](https://deep-paper.org/en/paper/2511.08923/images/cover.png)
大型语言模型 (LLM) 席卷全球,但任何使用过它们的人都注意到,当模型生成响应时,总会出现一个轻微的停顿——模型是一 token 一 token 地生成的。这种顺序、逐步的生成方式是自回归 (AR) 模型的特征,也是 GPT、Claude 和 Llama 等模型背后的核心架构。AR 模型以其非凡的连贯性和准确性而著称,但这种高质量是以速度为代价的。因为每个新 token 都依赖于前一个,它们天生就慢。
这时出现了扩散语言模型 (dLMs) 。 这些模型提供了另一种途径: 并行生成。它们可以同时解码多个 token,而不是逐个生成,这带来了吞吐量大幅提升的诱人前景。然而,这种速度通常伴随着输出质量的折损。并行解码背后的独立性假设可能破坏语言连贯性。
这就留下了一个核心问题: 我们究竟该选择高质量但缓慢的 AR 模型,还是高速但一致性欠佳的扩散模型?如果我们根本不需要做出选择呢?
来自 NVIDIA 的研究团队最近提出了 TiDAR (Thinking in Diffusion and Talking in Autoregression) ——一种革命性的混合模型,它将扩散模型的并行“思考”与自回归模型的高质量“表达”融合在一次高效的前向传播中。结果?TiDAR 缩小了与经典 AR 模型之间的质量差距,同时实现了惊人的 4.7 倍到 5.9 倍 生成吞吐量提升。
让我们来剖析这一跨越背后的洞见。
瓶颈: 为什么自回归模型那么慢?
要理解 TiDAR 的创新,我们首先要明白传统的 AR 模型受制于什么。问题不仅在于计算,更在于内存带宽 。
在每个解码步骤中,AR 模型必须从 GPU 内存中加载数十亿个参数以及键值 (KV) 缓存。这种数据传输是延迟的主要来源。相比之下,一旦数据加载完毕,生成一个 token 所需的计算本身非常快。这意味着 GPU 的计算单元常常闲置,尽管硬件充裕,管线却处于低效状态。
NVIDIA 的一项性能分析实验完美地展示了这一点:
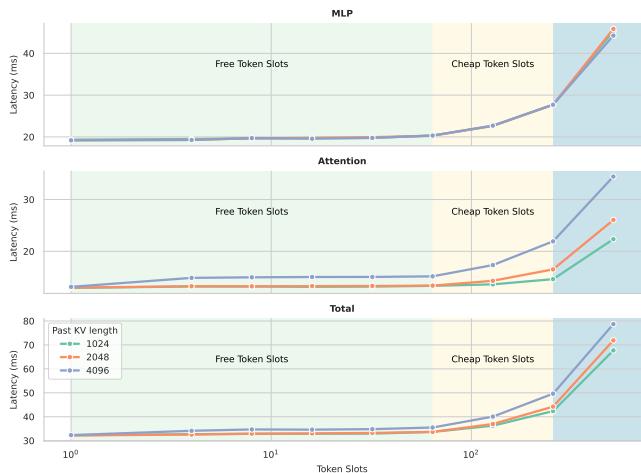
图 1 | Token 位置上的延迟扩展: 在 NVIDIA H100 上,Transformer 解码的延迟在最初的一组 token 上几乎保持平稳——这些是“免费”的 token 位置,几乎不增加额外延迟。TiDAR 正是利用这些免费位置来最大化吞吐量。
结论是: 在单次前向传播中增加几个额外 token 位置几乎不会显著增加延迟成本。这些 “免费 token 位置” 暗藏并行生成的潜力——前提是我们能维持序列质量。
这正是扩散模型试图解决的问题,但效果一直不尽人意。原因如下。
AR 与扩散模型的质量差距
AR 模型与扩散模型在文本序列概率建模方式上根本不同。
一个自回归模型通过将条件概率串联来表示完整句子的概率,其中每个 token 都依赖于之前所有 token:
\[ p_{\mathrm{AR}}(\cdot;\theta) = \prod_i p_{\theta}^{i}(x_i|\mathbf{x}_{\langle i};\theta) \]这种从左到右的因果结构天然地契合语言生成,产生流畅一致的文本。
而扩散模型则学习如何逐步去噪被破坏的序列。当并行生成多个 token 时,扩散模型会在共享的噪声上下文中独立预测每个 token:
\[ p_{\mathrm{Diff}}(\cdot;\theta) = \mathbb{E}_{\tilde{\mathbf{x}} \sim q(\cdot|\mathbf{x})} \prod_i p_{\theta}^{i}(x_i|\tilde{\mathbf{x}}) \]这种独立性假设牺牲了驱动人类语言连贯性的丰富上下文依赖。研究表明,像 Dream 和 LLaDA 这样的扩散式 LLM 通常只有在每步生成一个 token 时才能获得最佳质量——削弱了它们的并行优势。
如果一个模型能够像扩散模型一样计算 , 同时又像自回归模型一样采样 , 那就理想了吧?
这正是 TiDAR 所实现的。
核心方法: 单次前向传播中的思考与表达
TiDAR 通过一个结构化混合注意力掩码 , 在单次前向传播中整合了并行的扩散草稿生成和自回归采样。模型同时进行“思考” (起草) 与“表达” (验证) ——名字由此而来。
生成流程如下:
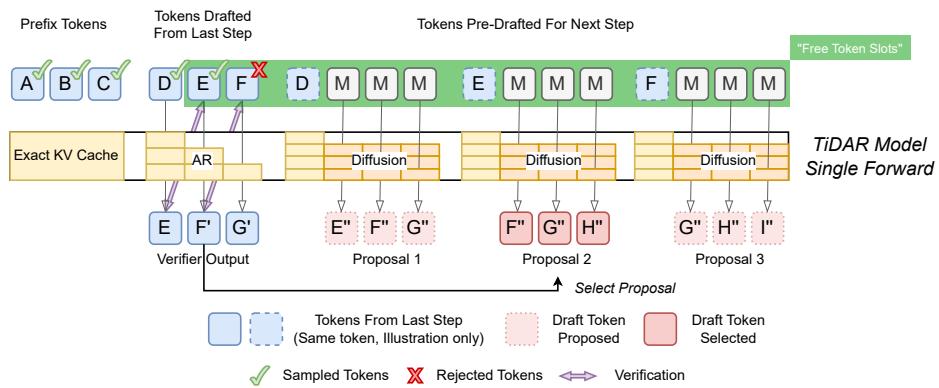
图 2 | TiDAR 架构: 在每次前向传播中,token 被划分为三个部分——前缀 token、上一步草稿 token,以及用于下一步的新预草稿 token——所有部分在同一次传播中高效处理。
每个生成步骤包含三个 token 段:
- 前缀 Token: 上一步中已验证的 token。
- 草稿 Token: 上一次迭代中提出的候选 token。
- 预草稿 Token: 作为下一步提议的掩码 token。
TiDAR 的结构化注意力掩码针对这些段采用不同策略:
- 前缀 + 草稿 Token: 使用因果注意力处理,遵循自回归语义。模型预测高质量的下一个 token,并通过拒绝采样验证草稿。
- 预草稿 Token: 使用双向注意力处理,以已接受的前缀为条件进行单步扩散起草。
在一次前向传播中,TiDAR 同时完成两项任务:
- 表达 (验证) : 自回归地检查草稿 token 是否符合因果预测。接受的 token 缓存重用,被拒绝的丢弃。
- 思考 (预起草) : 同时利用单步扩散生成下一步的多个并行 token 提议。
所有过程并行进行——计算密度与利用率显著提高,同时通过拒绝采样与 KV 缓存复用保持高质量。扩散模型提供速度,自回归模型提供精度,二者相辅相成。
训练双模一体的模型
为了训练这一双模式主干网络,TiDAR 在每个序列末尾添加一个 [MASK] token 块,使模型能够同时学习自回归与扩散目标。
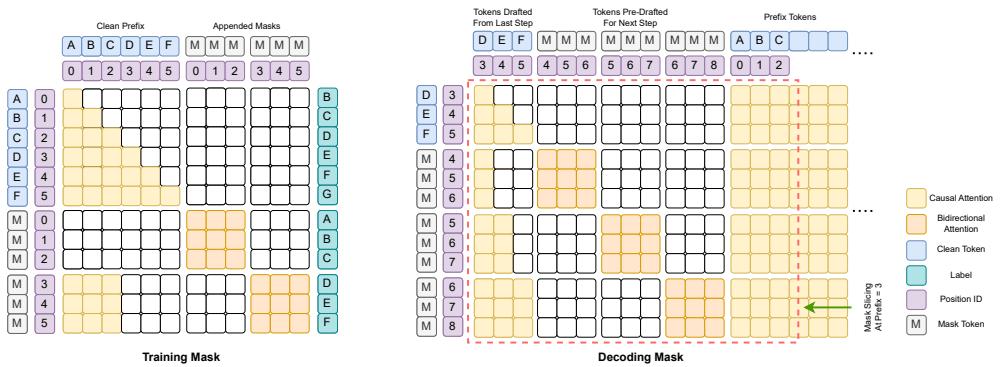
图 3 | 训练 vs 解码掩码: 在训练期间,干净 token 通过因果注意力 (橙色) 处理,而掩码 token 在扩散块中通过双向注意力处理。推理时,解码掩码平滑地结合两种机制以实现并行生成。
训练阶段:
- AR 损失应用于前缀 token (因果掩码) 。
- 扩散损失应用于被掩码的 token (双向掩码) 。
研究团队提出了一种优雅的简化——全掩码策略 : 与随机掩码不同,扩散部分的所有 token 都被掩码。这种策略大大简化了训练,并带来了以下好处:
- 更密集的扩散损失信号。
- AR 与扩散损失的平衡一致性。
- 训练行为与单步扩散推理完美对齐。
最终训练目标如下所示:
\[ \mathcal{L}_{TiDAR}(\theta) = \frac{1}{1+\alpha} \left( \sum_{i=1}^{S-1} \frac{\alpha}{S-1} \mathcal{L}_{AR}(x_i, x_{i+1}; \theta) + \sum_{i=1}^{S-1} \frac{1}{S-1} \mathcal{L}_{Diff}([mask], x_i; \theta) \right) \]由此产生一个多才多艺的模型,能同时以因果与双向方式理解语言——为超高效推理做好准备。
TiDAR 的测试: 结果与分析
研究团队在两个规模上测试了 TiDAR——1.5B 和 8B 参数——涵盖编码 (HumanEval、MBPP) 与数学推理 (GSM8K、Minerva Math) 等多种任务。
生成质量与速度
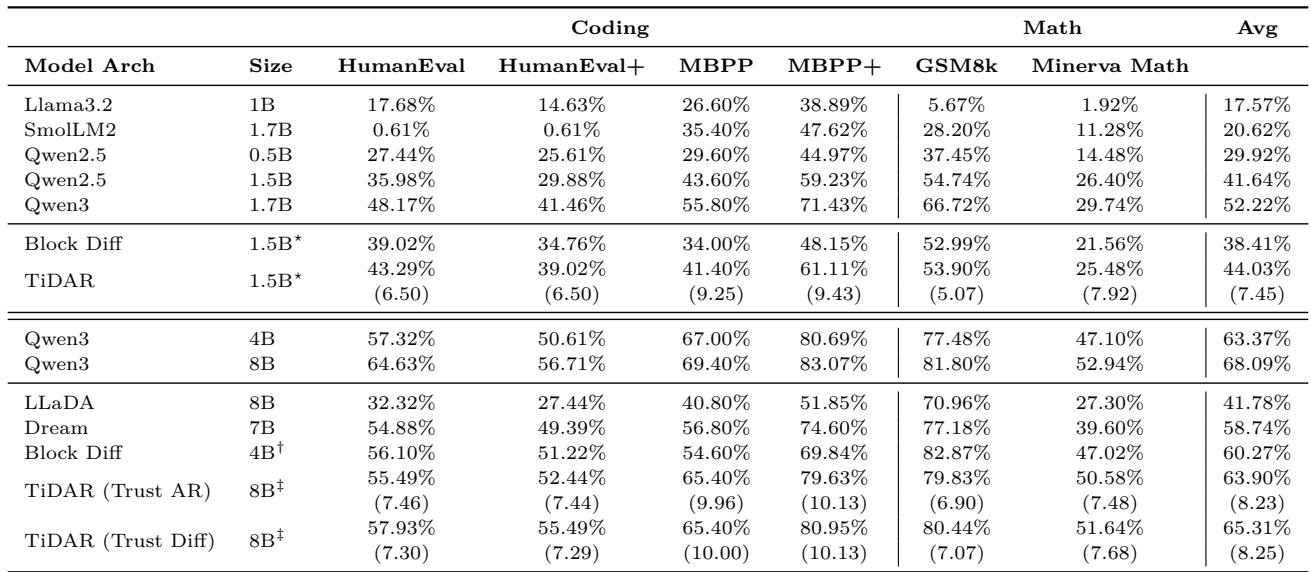
图 4 | 生成评估: TiDAR 在每次前向传播生成多个 token 的同时,实现了与领先 AR 模型几乎相当的质量。
在 1.5B 参数规模下,TiDAR 的质量与 AR 基础模型相当,每次前向传播平均生成 7.45 个 token 。 在 8B 规模下,质量损失极小,吞吐提升至每次前向传播 8.25 个 token 。 生成速度提升近六倍,同时保持准确性。
实际时间加速: 真正的成果
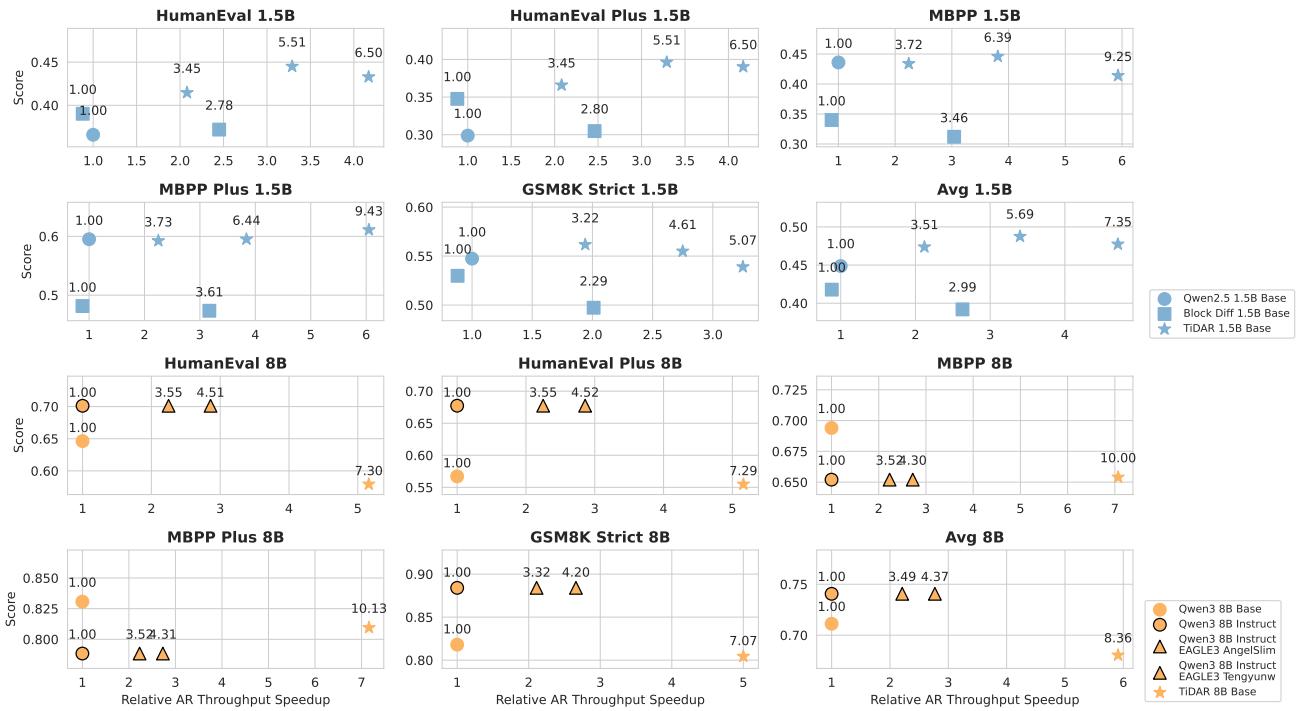
图 5 | 效率–质量基准: TiDAR 1.5B 实现了 4.7×,TiDAR 8B 实现了 5.9× 的速度提升,超越标准 AR 模型和推测解码方法。
在 NVIDIA H100 GPU 上的测量显示,TiDAR 将并行性转化为真实收益:
- 比 Qwen2.5 1.5B 吞吐提升 4.71× ;
- 比 Qwen3 8B 提升 5.91× 。
即使与最先进的推测解码系统 EAGLE-3 相比,TiDAR 的吞吐效率仍略胜一筹——这是扩散式方法首次在保持可比质量的同时超越推测解码。
为什么如此高效?关键消融研究
研究团队进行了多项消融实验,以确定性能提升的关键因素。
1. 全掩码策略
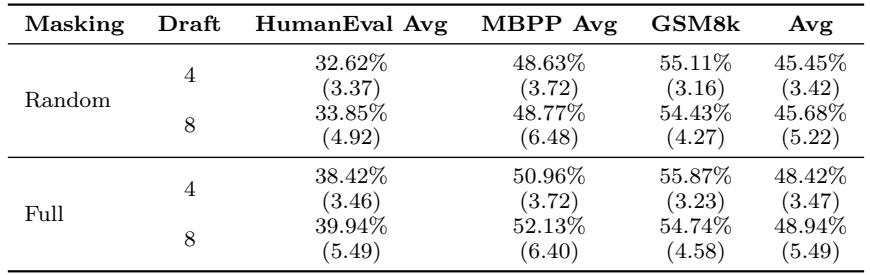
图 6 | 全掩码训练效果: 全掩码在编码和数学任务上带来了更高的质量与效率。
将随机损坏替换为全掩码显著改善了质量与吞吐量,这得益于训练–测试一致性及更强的扩散损失信号。
2. 平衡的 AR 与扩散验证
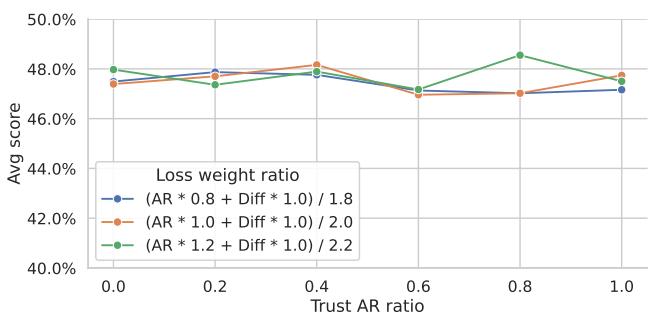
图 7 | 信任 AR 与扩散: 无论信任 AR 还是扩散的 logits,TiDAR 均保持稳定的高质量——表明其双模式训练非常均衡。
在融合 AR 与扩散 logits 的实验中,TiDAR 不论信任哪种预测都表现出一致的精度。这种稳定性彰显了自回归拒绝采样机制的鲁棒性,确保了起草方式不影响最终质量。
结论: 高效生成的新纪元
TiDAR 打破了语言模型推理中长期存在的质量与速度权衡。通过构建一个能以并行扩散“思考” 、并以自回归精度“表达” 的混合序列架构,它最大化了 GPU 利用率,最小化了延迟——且不牺牲连贯性。
其核心创新——结构化混合注意力掩码、单次传播起草验证机制和全掩码训练方案——共同实现了前所未有的解码效率。TiDAR 在保持自回归质量的同时,实现高达 6 倍的生成速度 , 为下一代 LLM 架构树立新标杆。
这是扩散模型首次达到并超越推测解码速度——清晰地预示着,未来的 LLM 推理属于混合式思维。