](https://deep-paper.org/en/paper/3607_videorope_what_makes_for_-1874/images/cover.png)
近年来,大型语言模型 (LLM) 的能力呈爆炸式增长,这主要归功于它们处理海量文本的能力。然而,当我们从文本转向视频时,撞上了一堵新墙。视频不仅仅是“带图片的文字”,它是一种复杂的立体媒介,结合了空间细节 (画面中发生了什么) 与时间进程 (什么时候发生的) 。
大多数当前的视频 LLM 试图直接将基于文本的技术调整用于视频,结果往往参差不齐。在这个适配过程中,最关键的组件就是位置嵌入 (Position Embedding) ——即模型如何知道某条信息位于“何处”。
在这篇文章中,我们将深入探讨 VideoRoPE , 这篇研究论文从根本上重新思考了我们如何在视频数据中编码位置。我们将探讨为什么现有方法在视频变长或内容重复时会失效,以及一种新的 3D 架构方法如何解决这些问题,从而在视频理解和检索方面取得最先进的结果。
挑战: 从文本到视频
要理解 VideoRoPE,我们首先需要了解它所改进的机制: 旋转位置嵌入 (Rotary Position Embedding, RoPE) 。
在 Transformer (GPT、LLaMA 和 Qwen 背后的架构) 的世界里,模型是并行处理 Token (词元) 的。如果没有位置嵌入,模型就不知道“dog”这个词是在“bites”之前还是之后。RoPE 通过在几何空间中旋转 Token 的嵌入来解决这个问题。旋转的角度对应于 Token 的位置。
Vanilla RoPE 的局限性
原始的 RoPE (Vanilla RoPE) 是为一维序列 (如文本行) 设计的。当研究人员开始构建视频 LLM 时,他们面临一个选择:
- 展平视频: 将视频帧视为一长串的一维 Token。这会破坏像素之间的空间关系 (垂直和水平邻居) 。
- 3D RoPE: 尝试分别编码时间 (\(t\))、高度 (\(y\)) 和宽度 (\(x\))。
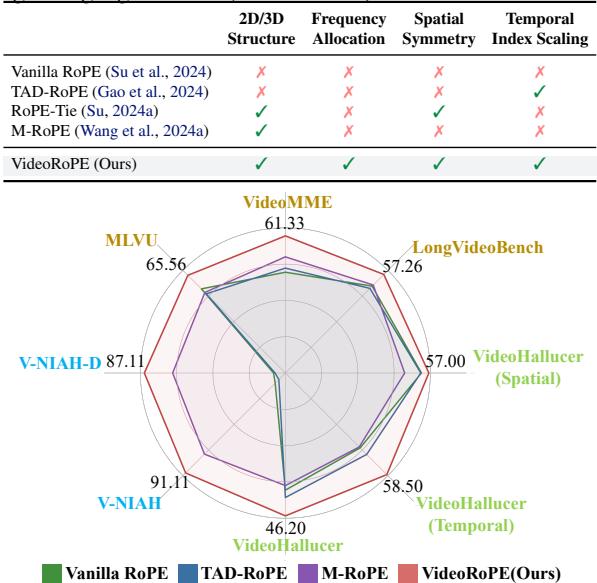
虽然像 M-RoPE (用于 Qwen2-VL) 这样的 3D 方法朝着正确的方向迈出了一步,但它们在数学上存在细微但致命的缺陷。如下面的对比所示,现有方法无法满足稳健视频建模所需的所有特征: 3D 结构、正确的频率分配、空间对称性和索引缩放。

VideoRoPE 的作者发现,仅仅拆分维度是不够的。你必须决定哪些维度代表时间,哪些代表空间。如果选择错误,当面对重复的视觉数据时,你的模型就会变得“困惑”。
试金石: “干扰项”问题
为了证明现有方法存在缺陷,研究人员引入了一个新的、更难的基准测试: V-NIAH-D (Visual Needle-In-A-Haystack with Distractors,带干扰项的视觉大海捞针) 。
标准的“大海捞针”测试将特定图像 (针) 隐藏在长视频 (大海) 中,并要求模型找到它。大多数模型在这方面表现不错。然而,研究人员增加了一个变数: 干扰项 (Distractors) 。 他们插入了在语义上与“针”相似但在并不是正确目标的图像。
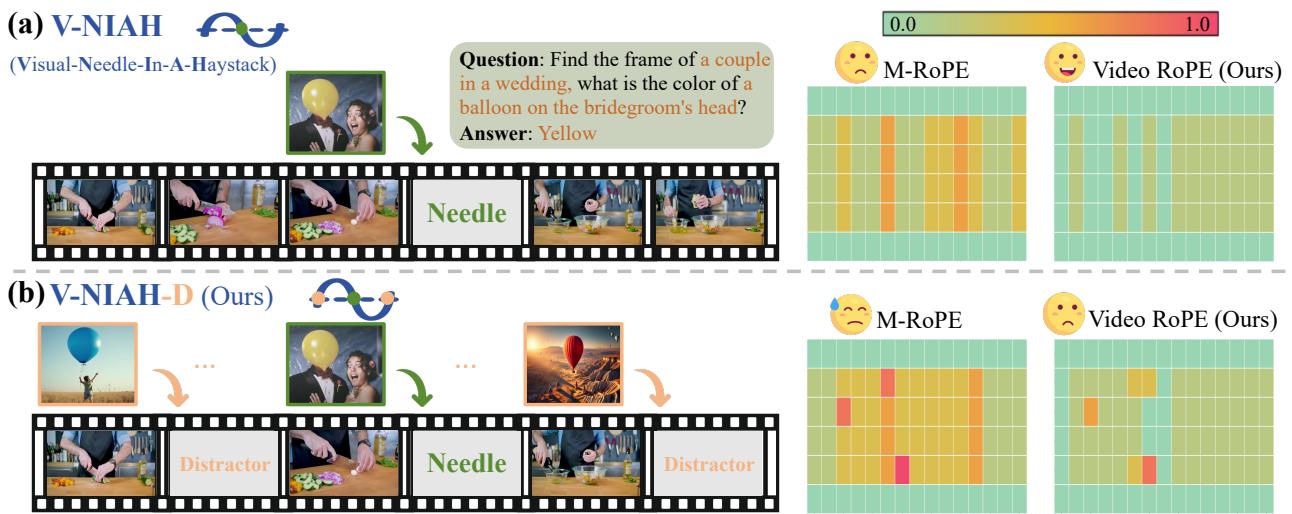
如上图所示,像 M-RoPE 这样的先前方法 (热力图中的第二行) 在标准任务 (a) 上表现尚可。但一旦引入干扰项 (b),它们的表现就会崩溃 (出现更多红色/橙色区域) 。
为什么?因为模型对“时间”的位置嵌入是周期性的。它在数学上将第 100 帧的“针”与第 1000 帧的“干扰项”混淆了,因为它们的位置编码看起来太相似了。这种现象在位置空间中被称为哈希冲突 (Hash collision) 。
故障分析: 为什么频率很重要
为了理解为什么会发生这些冲突,我们需要看看 RoPE 的数学原理。RoPE 以不同的频率旋转向量。
\[ A _ { t _ { 1 } , t _ { 2 } } = ( q _ { t _ { 1 } } R _ { t _ { 1 } } ) \left( k _ { t _ { 2 } } R _ { t _ { 2 } } \right) ^ { \top } = q _ { t _ { 1 } } R _ { \Delta t } \pmb { k } _ { t _ { 2 } } ^ { \top } , \]在一个标准的特征向量中 (例如大小为 \(d=128\)) ,所有维度并不都是平等的。
- 低维度 (索引 \(0, 1, 2...\)) 以高频旋转。它们转得非常快。
- 高维度 (索引 \(...126, 127\)) 以低频旋转。它们转得非常慢。
先前方法 (M-RoPE) 的问题: M-RoPE 将时间 (Temporal) 信息分配给了低维度 (前 16-32 个维度) 。这些维度旋转迅速。这意味着位置信号会很快重复自己 (振荡) 。如果你有一个长视频,“第 1 分钟”的位置嵌入在数学上可能看起来与“第 5 分钟”完全相同。
下面的可视化清晰地说明了这一故障。顶行 (M-RoPE) 将注意力集中在空间特征 (\(x, y\)) 而不是时间 (\(t\)) 上,当存在干扰项时,无法锁定正确的帧。
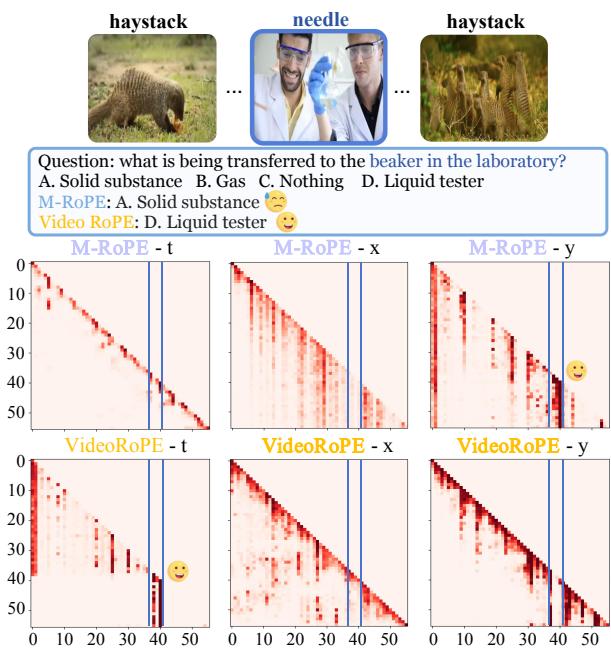
注意底部一行 (VideoRoPE) 。通过修正频率分配 (我们将在接下来详细说明) ,模型可以清晰地关注时间维度 (VideoRoPE-t) ,从而忽略干扰项。
核心方法: VideoRoPE
VideoRoPE 引入了一种 3D 位置嵌入策略,建立在旨在解决振荡、对称性和缩放问题的三大支柱之上。
1. 低频时间分配 (LTA)
VideoRoPE 最重要的贡献是反转了频率的剧本。VideoRoPE 没有使用高频 (低索引) 维度来表示时间,而是将时间分配给最高维度 (低频) 。
为什么这很重要?
- 高频 (低维度) : 适合局部细节,但波形重复得很快。
- 低频 (高维度) : 波形具有非常长的周期。在标准视频的背景下,它实际上永远不会重复。
通过将时间分量 \(t\) 移动到特征向量的末尾,VideoRoPE 确保位置嵌入随时间单调变化。第 1000 帧看起来与第 100 帧截然不同。
让我们看看频率波的 3D 可视化:
 上图: (a) M-RoPE 使用高频维度表示时间。注意那些“波纹”——这就是振荡。不同时间点的点获得了相同的值 (哈希冲突) 。
上图: (a) M-RoPE 使用高频维度表示时间。注意那些“波纹”——这就是振荡。不同时间点的点获得了相同的值 (哈希冲突) 。
 上图: (b) VideoRoPE 使用低频维度。表面光滑平坦。每一个时间点都有一个唯一的值。
上图: (b) VideoRoPE 使用低频维度。表面光滑平坦。每一个时间点都有一个唯一的值。
这一简单的改变消除了让先前模型易受干扰项影响的“哈希冲突”。
2. 用于空间对称性的对角布局 (DL)
第二个创新解决了我们如何相对于时间来组织空间维度 (\(x\) 和 \(y\)) 。
在像 M-RoPE 这样的先前方法中,视觉 Token 的索引与文本 Token 有些脱节。具体来说,M-RoPE 堆叠索引的方式会导致它们聚集在坐标系的角落。这造成了空间对称性 (Spatial Symmetry) 的缺失——视觉 Token 没有自然地承接在它们之前的文本 Token。
VideoRoPE 提出了一种对角布局 。 它不是重置索引或堆叠它们,而是沿着 3D 空间的对角线排列整个输入。
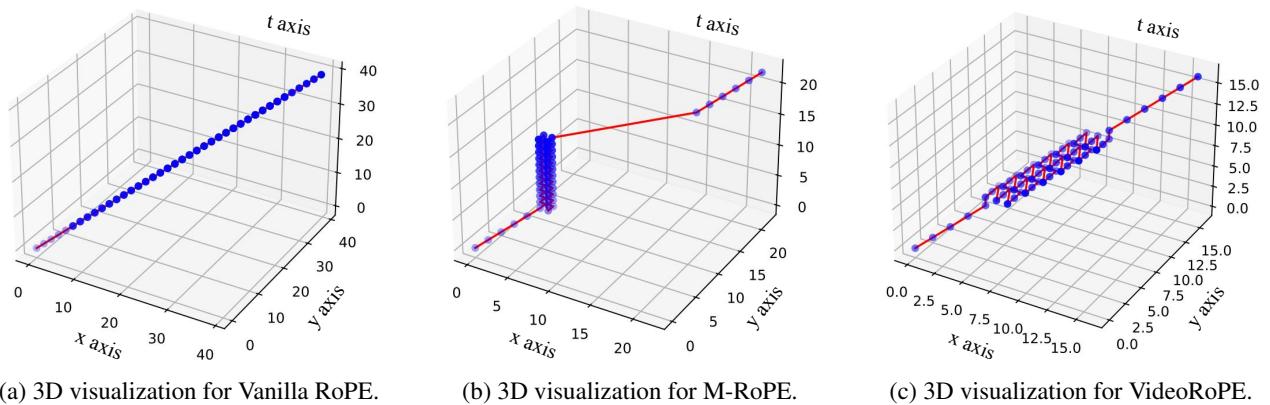
- (a) Vanilla RoPE: 一条直线 (1D) 。没有空间宽度。
- (b) M-RoPE: 注意垂直的“墙”。索引在某些方向停止增长,造成不自然的聚集。
- (c) VideoRoPE: 索引 (红点和蓝点) 沿着密集的对角路径延伸。
这种布局确保了任何两个视觉 Token 之间的相对位置得以保留,重要的是,文本提示结束与视频开始之间的“距离”是一致的。它模仿了文本 Token 的自然线性增长,同时保留了 3D 空间信息。
通过观察 Token 是如何交错的,这一点得到了进一步的可视化:
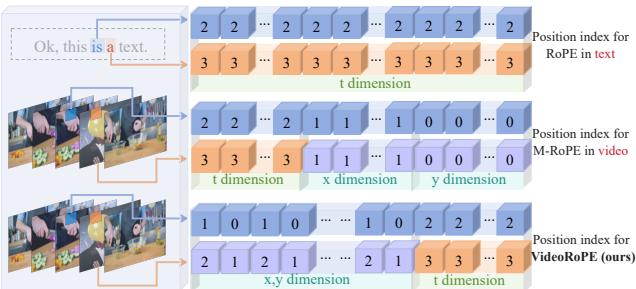
在底部一行 (VideoRoPE) 中,注意空间 (\(x,y\)) 和时间 (\(t\)) 设计是如何交错的,以保持一种对于最初在 1D 文本上训练的 Transformer 来说感觉“原生”的结构。
3. 可调节时间间隔 (ATS)
最后是粒度问题。文本序列中的一步 (一个单词) 在语义上并不等同于视频中的一步 (一帧) 。视频通常具有很高的冗余度;两个相邻的帧几乎相同,而两个相邻的单词通常不同。
VideoRoPE 引入了一个缩放因子 \(\delta\),以将视频帧索引与原始 Token 索引解耦。
\[ \begin{array}{c} \begin{array} { r } { ( t , x , y ) = \left\{ \begin{array} { l l } { ( \tau , \tau , \tau ) } & { \mathrm { i f ~ } 0 \leq \tau < T _ { s } } \\ { } \\ { } \\ { \left( T _ { s } + \delta ( \tau - T _ { s } ) , \right)} \\ { T _ { s } + \delta ( \tau - T _ { s } ) + w - \frac { W } { 2 } , } \\ { T _ { s } + \delta ( \tau - T _ { s } ) + h - \frac { H } { 2 } } \end{array} \right.} & { \mathrm { i f ~ } T _ { s } \leq \tau < T _ { s } + T _ { v } } \\ { } \\ { \left( \begin{array} { l } { \tau + ( \delta - 1 ) T _ { v } , } \\ { \tau + ( \delta - 1 ) T _ { v } , } \\ { \tau + ( \delta - 1 ) T _ { v } } \end{array} \right) } & { \mathrm { i f ~ } T _ { s } + T _ { v } \leq \tau < T _ { s } + T _ { v } + T _ { c } } \end{array} \end{array} \]这个公式可能看起来很吓人,但概念很简单:
- 起始文本: 使用标准索引。
- 视频: 将相对于起点的帧索引 ($ \tau - T_s \() 乘以 $\delta\)。这允许模型“拉伸”或“压缩”时间感知。
- 结束文本: 从视频结束的地方恢复线性索引。
这种解耦使得 VideoRoPE 能够处理不同帧率和长度的视频,而不会混淆模型的内部时钟。
实验与结果
这种理论上的重构真的有效吗?作者在多个基准测试中将 VideoRoPE 与 Vanilla RoPE、TAD-RoPE 和 M-RoPE 进行了对比测试。
长视频检索 (V-NIAH & V-NIAH-D)
最显著的结果来自检索任务。下面的热力图显示了不同上下文长度 (X 轴) 和帧深度 (Y 轴) 下的准确率 (绿色 = 100%,红色 = 0%) 。
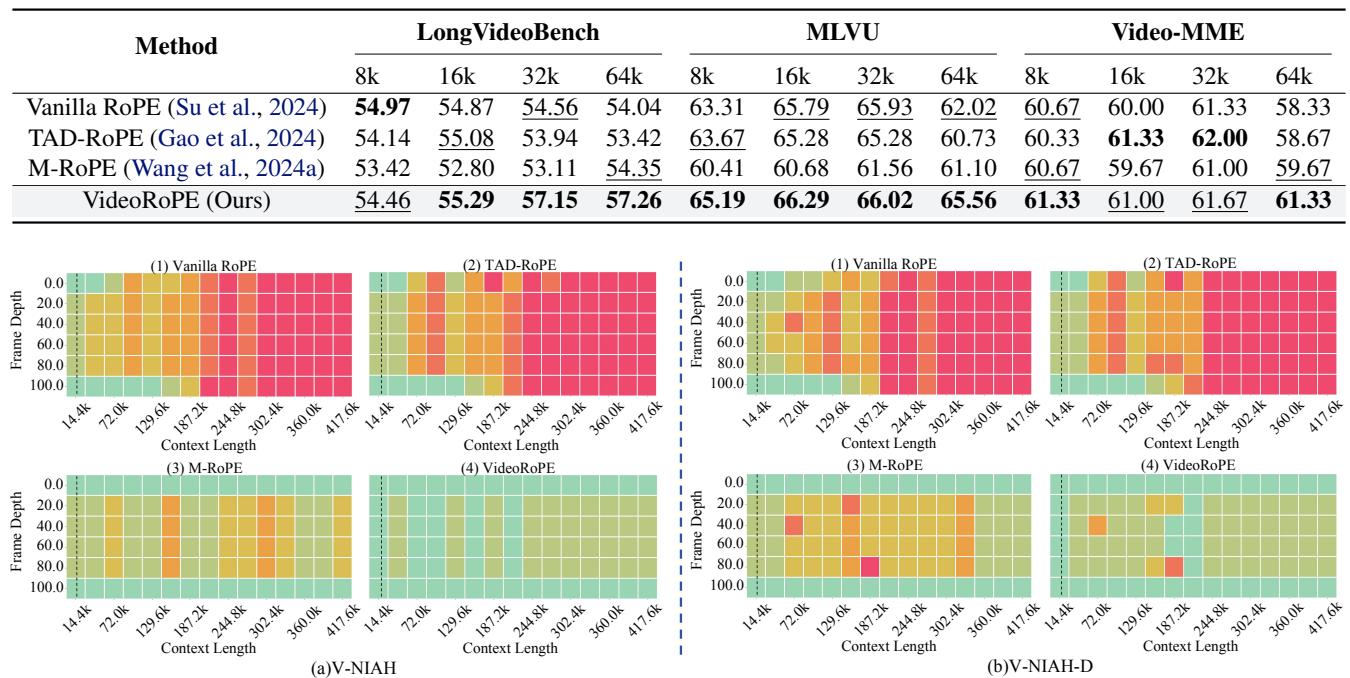
看部分 (b) V-NIAH-D (图表的底部一行) :
- Vanilla RoPE (1) & TAD-RoPE (2): 几乎全红。当存在干扰项时,它们无法找到针。
- M-RoPE (3): 稍好,但仍有明显的红色斑块,表明不稳定。
- VideoRoPE (4): 几乎全绿。它对干扰项具有鲁棒性,甚至在极端的上下文长度下也能有效工作。
定量数据支持了这一点:
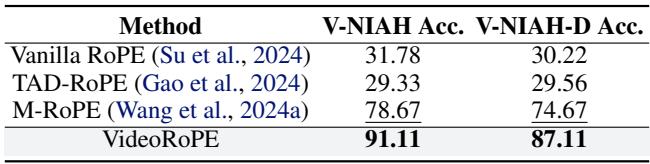
VideoRoPE 在困难的 V-NIAH-D 任务上达到了 87.11% 的准确率 , 相比之下, M-RoPE 仅为 74.67% , 而 Vanilla/TAD-RoPE 仅约为 30% 。
长视频理解
除了找到图像,模型还需要理解发生了什么。作者在 LongVideoBench 和 MLVU (多任务长视频理解) 等基准上进行了测试。
- (注: 请参考此图片的表格部分) *
VideoRoPE 在不同的上下文长度 (8k 到 64k) 下的得分始终更高 (以粗体标记) 。它表现出了特别的优势: 随着上下文长度的增加,它能保持性能,而其他方法往往会退化。
消融研究: 我们需要所有组件吗?
任何研究论文的一个关键部分是消融研究 (Ablation Study) ——移除系统的某些部分,看看它们是否真的是必要的。
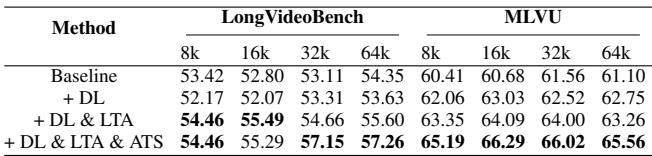
结果显示了阶梯式的提升:
- 基线 (M-RoPE): 得分 54.35。
- + 对角布局 (DL): 在某些指标上性能略有下降,但提高了稳定性。
- + DL & LTA (低频时间分配): 大幅跃升至 55.60。频率修正贡献最大。
- + DL & LTA & ATS (完整的 VideoRoPE): 最终跃升至 57.26。
这证实了对称性 (DL)、正确频率使用 (LTA) 和缩放 (ATS) 的结合对于获得最佳性能是必需的。
结论
VideoRoPE 代表了我们将大型语言模型适配到视频方面迈出的重要一步。这篇论文强调了一个微妙但深刻的教训: 数学很重要。 简单地将 3D 输入插入到 1D 或优化不佳的 3D 嵌入方案中,会引入无形的错误——振荡和冲突——从而在复杂性增加时混淆模型。
通过坚持四个关键原则——3D 结构、低频时间分配、空间对称性和可调节时间间隔——VideoRoPE 为下一代视频 LLM 提供了坚实的基础。它使模型能够清晰地“看到”时间,区分针和干扰项,无论视频变得多长。
随着我们迈向能够观看电影、分析监控录像或理解数小时实时交互的 AI 智能体,像 VideoRoPE 这样稳健的位置嵌入将是这一切成为可能的幕后引擎。