](https://deep-paper.org/en/paper/2511.07587/images/cover.png)
大型语言模型 (LLM) 令人惊叹,但它们存在记忆问题。让它总结一份10页的报告,它可能表现出色。但如果让它从一本500页的小说中回忆第七页的某个细节,并将其与第二页的一个想法联系起来,模型的短板便显现出来。这并非智力不足,而是架构上的根本限制: 上下文窗口 (context window) 。
LLM在执行任务时所“知道”的一切,都必须装入这个有限空间中。上下文窗口正不断扩展,甚至达到数百万个Token,但它们仍然是有限的。更糟的是,性能往往会随着窗口填满而下降——这一现象被称为*中间丢失 (lost-in-the-middle) *,即深埋在文本中的细节会逐渐从模型的掌握中淡去。
常见的解决方案是检索增强生成 (RAG) 。 RAG不向模型提供整个文档,而是只检索最相关的部分——通常是与查询相关的段落或短文本块——并在推理时提供给LLM。这对于基于事实的查询,例如*“法国的首都是什么?”非常有效。但当查询依赖于理解一个叙事*时,RAG就开始力不从心。
世界上的信息大多不是整齐的事实清单,而是由故事组成。比如犯罪报告、新闻文章、法律文件或项目会议记录。这些文本描述了行动者 (个人或组织) 扮演着角色 (嫌疑人、监管者、投标人) ,经历着状态 (被捕 → 提审 → 释放) 的变化,并在特定的时间和地点发生互动。标准的RAG将文本视为若干独立的片段,无法以连贯的方式把这些点连接起来。
人类却擅长这一点。我们拥有认知心理学家 Endel Tulving 所称的情景记忆 (episodic memory) ——在脑海中重温事件的能力。我们不仅记住事实,还会在情境中记住它们: 谁在场、发生了什么、何时何地。这种结构能让我们从经验中构建出一个连贯且不断演进的“世界模型”。
加州大学洛杉矶分校 (UCLA) 的研究人员提出了一种框架,为LLM赋予类似的能力。 生成式语义工作空间 (GSW) 是一种受神经启发的记忆系统,它能构建结构化、故事化的情境表征。它远超于简单的事实检索,使语言模型能够理解事件如何发生、谁参与其中、以及事件何时发生——在准确性和效率上都有显著提升。
从碎片化事实到连贯故事
要理解为何GSW是一次重要飞跃,我们需要认识现有RAG系统的不足。
标准RAG将文档切分为自包含的片段,使用嵌入模型对每个片段编码,并检索与查询语义最相似的段落。当答案存在于单个文本段中时,这种做法效果良好。
它的弱点在于碎片化。当答案跨越文档的多个部分 (比如分散在不同章节的段落) 时,标准RAG常常只能检索到部分所需信息。由于每个文本块独立索引,它们之间的上下文联系被打断。
结构化RAG系统通过引入知识图谱来捕捉语料库中实体和概念之间的关系,取得了进展。它支持多跳推理,能连接“公司”→“CEO”→“季度业绩”等数据点。但这些系统更多针对维基百科这类静态、充满事实的资源进行了优化。它们表示的是已知的事实,而非事件如何演变。它们难以建模一个行动者不断变化的角色,或描述事件如何跨时空发展。
GSW弥补了这一空白——它为叙事而设计,而非静态事实。GSW的记忆建立了对故事中谁、什么、何地、何时、如何的结构化表征,模拟了人类的情景推理过程。
受大脑启发的记忆蓝图
神经科学提供了指导性类比。人类的情景记忆源于两个互补系统的互动:
- 新皮层 (Neocortex) — 存储关于实体和事件的层级化抽象与模式。
- 海马体 (Hippocampus) — 将这些抽象联系为有时间与空间锚点的连贯序列。
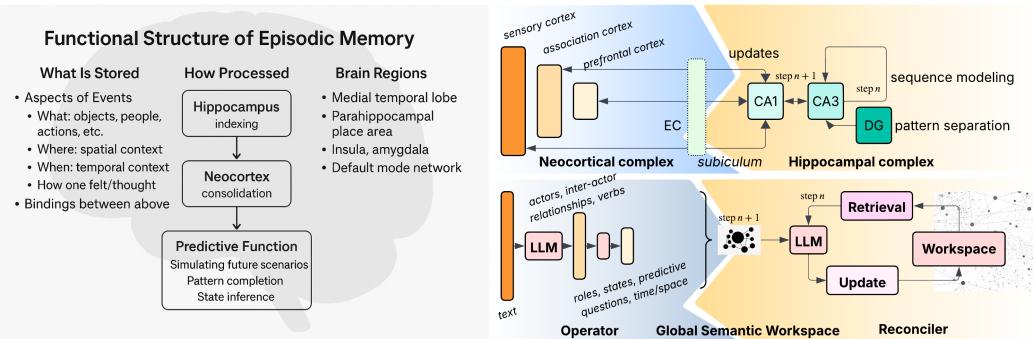
图1: 统一的大脑启发与生成语义——用于情景记忆建模。
GSW通过两个核心组件来模拟这种架构:
- 操作器 (Operator) 类似新皮层。它是一个由LLM驱动的模块,用于分析每个输入文本块,提取结构化信息——识别行动者、角色、状态、动作与关系。
- 整合器 (Reconciler) 类似海马体。它将这些语义快照整合到一个持久的工作空间中,确保时间、空间和逻辑上的一致性,负责将事件拼接成不断演化的世界模型。
两者共同构建出文本展开时的一个活的记忆。
生成式语义工作空间内部
GSW的目标是将原始的非结构化叙事转化为结构化、可解释的记忆。让我们来看看这一过程。
操作器: 理解当下
操作器分析一段小的文本,并构建一个语义地图——对情境的紧凑表示。该地图包括:
- 行动者、角色与状态:
- 行动者可以是人、地点、组织或物体。
- 角色定义行动者在情境中能执行的行为 (例如,嫌疑人、法官、组织者) 。
- 状态是在特定时间点对角色的具体化 (嫌疑人在逃 vs. 嫌疑人被捕) 。
从数学上看,一个行动者对另一个行动者采取行动的概率取决于他们的角色和状态:
\[ \pi_{r,s}(a_i \to a_j) = \pi_r(a_i \to a_j \mid s) \]动词与价态: 动词描述角色或状态如何、为何变化——例如,“逮捕”会将一个人从在逃转变为被拘留。价态编码了这种因果关系。
时间与空间: 操作器会将每个事件锚定在其时间与地点背景中。如果文本提到“警官在格林维尔市中心逮捕了乔纳森·米勒”,模型会将两个行动者与该位置和时间戳关联起来,确保它们共享上下文。
前瞻性问题: 这些预测性问题作为记忆构建的一部分生成,例如: “米勒何时会被起诉?”或“审判将在哪里进行?”它们帮助系统预测并连接未来的叙事发展。
这种结构将文本转化为一部电影中的单个帧——一个清晰的事件快照。
论文中的一个生动例子展示了GSW如何围绕黑客马拉松事件为朱利安·罗斯构建记忆。
第一个文本块显示朱利安参加了活动,但未提及时间或地点。第二个文本块从他的智能手表中揭示日期——2024年5月31日。
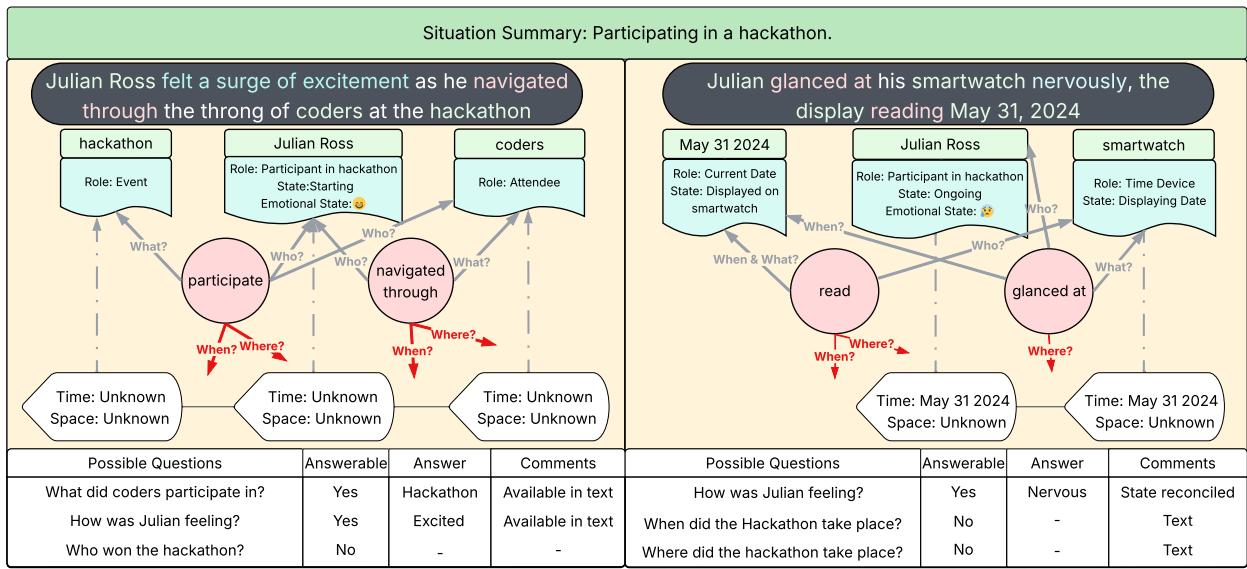
图8: 操作器示例——两个文本块被分析为结构化语义框架。
整合器: 编织故事
整合器接收来自操作器的输出,并将它们整合成一致、不断演进的记忆。它执行两种关键形式的整合:
- 实体整合 (Entity Reconciliation) : 识别多个文本块中提到的“朱利安·罗斯”为同一人物,并合并其属性。
- 时空整合 (Spatiotemporal Reconciliation) : 利用新发现的时间或地点细节更新先前记忆,并将该信息传播给相关实体。
整合后的结果形成一个统一、带时间戳的事件表征。
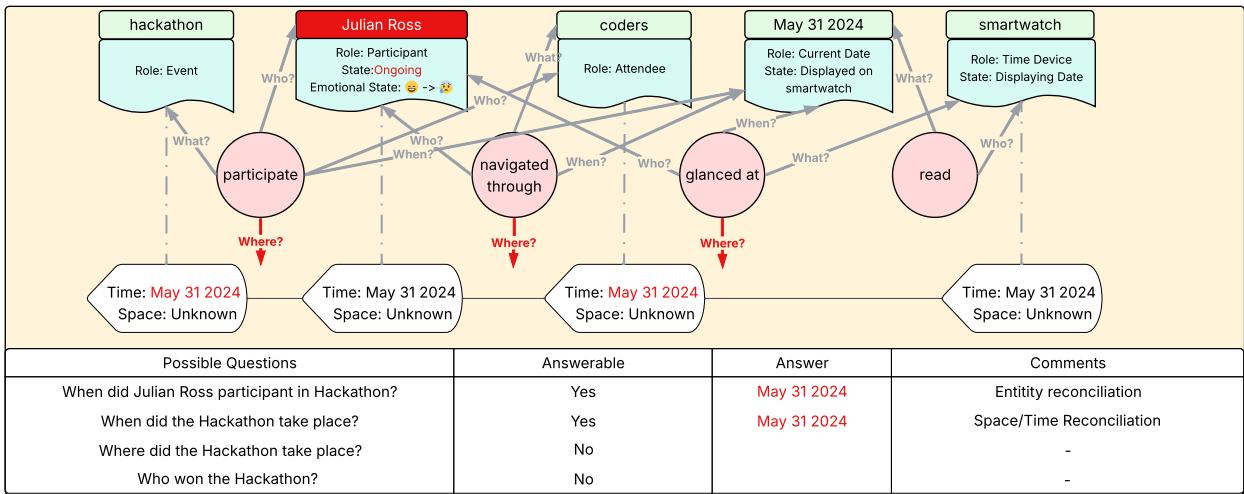
图9: 整合器示例——链接实体并保持时间连续性。
随着新文本出现 (例如揭示地点“硅滩”和罗斯获胜的消息) ,整合器不断更新。它能回答先前创建的前瞻性问题,同时扩展语义网络,形成连贯的叙事轨迹。
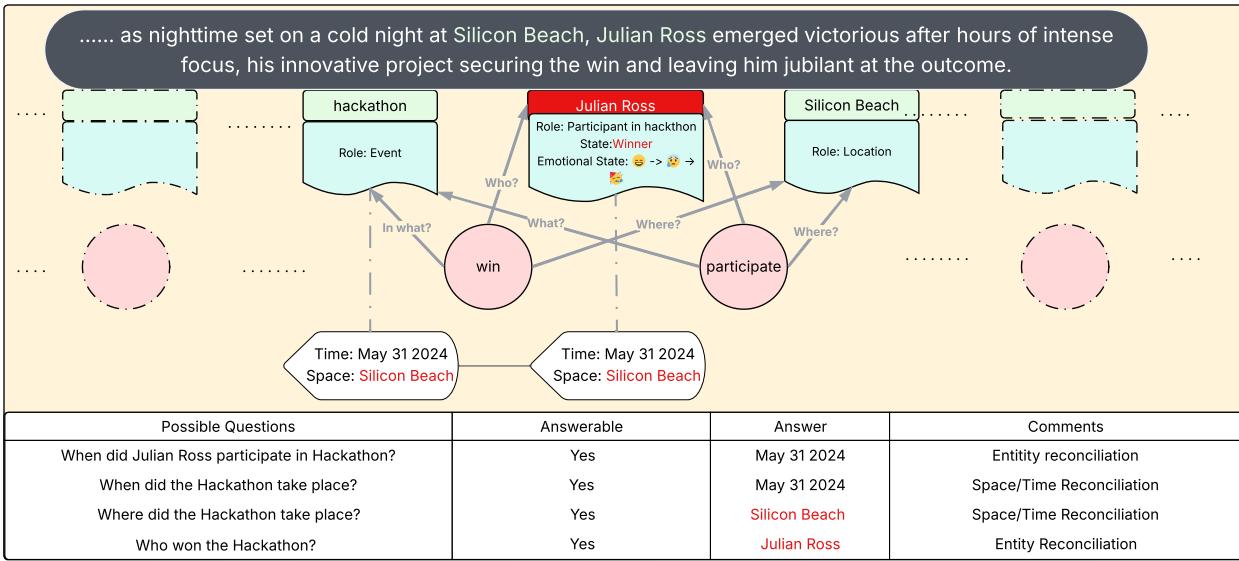
图10: 最终的GSW——整合行动者、时空信息与已解决的问题。
这一逐步过程体现了GSW随时间构建记忆的机制,其形式化表示为:
\[ P(\mathcal{M}_n | \mathcal{C}_{0:n}) = \sum_{\mathcal{M}_{n-1}, \mathcal{W}_n} P(\mathcal{M}_n | \mathcal{M}_{n-1}, \mathcal{W}_n) \, P(\mathcal{M}_{n-1} | \mathcal{C}_{0:(n-1)}) \, P(\mathcal{W}_n | \mathcal{C}_n) \]通俗来说就是: 新记忆 = f(旧记忆, 新信息)。
问答: 调用记忆
一旦记忆构建完成,GSW即可用于优雅的问答流程:
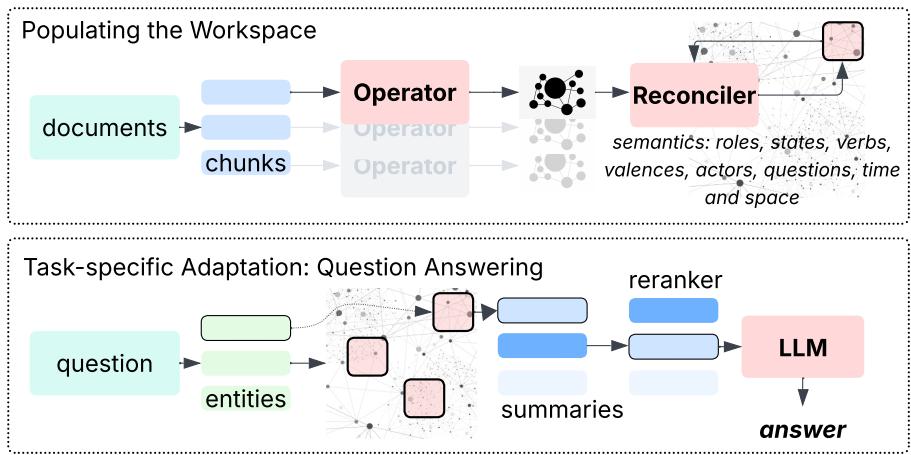
图2: 情景记忆创建与问答——构建与查询工作空间。
- 实体匹配: 找出查询中提到的实体 (例如,“卡特·斯图尔特”、“科学会议”) 。
- 摘要生成: 从工作空间中检索这些实体的简洁按时间排序的摘要——包含角色、状态、时间和地点。
- 重排序: 按查询相关性对摘要进行排序。
- 答案合成: 将最高相关的摘要传递给LLM,生成最终的上下文驱动答案。
这种方法在LLM处理之前,就已将记忆转化为紧凑、语义丰富的摘要。完整的问答示例如下:

图11: GSW问答框架示例——在结构化记忆中进行匹配与推理。
测试GSW
为了验证该方法,作者在情景记忆基准 (EpBench) 上评估了GSW。该基准测试AI在不断变化的叙事中回忆与推理的能力。使用了两个版本:
- EpBench-200 (约10万Token,200章节)
- EpBench-2000 (约100万Token,2000章节)
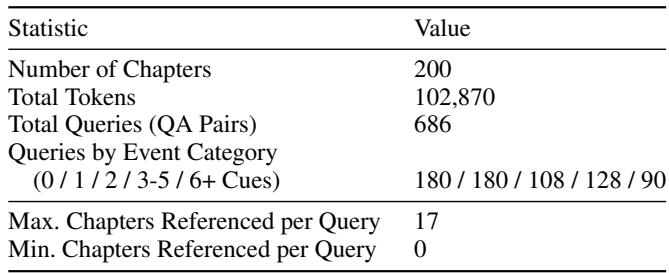
表1: EpBench-200 数据集——结构化叙事基准。
GSW与多个强基线模型对比: 长上下文LLM、标准嵌入式RAG以及结构化RAG变体 (GraphRAG、HippoRAG2、LightRAG) 。
准确性: 当上下文变复杂时
在所有难度级别上,GSW都展现出更高的准确性。
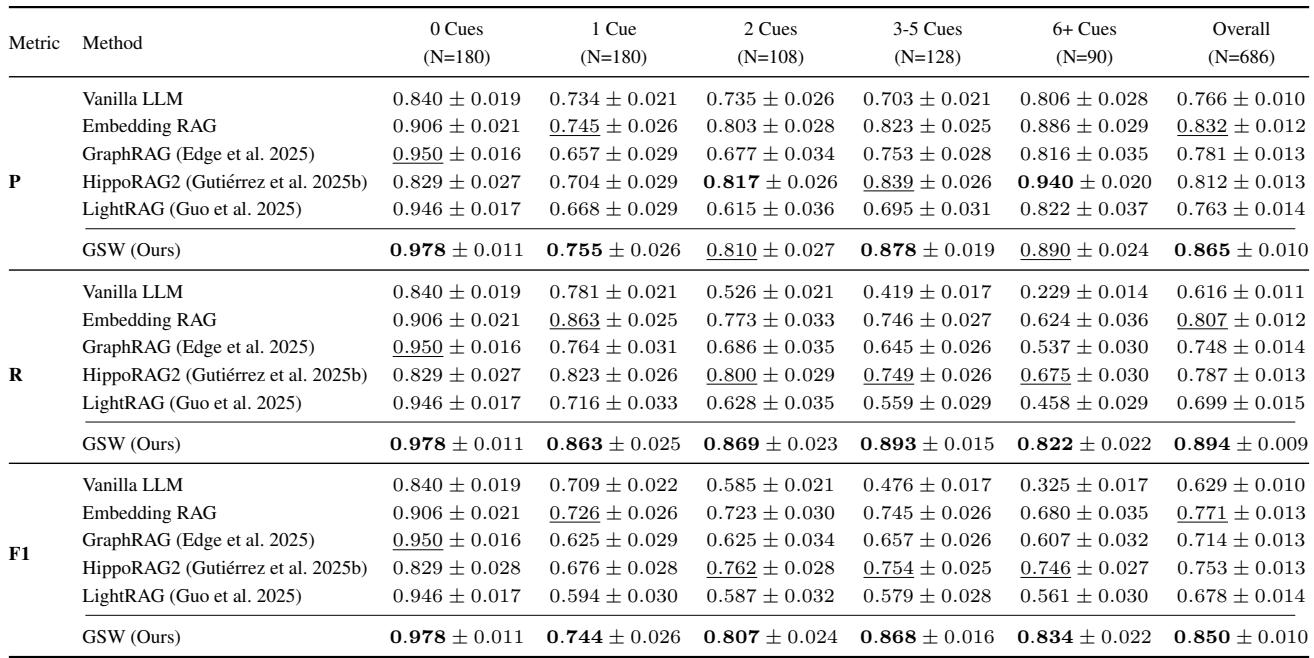
表2: GSW在 EpBench-200 上的性能表现。
最具挑战的是*“6+提示”*类别——问题需跨越多达17个不同章节进行推理。在这一最难类别中,GSW的召回率比次优系统 HippoRAG2 高出 20% 。 与其他框架在复杂度提升时召回率急剧下降不同,GSW的结构化、连贯记忆使其能稳定追踪相关情节。
效率: 以更少的Token完成更多任务
GSW不仅思考更好,还更高效。由于查询使用摘要而非原始文档块,输入LLM的Token数量显著减少。
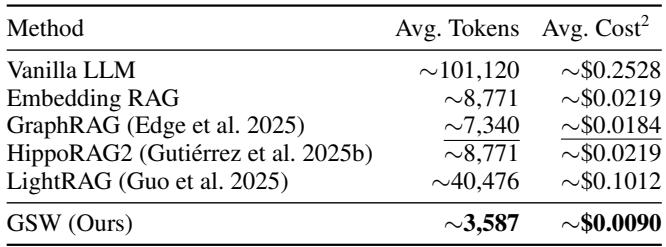
表3: GSW的效率——更少Token,更低成本。
与GraphRAG相比,GSW的平均Token使用量减少 51% , 与嵌入式RAG相比减少近 59% 。 这不仅意味着更快的推理、更低的成本,也减少了幻觉生成,因为模型专注于简洁、相关的上下文。
可扩展性: 在十倍规模下保持稳定
在2000章节的大型数据集上,GSW依然领先——F1分数提升 15% , 召回率提升 14% 。
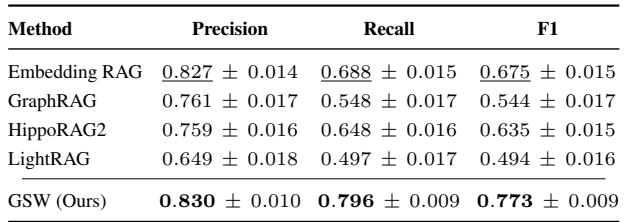
表4: GSW在2000章节基准测试上的性能表现。
这些结果表明,GSW能优雅扩展,在长而复杂的叙事中保持强大的推理能力——这对于支撑百万级Token规模的真实知识库至关重要。
结论: 迈向类人式AI记忆
生成式语义工作空间 (GSW) 为LLM提供了一种全新的记忆机制——它是结构化的、可解释的、且动态的。GSW不是简单地检索孤立事实,而是构建一个不断演进的语义世界模型,追踪行动者、角色、状态和情境,就像人类回忆故事一样。
GSW的操作器与整合器形成了一个受神经启发的循环,将文本转化为连贯的世界模型。这不仅使得精准的长上下文推理成为可能,还在复杂情景任务中显著提升准确性,并带来了显著的效率收益。
尽管当前实现依赖于大型专有模型,未来方向包括探索开源替代方案,以及将GSW扩展到视频或传感器数据等多模态输入。其长远愿景令人振奋: 让LLM不仅能阅读,更能记忆——成为能理解不仅发生了什么,还理解如何和为何发生的智能体。
简而言之,GSW让LLM向真正的叙事理解更近一步——连接语言与持久理解,连接事实与情节,连接记忆与推理。