](https://deep-paper.org/en/paper/2511.09148/images/cover.png)
大语言模型 (LLM) 已经改变了自然语言处理领域,但只有当它们能够与外部世界互动时,其全部潜力才能得以释放。通过学习使用工具——例如 API、数据库或代码执行函数——LLM 从文本生成器进化为能够推理和行动的智能代理。想象一下,一个 AI 助手可以在一场对话中无缝地预订航班、分析销售数据并撰写商业报告。这正是工具增强型语言模型所带来的前景。
然而,要让 LLM 真正掌握工具的使用并不容易。传统训练方法依赖于静态的、预先生成的工具使用示例数据集,而这种方式存在两大问题:
- 静态数据: 数据只生成一次然后就被锁定。模型始终在相同的示例上训练,即便早已掌握这些示例,却无法遇到足够多的困难案例来提升推理和决策能力。
- 噪声标签: 自动生成的数据集往往包含细微错误——参数不对、调用不完整或输出不匹配——这些错误会混淆模型并降低其性能。
如果这个过程能更智能一些呢?如果模型能够亲自指导和纠正自己的训练数据——找出弱点、过滤掉噪声样本、并生成它真正需要的挑战性示例,会发生什么?
这正是 LoopTool 的核心理念。它是一个自动化、模型感知的框架,将数据生成与训练融合为一个持续的闭环过程。不再是从数据到模型的单向流动,LoopTool 让训练变得迭代、自适应且自我纠正,从而显著提升工具使用型 LLM 的性能。
旧方法的弊端: 静态流水线
在多数工具学习系统中,训练流程是停滞的:
- 生成数据: 一个强大的模型 (通常闭源且昂贵) ,比如 GPT-4,生成大量工具使用的对话数据。
- 训练模型: 一个较小的开源模型在该合成数据集上进行微调。
- 祈祷结果: 完成训练后再评估效果。
这一流程是脱节的。数据生成器不了解训练模型的薄弱环节,而训练模型也无法影响后续的数据生成。这就像给学生一本千页的教材,却从不测验他们究竟在哪些章节需要帮助。更糟的是,如果教材本身就有错误,学生也会照单全收。
LoopTool 用一个动态、反馈驱动的循环取代了这种脱节的范式,使数据生成、模型诊断与改进持续相互促进。
LoopTool 框架: 自精炼循环如何运作
LoopTool 将四个紧密相连的阶段结合为一个良性循环: 训练、诊断、验证和数据扩展 。 随着循环运行,数据集和模型共同演进,相互强化。
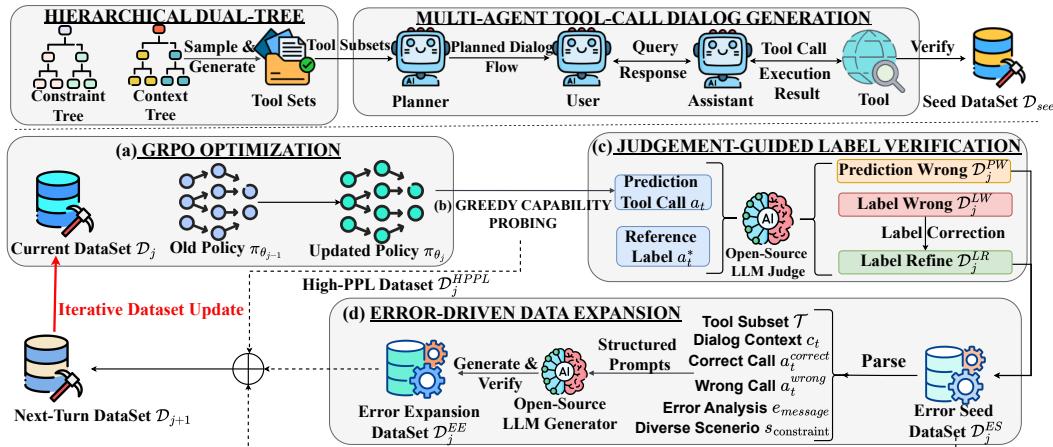
图 1: LoopTool 的整体闭环自动化流水线,结合了 (a) GRPO 优化、(b) 贪婪能力探测、(c) 判别指导的标签验证以及 (d) 错误驱动的数据扩展,实现工具使用的迭代增强。
第 0 步: 播种 —— 自动化数据构建
在循环开始前,LoopTool 需要一个高质量的种子数据集作为基础。团队通过两个创新模块构建了它:
分层 API 合成: 采用双树结构生成多样且真实的 API。上下文树定义应用领域 (例如,旅行 → 航班 → 搜索) ,而约束树确保结构有效 (参数类型、命名、格式) 。从两棵树中采样可生成结构化且连贯的新 API。
多代理模拟: 四个代理——规划器、用户、助手和工具代理——模拟自然的多轮工具使用对话。规划器设计对话流程,用户发出请求,助手选择并调用工具,工具代理返回模拟结果。每条对话都贴近真实使用场景。
所有生成数据都经过规则校验和开源 LLM 判别器 (Qwen3-32B) 的验证,确保语法与语义正确后才纳入种子语料库。
第 1 步: GRPO 优化 —— 强化微调
训练从 GRPO (Grouped Reinforcement Policy Optimization) 开始,这是一种强化学习技术,当模型生成正确的工具调用时会给予奖励。
奖励函数如下:
\[ r(\mathcal{T}, c_t, a_t^*, a_t) = \begin{cases} 1, & \text{ToolMatch}(a_t, a_t^*) \\ 0, & \text{otherwise} \end{cases} \]这里,\(a_t^*\) 是上下文 \(c_t\) 与工具集 \(\mathcal{T}\) 对应的正确工具调用。模型的目标是最大化二元奖励,并在不同版本间保持稳定。
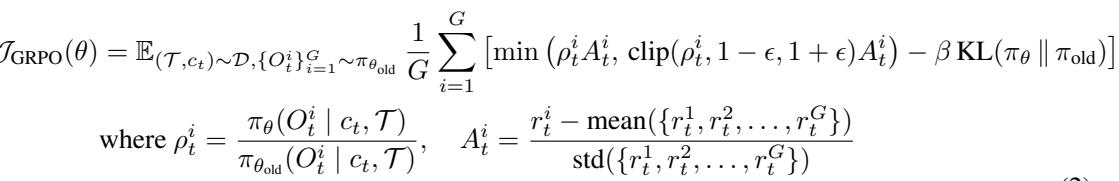
经过这一轮初步训练,模型已有一定学习成果——但仍不完美。接下来的步骤将诊断它的不足,并利用洞察升级数据与知识。
第 2 步: 贪婪能力探测 (GCP)
训练结束后,通过贪婪解码——即总是选择概率最高的下一个词元——来“探测”模型的能力。每个样本分为两类:
- 已掌握: 模型预测正确的工具调用。
- 失败: 预测与标签不匹配。
并非所有已掌握的样本都同样有价值。有些轻易获得成功,另一些则接近决策边界、模型较为不确定。为识别这些“临界”样本,研究者计算困惑度 (Perplexity, PPL) :
\[ PPL_{(\mathcal{T},c_t)} = \exp\left(-\frac{1}{L}\sum_{i=1}^{L}\log p_{\theta}(o_i \mid \mathcal{T}, c_t, o_{1:i-1})\right) \]高 PPL 值表示不确定性。这些样本与失败案例一起被保留用于分析,而简单样本则被丢弃,以使后续训练更集中、高效。
第 3 步: 判别指导的标签验证 (JGLV)
合成数据常含噪声或错误标签。LoopTool 通过判别模型 (如开源的 Qwen3-32B) 比较模型预测与参考标签,客观决定哪个更优。
判别结果分为:
- PRED_WRONG: 模型预测错误。
- LABEL_WRONG: 原标签错误,模型预测更好。
- BOTH_CORRECT / BOTH_WRONG: 其他不具信息的情况。
据此得到两个精炼集合:
\[ \mathcal{D}_{j}^{PW} = \{(\mathcal{T}, c_t, a_t^*, a_t) \mid y_{\text{judge}} = \text{PRED_WRONG}\} \]\[ \mathcal{D}_{j}^{LW} = \{(\mathcal{T}, c_t, a_t^*, a_t) \mid y_{\text{judge}} = \text{LABEL_WRONG}\} \]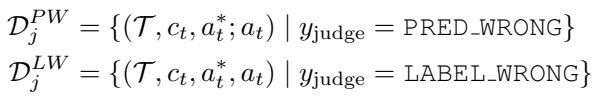
图 2: 根据判别模型的裁决对样本分类,区分真实的模型错误与标签修正。
在 LABEL_WRONG 情况下,LoopTool 用模型的修正输出替换错误标签,从而自动清洁数据集。随着训练循环,监督信号被逐步净化,模型持续从更加清晰、高质量的样本中学习,无需人工干预。
第 4 步: 错误驱动的数据扩展 (EDDE)
系统已经了解模型的弱项与错误来源。仅在错误上重新训练还不够。LoopTool 将验证后的失败样本当作种子,用于生成新的挑战性数据 。
生成器模型接收失败上下文、错误与正确的调用示例及简短错误分析,输出若干新样本。新样本保持原有困难点,但在内容上变化——如用户目标、领域或参数不同——以增强泛化能力。
这种错误驱动的数据扩展 (EDDE) 让数据集动态增长,准确聚焦模型的难点,同时保证多样性。
第 5 步: 闭环迭代
每轮结束后,LoopTool 将所有改进的数据源合并,形成下一轮训练语料:
\[ \mathcal{D}_{j+1} = \mathcal{D}_j^{ES} \cup \mathcal{D}_j^{EE} \cup \mathcal{D}_j^{HPPL} \cup \mathcal{D}_j^{Seed-new} \]这份合并语料包含修正样例、新生成的难题、高 PPL 样本以及部分未动的种子数据。随后模型再次进入 GRPO 训练,开启更挑战性、更干净的学习循环。每次迭代都让模型的推理、准确性与鲁棒性进一步提升。
实验结果: 真的有效吗?
研究者在 LoopTool 框架内训练了一个 Qwen3-8B 模型,并在两个行业标准基准上进行评测: BFCL-v3 和 ACEBench 。
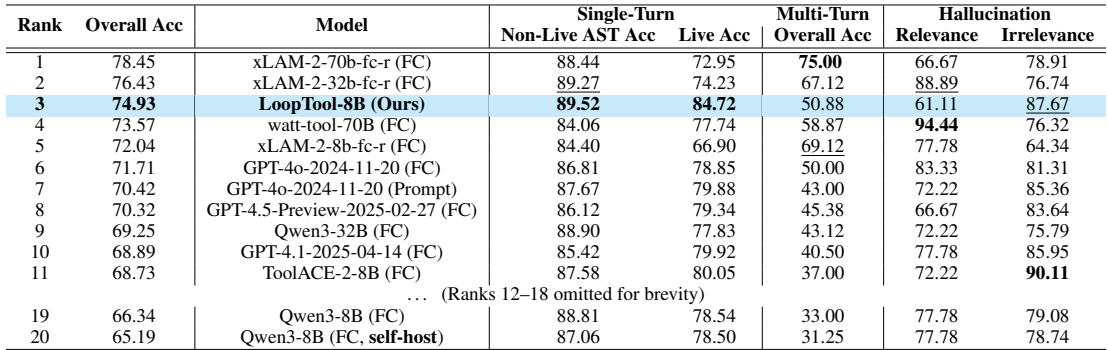
表 1: BFCL-v3 基准结果。LoopTool-8B 优于许多更大的模型。
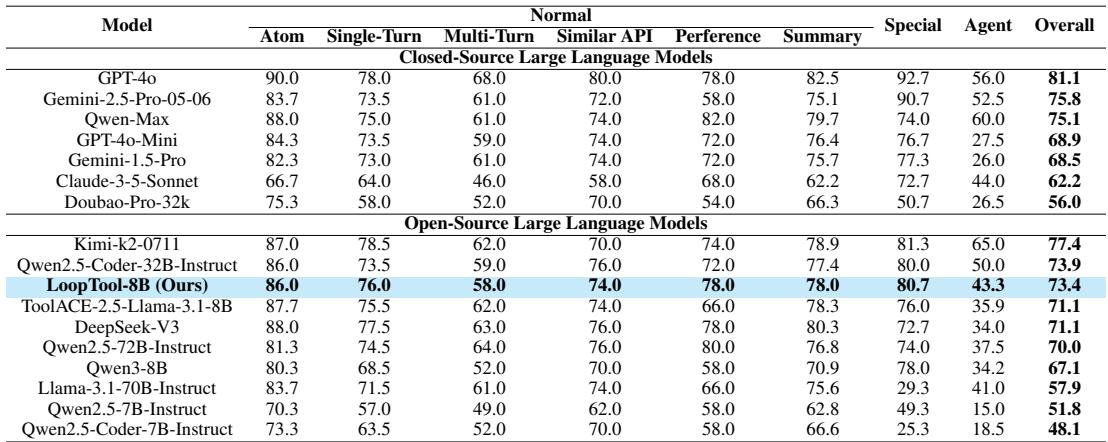
表 2: ACEBench 结果。LoopTool-8B 再次在 8B 规模模型中达成最优性能。
在两个基准中, LoopTool-8B 达到了该规模级别的最先进水平 , 超越了多款参数量是其四倍的模型。更令人惊讶的是,LoopTool-8B 甚至超越了 32B 的 Qwen3 模型——这个模型正是用于生成并评判其训练数据的“教师”。这证明闭环优化能够让学生模型的能力超越教师模型的规模限制。
迭代的力量
为证明迭代机制是性能提升的关键,团队比较了在开启和关闭自适应循环情况下,四轮训练的结果。
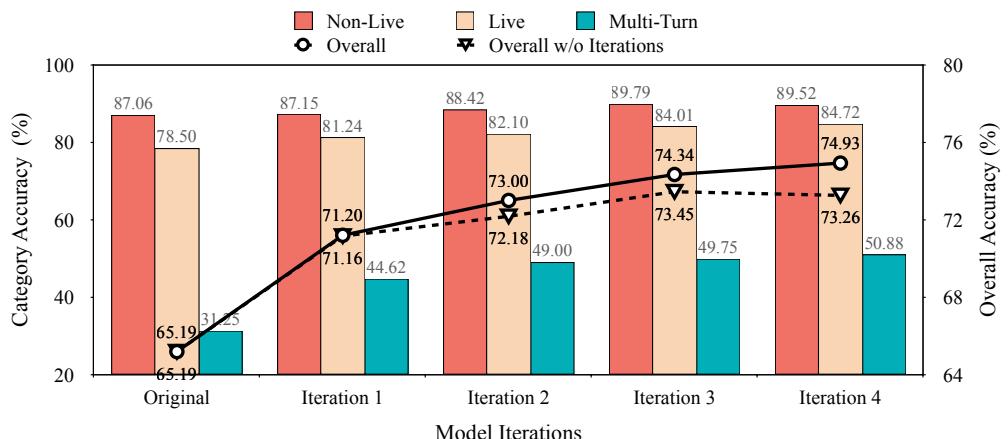
图 3: 在 BFCL-v3 上的迭代表现。LoopTool 的自适应训练曲线持续上升,而静态数据训练迅速出现停滞。
每次迭代都带来稳定的准确性提升。相比之下,使用相同种子数据的静态训练很快遇到瓶颈。没有自进化的数据课程,模型耗尽学习信号并开始过拟合——凸显动态反馈的重要性。
为什么每个组件都不可或缺
广泛的消融实验证实,LoopTool 的每个模块都发挥着关键作用。
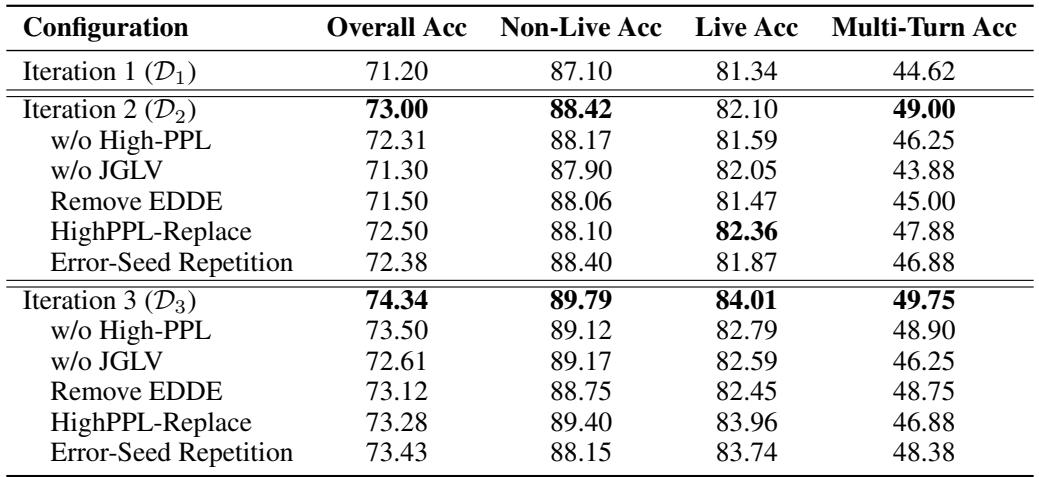
表 3: 消融研究结果。移除任何组件——如标签验证或数据扩展——均导致整体性能下降。
- 没有 JGLV (标签验证) : 准确率骤降,表明清理噪声标签对于保持高质量监督至关重要。
- 没有 EDDE (数据扩展) : 系统在复杂案例上的提升能力消失。单纯重复错误样本几乎无用,而 EDDE 生成的新样本使模型获得更广泛的泛化。
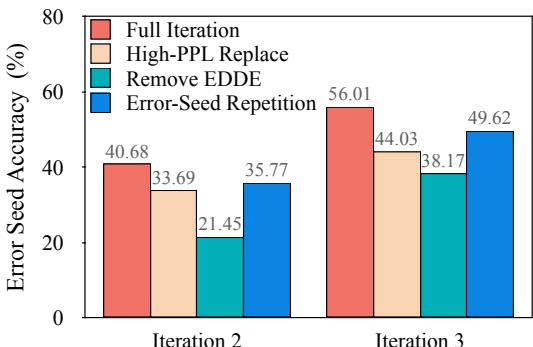
图 4: 针对原始“错误种子”样本的比较。包含 EDDE 的完整 LoopTool 配置 (红色) 在历史上困难的案例中实现最强恢复。
实验结果表明, LoopTool 的协同机制——诊断、纠正与针对性数据生成的结合——正是实现持续改进的关键 。
结论: 更智能、自校正的 AI 训练
LoopTool 标志着智能代理训练范式的转变。它不依赖静态、单向的流水线,而是构建了一个封闭的、自我精炼的生态体系 , 数据与模型共同进化。通过持续:
- 诊断弱点 (贪婪能力探测) ,
- 净化数据 (自动标签验证) ,
- 扩展覆盖 (错误驱动数据合成) ,
LoopTool 使得体量更小的模型能够超越传统方式训练的更大模型,提供了一条稳健且高效的路径,迈向更智能、更具适应性的 LLM。这一切完全基于开源工具实现。
LoopTool 的成功展示了人工智能的未来突破,或许不仅依赖于更大的模型和更多的数据,还取决于更聪明的训练循环——能够自我改进的系统。LoopTool 已闭合循环,也开启了真正自适应、自进化语言代理的新纪元。