](https://deep-paper.org/en/paper/6011_efficient_and_separate_au-1708/images/cover.png)
想象一下,你想给同事发送一份机密蓝图。你不想使用标准的加密方式,因为一个名为 top_secret_plans.enc 的文件对任何拦截者来说都太显眼了。相反,你决定将蓝图隐藏在一张无害的猫的照片里。这就是隐写术 (Steganography) : 一种在眼皮底下隐藏信息的艺术。
多年来,研究人员利用深度学习使这一过程变得极其有效。然而,这里存在一个明显的安全漏洞。在大多数现有系统中,如果你拥有“提取”网络,你就能看到隐藏在图像中的所有内容。这里没有“钥匙”或特定用户认证的概念。如果你在一张封面照片中为五个不同的人隐藏了五张不同的秘密图像,任何拥有解码器的人都能看到这五张图。
今天,我们将深入探讨一篇引人入胜的论文,题为 “Efficient and Separate Authentication Image Steganography Network” (AIS,高效分离认证图像隐写网络) 。研究人员提出了一种新颖的架构,不仅在图像隐藏中引入了安全的“锁”和“钥匙”,而且在大幅缩小模型尺寸的同时提高了图像质量。
如果你是计算机视觉或网络安全专业的学生,这篇论文填补了生成式深度学习与安全通信之间的空白。让我们来拆解一下他们是如何做到的。
问题所在: “全有或全无”的缺陷
传统的深度学习隐写术通常采用可逆神经网络 (Invertible Neural Networks, INNs) 。 这些网络非常出色,因为它们不会丢失信息——它们可以完美地将数据进行正向 (隐藏) 和反向 (提取) 映射。
然而,目前的方法存在三个关键缺陷:
- 无认证: 如前所述,这是一个全有或全无的访问模式。请看下面的图 1。在传统方法 (a) 中,任何拥有接收端网络的人都能获得秘密。在提出的 AIS 方法 (b) 中,则需要特定的密钥。
- 质量下降: 认证通常需要将额外的“锁”信息 (如密码哈希) 嵌入到图像中。这种“噪声”与实际图像数据争夺空间,从而降低了最终图片的质量。
- 模型臃肿: 为了隐藏多张图像 (例如,一张给 Alice,一张给 Bob) ,传统方法是串行运行网络的。要隐藏 5 张图像,你实际上需要堆叠 5 个网络。这使得模型既沉重又缓慢。

研究人员旨在证明,你可以在增加认证机制的同时,既不破坏图像质量,也不让模型变得庞大。
挑战: 为何加密会损害质量
在查看解决方案之前,我们需要理解认证与隐写术之间在数学上的摩擦。
当你在神经网络中引入“锁”或密钥时,你实际上是引入了一个条件。网络需要学习一种数据分布,即输出会根据该条件发生变化。
研究人员通过比较“无认证”方法与标准“基于认证”方法分析了这一点。
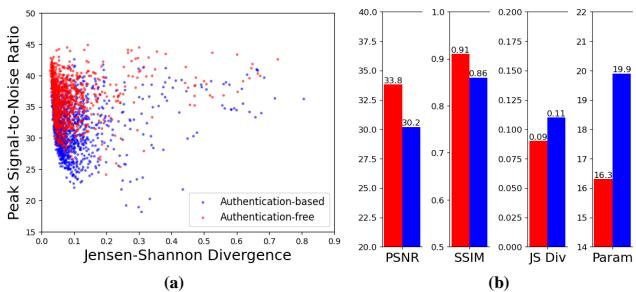
如图 2 所示:
- 图表 (a): 蓝点 (基于认证) 通常比红点显示出更高的散度 (与原始图像差异更大) 和更低的 PSNR (质量更低) 。
- 图表 (b): 增加锁机制后,PSNR 从约 33.8 dB 下降到约 30.2 dB。
为什么? 因为“锁”信息看起来像随机噪声 (高熵) ,而自然图像具有结构 (低熵) 。强迫网络将结构化的图像和充满噪声的锁同时隐藏到一张封面图像中,会产生“分布不匹配”。锁占据了宝贵的隐藏空间,从而降低了视觉效果。
解决方案: AIS 架构
研究人员提出了高效分离认证图像隐写网络 (AIS) 。
该架构的精妙之处在于它将问题分解为两个不同的阶段,由两个专门的网络处理:
- IAN (Invertible Authentication Network,可逆认证网络) : 处理“上锁”并准备数据。
- IHN (Invertible Hiding Network,可逆隐藏网络) : 处理向封面图像中的实际嵌入。
让我们看看详细的架构:
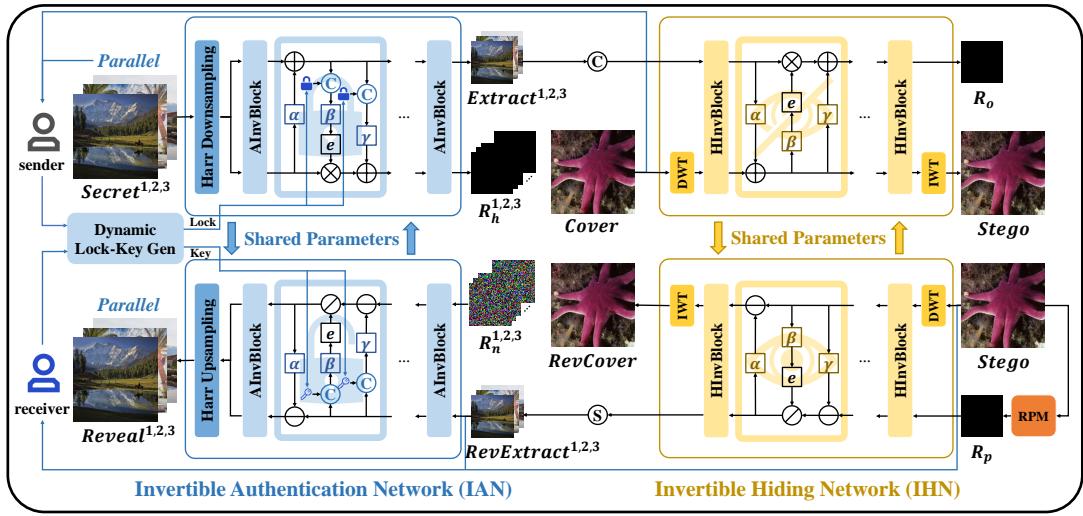
第一阶段: 可逆认证网络 (IAN)
IAN 是系统的“保镖”。它还不会接触封面图像;它只处理秘密图像。它的工作有两方面: 安全性和分布自适应 。
动态锁生成
静态密钥 (如所有人都用同一个密码) 是有风险的。如果一个泄漏,整个系统都会受到损害。AIS 使用了一个动态生成模块 。
它从特定的秘密图像中提取特征并生成一个唯一的、动态的锁。这意味着打开“秘密图像 A”的密钥在数学上是与“秘密图像 A”本身耦合的。
分布自适应与主要信息
这是核心创新点。IAN 不是试图隐藏完整的 RGB 秘密图像加上一把锁,而是将它们“融合”。
它通过可逆块处理秘密图像和锁。网络学习提取最本质的特征——称为主要信息 (Primary Information) (\(S_c\))——并将锁混合到这些数据中。
通过这样做,网络将锁和秘密图像这种“不一致”的分布转换为单一、统一的特征集,这更容易隐藏。它本质上将秘密和锁压缩成了一种仅包含 3 个通道的“易于隐藏的格式” (\(S_c\))。
条件概率流可以用数学描述。秘密图像 \(x\) 的分布是以锁 \(c\) 为条件的:
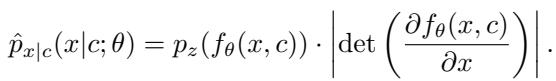
该方程确保了隐藏数据的分布被锁根本性地改变了。没有正确的锁 \(c\),分布就没有意义,图像也无法恢复。
第二阶段: 可逆隐藏网络 (IHN)
现在我们有了“注入锁的主要信息” (\(S_c\)),我们需要将其隐藏在封面图像中。这就是 IHN 的工作。
频域处理
注意图 3 中网络使用了Haar 下采样或 DWT (离散小波变换) 。 图像隐写术在频域 (分离低频颜色和高频细节/边缘) 效果最好,因为人眼对高频的变化不太敏感。
并行隐藏
这也是标题中“高效”一词的由来。在传统方法中,如果你有 3 个秘密,你需要先隐藏秘密 1,得到结果,再在结果中隐藏秘密 2,依此类推 (串行处理) 。
因为 IAN 已经将秘密预处理为紧凑的“主要信息”,IHN 可以并行隐藏多个秘密 。
它将封面图像的频率分量 (\(C_f\)) 与所有秘密图像的主要信息 (\(S_c^{1,2,3}\)) 拼接在一起,一次性送入可逆块中。
这种单次通过的方法意味着无论你要隐藏多少秘密,你只需要训练一个隐藏网络。
实验结果
这种两阶段、并行的方法真的有效吗?结果令人信服。
1. 视觉质量
隐写术的首要目标是不可见性。“隐写 (Stego) ”图像 (封面+秘密) 看起来应该与原始封面完全相同。

在图 4 中,请看残差 (Residual) 列 (原始图像与隐写图像之间的差异,放大 10 倍) 。
- ISN 和 DeepMIH (基线) : 你可以看到明显的“重影”或噪声模式。隐藏的数据正在干扰封面图像的像素。
- AIS (本文方法) : 残差几乎是黑色的。这意味着对封面图像的修改微乎其微,人眼几乎无法察觉。
量化数据也支持这一点。在下表 1 中,请看参数量 (Params) 和峰值信噪比 (PSNR) 。
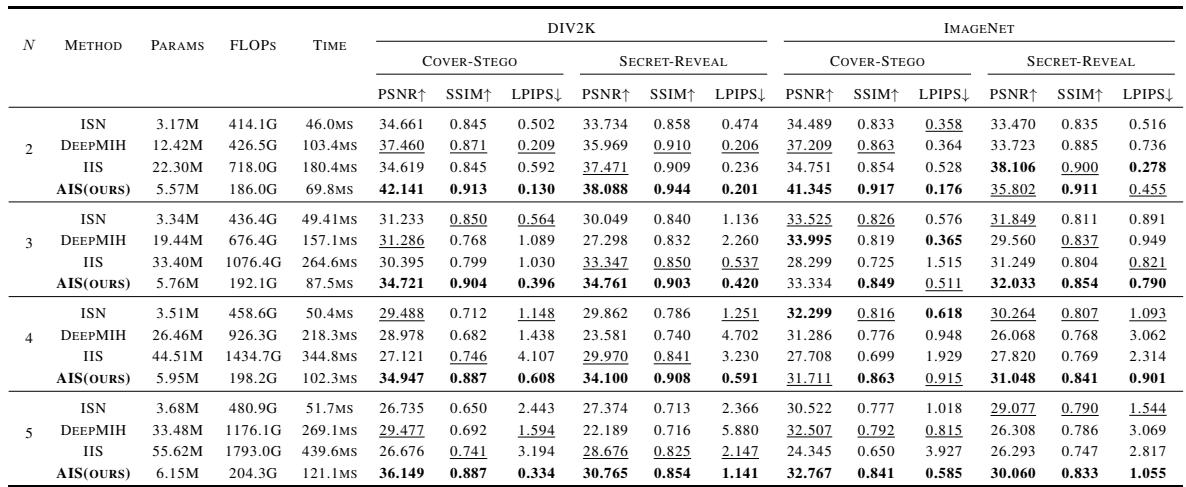
- 效率: 当隐藏 5 张图像 (N=5) 时,基线 IIS 需要 5562 万参数。AIS 仅需 615 万参数。这是一个巨大的缩减,使得模型轻量到足以在移动或边缘设备上运行。
- 质量: AIS 在隐写图像和提取的秘密图像上始终得分更高的 PSNR (质量更好) 。
2. 安全性分析
“分离认证”的主张需要经过测试。如果你尝试用错误的密钥解锁图像会发生什么?
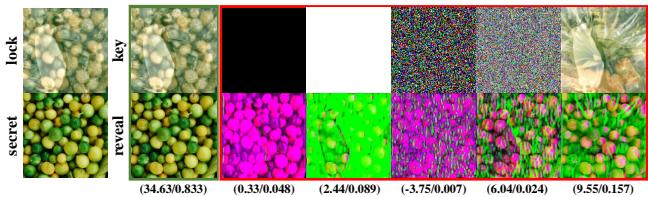
图 5 显示了使用错误密钥 (随机噪声、全零或来自不同图像的密钥) 的结果。输出是无法识别的噪点。这证实了 IAN 成功地将图像数据与锁纠缠在了一起。没有精确的密钥,秘密图像在数学上是无法访问的。
3. 隐写分析 (抗检测)
有一些 AI 模型专门设计用于捕捉隐写术 (隐写分析) 。一个稳健的方法应该能欺骗这些检测器。
研究人员使用 ManTraNet (一种最先进的伪造检测网络) 对 AIS 进行了测试。
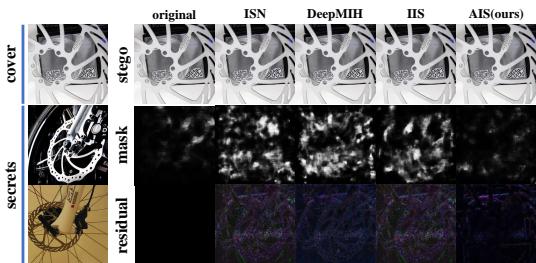
在图 6 中,白色像素代表 ManTraNet 认为隐藏了东西的区域。
- DeepMIH / IIS: 检测器亮起,清晰地勾勒出隐藏物体的轮廓。
- AIS: 输出大部分是黑色的。AIS 所做的修改非常微妙且分布良好,以至于检测器无法找到异常。
为何有效: 分布自适应的力量
你可能会想,为什么将过程分成两个阶段效果会好这么多?
研究人员认为,第一阶段 (IAN) 中的“分布自适应”是关键。通过在隐藏之前融合锁和秘密,网络创建了一种与封面图像更兼容的新数据表示。
我们可以直观地看到这种差异:

在图 10 中:
- 行 (a): 显示了单阶段方法中使用的原始“锁”。它们看起来像绿色的、混乱的噪声。隐藏这种“混乱”是很困难的。
- 行 (b): 显示了 AIS 提取的“主要信息”。它看起来像原始图像的紫色调版本。它保留了结构。对于神经网络来说,将结构化数据隐藏在结构化数据 (封面) 中,比隐藏随机噪声要容易得多。
此外,统计分析也证实了这一点。图 7(b) 比较了数据的统计分布 (均值与标准差) 。
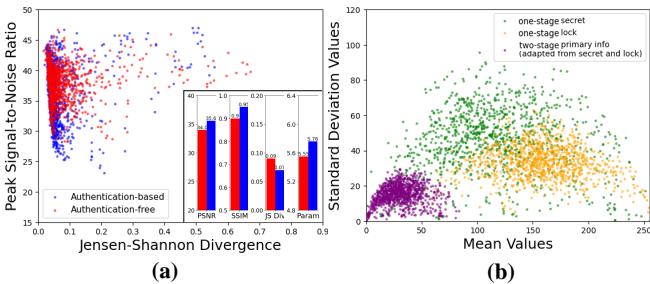
紫点 (AIS 主要信息) 的聚类方式与原始秘密或锁不同,表明网络已经学习到了一种紧凑的表示,最大限度地减少了“隐藏足迹”。
大容量潜力
最后,到底能隐藏多少东西?因为该模型只提取必要的“主要”信息,所以它节省了空间。研究人员推动模型在单张封面图像中隐藏了 8 张不同的秘密图像 。

如图 9 所示,即使隐藏了 8 张图像,“隐写”图像 (左上列) 看起来仍然非常干净,提取出的秘密 (中间列) 也非常详细。这种容量水平是传统的串行方法在不破坏封面图像的情况下难以实现的。
结论
高效分离认证图像隐写网络 (AIS) 代表了安全数据隐藏向前迈出的重要一步。通过重新思考架构——从单体式的“隐藏一切”模块转变为专门的认证阶段 , 随后是并行隐藏阶段——作者解决了权衡的三角关系:
- 安全性: 通过动态、可学习的锁实现。
- 质量: 通过分布自适应和频域嵌入实现。
- 效率: 通过并行处理实现,在大容量场景下减少了近 90% 的模型参数。
对于学生和研究人员来说,这篇论文展示了深度学习设计中宝贵的一课: 有时,将复杂问题解耦为专门的子网络,比试图强迫单个网络同时学习相互冲突的任务 (如隐藏结构化图像和随机锁) 要有效得多。
该项目的完整代码已在 GitHub 上开源,供想要尝试生成自己的带锁隐写图像的人使用。