](https://deep-paper.org/en/paper/5715_bridging_layout_and_rtl_k-1747/images/cover.png)
我们能教会 RTL 模型物理知识吗?深入解析 RTLDistil 框架
在现代芯片设计的世界里,速度就是一切——不仅指最终处理器的时钟速度,还指工程师设计它的速度。这在电子设计自动化 (EDA) 中制造了一个根本性的矛盾。一方面,你希望尽可能早地 (在寄存器传输级,即 RTL) 知道你的设计是否满足时序约束。另一方面,除非你完成了包含组件放置和布线在内的物理版图设计,否则你无法真正知晓时序。
这造成了一个巨大的反馈循环瓶颈。工程师编写代码,综合代码,通过物理版图引擎运行 (这需要数小时甚至数天) ,然后才发现存在时序违例。这个过程通常被称为“慢速 EDA 流程”,是生产力的主要杀手。
行业的解决方案是“左移 (Left-Shift) ”范式: 将验证和预测在时间线上前移。但这有个问题。RTL 代码是抽象逻辑;它不知道导线电阻、电容或物理拥塞。那么,如何让抽象的 RTL 模型准确预测物理现实呢?
答案可能在于 RTLDistil , 这是第 42 届国际机器学习会议 (ICML) 上发表的一项新研究提出的框架。这篇论文提出了一个巧妙的解决方案: 利用 知识蒸馏 (Knowledge Distillation) 将具有版图感知能力的模型的“物理智慧”转移到一个快速、轻量级的 RTL 模型中。
在这篇深度解析中,我们将探索 RTLDistil 的工作原理,其图神经网络 (GNN) 的架构,以及为什么它的多粒度方法为早期时序预测设立了新标准。
问题所在: 抽象与物理的对决
要理解这项研究的必要性,我们首先需要可视化 RTL 和版图之间的差距。
RTL (通常用 Verilog 或 SystemVerilog 编写) 描述了芯片做什么。它定义了寄存器、逻辑门和数据流。然而,它将连接视为理想的、瞬时的通路。它忽略了物理现实,即电流在导线上传输需要时间,且芯片上的拥挤区域会产生寄生电阻和电容 (RC) 。
物理版图是制造的蓝图。它确切地知道每个触发器位于何处以及每根导线有多长。这使得静态时序分析 (STA) 成为精度的黄金标准。
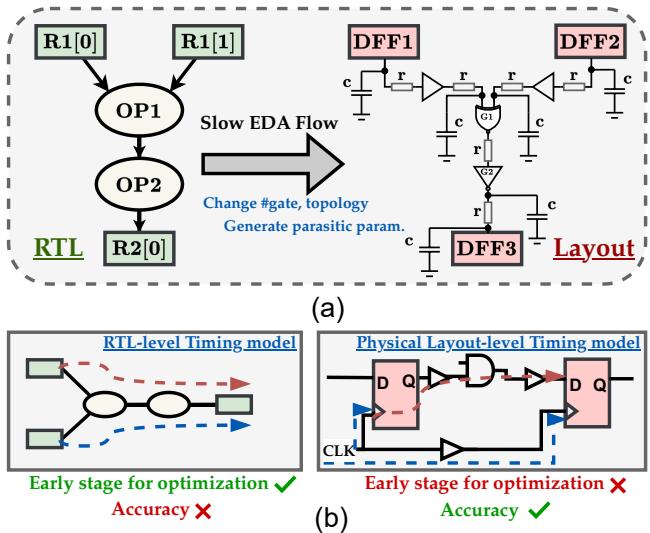
如上图 Figure 1 所示,两者对比鲜明。RTL 模型 (左侧) 速度快但不准确 (标有红叉) ,因为它基于逻辑深度猜测时序。物理模型 (右侧) 准确但计算昂贵,并且在设计周期中出现得太晚,无法用于快速迭代。
RTLDistil 的目标是兼具右侧的精度与左侧的速度 。
解决方案: 师生蒸馏
研究人员利用 知识蒸馏 (Knowledge Distillation, KD) 来解决这个问题。KD 是一种机器学习技术,即用一个大型、复杂的模型 (教师) 来训练一个更小、更简单的模型 (学生) 来模仿其行为。
在 RTLDistil 的背景下:
- 教师 (版图 GNN) : 该模型可以看到完整的物理网表。它了解单元驱动强度、电容、输入/输出转换速率 (slew) 和导线延迟。它被训练成物理时序方面的专家。
- 学生 (RTL GNN) : 该模型只能看到抽象的 RTL 图 (简单算子图,SOG) 。在推理过程中,它无法访问任何物理参数。
- 蒸馏: 在训练期间,教师强制学生将其内部特征表示与教师的物理洞察力对齐。
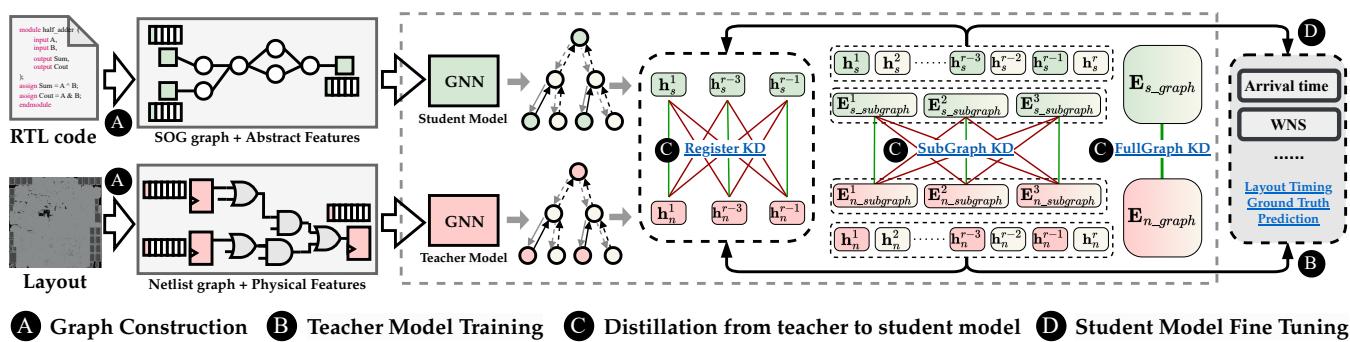
Figure 2 概述了整个流程。请注意,该过程包括为两个阶段构建图,训练教师模型,然后通过三个特定层级 (节点、子图和全局) 将知识蒸馏给学生。最后,学生模型针对实际的预测任务进行微调。
数据表示: 两种图的故事
教师知道的和学生知道的之间存在巨大差异。下表展示了每个模型可用的特征。
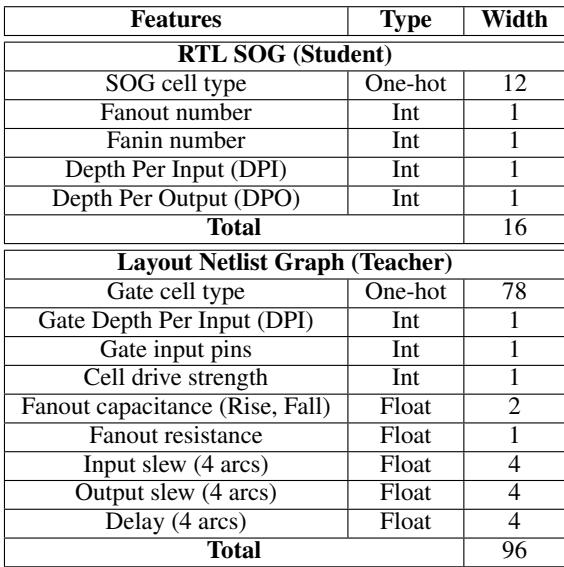
学生 (RTL) 拥有一个大小为 16 的特征向量,主要由逻辑深度和扇入/扇出计数组成。然而,教师 (版图) 在包含电阻、电容 (上升/下降) 和延迟弧等丰富物理数据的 96 维向量上进行操作。
挑战是巨大的: 学生必须学会根据物理现象 (如电容) 预测结果,而无需明确看到这些现象的数据。
核心方法: 图神经网络与传播
教师和学生模型都是使用图神经网络 (GNN) 构建的,特别是图注意力网络 (GAT) 。电路天然地可以表示为图,其中逻辑门是节点,导线是边。
然而,标准的 GNN 传播 (聚合邻居信息) 对于时序分析来说是不够的。在数字电路中,时序由路径决定。信号在前向移动时会积累延迟,但时序约束 (裕量/Slack) 通常是通过查看所需的到达时间来计算的,这需要从输出端向后传播。
异步前向-反向传播
为了模拟延迟传播和静态时序分析 (STA) 的实际物理过程,研究人员开发了一种领域特定的 异步前向-反向传播 策略。
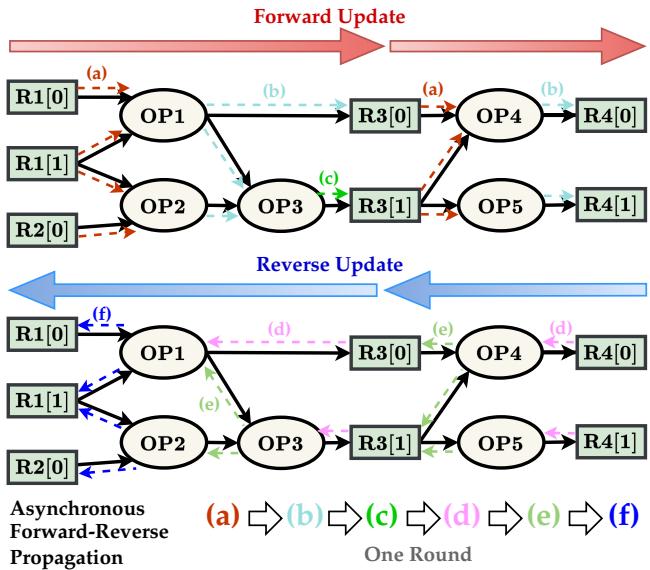
如 Figure 3 所示,模型不仅仅是按随机顺序更新节点。
- 前向传递 (红箭头) : 信息从输入 (源端) 流向输出 (汇端) 。这模拟了单元和导线延迟的累积 (到达时间) 。
- 反向传递 (蓝箭头) : 信息从输出流回输入。这模拟了所需到达时间的传播和裕量计算。
这种双向流动使每个节点都能理解其上下文: “信号到达我这里花了多长时间?” (前向) 以及“我还有多少时间将信号传送到终点?” (反向) 。
节点特征 \(h\) 的数学更新规则结合了其邻居特征和注意力机制权重 \(\alpha\):
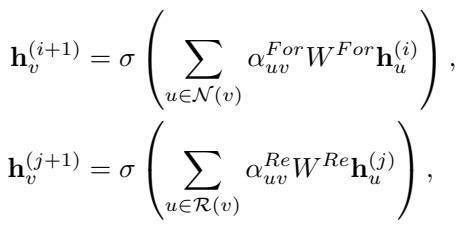
在这些公式中,\(\mathcal{N}(v)\) 代表前向邻居 (扇入) ,\(\mathcal{R}(v)\) 代表反向邻居 (扇出) 。教师模型运行更多轮次的这种传播以捕捉长路径累积,而学生模型运行较少轮次以保持轻量级和快速。
核心秘诀: 多粒度蒸馏
如果我们只是简单地训练学生预测最终的时序数值 (例如“1.5ns”这类标量值) ,它很可能会过拟合或无法泛化。它需要像教师一样“思考”,而不只是猜测教师的答案。
RTLDistil 采用了 多粒度知识蒸馏 , 在三个不同的结构层级上对齐模型。这确保了学生在局部、区域和全局范围内学习物理依赖关系。
1. 节点级蒸馏 (寄存器)
在最细的粒度上,模型对齐特定寄存器节点 (触发器) 的特征。这确保了对于特定的寄存器 \(v\),学生的嵌入表示与教师的嵌入表示具有相同的时序关键性。
损失函数使用平滑 \(L_1\) 距离度量来最小化教师嵌入 (\(embedding_T\)) 与学生投影嵌入 (\(embedding_S\)) 之间的差异:

选择平滑 \(L_1\) 损失是因为它比均方误差 (\(L_2\)) 对离群值更不敏感,并且在零附近比绝对误差 (\(L_1\)) 更平滑:
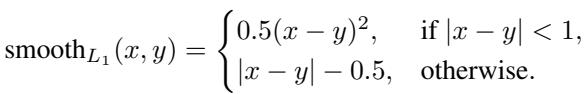
2. 子图级蒸馏 (上下文)
寄存器并非孤立存在;它的时序由“扇入锥 (Fan-in Cone) ”决定——即输入到它的组合逻辑云 (与门、或门、非门) 。
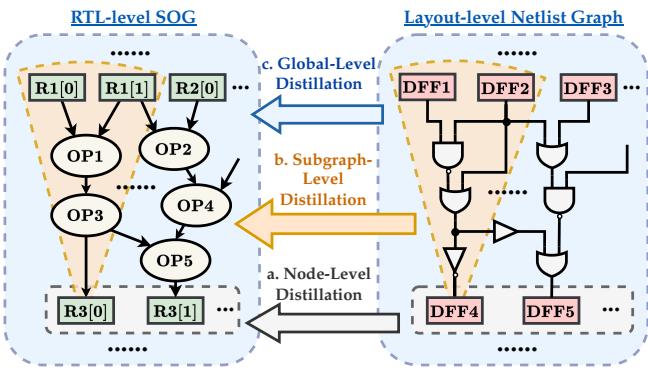
如 Figure 4 (b) 所示,子图蒸馏聚合了整个扇入锥的嵌入。这迫使学生理解驱动信号到达寄存器的结构复杂性。如果教师在版图中看到了一条高电阻路径,学生必须学会识别 RTL 中导致这种情况的相应逻辑拓扑。

这里,\(\mathcal{G}_{sub}(v)\) 代表节点 \(v\) 的子图 (扇入锥) 。
3. 全局级蒸馏 (宏观图景)
最后,模型查看整个电路图 \(\mathcal{G}\)。全局蒸馏汇集所有节点嵌入以形成单个图向量。这有助于学生考虑影响全局时序的芯片级属性,例如整体拥塞或时钟树特征。
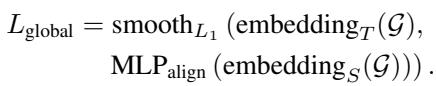
总损失函数
训练过程将所有这些蒸馏损失与实际的监督损失 (预测到达时间的误差) 相结合。
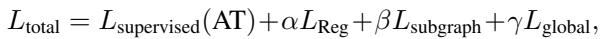
系数 \(\alpha, \beta, \gamma\) 允许研究人员调整每个粒度层级的重要性。这个综合损失函数指导学生模型本质上“推断”出它看不到的物理参数,从而产生高度准确的预测。
实验结果
研究人员在一个包含 2,004 个 RTL 设计的数据集上评估了 RTLDistil,范围从小型算术模块到复杂的 RISC-V 子系统。这种多样性确保模型不仅仅是死记硬背一种类型的电路。
评估的关键指标包括:
- 到达时间 (AT): 信号何时到达。
- 最差负裕量 (WNS): 设计中最严重的时序违例。
- 总负裕量 (TNS): 所有时序违例的总和 (衡量整体设计有多“糟糕”) 。
- MAPE: 平均绝对百分比误差 (越低越好) 。
- PCC: 皮尔逊相关系数 (越接近 1.0 越好) 。
与最先进技术的比较
RTLDistil 与 MasterRTL 和 RTL-Timer 进行了比较,后两者是该领域之前的领先者。 Table 2 中总结的结果令人震惊。

观察 到达时间 (AT) , RTLDistil 达到了 0.9227 的相关性 (PCC) ,显著高于 MasterRTL (0.3498) 和 RTL-Timer (0.8782)。更令人印象深刻的是误差的减少: RTLDistil 将 MAPE 降至 16.87% 。
对于 总负裕量 (TNS) , 由于误差会累积,这通常极难预测,RTLDistil 跃升至 0.9586 的相关性 , 而 MasterRTL 仅为 0.6255。
可视化相关性
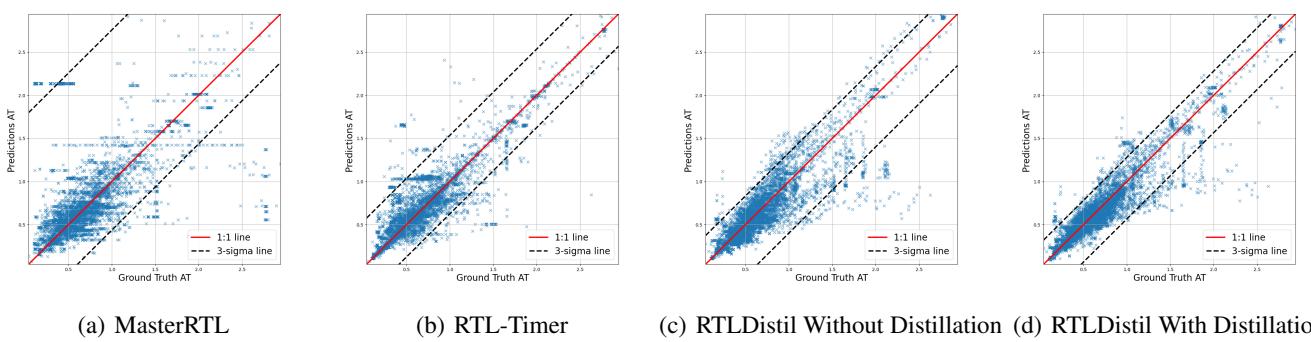
表格中的数字是一回事,但散点图更能说明问题。在下图中,X 轴是真实值 (物理) ,Y 轴是预测值。理想情况下,所有蓝色星星应完美地落在红色对角线上。
到达时间 (AT): 在 Figure 6 中,注意 MasterRTL (a) 和 RTL-Timer (b) 的点是多么分散。RTLDistil (d) 显示出沿对角线的紧密聚集,表明精度很高。
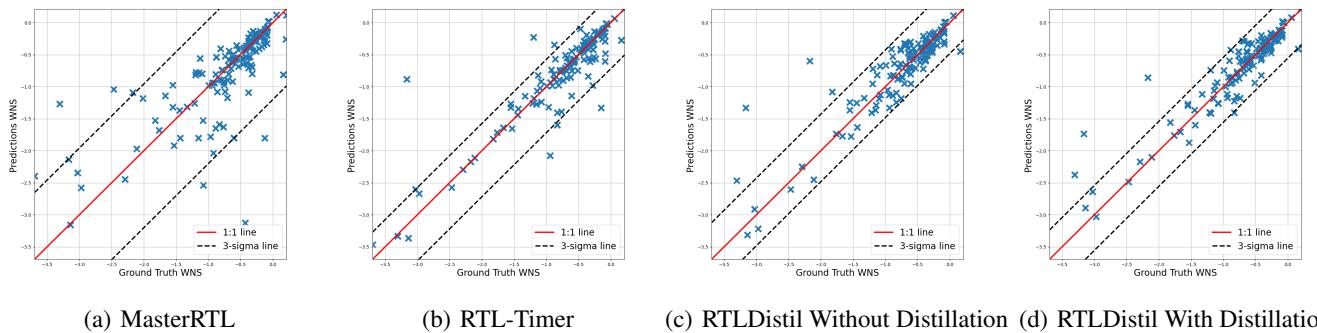
最差负裕量 (WNS): WNS 至关重要,因为它决定了芯片的最大时钟频率。 Figure 7 显示 MasterRTL (a) 有大量的离群点。带蒸馏的 RTLDistil (d) 将这些离群点拉了回来,紧贴 1:1 线。
蒸馏真的有帮助吗? (消融实验)
有人可能会问: “起作用的是 GNN 架构,还是知识蒸馏?”研究人员进行了消融实验,以分离蒸馏过程的影响。
Table 3 比较了教师 (性能上限) 与有无蒸馏的学生模型。

“RTLDistil (w/o Distillation)”一行显示了如果在没有教师指导的情况下仅使用标签训练 RTL 模型会发生什么。到达时间的 MAPE 为 22.04% 。 当加入蒸馏和微调 (Full Model) 后,误差降至 16.87% 。 这证明了学生确实正在从教师那里学习“隐藏”知识。
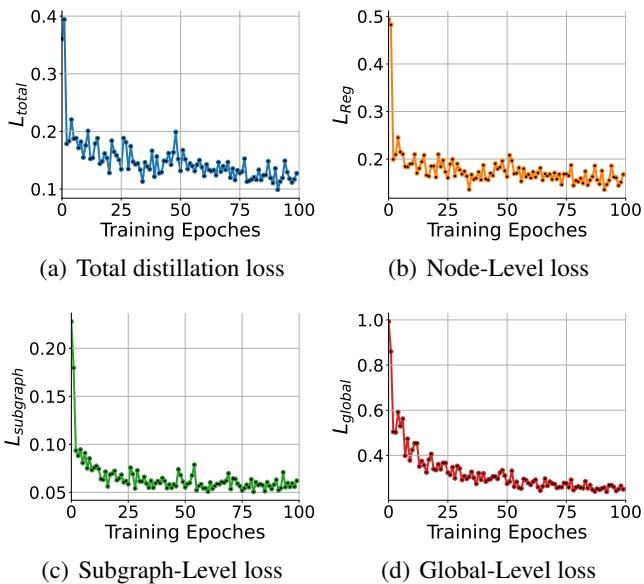
此外,训练动态显示了模型的学习过程。 Figure 5 显示了不同粒度的损失曲线。你可以看到节点级损失 (b) 下降得很快——寄存器很容易对齐。全局级损失 (d) 需要更长时间,表明对齐电路的整体“氛围”更难,但最终会收敛。
传播策略分析
最后,团队验证了他们的“前向-反向”传播理论。它比仅前向传播更好吗?

Table 5 证实了双向方法 (“2 Forward + Reverse”) 优于仅前向方法。它还强调了一个有趣的发现: 并不总是越多越好。增加到 5 轮传播实际上略微降低了性能,这可能是由于过拟合或噪声放大 (GNN 中常见的“过平滑”问题) 。
结论与未来启示
RTLDistil 代表了 EDA “左移”运动迈出的重要一步。通过成功弥合抽象 RTL 世界与物理版图世界之间的鸿沟,它提供了一个既足够快可用于早期设计探索,又足够准确值得信赖的工具。
核心创新不仅在于 GNN,还在于 多粒度知识蒸馏 。 通过强制 RTL 模型在节点、子图和全局层面上理解电路,研究人员创建了一个能够以惊人的准确性推断物理现实的模型。
对于 EDA 领域的学生和研究人员来说,这突显了 AI 的潜力,不仅在于自动化任务,还在于在不同抽象层级之间进行翻译。随着设计变得越来越复杂以及“摩尔定律”放缓,像 RTLDistil 这样的工具对于在最短时间内从硅片中榨取最大性能至关重要。芯片设计的未来不仅关于更好的物理引擎;它还关于能够向专家学习物理知识的更智能的模型。