](https://deep-paper.org/en/paper/2511.09515/images/cover.png)
想象一下,一个机器人能听懂你的指令: “拿起红色积木,放到蓝色积木上。” 这正是视觉-语言-动作 (VLA) 模型所承诺的未来——融合视觉、语言理解与物理控制的机器人技术新前沿。训练这类模型最常见的方法是模仿学习: 向机器人展示成千上万次人类示范的例子,让它模仿这些行为。
但当机器人出现小的失误时会怎样?如果遇到训练数据之外的情况,一个通过模仿学习训练出的策略可能会变得脆弱。它可能会持续用力推挤障碍物,或陷入循环无法恢复——因为它只知道如何复制成功,而不会从失败中学习。
强化学习 (RL) 提供了一个经典的解决思路。它让智能体通过试错学习,成功获得奖励,失败受到惩罚。然而,直接在现实中进行强化学习是个后勤噩梦: 需要数百万次交互,既耗时又昂贵,还可能危及机器人及周围环境。
那我们该如何赋予机器人强化学习的强大自我改进能力,却避免现实试验的高昂代价? 这正是最新研究论文 《WMPO: 基于世界模型的视觉-语言-动作模型策略优化》 所要解决的核心问题。研究者提出了一个令人着迷的方案——让机器人在想象中学习 。
通过训练一个能够模拟真实世界的高保真“世界模型”,机器人可以在虚拟环境中练习、犯错并从错误中学习,从而实现高效、可扩展且更加安全的训练。
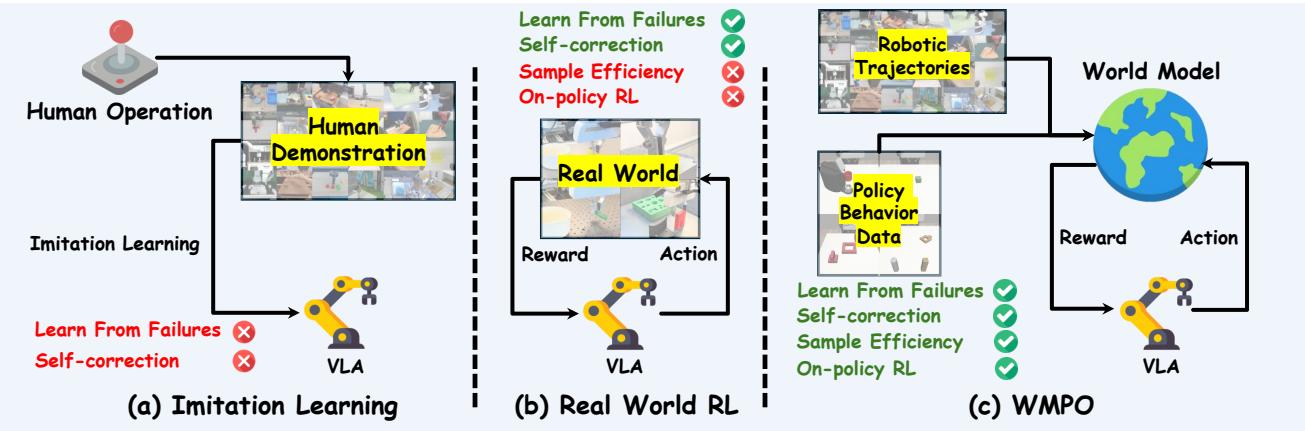
图 1. 三种 VLA 训练范式。WMPO 弥合了模仿学习与现实世界强化学习之间的鸿沟,使得在学习到的世界模型中可高效进行同策略学习。
挑战: 在模仿与交互之间
在深入了解 WMPO 的工作机制之前,让我们先梳理当前技术的格局。
视觉-语言-动作 (VLA) 模型。 VLA 模型将视觉输入和自然语言指令映射到机器人动作。通常基于大型视觉-语言基础模型构建,并在机器人轨迹数据集上微调。比如在获得“打开抽屉”的指令后,它会分析视觉场景并预测执行该动作所需的电机控制。尽管功能强大,但它们依赖模仿学习,因此在未遇见过的情况中往往表现不稳。
强化学习 (RL) 。 RL 通过交互帮助智能体学习。RL 策略通过探索来避免错误、从失败中恢复,并优化累计奖励。限制在于物理交互——每次试验都需消耗现实资源与时间,使得规模化几乎不可行。
世界模型。 世界模型学习预测环境在动作后的变化。给定当前的视频帧和动作,模型可以“想象”下一帧,从而实现虚拟实验。早期世界模型通常在潜在空间 (即压缩后的表示) 中运行。但在像素级视觉数据上预训练的 VLA 模型期望获得逼真图像而非抽象嵌入。 WMPO 的研究者认为,一个基于像素的视频世界模型是与预训练 VLA 保持一致性和兼容性的关键。
WMPO 框架: 在机器的想象中学习
WMPO 是一种完全在基于像素的、学习到的世界模型中进行策略优化的框架——类似于机器人版的 *《黑客帝国》 (Matrix) *。它作为一个闭环系统运作,其中策略模型与世界模型不断交互、自我改进。
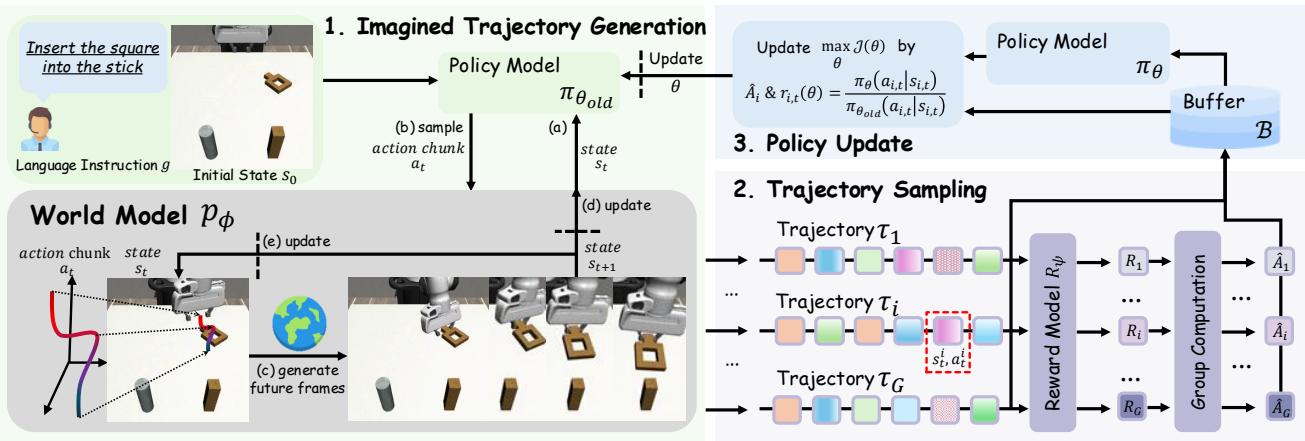
图 2. WMPO 的三部分循环: (1) 想象轨迹生成;(2) 通过奖励模型评估轨迹;(3) 根据成功与失败信号进行策略更新。
下面我们逐一解析这些组件。
1. 生成式世界模型: 梦境引擎
世界模型是整个系统的核心。它模拟机器人的世界——生成结合逼真视觉与合理动作的“想象”轨迹。
循环过程如下:
- 策略模型 \( \pi_{\theta} \) 接收最近的图像帧与语言指令作为输入。
- 它预测下一步的动作序列。
- 世界模型 \( p_{\phi} \) 使用这些动作与先前帧生成新的图像帧: \[ I_{i:i+K} \sim p_{\phi}(I_{i-c:i}, a_{i:i+K}) \]
- 重复此过程即可形成完整的想象轨迹,展示机器人与环境的交互过程。
为确保世界模型的稳健与真实,WMPO 引入了多个创新:
- 像素空间生成: WMPO 世界模型不使用低维潜在表示,而是通过二维 VAE 生成高分辨率图像,确保与 VLA 预训练的视觉数据一致。
- 带噪帧条件化: 自回归生成容易累积误差,导致模糊或漂移。训练时对输入帧施加轻微噪声,可提升模型对长序列误差的鲁棒性。
- 策略行为对齐: 世界模型首先用大规模数据 (Open X-Embodiment) 训练,再利用少量来自当前策略的轨迹进行微调。这样,它不仅学习了成功,还学习了策略可能产生的失败类型,从而能真实地“想象”成功与失败场景。
2. 奖励模型: 梦境裁判
为评估想象轨迹,WMPO 使用一个学习到的奖励模型 \( R_{\psi} \)。
该紧凑分类器无需人工标注数千视频,只需在中等规模真实数据集上训练,用于区分成功与失败片段。在 WMPO 训练时,它会审查每条想象轨迹并给予稀疏奖励——成功为 1,失败为 0。
这一自动化信号高效地引导策略学习,减少了昂贵的人工监督。
3. 同策略强化学习: 从想象中学习
一旦轨迹可被模拟与评估,策略优化随之展开。WMPO 解决了两个主要强化学习瓶颈:
- 物理交互瓶颈: WMPO 将训练完全放在世界模型中,无需真实机器人操作——避免了磨损与风险。
- 异策略偏差: 传统 RL 常使用异策略数据,易造成不稳定的价值估计。WMPO 的想象环境允许使用组相对策略优化 (GRPO) 算法进行同策略训练。
GRPO 循环的关键过程包括:
- 轨迹采样: 从同一初始状态生成多条想象轨迹。世界模型能复现完全相同场景——物理环境中无法做到。为确保学习平衡,WMPO 采用动态采样: 若所有轨迹均成功或均失败,则重新采样。
- 策略更新: 调整策略以提高导致成功的动作概率,降低导致失败的动作概率。其数学形式如下: \[ \mathcal{J}(\theta) = \mathbb{E}\bigg[\frac{1}{G} \sum_{i=1}^{G}\frac{1}{T} \sum_{t=0}^{T} \min\!\left(r_{i,t}(\theta)\hat{A}_i, \text{clip}(r_{i,t}(\theta))\hat{A}_i\right)\bigg] \] 其中 \(r_{i,t}(\theta)=\frac{\pi_{\theta}(a_{i,t}\mid s_{i,t})}{\pi_{\theta_{\text{old}}}(a_{i,t}\mid s_{i,t})}\), \( \hat{A}_i=\frac{R_i-\text{mean}(\{R_i\})}{\text{std}(\{R_i\})} \)。
从概念上看: 若轨迹结果优于平均值,策略会强化对应动作;若较差,则削弱。裁剪项确保更新稳定。
梦境训练真的有效吗?实验结果
研究者在模拟环境和真实机器人上验证了 WMPO 的效果——结果令人印象深刻。
卓越性能与样本效率
在四项操作任务的模拟基准上,WMPO 与在线 GRPO (在真实环境中训练的 RL) 及离线 DPO (基于偏好的方法) 进行了比较。
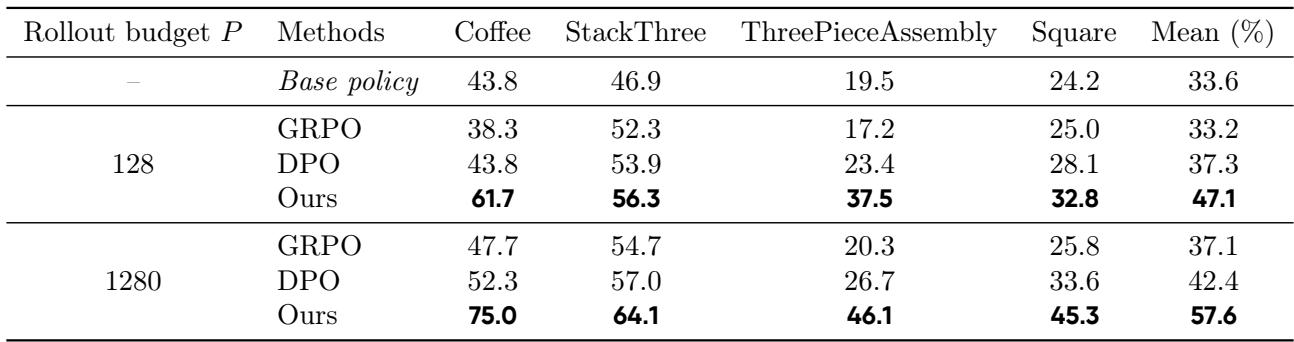
表 1. WMPO 使用显著更少的真实轨迹就实现了更高的成功率,证明了其样本效率与可扩展性。
即使仅使用 128 条真实轨迹微调世界模型,WMPO 的表现就比最佳基线高出近 10 个百分点。当 rollout 数提升至 1280 条时,其优势进一步扩大——表明 WMPO 能随数据量增长高效扩展。
涌现的自我纠正能力
除了性能提升外,WMPO 训练出的策略还展现了训练演示中没有的新行为——尤其是自我纠正。
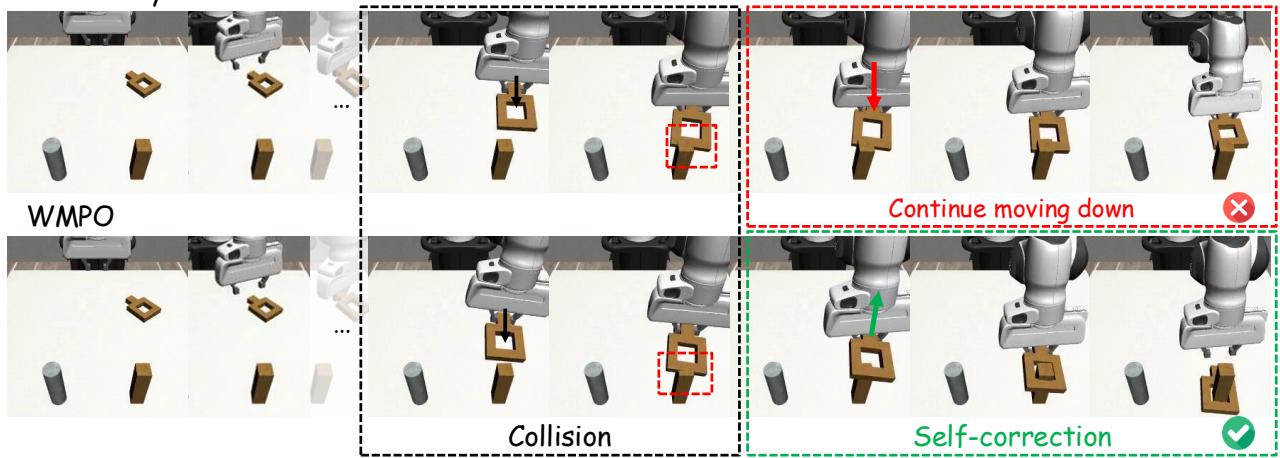
图 3. 经过 WMPO 训练的机器人能预测到碰撞,将积木抬起、重新对准,最终成功完成任务——展现了学到的自我纠正能力。
例如,在“方块”插入任务中,模仿学习策略会继续推挤障碍物直到失败。而 WMPO 策略,因曾“想象”过类似失败,会抬起、重新校准并成功插入。这种涌现的适应性标志着向真正学习迈出重要一步。
此外,WMPO 训练出的策略在执行任务时更加流畅与高效。
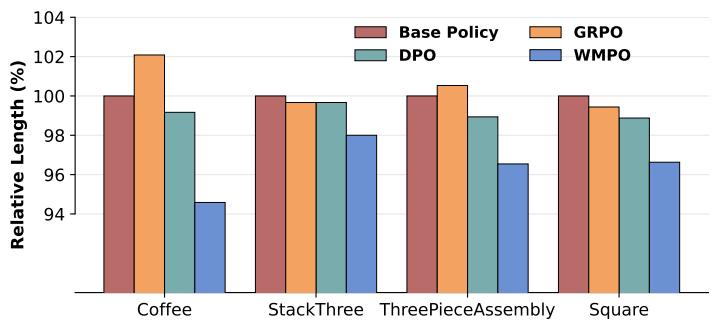
图 5. WMPO 的成功轨迹更短、更高效,说明“卡住”现象明显减少。
泛化能力与终身学习
一个强健的机器人策略应具备超越训练条件的泛化能力。WMPO 在位置信息、背景与纹理变化的测试下均表现稳定。
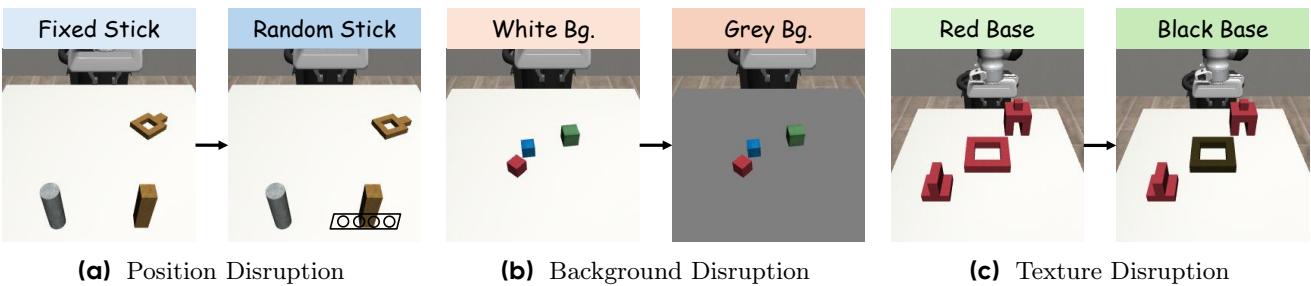
图 4. WMPO 在不同扰动条件下保持稳定性能,展现出强大的泛化能力。
与基线方法在未见背景或表面下性能明显下降不同,WMPO 维持了较高成功率——这证明了其“在梦中学习”衍生出可迁移技能。
此外,WMPO 支持终身学习 。 在部署后,机器人可利用自身新经验进行数据采集,重新训练世界模型并持续优化策略。实验显示,该迭代过程能不断提升性能,而 DPO 等方法则趋于不稳定。
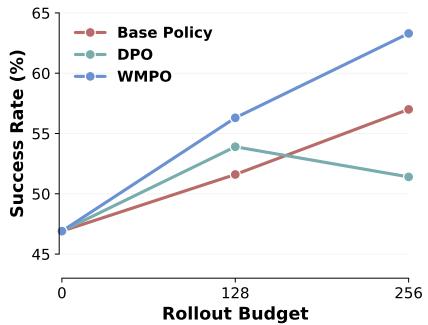
图 6. WMPO 的迭代改进证明了其可连续从新数据中学习的能力。
现实世界成功案例
最后,研究者在真实机器人上测试了 WMPO,执行挑战性任务——将方块插入棍子,间隙仅 5 毫米。

图 7. 世界模型从相同初始状态准确预测了真实世界的任务动态。
即使训练时未见过这些动作,世界模型的预测仍与真实物理运动高度一致。经 WMPO 训练后,真实任务成功率从 53% (模仿学习) 与 60% (离线 DPO) 跃升至 70%——验证了该框架的实用性。
结论: 教机器人从失败中学习
WMPO 代表了一种全新的机器人学习范式——连接模仿与真实交互的桥梁。 通过基于高保真像素级生成世界模型的同策略强化学习,它让 VLA 系统能从想象中的成功与失败中学习。
其核心创新——策略行为对齐实现逼真想象、稳健的自回归视频生成以及高效的同策略优化——在无需昂贵现实实验的前提下打破解锁了可扩展的自我提升。
简而言之,WMPO 让机器人能够在梦中训练 , 允许它们犯错、自我纠正,并不断成长和学习——就像人类一样。