](https://deep-paper.org/en/paper/496_relational_invariant_learn-1773/images/cover.png)
走出实验室: 利用 AI 预测未知溶剂中的分子行为
在药物发现和材料科学领域,环境决定一切。一个在水中表现完美的分子,在乙醇或丙酮中可能会表现出完全不同的行为。这种现象被称为溶剂化 (solvation) , 它是化学和制药过程如何运作的核心。
预测溶剂化自由能——即溶质 (如药物分子) 溶解在溶剂中时的能量变化——是计算化学中的“圣杯”任务。如果我们能利用 AI 准确预测这一点,我们就可以在不进入湿实验室 (wet lab) 的情况下筛选数百万种候选药物。
然而,这里有个问题。大多数当前的 AI 模型都基于一个简化的假设: 未来会像过去一样。它们假设测试数据来自与训练数据相同的分布 (独立同分布,即 IID )。但在现实世界的化学中,我们经常遇到分布外 (Out-of-Distribution, OOD) 场景——即模型以前从未见过的新溶剂或新分子结构。当传统模型面对这些未知环境时,它们往往会惨遭失败。
本文将通过一篇名为 《用于鲁棒溶剂化自由能预测的关系不变学习》 (Relational Invariant Learning for Robust Solvation Free Energy Prediction) 的研究论文,深度解析其提出的RILOOD新框架。该框架旨在使 AI 足够鲁棒以应对这些化学环境的变化,确保即使溶剂发生改变,预测依然准确。
核心问题: “溶剂鸿沟”
为了理解其中的困难,我们需要了解传统的图神经网络 (GNN) 是如何处理分子预测的。通常,这些模型会在溶质分子中寻找模式——比如特定的环结构或官能团——并将该特征与某种性质相关联。
问题在于,这些相关性往往是虚假的 (spurious) 。 模型可能会因为“分子 X”在训练期间出现在特定溶剂中,就“学会”了它具有高溶剂化能。如果你把“分子 X”放入不同的溶剂中,这种相关性可能会被打破。模型是在死记硬背特定的上下文,而不是理解溶质与溶剂之间本质的相互作用。
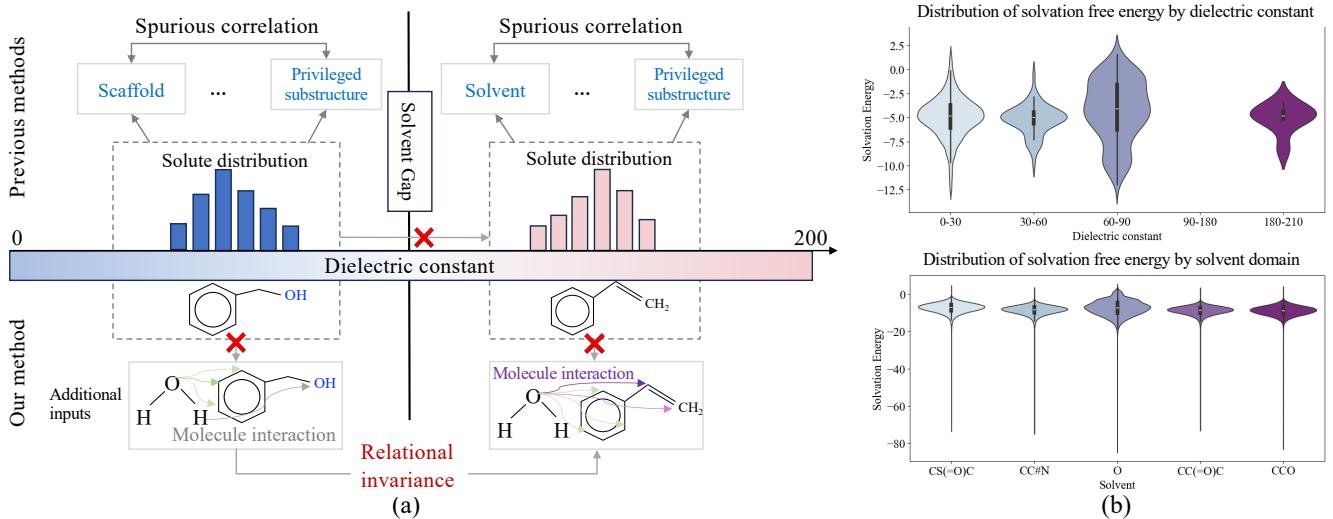
如图 1 所示,先前的方法 (左侧) 往往依赖于“优势子结构”。它们可能会看到一个苯酚基团,并根据过去的数据猜测能量。然而,随着介电常数 (衡量溶剂极性的指标) 的变化,“溶质分布”会发生剧烈变化 (虚线框所示) 。旧的相关性无法跨越“溶剂鸿沟”。
研究人员提出了一种方法 (图 1 右侧) ,专注于关系不变性 (Relational Invariance) 。 模型关注的是动态相互作用——如氢键和范德华力——这些作用无论在具体的溶剂环境中如何,都保持一致 (不变) 。
解决方案: RILOOD 框架
研究人员介绍了 RILOOD (面向分布外泛化的关系不变学习) 。这不仅仅是一个新的神经网络层;它是一个综合的学习策略,旨在剥离环境偏差,寻找支配溶剂化的“真实”物理规律。
该框架包含三个主要支柱:
- 基于 Mixup 增强的条件变分建模: 用于模拟多样化环境。
- 多粒度上下文感知细化: 用于捕获原子级和分子级的相互作用。
- 不变学习机制: 用于过滤虚假相关性。
在深入细节之前,让我们先看看高层架构。
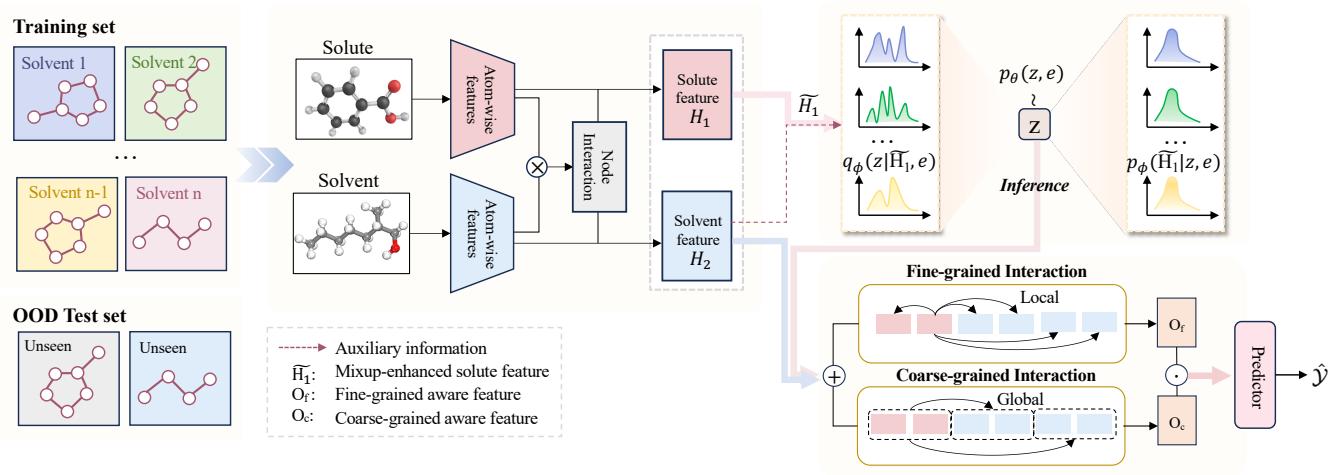
如图 2 所示,该模型以溶质和溶剂作为输入。它通过交互层处理它们,并利用辅助信息来创建鲁棒的预测。让我们来分解其工作机制。
1. 利用 Mixup 模拟多样化环境
OOD 泛化的最大挑战之一是,我们并不总能获得每个可能环境因素的明确标签。我们知道溶剂的名称,但我们可能没有数学标签来确切描述丙酮在每种情况下与乙醇有多么“不同”。
为了解决这个问题,作者使用了一种称为 Mixup 的技术。Mixup 是一种数据增强策略,通过混合两个现有的数据点来创建新的合成数据点。在这篇论文的背景下,他们混合了不同分子环境的表示。
生成混合分子表示 (\(\tilde{H}_1\)) 和混合环境标签 (\(e\)) 的公式如下:
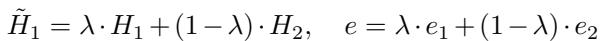
这里,\(\lambda\) (lambda) 是一个介于 0 和 1 之间的混合系数。这迫使模型学习环境的连续、平滑表示,而不是离散、僵化的类别。它允许模型在已知溶剂之间进行“插值”,使其能够更好地处理可能介于已训练溶剂之间的未知溶剂。
这种 Mixup 策略是条件变分自编码器 (CVAE) 的一部分。CVAE 的目标是在以环境为条件的情况下,推断溶质分子的潜在 (隐藏) 分布。通过优化这一点,模型学会了当环境改变时,分子的表示应该如何变化。
2. 多粒度上下文感知细化 (MCAR)
标准 GNN 通常非常关注局部原子相互作用——例如一个碳原子如何与附近的氧原子相互作用。虽然这很重要,但溶剂化是一种全局现象。整个溶剂会在溶质周围形成一个“场”。
MCAR 模块旨在捕获两个层面的相互作用:
- 细粒度 (局部) : 详细的原子间作用力。
- 粗粒度 (全局) : 整个溶质分子如何与溶剂环境相关联。
模型计算一个“上下文感知”表示,记为 \(H_c\)。它通过结合全局注意力机制 (关注长距离依赖) 和局部特征变换来实现这一点。
这种结合是通过粗粒度 (\(O_c\)) 和细粒度 (\(O_f\)) 特征的 Hadamard 积 (逐元素乘积) 来实现的:
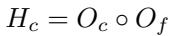
这确保了最终的表示既包含特定的化学细节,又包含准确预测溶剂化能量所需的更广泛的环境背景。
3. 不变关系学习
这是论文中理论性最强但可能也是最重要的部分。目标是学习一种不变 (invariant) 的表示。
在机器学习术语中,不变特征是指其与目标标签 (溶剂化能量) 的关系不会随环境 (溶剂) 改变而改变的特征。如果一个特征在水中与能量相关,但在 DMSO 中不相关,那就是一个“虚假”特征。如果它在两者中都相关,那它很可能是一个因果的、物理的特征。
为了实现这一点,研究人员利用互信息 (Mutual Information, MI) 最大化。他们希望最大化学习到的“不变”表示 (\(\widehat{H}_{inv}\)) 与标签之间的互信息,同时过滤掉噪声。
优化问题公式化为:
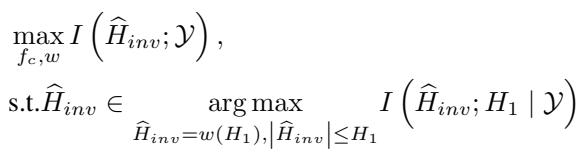
本质上,如果模型依赖于仅特定于一个训练环境的特征,它就会受到惩罚。如果它发现了普遍适用的相互作用“规则”,就会受到奖励。
总损失函数 (\(\mathcal{L}\)) 结合了预测误差 (\(\mathcal{L}_{inv}\))、环境建模损失 (\(\mathcal{L}_{MCVAE}\)) 和互信息约束 (\(\mathcal{L}_{MI}\)):
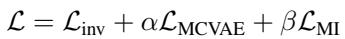
通过平衡这三个目标 (由权重 \(\alpha\) 和 \(\beta\) 控制) ,模型创建了一个准确、环境感知且具有化学鲁棒性的预测引擎。
实验结果
研究人员将 RILOOD 与几个最先进的基准模型进行了测试,包括标准 GNN (如 GCN 和 GAT) 和专门的分子关系学习模型 (如 CIGIN 和 MolMerger) 。
他们使用了 MNSolv 和 QM9Solv 等数据集,其中包含数千对溶质-溶剂对。关键在于,他们不仅仅是随机分割数据。他们进行了OOD 分割 :
- 溶剂分割 (Solvent Split) : 测试集包含训练期间从未见过的溶剂。
- 骨架分割 (Scaffold Split) : 测试集包含训练期间从未见过的分子结构 (骨架) 。
定量性能
结果令人信服。在下表中, RMSE (均方根误差) 作为指标——数值越低越好。
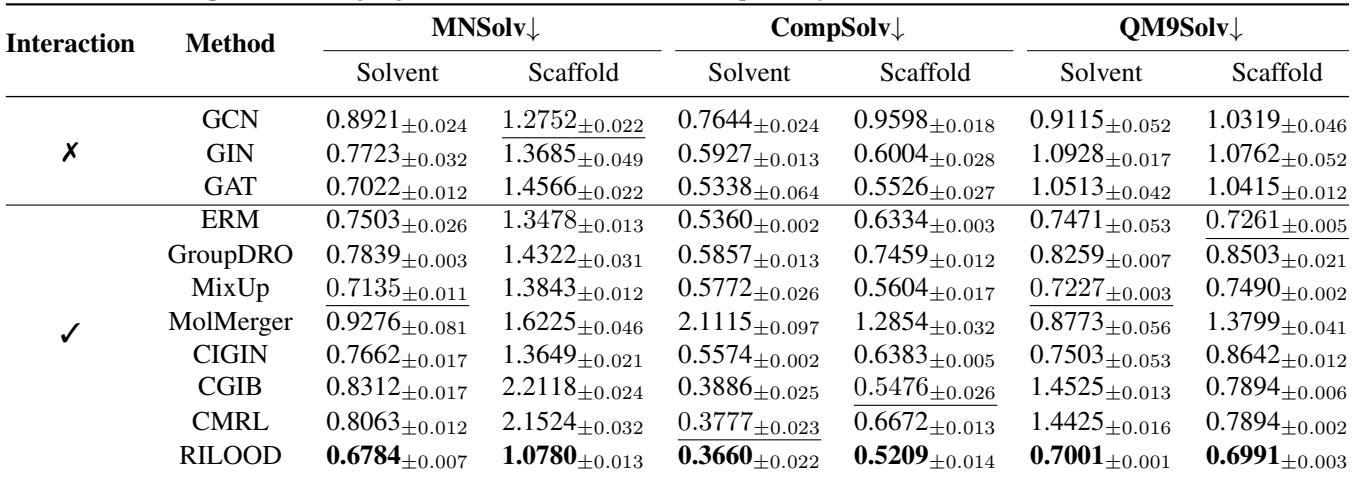
RILOOD (最后一行) 在几乎所有类别中都实现了最低的误差率。
- 在 MNSolv 溶剂分割中,它达到了 0.6784 的 RMSE,显著优于第二好的模型。
- 在 CompSolv 溶剂分割中,差距甚至更大,表明 RILOOD 特别擅长处理传统模型难以应对的复杂溶剂化环境。
这证实了“不变学习”方法可以防止模型过拟合训练集中的特定溶剂。
可视化不变性
数字固然好,但查看数据分布有助于我们理解模型为什么效果更好。研究人员使用 t-SNE (一种降维技术) 来可视化分子学习到的特征。
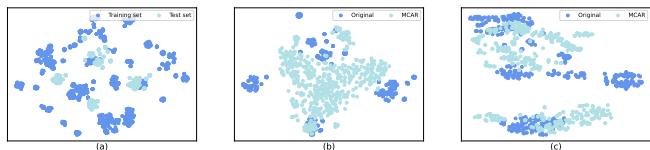
在图 4 中:
- 图 (a) 显示了训练集和测试集之间的原始分布偏移——它们明显不同,这也解释了为什么标准模型会失败。
- 图 (c) 显示了 RILOOD 学习到的特征 (带有 MCAR 模块) 。请注意聚类比原始数据更加紧密和清晰。这表明模型已成功将训练数据和测试数据的表示对齐到一个共享的潜在空间中,有效地“弥合”了已知与未知之间的差距。
对抗虚假相关性的鲁棒性
研究人员还在合成数据上进行了“压力测试”。他们故意注入虚假相关性——将特定环境与标签联系起来的虚假模式——看看模型是否会被欺骗。
随着这些虚假相关性强度的增加,大多数基准模型的性能虚假地提高了 (通过作弊和学习虚假模式) 。然而,RILOOD 保持了稳定。这证明互信息约束成功地迫使模型忽略统计上的巧合,专注于物理现实。
结论与启示
RILOOD 框架代表了“AI 用于科学 (AI for Science) ”迈出的重要一步。通过超越简单的模式匹配,并结合环境不变性和多粒度相互作用等概念,作者创造了一种反映化学家真实思维方式的工具。
给学生和从业者的关键启示:
- OOD 是常态: 在科学发现中,我们几乎总是试图预测以前从未见过的东西。模型的设计必须针对分布外泛化,而不仅仅是 IID 准确性。
- 上下文很重要: 分子通常不存在于真空中。对环境 (溶剂) 的建模与对物体 (溶质) 的建模同样重要。
- 不变性是关键: 为了建立鲁棒的模型,我们必须将稳定的因果关系与暂时的环境偏差区分开来。
这种方法为更可靠的药物和材料高通量筛选打开了大门,通过准确预测分子在复杂的现实环境中的溶解、反应和功能,可能会节省数年的实验时间。