](https://deep-paper.org/en/paper/5707_efficient_source_free_unl-1760/images/cover.png)
在人工智能的现代纪元,数据被视为新的石油。但与石油不同,数据往往附带附加条件: 隐私法规。随着欧盟《通用数据保护条例》 (GDPR) 和《加州消费者隐私法案》 (CCPA) 等法律的实施,个人获得了“被遗忘权”。这意味着如果用户要求删除其数据,任何在该数据上训练过的机器学习模型理论上都必须“遗忘”它。
这个过程被称为机器遗忘 (Machine Unlearning) 。 理想情况下,我们只需删除数据并从头开始重新训练模型。然而,重新训练大型模型在计算上既昂贵又耗时。因此,研究人员开发了算法,可以在不完全重置的情况下从训练好的模型中清除特定数据点。
但这存在一个陷阱——甚至是一个悖论。大多数现有的遗忘方法都需要访问原始训练数据,以计算哪些需要移除,哪些需要保留。 如果你无法访问原始数据会发生什么? 在许多现实场景中,为了确保存储合规性,训练数据在使用后会被立即删除,或者因为数据量太大而无法无限期存储。
这种场景被称为无源机器遗忘 (Source-Free Unlearning) , 它是目前该领域最艰巨的挑战之一。
在本文中,我们将深入探讨一篇提出该问题新颖解决方案的研究论文: 基于数据合成的判别感知 (DSDA) 框架。该方法允许模型在永远不再看到原始训练集的情况下有效地遗忘信息。
无源挑战
在理解解决方案之前,我们需要掌握该问题的具体约束条件。
- 目标: 从预训练模型中消除特定子集类别 (遗忘数据,\(D_f\)) 的影响。
- 约束: 我们无法访问原始训练数据集 (\(D_{train}\)) 。我们只有预训练的模型权重 (\(\theta_o\)) 和类别标签。
- 障碍: 现有的无源方法通常依赖于知识蒸馏 (训练一个学生模型来模仿教师模型) ,这在计算上既繁重又缓慢。
DSDA 框架的作者提出了一种两阶段方法,模拟原始数据,然后优化模型以遗忘特定部分。
 图 1: DSDA 框架的架构。它分两个阶段运行: (1) 生成合成数据以替代缺失的训练集,以及 (2) 使用多任务方法优化模型以遗忘特定类别并保留其他类别。
图 1: DSDA 框架的架构。它分两个阶段运行: (1) 生成合成数据以替代缺失的训练集,以及 (2) 使用多任务方法优化模型以遗忘特定类别并保留其他类别。
如图 1 所示,该框架分为加速能量引导数据合成 (AEGDS) 和判别感知多任务优化 (DAMO) 。 让我们逐一拆解。
第一阶段: 加速能量引导数据合成 (AEGDS)
如果我们没有数据,我们就必须制造数据。但我们不能只向模型输入随机噪声;我们需要统计上与原始训练集相似的数据,以便模型能够区分保留什么和删除什么。
作者提出使用预训练模型本身来生成这些数据。由于模型已经学习了数据的特征,它实际上包含了分布的“记忆”。
基于视角的能量模型
研究人员将分类器重新解释为基于能量的模型 (Energy-Based Model, EBM) 。 在物理学和机器学习中,能量函数 \(E(x)\) 为状态 \(x\) 分配一个标量值。能量越低的状态越稳定,概率也越高。
通过基于模型的输出 Logits 定义能量函数,模型确信的样本 (高概率) 将具有低能量。能量函数定义为:
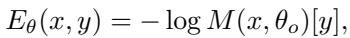
这里,\(M(x, \theta_o)[y]\) 是模型将输入 \(x\) 分配给类别 \(y\) 的概率。通过最小化这个能量,我们可以找到一个看起来像类别 \(y\) 的有效样本的输入 \(x\)。
朗之万动力学与速度需求
为了生成这些样本,作者利用了朗之万动力学 (Langevin Dynamics) 。 这是一个迭代过程,从随机噪声开始,通过跟随能量函数的梯度 (向高概率区域移动) 缓慢更新,同时加入一点噪声来探索空间。
用于寻找将分布 \(q\) 映射到目标 \(p\) 的变换 \(T(x)\) 的标准更新规则源自最小化 KL 散度:
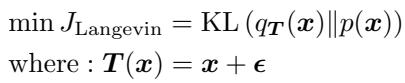
然而,标准的朗之万动力学很慢。它需要许多步骤才能收敛到逼真的图像,并且每一步计算梯度在计算上都很昂贵。这种缓慢使得它在高效遗忘方面不切实际。
“加速”解决方案
为了解决这个问题,作者引入了 AEGDS 。 他们将采样过程视为微分方程,并使用先进的数值求解器来加速它。
1. 龙格-库塔积分 (Runge-Kutta Integration) : 他们不使用简单的步骤,而是使用二阶龙格-库塔方法 (具体为休恩方法) 。这允许合成器以更高的精度采取更大的步长,有效地跳过冗余的中间计算。
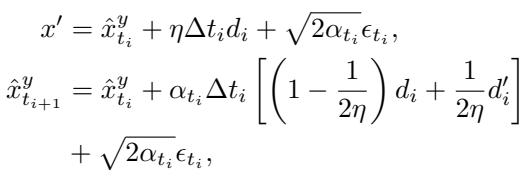
在这个方程中:
- \(d_i\) 是从当前步骤的梯度推导出的方向。
- \(d'_i\) 是一个“前瞻”梯度估计。
- 这种两阶段估计使得合成图像 \(\hat{x}\) 的更新更加准确。
2. Nesterov 动量: 为了进一步加快收敛速度,他们添加了一个动量项。就像滚下山的球会获得速度一样,优化过程“记住”了之前的方向 (\(v_i\)) ,以便更快地穿过能量景观的平坦区域。
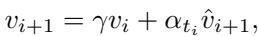
通过结合这些技术,DSDA 框架可以快速生成两个合成数据集: \(\hat{D}_r\) (我们想要保留的类别的合成数据) 和 \(\hat{D}_f\) (我们想要遗忘的类别的合成数据) 。
第二阶段: 判别感知多任务优化 (DAMO)
现在我们有了合成数据,可以进行实际的遗忘操作了。标准的遗忘通常涉及两个简单的目标:
- 最大化遗忘集的误差 (让模型无法识别被遗忘的类别) 。
- 最小化保留集的误差 (保持模型在其他方面表现良好) 。
然而,作者发现简单地应用这两种力量会导致一个称为特征发散 (feature scattering) 的问题。
特征分布的问题
当你强迫模型“遗忘”一个类别时,它会破坏模型的内部特征空间。
 图 2: 特征空间对比。(a) 原始模型。(b) 从头开始重训练的模型 (黄金标准) 。(c) 使用标准损失函数遗忘的模型。(d) 使用 DSDA 遗忘的模型。
图 2: 特征空间对比。(a) 原始模型。(b) 从头开始重训练的模型 (黄金标准) 。(c) 使用标准损失函数遗忘的模型。(d) 使用 DSDA 遗忘的模型。
看图 2(c) 。 这展示了标准遗忘的结果。注意点 (代表数据样本) 是如何分散的吗?类别之间没有很好地分离。这意味着模型变得混乱,可能会降低其在应该保留的数据上的准确性。
将其与图 2(b) 也就是“重训练”模型 (我们渴望达到的目标) 进行对比。在这里,簇是紧密且清晰的。
判别特征对齐目标
为了解决 2(c) 中看到的发散问题,作者引入了一个新的损失函数: 判别特征对齐 (Discriminative Feature Alignment) 。
目标是双重的:
- 类内紧凑性: 将同一保留类别的样本拉得更近。
- 类间可分离性: 将不同保留类别的样本推得更远。
该目标的数学公式为:
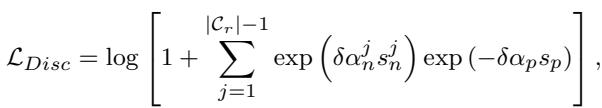
这个损失函数 (\(\mathcal{L}_{Disc}\)) 使用余弦相似度 (\(s\)) 来惩罚模型,如果不同的类别靠得太近 (\(s_n^j\)) 或同一个类别太过分散 (\(s_p\)) 。
结果在图 2(d) 中可见。DSDA 遗忘模型保持了紧密、分离的簇,看起来与图 2(b) 中的重训练模型非常相似。
多任务优化: 解决梯度冲突
我们现在有三个不同的目标需要优化:
- 遗忘损失 (\(\mathcal{L}_F\)): 破坏目标类别的知识。
- 保留损失 (\(\mathcal{L}_R\)): 保存其他类别的知识。
- 判别损失 (\(\mathcal{L}_{Disc}\)): 保持特征空间整洁。
同时优化这些是困难的,因为它们的梯度经常冲突。例如,帮助模型“遗忘”的梯度更新可能会意外地将权重推向破坏“保留”类别紧凑性的方向。
为了解决这个问题,作者将其视为一个多任务优化问题。他们寻找一个更新方向 \(d\),尽可能好地满足所有三个目标。
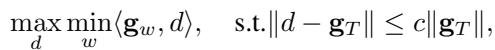
这个方程本质上是在问: 什么方向 \(d\) 能够最大化“表现最差”目标的改进,同时又不会偏离整体平均梯度 (\(\mathbf{g}_T\)) 太远?
通过求解这个拉格朗日优化问题 (论文中的定理 3.3) ,他们推导出一个动态加权系统,可以即时调整每个损失函数的重要性,从而确保稳定和平衡的遗忘过程。
实验与结果
作者在三个基准数据集上测试了 DSDA: CIFAR-10、CIFAR-100 和 PinsFaceRecognition (用于人脸识别任务) 。他们将其与几个基线进行了比较,包括“重训练” (理想的上限) 和其他无源方法,如 GKT 和 ISPF。
有效性: 准确性与隐私
成功的主要指标是:
- \(A_f\) (遗忘数据上的准确率) : 应该是 0% (完全失忆) 。
- \(A_r\) (保留数据上的准确率) : 应该很高 (接近原始模型) 。
- MIA (成员推理攻击) : 分数越低越好;它表明攻击者无法确定特定数据是否用于训练。
 表 1: 单类遗忘结果。注意 DSDA 在遗忘准确率 (\(A_f\)) 上达到了 0.00%,同时在无源方法中保持了最高的保留准确率 (\(A_r\))。
表 1: 单类遗忘结果。注意 DSDA 在遗忘准确率 (\(A_f\)) 上达到了 0.00%,同时在无源方法中保持了最高的保留准确率 (\(A_r\))。
如表 1 所示,DSDA (最后一行) 始终优于其他无源方法。它有效地清除了目标类别的记忆 (\(A_f = 0.00\)) ,同时保持保留准确率 (\(A_r\)) 与原始模型几乎相同。至关重要的是,它的 MIA 分数非常低 (11.80%) ,表明具有很高的隐私保护能力。
效率: 速度至关重要
DSDA 的主要卖点之一是“加速”合成。它经得起考验吗?
 图 3: 效率比较。X 轴代表执行时间 (ET),Y 轴代表保留准确率 (\(A_r\))。
图 3: 效率比较。X 轴代表执行时间 (ET),Y 轴代表保留准确率 (\(A_r\))。
在图 3 中,我们可以看到 DSDA (红线) 几乎立即达到了高准确率。竞争方法如 ISPF (蓝色) 和 GKT (绿色) 需要更长的时间才能达到像样的准确率水平,或者根本达不到。这证明第一阶段中龙格-库塔和动量的集成带来了显著的回报。
合成数据是否会泄露隐私?
生成合成数据的一个合理担忧是,我们可能会意外地重建用户的真实面部或图像,从而违反我们试图保护的隐私。
作者可视化了通过 AEGDS 过程生成的合成数据:
 图 5: (a) 真实数据与合成数据之间的特征分布重叠。(b) 合成数据实际看起来的样子。
图 5: (a) 真实数据与合成数据之间的特征分布重叠。(b) 合成数据实际看起来的样子。
图 5(b) 显示合成图像是视觉上无法识别的噪声模式。它们捕捉了模型所需的统计特征 (如 5(a) 中重叠的簇所示) ,但它们不泄露任何人类可解释的信息。这确保了遗忘过程本身保持隐私保护。
结论
DSDA 框架代表了隐私中心机器学习向前迈出的重要一步。通过成功地将遗忘与原始数据的需求解耦,它为公司和研究人员提供了一条可行的途径,以在不产生巨大计算成本或存储责任的情况下遵守“被遗忘权”法规。
两阶段的创新——首先使用加速能量模型有效地“构想”必要的统计数据,然后通过多任务优化精心组织特征空间——表明我们并不总是需要原始数据来纠正模型的行为。我们只需要充分理解模型的内部能量和特征表示来引导它。
随着隐私法律变得越来越严格,像 DSDA 这样的技术可能会从学术论文走向全球 MLOps 流程的标准实践。