](https://deep-paper.org/en/paper/3322_tllc_transfer_learning_ba-1610/images/cover.png)
引言
在深度学习时代,数据就是新的石油。但如果没有准确的标签,原始数据就毫无用处。虽然我们很希望让领域专家来标注每一张图片或每一份文档,但这通常极其昂贵且缓慢。于是众包 (Crowdsourcing) 应运而生: 这种方法将任务分发给大量的非专家工人 (例如在 Amazon Mechanical Turk 上) 。
众包具有成本效益,但它带来了两个令人头疼的主要问题:
- 噪声 (Noise) : 众包工人会犯错。
- 稀疏性 (Sparsity) : 工人通常只回答了可用问题中的极小一部分。
为了处理噪声,我们通常使用标签聚合 (Label Aggregation) (投票机制) 来从多个工人的结果中推断出真实标签。然而,当数据稀疏时,聚合算法就会陷入困境。如果一张特定的图片只有一两个不可靠的工人进行过标注,多数投票法就会失效。
这就引出了标签补全 (Label Completion) ——这是一个预处理步骤,我们尝试在聚合投票之前,智能地“填补”标签矩阵中的空白。
在这篇文章中,我们将深入探讨一篇 2025 年的论文,题为 “TLLC: Transfer Learning-based Label Completion for Crowdsourcing” (TLLC: 面向众包的基于迁移学习的标签补全) 。 针对标签补全中的一个特定问题: 当一个工人几乎没有标注任何东西时,你如何对他的行为进行建模? 作者提出了一个巧妙的解决方案,那就是迁移学习 (Transfer Learning) 。
问题: 工人建模不充分
目前最先进的方法试图通过对每个工人的“个性”或可靠性进行建模来预测缺失的标签。如果我们知道工人 A 擅长识别狗但不擅长识别猫,我们就可以相应地加权他们的投票,或者预测他们可能会投出什么票。
然而,这陷入了一个“第二十二条军规”式的两难境地。要建立一个好的工人 A 的模型,我们需要大量来自他们的数据。但在现实场景中,工人通常只标注极少量的实例。这导致了工人建模不充分 (insufficient worker modeling) 。 模型无法捕捉到工人的特征,从而导致对缺失标签的预测效果很差。
解决方案: TLLC
研究人员提出了基于迁移学习的标签补全 (Transfer Learning-based Label Completion, TLLC) 。 其核心思想简单而强大: 与其从头开始为每个工人训练一个模型 (这会因缺乏数据而失败) ,我们不如先在来自整个人群的高置信度数据 (源域) 上训练一个“通用”模型。然后,我们将这个知识丰富的模型迁移到个体工人 (目标域) 身上并进行微调。
这使得模型能够从群体中学习通用特征,同时仍能适应个体工人的特定习惯。
TLLC 框架
让我们来看看 TLLC 方法的整体工作流程。
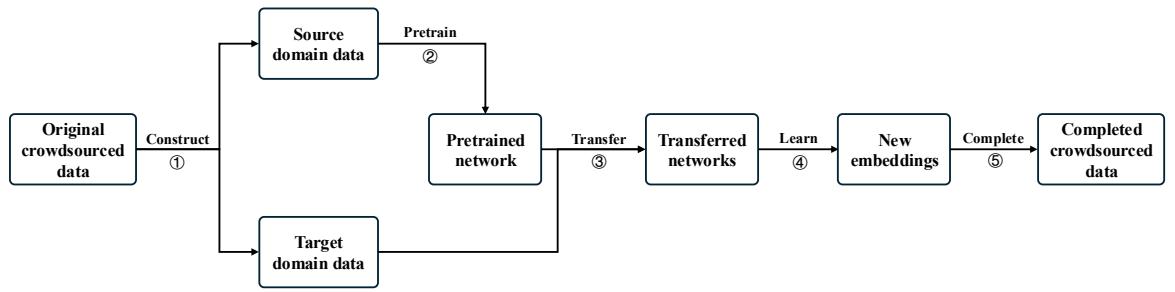
如图 1 所示,该过程分为五个明显的步骤:
- 构建 (Construct) 源域和目标域。
- 在源域上预训练 (Pretrain) 一个孪生网络 (Siamese network) 。
- 将网络迁移 (Transfer) 给特定工人。
- 学习 (Learn) 嵌入 (embeddings) 。
- 补全 (Complete) 缺失的标签。
让我们详细分解这些步骤。
第 1 步: 构建源域和目标域
在进行任何训练之前,我们需要整理数据。 目标域 (Target Domain) 很简单——就是特定工人标注的数据。
源域 (Source Domain) 则比较棘手。我们需要一个高质量的大型数据集来预训练我们的网络。但我们没有真实标签 (ground truth) ;我们只有充满噪声的众包投票。作者使用了一种受*置信学习 (confident learning) *启发的技术来过滤数据。
首先,他们计算实例的初始聚合标签 \(\hat{y}_i\) (通常是多数投票结果) 以及该标签的概率 (置信度) 。

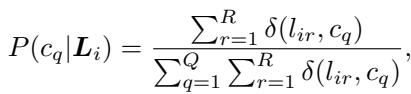
接下来,他们计算每个类别的平均置信度阈值 \(\mu\)。这设定了一个质量标准: 如果一张图片被标记为“猫”,其置信度分数是否高于所有“猫”图片的平均置信度?
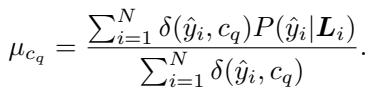
最后,他们通过仅保留置信度分数超过该类别平均阈值的实例来构建源域 (\(X_S\)) 。
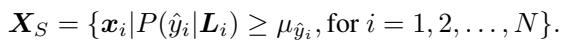
通过这样做,研究人员实际上创建了一个“银标准 (Silver Standard) ”数据集——它不是完美的真实标签,但是从人群中能获得的最高置信度的数据。
第 2 步和第 3 步: 通过孪生网络进行工人建模
有了数据之后,我们如何对工人进行建模?作者选择了孪生网络 (Siamese Network) 架构。
孪生网络旨在通过测量相似性来工作。它们接受两个输入并输出一个距离度量——如果两个图像具有相同的标签,网络就会学习将它们在嵌入空间中拉近。如果它们标签不同,网络就会将它们推远。
迁移学习的转折点:
- 预训练: 网络首先在高质量的源域上进行训练。由于这个数据集很大,网络可以学习到数据稳健的特征表示 (嵌入) 。
- 迁移与微调: 这个预训练网络的权重随后被复制到特定工人的网络中。然后,仅使用该特定工人标注的少数实例( 目标域 )对该网络进行微调。
这种方法解决了稀疏性问题。即使一个工人只标记了 5 个项目,由于经过了预训练,他们的特定模型也是建立在对数据的丰富理解之上的。
训练使用均方误差 (MSE) 损失函数来最小化两个项目的预测距离与其实际关系 (相同类别为 0,不同类别为 1) 之间的差异。
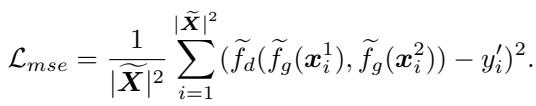
第 4 步和第 5 步: 标签补全
一旦工人特定的网络训练完成,它就可以为任何实例生成一个新的嵌入向量 (记为 \(z\)) 。
为了预测工人的缺失标签:
- 作者计算该工人标记为类别 A、类别 B 等的所有实例的质心 (平均位置) 。
- 他们在这些质心周围定义了一个“安全半径” (平均距离) 。
- 对于一个未标记的实例,他们将其映射到这个空间中。
如果未标记的实例落入特定类别的质心附近 (距离小于计算出的平均距离) ,算法就会将该标签分配给该实例。
补全的正式条件为:
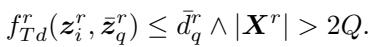
在这里,实例 \(z_i\) 与类别质心 \(\bar{z}_q\) 之间的距离必须小于阈值 \(\bar{d}_q\)。
实验与结果
为了证明这种方法的有效性,作者将 TLLC 与最先进的基准方法进行了测试,其中包括一种称为 WSLC (基于工人相似度的标签补全) 的方法。他们使用了真实世界的数据集: Income (二分类) 、Leaves (6 分类) 和 Music_genre (10 分类) 。
它能提高准确率吗?
主要指标是聚合准确率 (Aggregation Accuracy) ——在使用 TLLC 填充缺失标签后,我们能多准确地确定真实标签?
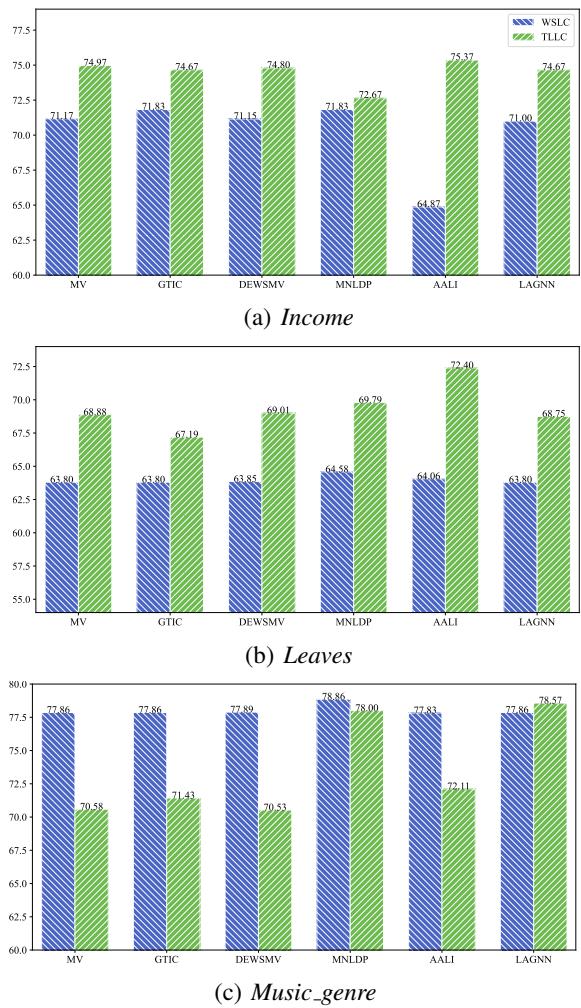
如图 2 所示,TLLC (绿色/条纹柱) 始终优于或持平于基准 WSLC (蓝色柱) 。
- Income 和 Leaves: TLLC 在几乎所有的聚合方法 (MV, GTIC 等) 上都显示出显著的改进。
- Music_genre: 表现具有竞争力,尽管差距较小。
为什么迁移学习很重要?
论文中最有力的证据是嵌入的可视化。作者选取了一位标注实例非常少的工人,并可视化了在使用和不使用迁移学习的情况下,网络是如何“看待”数据的。
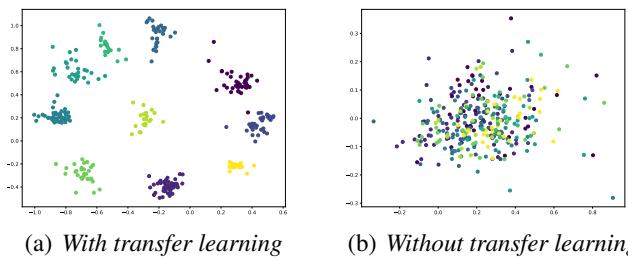
- 右图 (无迁移学习) : 数据点是一团混乱。模型没有看到足够的数据来区分各个类别。
- 左图 (有迁移学习) : 类别 (颜色) 清晰且聚类分明。尽管这位特定的工人提供的数据很少,但预训练使模型能够理解数据集的结构。
保留工人特征
标签补全的一个风险是“同质化”——让每个工人看起来都像平均水平。然而,有效的众包依赖于多样性。
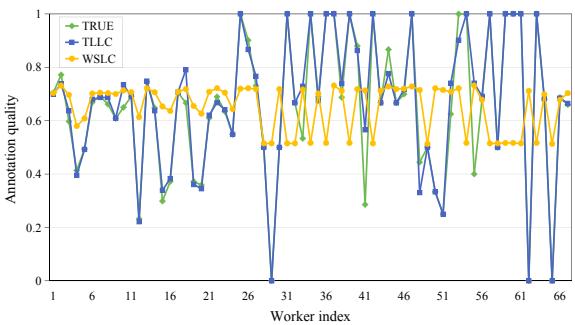
图 6 展示了工人的标注质量。橙色线 (WSLC) 表明基准方法倾向于拉平曲线,使糟糕的工人看起来更好,好的工人看起来更差——它将他们平均化了。蓝色线 (TLLC) 更接近绿色线 (真实质量) ,这意味着 TLLC 在填充缺失数据的同时,尊重了每个工人的独特能力水平。
结论
TLLC 方法解决了众包中的一个关键空白: 无法对那些尚未完成足够工作的工人进行建模。通过将集体的高置信度数据作为源域 , 将个体工人作为目标域 , 研究人员成功应用迁移学习稳定了这一过程。
核心要点:
- 不要从零开始: 在稀疏数据环境中,利用全局数据集为个体预训练模型。
- 先过滤: 使用置信学习来创建一个干净的源域对于有效的预训练至关重要。
- 嵌入很有效: 孪生网络允许我们要基于几何相似性来补全标签,这通常比单纯的概率更稳健。
这项研究为更高效的众包平台铺平了道路,这些平台可以用更少的标注获得准确的结果,从而节省时间和金钱。