](https://deep-paper.org/en/paper/4280_better_to_teach_than_to_g-1734/images/cover.png)
引言: 授人以渔 vs. 授人以鱼
在深度学习的世界里,有一句古老的谚语出奇地贴切: “授人以鱼,不如授人以渔。”
在计算机视觉领域,特别是域泛化语义分割 (Domain Generalized Semantic Segmentation, DGSS) 中,“授人以鱼”类似于数据增强或生成合成数据。如果你想让你的自动驾驶汽车模型 (在晴朗天气的模拟器中训练) 能够识别雨天的街道,标准的做法是生成数千张雨天图像并将其喂给模型。虽然这在一定程度上有效,但它的计算成本很高,并且受限于你能生成的数据的多样性。
但是,如果我们能“教”模型理解场景的底层规律呢?如果模型能够理解“汽车出现在道路上”和“天空在建筑物上方”,无论图像看起来像照片、素描还是梵高的画作,那会怎样?
这就是论文 “Better to Teach than to Give” 中提出的新颖框架 QueryDiff 的前提。研究人员不再仅仅向模型提供更多数据,而是利用预训练扩散模型 (如 Stable Diffusion) 的巨大“大脑”来教导分割网络理解场景的底层结构。
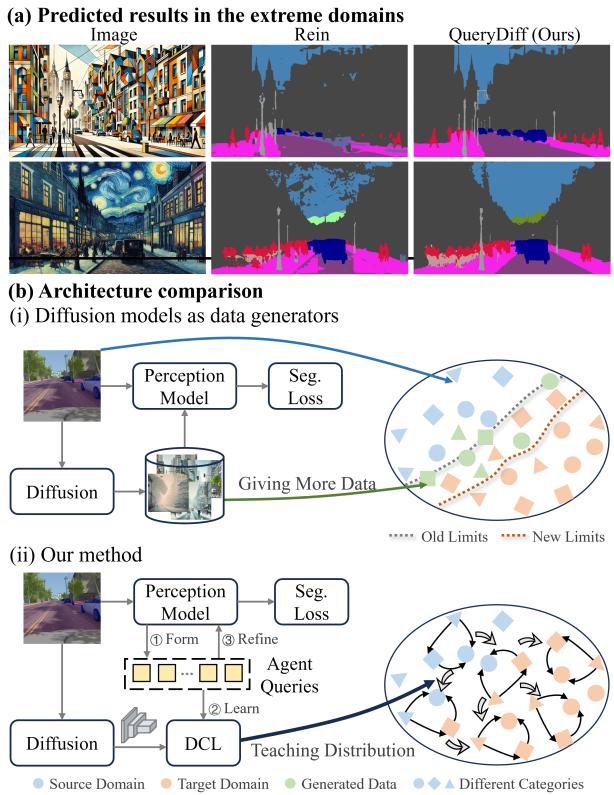
如图 1 所示,传统方法 (b-i) 将扩散模型用作数据生成器。QueryDiff (b-ii) 将扩散模型用作教师。结果如何?如部分 (a) 所示,QueryDiff 可以在极端域 (如立体主义艺术) 中有效地分割图像,而传统方法则难以做到。
在这篇文章中,我们将解读 QueryDiff 的工作原理,深入探讨其独特的架构、“代理查询 (Agent Queries) ”的概念,以及它是如何在不被艺术风格干扰的情况下从扩散模型中提取纯粹的语义知识的。
问题所在: 域泛化
语义分割是一项为图像中的每个像素分配类别标签 (汽车、道路、树木) 的任务。在有标签的源域 (如合成的 GTA5 视频游戏数据集) 上训练的模型,在未见过的目标域 (如真实的 Cityscapes 数据) 上测试时,通常会遭遇巨大的性能下降。
核心问题在于域偏移 (Domain Shift) 。 虽然内容是一致的 (车还是车) ,但风格 (光照、纹理、渲染质量) 却发生了剧烈变化。
大多数现有的解决方案依赖于域随机化 (Domain Randomization) ——改变训练数据的视觉外观以使模型具有鲁棒性。然而,这些方法往往无法捕捉到场景分布 : 即物体之间的空间关系和上下文依赖性。一辆车不仅仅是一个金属盒子;它是一个停在路上、通常位于天空下方的金属盒子。捕捉这种“场景先验”是实现鲁棒性的关键。
教师: 扩散模型
在深入探讨该方法之前,我们需要简要介绍一下扩散模型。这些生成式模型因能够根据文本提示创建高质量图像而闻名。它们的工作原理是逐渐向数据添加噪声 (前向过程) ,然后学习逆转该噪声以恢复图像 (反向过程) 。
前向过程定义为:
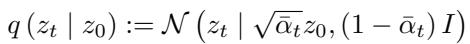
这里,\(z_0\) 是原始数据,\(z_t\) 是第 \(t\) 步的噪声数据。
模型学习的反向过程是:
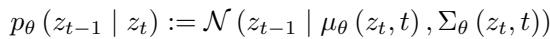
QueryDiff 的核心见解是,为了擅长生成图像,扩散模型必须隐式地学习强大的场景分布先验 。 它们知道物体属于哪里。然而,直接将扩散模型用于分割任务效率低下 (因为迭代采样很慢) 且充满噪声 (它们关注纹理/颜色,而分割模型应该忽略这些) 。
解决方案: QueryDiff 架构
研究人员提出了一个使用代理查询 (Agent Queries) 作为桥梁的框架。模型不是直接将扩散特征输入到分割网络中,而是创建“代理”去“询问”扩散模型以获取指导。
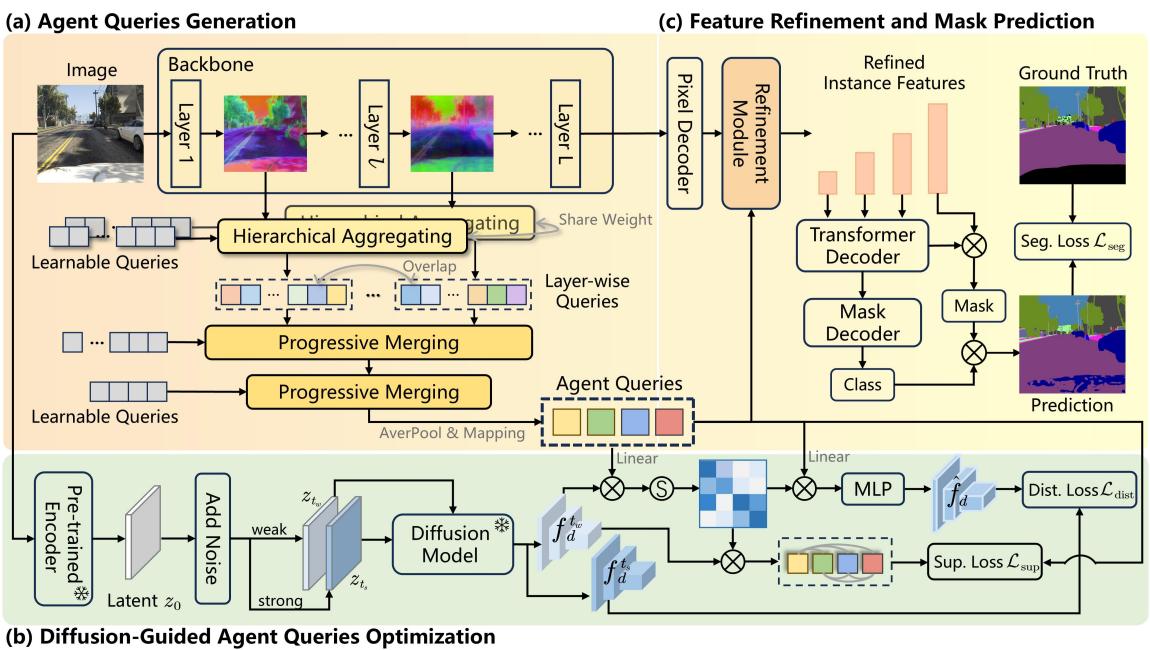
该架构包含三个主要阶段,如下图所示:
- 代理查询生成: 将图像特征压缩为查询向量。
- 扩散引导优化: 使用扩散模型来教导这些查询关于场景结构的知识。
- 特征细化: 使用受过教导的查询来改进分割。
让我们逐步拆解这些步骤。
1. 代理查询生成
第一个挑战是效率。我们不能为每个像素运行繁重的扩散过程。相反,QueryDiff 将来自分割骨干网络的信息聚合到一小组“代理查询”中。
该过程始于从骨干网络 (如 ResNet 或 MiT) 获取层级特征。对于特征层 \(l\),模型使用一组可学习参数 \(q_{init}\) 来提取层级查询:
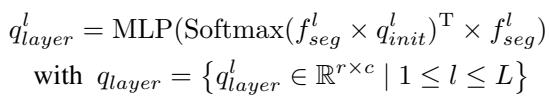
这些查询代表实例级信息 (例如,“我觉得我在这里看到了一辆车”) 。然而,神经网络的不同层看到的东西不同。为了统一这一点,作者使用了渐进式合并策略 。
他们使用类似于注意力的机制合并来自不同阶段的查询。可学习查询 \(q_{init}\) 充当查询 (Query, \(Q\)) ,而前一阶段的输出充当键 (Key, \(K\)) 和值 (Value, \(V\)) :
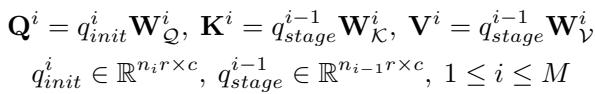
这些查询基于相似度进行合并:
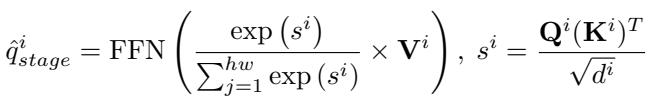
最后,在经过所有阶段后,我们得到了一组统一的代理查询 (\(q_{agent}\)):
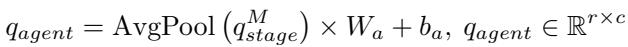
这些查询现在包含了图像中实例的压缩表示。它们准备好接受“教导”了。
2. 扩散引导优化
这是论文的核心贡献。我们希望将扩散模型的“智慧”注入到这些代理查询中。然而,扩散特征包含两种类型的信息:
- 场景分布 (语义) : “车在路上。” (对分割有益) 。
- 视觉外观 (风格) : “车是红色的且闪闪发光。” (对泛化不利) 。
为了分离这些信息,作者利用了扩散时间步的一个特性。
- 弱噪声 (\(t_w\)): 包含细粒度的细节 (纹理、颜色) 。
- 强噪声 (\(t_s\)): 包含粗粒度的语义 (形状、布局) 。
模型在两个噪声水平下提取特征:
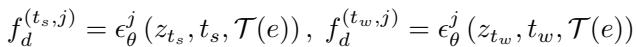
扩散一致性损失 (DCL)
目标是在不传递风格噪声的情况下传递语义知识。作者提出了一种巧妙的损失函数,称为扩散一致性损失 (Diffusion Consistency Loss, DCL) 。
首先,他们计算代理查询与弱噪声特征之间的相似度图。弱噪声特征具有我们需要定位物体的结构细节,但也包含我们想要忽略的风格。
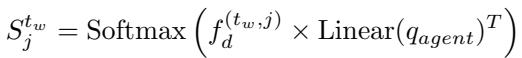
为了“清理”这个相似度图,他们强制它去重建强噪声特征。由于强噪声特征缺乏高频细节 (风格) ,强制重建结果与强噪声特征匹配,可以确保从弱噪声图中剥离掉“视觉细节”,只留下结构分布。
这是通过分布损失 (KL 散度) 强制执行的:
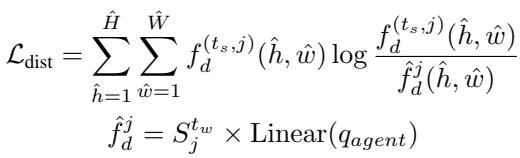
这里,\(\hat{f}_d\) 是重建的特征。如果相似度图 \(S\) 包含太多的“风格”信息,它就无法匹配“仅含结构”的强特征。
最后,使用这个“清理后”的语义图更新代理查询:
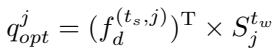
并进行监督以确保原始代理查询学习到这种分布:
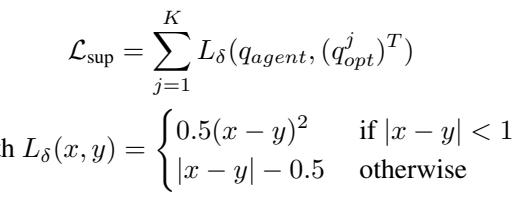
总的扩散一致性损失结合了监督和分布两个部分:
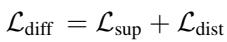
这个过程有效地将庞大扩散模型的场景理解能力“蒸馏”到了轻量级的代理查询中。
3. 特征细化与预测
现在我们有了理解场景结构的优化后的代理查询 , 我们利用它们来细化分割解码器中的像素级特征。
这是通过一个包含交叉注意力的细化模块完成的。然后,解码器生成掩膜 (masks) 和类别概率。最终的分割损失是交叉熵损失和 Dice 损失的标准组合:
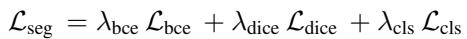
总训练目标结合了分割损失和扩散一致性损失:
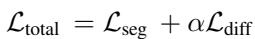
关键点: 在推理 (测试) 期间,扩散分支会被关闭。模型完全依赖于训练好的代理查询。这使得该方法在运行时非常高效。
实验与结果
作者在标准的域泛化基准上对 QueryDiff 进行了评估。经典的设置包括在合成数据 (GTA5) 上训练,并在真实世界数据集 (Cityscapes, BDD100K, Mapillary) 上测试。
定量性能
结果令人印象深刻。如表 1 所示,QueryDiff 在不同的骨干网络 (ResNet, MiT, DINOv2) 上均达到了最先进 (SOTA) 的性能。
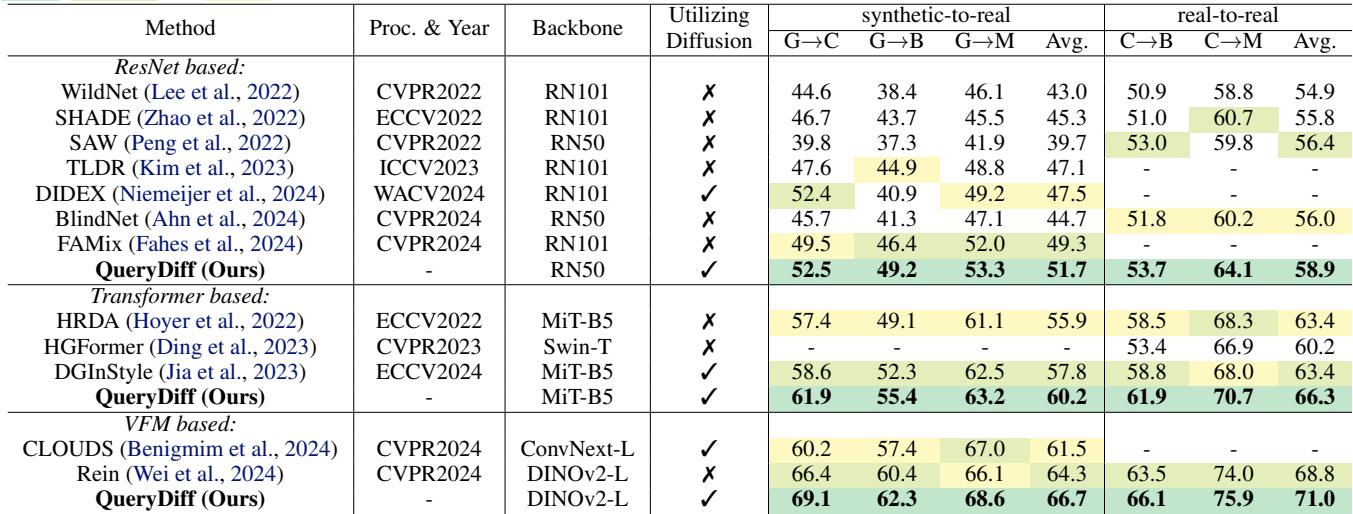
值得注意的结论:
- 在 GTA \(\to\) Cityscapes 任务中,使用 DINOv2 骨干网络,QueryDiff 达到了 69.1% mIoU , 显著优于之前的最佳方法 (Rein) 的 66.4%。
- 它始终优于那些单纯使用扩散模型进行数据生成的方法 (如 DIDEX) 。
对恶劣天气的鲁棒性
模型还在从正常天气到恶劣条件 (雾、雨、雪、夜间) 的泛化能力上进行了测试,使用的是 ACDC 数据集。
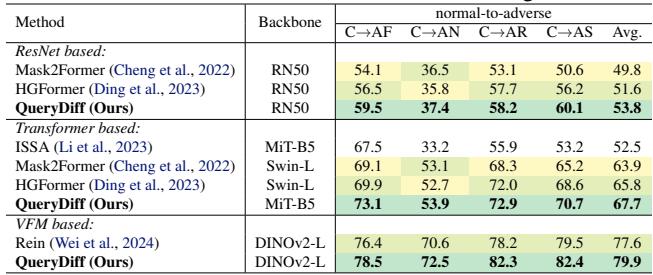
同样,QueryDiff 表现出了卓越的鲁棒性,证明了学习场景分布比以前的方法更能帮助模型看穿雨水和黑暗。
定性分析
定性结果展示了“教导”的效果。在图 4 中,对比 Rein (中间) 与 QueryDiff (右侧) 的预测结果。
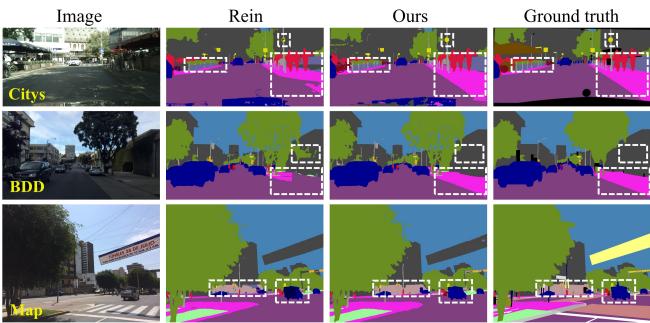
注意白色虚线框区域。QueryDiff 在复杂区域产生了更清晰的边界和更少的伪影,与真值 (Ground Truth) 非常接近。
此外,观察分类别的改进情况( 图 3 ),我们可以看到在骑行者 (Riders) 、摩托车 (Motorcycles) 和火车 (Trains) 等“困难”类别上有显著提升。

为什么有效? (消融实验)
作者进行了消融实验来验证他们的设计选择。
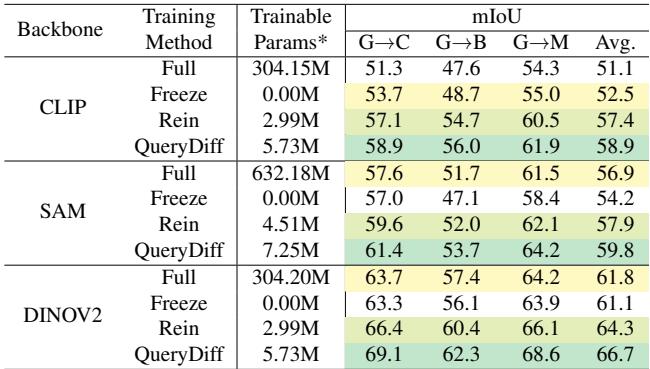
1. 我们需要所有组件吗? 是的。移除代理查询或特定的损失函数 (\(L_{sup}\), \(L_{dist}\)) 都会导致性能下降。

2. 基础模型重要吗? 无论骨干网络是 CLIP、SAM 还是 DINOv2,QueryDiff 都能提升性能。它有效地利用了这些巨型模型的预训练知识。
3. 扩散模型的选择重要吗? 有趣的是,不重要。如表 6 所示,使用 Stable Diffusion 1.4、1.5 或 2.1 产生的结果非常相似。这表明该方法是鲁棒的,并且捕捉到了存在于所有这些模型中的普遍场景先验。

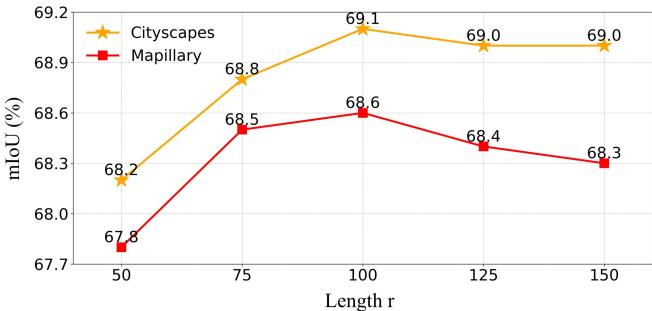
4. 需要多少个查询? 代理查询的“长度 \(r\)”指的是使用了多少个 token。 图 5 显示性能在 \(r=100\) 左右达到峰值。查询太少会丢失细节;太多则可能引入噪声。
结论
论文“Better to Teach than to Give”提出了域泛化领域的一个引人注目的转变。QueryDiff 不是通过生成无限变化的训练数据来强行解决问题 (“授人以鱼”) ,而是提取隐藏在扩散模型内部的深层结构化世界理解 (“授人以渔”) 。
通过使用代理查询作为轻量级接口,并使用扩散一致性损失过滤掉风格信息,QueryDiff 在语义分割上达到了最先进的结果。它使得在视频游戏中训练的模型能够导航现实世界的街道——即使这些街道被画成了立体主义风格。
这个框架不仅提高了准确性,还提高了效率,因为在训练后可以丢弃笨重的扩散模型,只留下一个更智能、更鲁棒的分割网络。