](https://deep-paper.org/en/paper/5576_visual_and_domain_knowled-1759/images/cover.png)
引言
在过去几年中,我们见证了大型视觉语言模型 (Large Vision-Language Models, LVLM) 能力的巨大飞跃。像 GPT-4o 和 Gemini 这样的模型可以描述繁华街道的照片,根据白板草图编写代码,甚至解释梗图。然而,当我们把目光从通用的互联网图片转向高风险的医学领域时,这些“基础模型”往往会碰壁。
为什么?因为医学诊断不仅仅是识别物体。它是关于推理的。
如果你给通用的 LVLM 展示一张医学扫描图,它可能会正确地识别出这是一张脑部 MRI。它甚至可能发现一个巨大的肿瘤。但是,如果你问它一个专业级别的问题——比如“基于基底节的病灶模式,预测这名新生儿两年后的神经认知结果是什么?”——模型就会崩溃。
这正是这篇引人入胜的新论文 《Visual and Domain Knowledge for Professional-level Graph-of-Thought Medical Reasoning》 (用于专业级思维图医学推理的视觉和领域知识) 所要解决的问题。研究人员认为,要使 AI 在临床环境中发挥作用,我们需要超越简单的视觉问答 (VQA) ,转向能够模仿人类专家逐步推理过程的模型。
在这篇深度文章中,我们将探讨他们如何构建了一个针对“硬核”医学问题的新基准,并开发了一种名为临床思维图 (Clinical Graph of Thoughts, CGoT) 的新方法来解决这些问题。
医疗 AI 的差距
要理解这篇论文的创新之处,我们首先需要审视医疗视觉问答 (Medical Visual Question Answering, MVQA) 的现状。
大多数现有的医疗 AI 数据集都集中在临床医生认为“简单”或“无关紧要”的任务上。例如,一个数据集可能会要求模型识别图像中的器官或成像模态 (例如,“这是 CT 还是 MRI?”) 。虽然这些是必要的初步步骤,但并不是医生需要帮助的任务。放射科医生当然知道他们正在看的是脑部 MRI。
医生真正需要的是在复杂的预后判断和决策制定方面的协助。
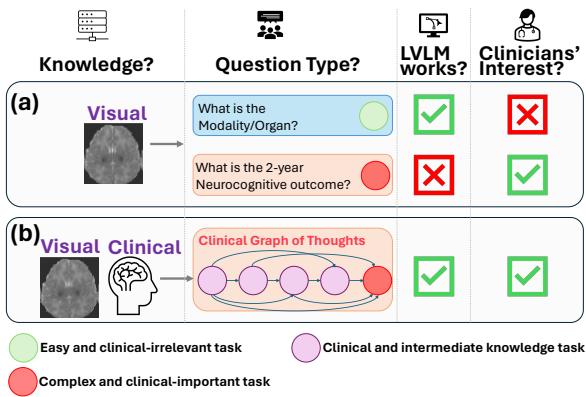
如图 1 所示,AI 目前的测试内容 (场景 A) 与临床医生实际关心的内容 (场景 B) 之间存在错位。研究人员发现,虽然 LVLM 可以处理简单的感知任务,但它们在复杂的、临床上重要的任务 (由红色圆圈表示) 上表现失败,例如预测患者的长期健康结果。
HIE-Reasoning 基准的引入
为了弥补这一差距,作者引入了一个名为 HIE-Reasoning 的新基准。该数据集专注于一种特定且危急的医疗状况: 缺氧缺血性脑病 (Hypoxic-Ischemic Encephalopathy, HIE) 。
HIE 是一种脑功能障碍,发生在新生儿出生前后大脑没有获得足够的氧气和血流时。它是新生儿死亡和残疾的主要原因之一。诊断 HIE 的严重程度并预测婴儿是否会遭受长期问题 (如脑瘫或认知缺陷) 是非常困难的,需要专家综合分析 MRI 数据。
为什么这个基准与众不同
大多数医疗数据集是从公共数据库中抓取并由普通标注者进行标注的。然而,HIE-Reasoning 是利用长达十年 (2001–2018) 的真实临床报告和专家标注构建的。

如表 1 所示,HIE-Reasoning 的独特之处在于它要求未来预测 。 AI 不仅仅是描述屏幕上当前显示的内容;它必须预测患者两年后的神经认知结果。这被认为是临床决策支持的“圣杯”。
HIE-Reasoning 的六项任务
该基准不仅仅是一个单一的问题。它的结构旨在模拟完整的临床工作流程。研究人员定义了 AI 必须执行的六项具体任务,反映了放射科医生和新生儿科医生会采取的步骤:
- 病灶分级 (Lesion Grading) : 估算受损脑容量的百分比和严重程度。
- 病灶解剖定位 (Lesion Anatomy) : 识别哪些特定的脑区 (ROI) 受损。
- 罕见位置病灶 (Lesion in Rare Locations) : 确定损伤模式是典型的还是非典型的。
- MRI 损伤评分 (MRI Injury Score) : 分配医院使用的标准化临床评分 (NRN 评分) 。
- 神经认知结果预测 (Neurocognitive Outcome Prediction) : 终极目标——预测 2 年后的结果是正常还是不良。
- MRI 解读摘要 (MRI Interpretation Summary) : 生成连贯的文本报告。
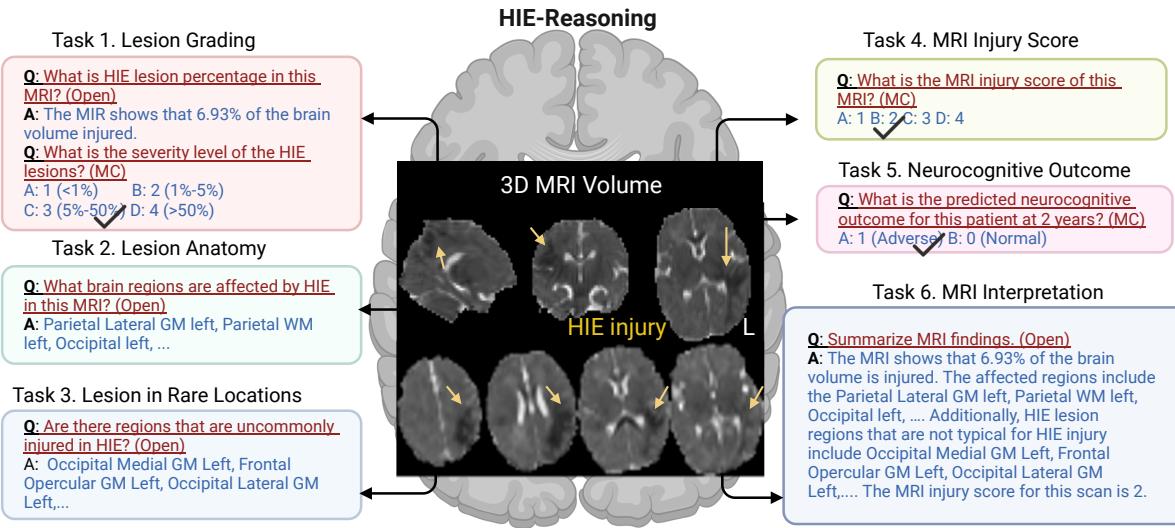
图 2 可视化了这个生态系统。通过将诊断分解为这些组成部分,该基准迫使模型在分析的每个层面上展示其理解能力。
解决方案: 临床思维图 (CGoT)
研究人员发现,如果你简单地将 MRI 输入标准的 LVLM (如 GPT-4o) 并询问“2 年后的结果是什么?”,模型的表现很差——通常并不比随机猜测好多少。模型缺乏将视觉模式与复杂预后联系起来的领域专业知识。
为了解决这个问题,他们提出了临床思维图 (Clinical Graph of Thoughts, CGoT) 模型。
什么是思维图?
在 AI 提示工程中,“思维链 (Chain of Thought) ”是一种要求模型“一步步思考”的技术。“思维图 (Graph of Thoughts) ”通过将推理过程建模为互连节点的网络,而不仅仅是一条线性线条,从而更进一步。
在 CGoT 中,图的“节点”对应于我们刚才讨论的临床任务。模型首先解决简单的任务,并将该信息 (“思维”) 传递给下一个节点,以帮助解决更难的任务。
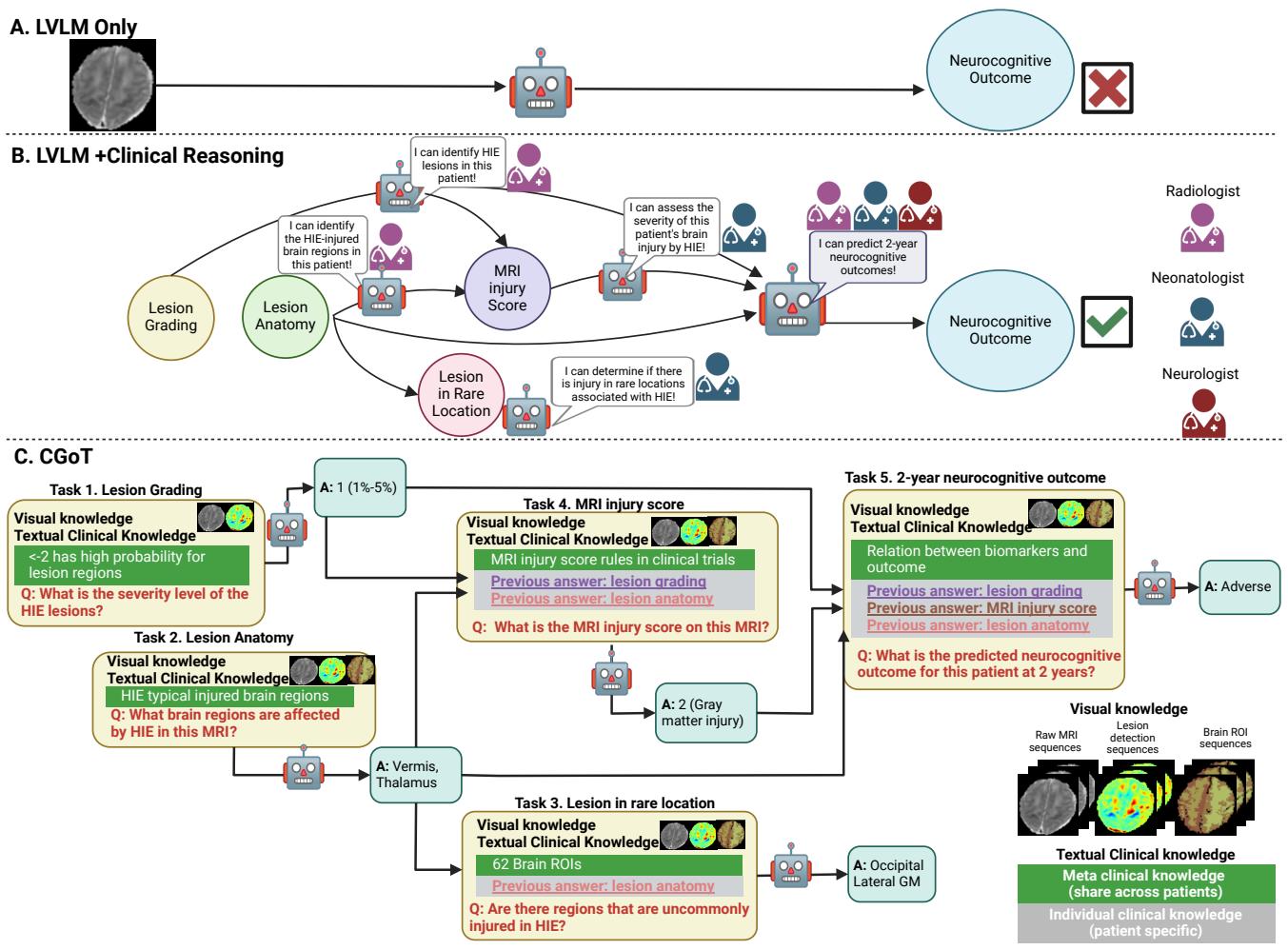
图 3 提供了一个清晰的对比。
- 方法 A 是朴素的方法: 图像 \(\rightarrow\) 模型 \(\rightarrow\) 预测。它失败了。
- 方法 C 是 CGoT。它模仿医生,首先评估严重程度 (病灶分级) ,然后检查损伤在哪里 (解剖定位) ,接着给出临床评分,最后才对未来做出预测。
驱动图谱: 视觉和文本知识
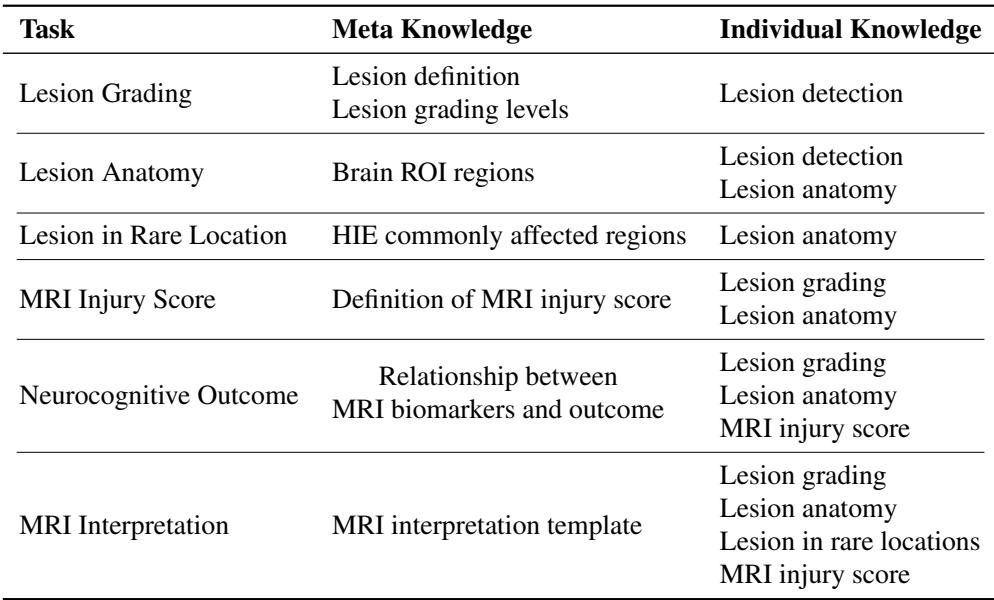
为了让这个图谱发挥作用,模型需要的不仅仅是原始像素。它需要领域知识 。 作者向模型提供了两种不同类型的信息:
1. 视觉知识
原始 MRI 扫描对于 AI 来说很难解读,因为不同患者的“正常”强度各不相同。作者通过以下方式增强了原始数据:
- \(Z_{ADC}\) 图谱: 一种统计归一化,突出显示像素与“健康”大脑的偏离程度。
- 病灶概率图: 显示可能损伤部位的热力图。
- 脑解剖图: 标记大脑中 62 个特定感兴趣区域 (ROI) 的叠加层。
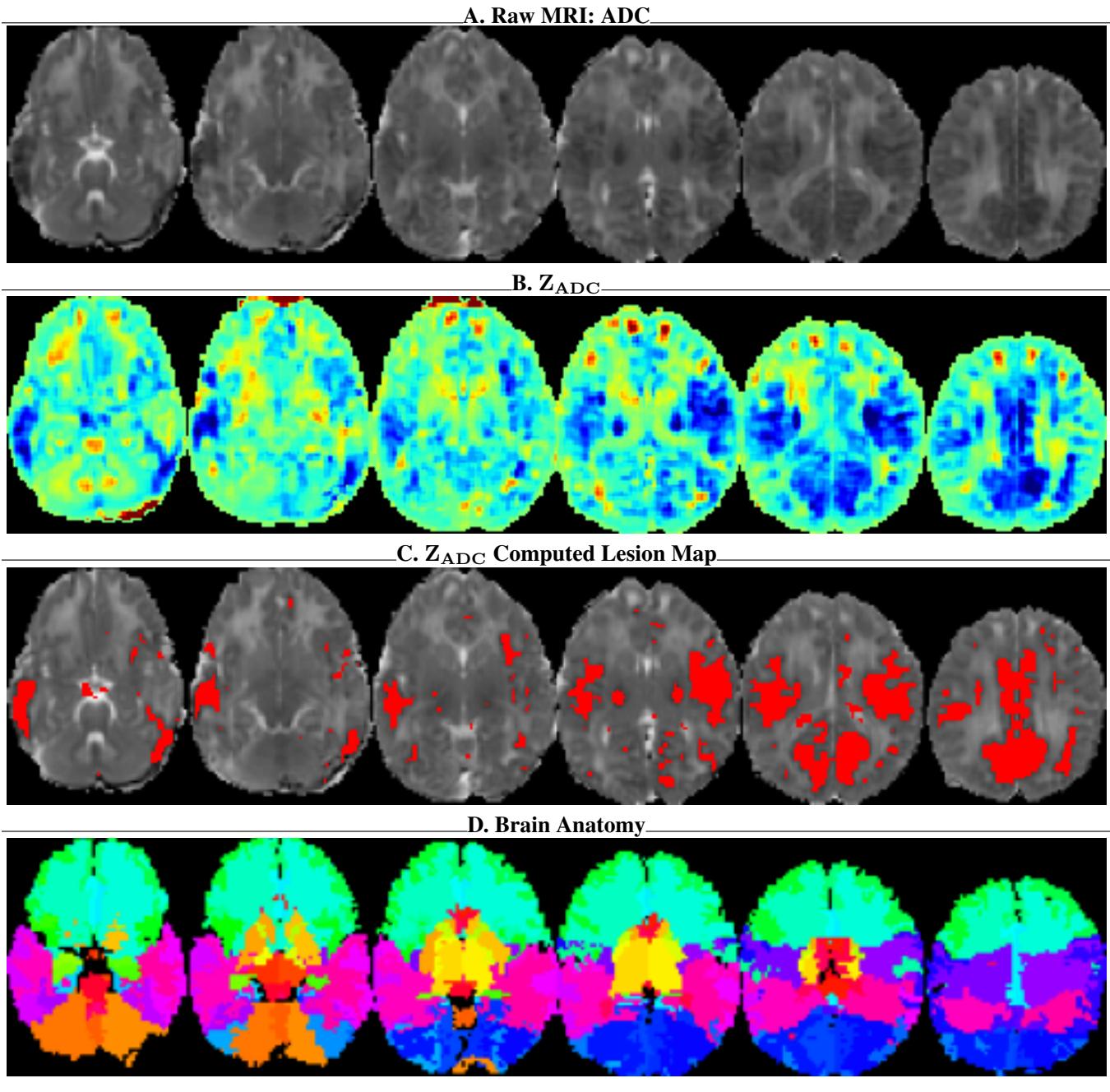
如图 7 所示,为模型提供解剖图 (面板 D) 和统计偏差图 (面板 B) ,本质上是给了 AI “放射科医生的视野”,使其能够看到在原始灰色像素中可能不可见的结构和异常。
2. 文本知识
模型还会接收分为元知识 (Meta Knowledge) 和个体知识 (Individual Knowledge) 的文本提示。
- 元知识: 这是通用的医学教科书信息 (例如,“基底节常在 HIE 中受累”) 。
- 个体知识: 这是由图中先前步骤生成的患者特定信息 (例如,“该特定患者在左侧丘脑有病灶”) 。
实验与结果
那么,像医生一样思考真的能帮助 AI 表现得更好吗?结果令人信服。
与最先进技术的比较
作者测试了标准模型 (GPT-4o, Gemini, Med-Flamingo) 与他们的 CGoT 方法。
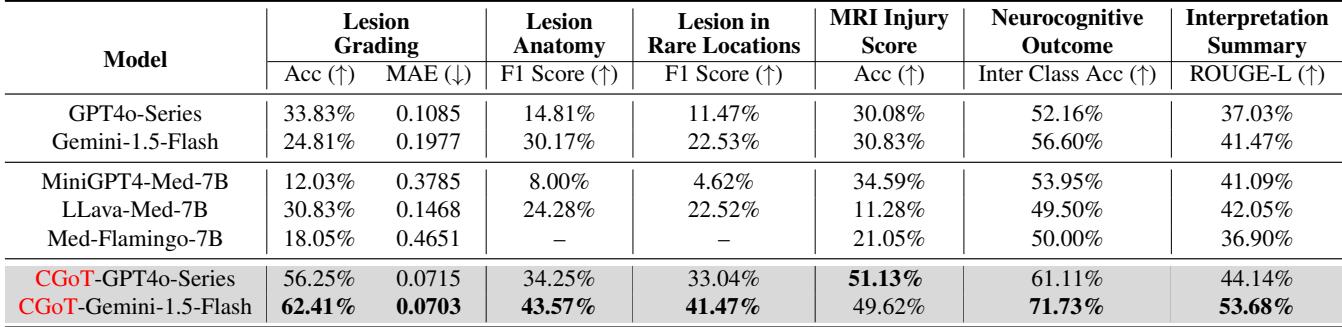
表 2 揭示了巨大的差异。
- 基线模型: 标准模型表现非常挣扎。对于至关重要的“神经认知结果”任务,像 LLava-Med 和 Med-Flamingo 这样的模型准确率徘徊在 50% 左右——本质上就像抛硬币。即使是强大的 GPT-4o 系列也仅达到了 52.16%。
- CGoT: 当包裹在 CGoT 框架中时,Gemini-1.5-Flash 在结果预测任务上的准确率飙升至 71.73% 。 这是一个巨大的提升,表明推理结构与底层模型同等重要。
定性分析
数字虽然漂亮,但透明度更佳。因为 CGoT 是分步骤工作的,我们可以检查它的“思维过程”。
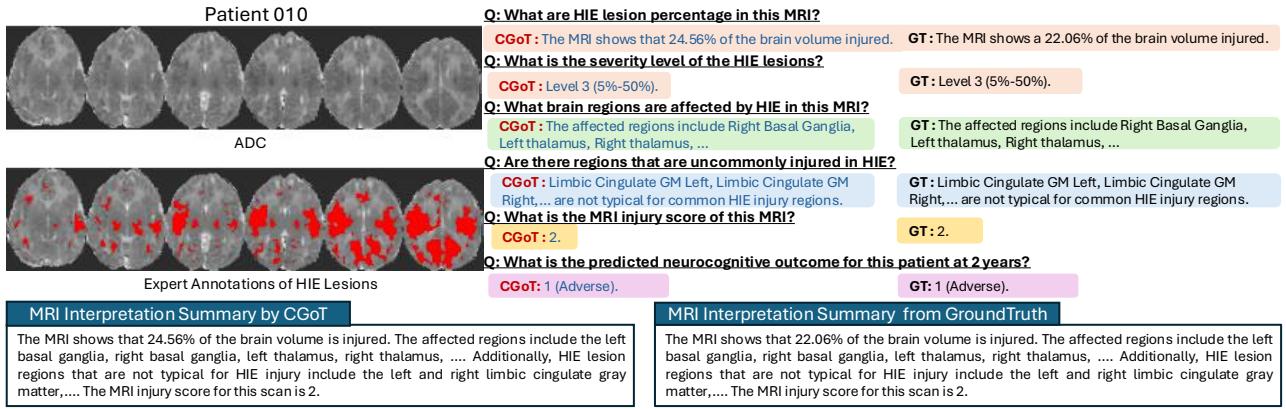
图 4 显示了为“患者 010”生成的报告。请注意模型是如何正确识别“右侧基底节”和“左侧丘脑”为受累区域的。因为它在“病灶解剖定位”步骤中识别了这些关键区域,所以它能够正确地将 MRI 损伤评分计算为“2”,从而引导其正确预测出“不良 (Adverse) ”结果。一个黑盒模型可能预测对了也可能预测错了,但它无法告诉你原因。
为什么它有效? (消融实验)
研究人员进行了“消融实验”以验证他们复杂的图谱的每个部分是否都是必要的。
1. 我们需要这个图谱吗? 是的。如表 3 所示,移除“思维图” (推理步骤) 将准确率从 71.73% 降至 52.43%。
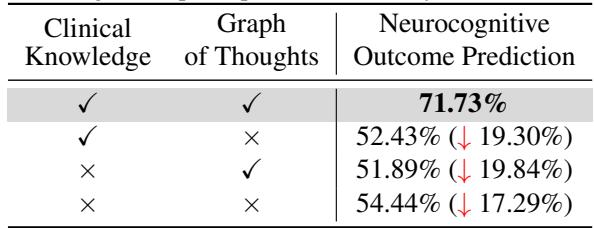
2. 哪一步最关键? 他们发现 MRI 损伤评分步骤是关键环节。如果从图中移除这个特定节点,准确率暴跌超过 20%。
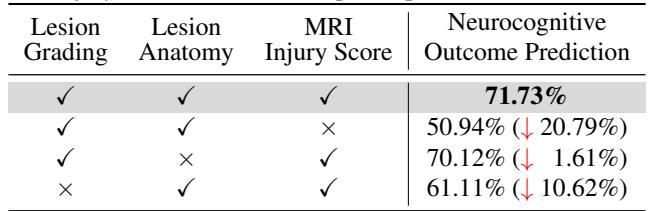
这完全符合临床常识。MRI 损伤评分 (特别是论文中提到的 NRN 评分) 是人类医生用来预测结果的标准生物标志物。通过强迫 AI 显式计算这个分数,研究人员将 AI 的“隐空间”与既定的医学科学对齐了。
结论与启示
论文《Visual and Domain Knowledge for Professional-level Graph-of-Thought Medical Reasoning》代表了医疗 AI 的一个重大转变。它摆脱了仅仅需要“更大模型”的观念,转向了我们需要更好的推理结构的理念。
通过创建 HIE-Reasoning 基准 , 作者为涉及预后和未来预测的专业级医疗任务提供了一个试验场。通过开发 CGoT , 他们展示了将复杂的医疗问题分解为由更小的、临床相关的子任务组成的图谱,可以让通用 LVLM 表现得像专家一样。
关键要点:
- 上下文至关重要: 向 AI 提供原始像素对于医疗诊断通常是不够的。模型需要统计上下文 (如 \(Z_{ADC}\) 图谱) 和解剖上下文 (ROI 图谱) 。
- 过程模仿: 当推理过程模仿人类专家的工作流程 (分级 \(\rightarrow\) 解剖定位 \(\rightarrow\) 评分 \(\rightarrow\) 预测) 时,AI 的表现最佳。
- 可解释性: 基于图的推理不仅提高了准确性;它还生成了审计线索。如果模型做出了错误的预测,我们可以查看中间节点以了解它在哪里出了错 (例如,它是否遗漏了丘脑中的病灶?) 。
这项工作预示着这样一个未来: 在新生儿护理的高风险环境中,AI 不仅是一个模式识别器,更是一个透明的、具有推理能力的合作伙伴。