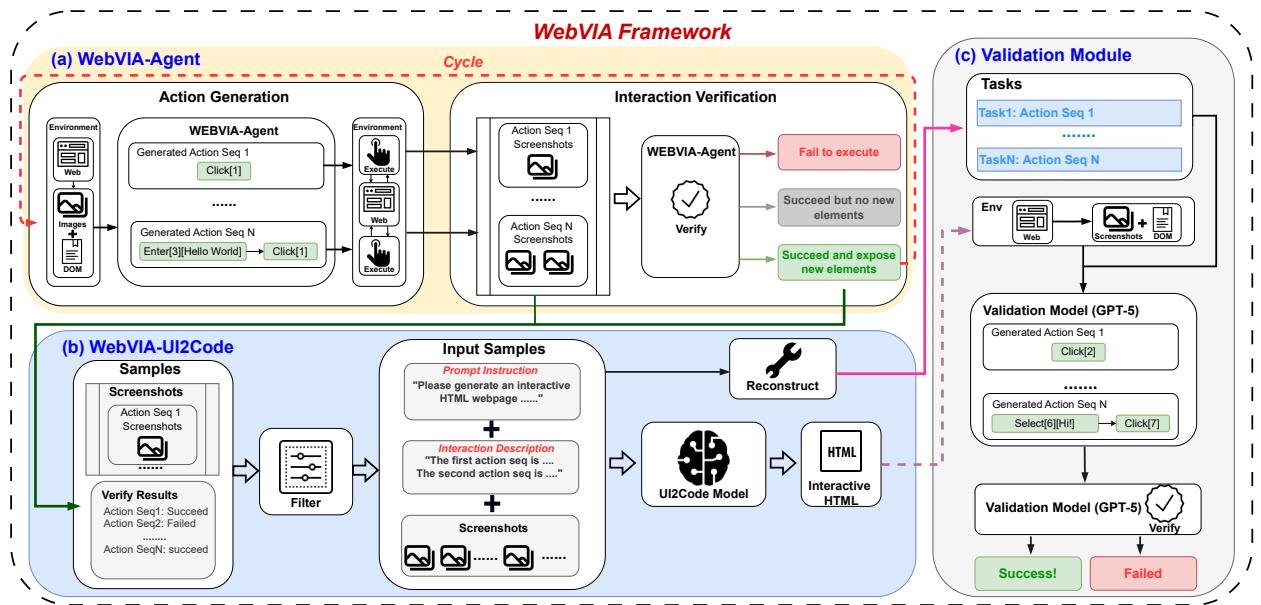
图 2: WebVIA 框架概览。该流水线从智能体探索到代码生成与任务验证形成闭环。
下面我们逐步解析每个部分。
第一部分 —— 探索智能体: 感知、行动、验证
WebVIA 的核心是一名训练有素的探索智能体。将网页视为一个环境 \(\mathcal{E}\)。在第 \(t\) 步,智能体观察到一个多模态状态 \(s_t = (I_t, D_t)\),其中 \(I_t\) 是截图,\(D_t\) 是 DOM 快照。智能体提出一个动作 \(a_t\) (点击、输入文本、选择) ,在浏览器执行该动作后,观察新的状态 \(s_{t+1}\),并验证此动作是否引发了有意义的状态转换。
关键设计要点:
- 动作生成依赖于当前状态及智能体的历史轨迹。动作可为原子操作 (单次点击) 或短流程 (输入文本后提交) 。
- 交互验证通过对比截图与 DOM,将结果分类为: 失败/无操作、成功但无新元素、成功并揭示新交互元素。
- 探索策略结合了广度优先的覆盖 (尝试多个可见元素) 与深度优先的跟进 (深入潜在的多步骤流程) 。
智能体逐步构建交互图 \(\mathcal{G} = (\mathcal{S}, \mathcal{T})\): 节点表示发现的状态,边表示经过验证的转换。该图成为代码生成器的丰富多模态输入。
验证的重要性: 如果没有验证,智能体可能陷入冗余点击 (低精度) ,或盲目尝试所有可见元素 (高召回率但低效用) 。验证机制能筛除无效操作,将数据收集聚焦于有意义的状态变化。
第二部分 —— UI2Code: 从交互图到可执行前端
UI2Code 模型的输入并非单张截图,而是结构化的交互图: 包含多个截图 (状态) 、DOM 快照,以及已验证的状态转换动作。这样模型便获得了明确的动态行为证据——例如“点击此处会弹出模态框”或“输入文本会更新字段”。
训练过程要点:
- 作者构建了一个大型交互网页数据集 (WebView) ,并利用 WebVIA-Agent 为每个页面采集多状态轨迹。
- 对每个交互图,生成基准交互式 HTML/CSS/JS 代码 (使用强大的多模态模型生成高质量的 React + Tailwind 代码) ,经渲染验证后用于微调基础视觉语言模型 (Qwen-2.5-VL 和 GLM-4.1V) 。
- 模型学习将视觉状态序列与动作轨迹映射到布局标记及事件处理器与状态更新,从而能生成端到端可执行页面,而非仅仅静态外观。
核心优势在于: 多状态监督教会模型 GUI 元素与行为之间的因果关联,而单截图训练无法编码这一点。
第三部分 —— 验证: 测试驱动生成
生成代码是一回事,验证其行为一致性是另一回事。验证模块就像自动化的 QA 测试:
- 它在生成页面上重放源于原始交互图的任务序列 (例如: 点击登录 → 模态框出现 → 输入凭据 → 点击提交) 。
- 若重放动作产生预期的视觉与结构变化,则页面通过验证;否则判定失败。
这种面向任务的验证关注端到端行为协调,而非单纯的布局相似度。它强大在于能提供二元、可复现的交互保真度证据。
构建训练环境: 合成网页与数据集
WebVIA 需要大量稳定、可交互的训练数据。真实网页常被广告与异步加载干扰,因此作者设计了合成 HTML 流水线,以生成多样且可执行的单页应用 (React + Tailwind) ,确保交互真实有效。
此流水线产出了两个主要数据集:
- 动作生成数据集 : 包含 (截图,DOM) 对及标注的有效动作序列。
- 交互验证数据集 : 包含 (前状态、动作序列、后状态、成功标签) 的元组,用于判定动作是否引发有效变化。
用于 UI2Code 训练的 WebView 数据集 含约 11,000 个合成网页,每个都有交互图与已验证的基准交互式代码。WebVIA-Agent 探索页面生成多状态输入,一个强模型 (Claude-Sonnet-4) 则生成可执行代码,作为 UI2Code 的微调基准。
半自动人工核查与浏览器端执行 (Playwright) 确保保留的页面与状态转换均有效且可复现。
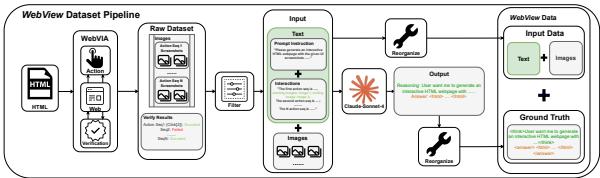
图 3: WebView 构建流程: 生成交互式 HTML → 探索收集轨迹 → 将多模态输入与可执行基准代码配对。
实验: 探索 + 交互监督是否奏效?
评估分为两部分: 探索智能体本身的性能,以及 UI2Code 模型生成可交互页面的能力。
智能体级评估 (单步)
两个子任务分别考察智能体:
- 动作生成 : 给定 (截图,DOM) ,预测哪些动作有效;
- 交互验证 : 给定前后截图,判断动作是否执行及是否产生新交互元素。
关键单步结果 (UIExplore-Bench) :
- WebVIA-Agent —— 精确率 82.37%,召回率 92.61%,F1 = 85.30%
- 基线模型示例: Gemini-2.5-pro (精确率 74.01,召回率 95.94,F1 81.70) ,Claude-Sonnet-4 (精确率 81.16,召回率 89.67,F1 83.38)
WebVIA-Agent 略降召回但提升了精确率,取得最高 F1 分数: 它避免了虚构交互元素,同时仍成功识别大多数真实的交互。其验证准确率亦领先,稳定区分有意义的状态变化。
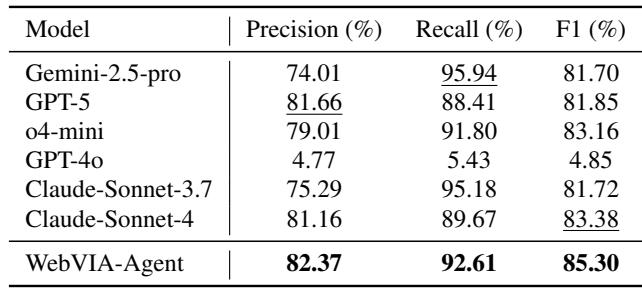
表 1: 单步动作生成结果。WebVIA-Agent 以精确率与召回率平衡获得最高 F1 得分。
流水线级评估 (端到端探索)
在此任务中,智能体自主探索完整网页并构建交互图。评估指标包括:
- 完整性 (Completeness) : 发现的不同可操作元素比例;
- 正确性 (Correctness) : 验证输出的准确度;
- 去重率 (Deduplication rate) : 避免重复交互的程度。
加权综合得分: Overall = 0.40·Comp + 0.35·Correct + 0.25·Dedup。
结果 (UIExplore-Bench) :
- WebVIA-Agent 总体得分: 89.63%
- 完整性: 93.12%
- 正确性: 97.71%
- 去重率: 72.73%
与强基线相比,WebVIA-Agent 通过结合广覆盖、高验证准确性与合理效率,取得最佳整体表现。
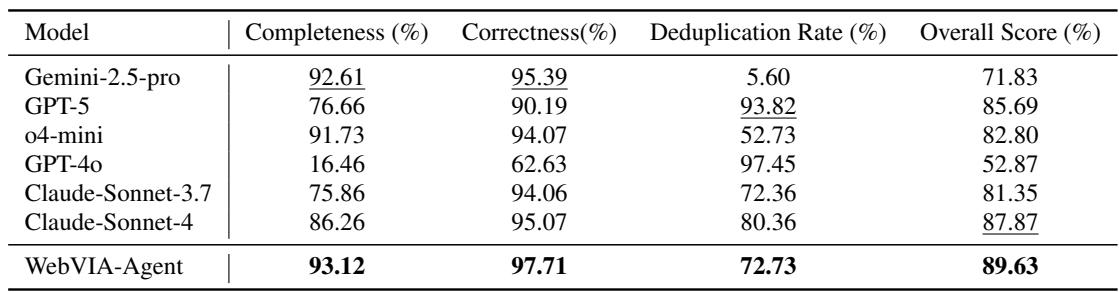
表 2: 完整网页任务的流水线评估。WebVIA-Agent 在完整性与正确性上领先,生成高质量交互图。
作者还指出,WebVIA-Agent 在平均交互轨迹长度 (探索成本) 与总体得分间保持良好平衡——探索深度适中而不冗长。一张相关性图显示 WebVIA-Agent 位于右上象限: 高分且中等轨迹长度。
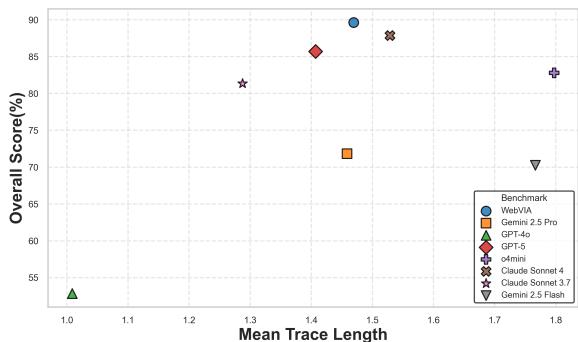
图 4: 平均轨迹长度与整体探索得分的关系——优秀智能体能以较少步骤获得更高表现。
交互式代码生成评估
这是关键测试: 在 WebVIA 框架下微调的 UI2Code 模型,是否能生成通过验证的交互式可执行网页?
使用的基准测试:
- Design2Code —— 标准静态布局重建基准;
- UIFlow2Code —— 作者提出的新交互基准,用于验证生成页面是否支持标注的状态转换 (任务级验证) 。
代表性结果:
- Qwen2.5-VL-7B (基础模型) Design2Code: 29.1
- WebVIA-UI2Code-Qwen (微调后) Design2Code: 34.3
- WebVIA-UI2Code-Qwen UIFlow2Code: 75.9 (基础 Qwen 未通过)
- GLM-4.1V-9B (基础模型) Design2Code: 58.3
- WebVIA-UI2Code-GLM Design2Code: 63.0
- WebVIA-UI2Code-GLM UIFlow2Code: 84.9
论文中的可视化图总结了这一改进: 基础模型通常无法生成可用交互代码;经 WebVIA 在 WebView 数据上的微调后,相同模型显著提升交互性能。说明交互监督是必需且有效的。
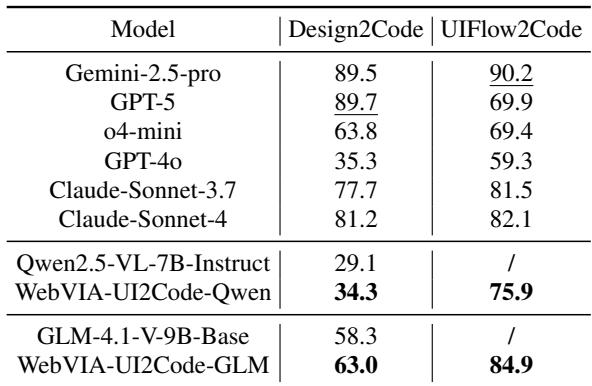
表 3: WebVIA 微调显著提升交互式代码生成能力。基础模型在 UIFlow2Code 上失败;WebVIA 变体则通过了多数任务。
定性结果显示,WebVIA 训练后模型生成的页面不仅正确渲染,还能连接事件处理与状态更新,使操作 (点击、选择、输入) 触发预期页面变化。论文的并排图展示了 WebVIA 输出的功能完整页面与基线模型产生的非交互或错误结果的对比。

图 5: 网页合成效果对比。WebVIA 输出 (左侧) 在视觉与功能上均更完整;基线模型常遗漏交互逻辑。
局限性与实践考量
作者坦率地说明了当前局限:
- 动作集受限 : 仅包括点击、输入、选择。复杂交互 (拖放、绘画) 需像素级控制,暂未涵盖。
- 训练偏向合成数据 : 智能体主要在程序生成页面上训练。尽管对真实网站的泛化效果尚佳,仍存在领域差距 (如计算器、绘图工具) 行为模式不同。
- 基准数据依赖强模型 : 基准代码由强模型生成;要在大规模上自动生成高质量基准并不容易,仍需人工筛选与验证。
这些都是现实约束: WebVIA 是令人信服的概念验证与重要进步,但尚不具备替代生产级 UI 工程的条件。
对实践者与研究者的启示
- 交互式监督至关重要 : 在多状态交互图上训练 UI2Code 模型能学习事件的因果行为映射,而不仅是静态布局复现。
- 智能体探索是可扩展的数据获取方式 : 探索智能体能系统地发现状态与转换,从而构建高价值多状态数据集。
- 验证不可或缺 : 任务级回放为交互性提供明确的通过/失败信号,比像素相似度指标更具意义。
- 合成环境是务实的折衷方案 : 通过可控页面生成与执行,研究者可创建大量、多样且可验证的数据集。关键在于弥合“合成 → 真实”的鸿沟。
未来方向
WebVIA 展示了一条切实可行的路线图: 结合智能体探索、多模态监督微调与任务级验证,推进向全交互式 UI 合成。未来工作可扩展动作集、引入真实网站数据微调,并研究更强的端到端生成 (如生产级组件化代码、可访问性特性及自动化测试套件) 。
如果你正在开发者工具、原型平台或自动化 UI 流水线领域工作,WebVIA 的核心思想——让模型通过行动与验证来学习——为将设计稿转化为真正可运行的原型提供了令人期待的方向。
文中引用的参考文献与图表均来自论文《WebVIA: A Web-based Vision-Language Agentic Framework for Interactive and Verifiable UI-to-Code Generation》。