](https://deep-paper.org/en/paper/8317_scaling_trends_in_languag-1757/images/cover.png)
AI 军备竞赛: 规模扩大能自动解决鲁棒性问题吗?
大型语言模型 (LLM) 的迅速崛起主要归功于一个简单而强大的概念: 缩放定律 (scaling laws) 。 我们从经验中得知,增加参数、数据和计算量能够持续解锁新的能力。从编写代码到通过律师资格考试,“越大越好”一直是 AI 繁荣时期的黄金法则。
但这种增长也有其阴暗面。虽然模型变得越来越强,但它们在对抗性攻击面前仍然顽固地表现出脆弱性。“越狱”——旨在诱骗模型生成有害内容的提示词——甚至困扰着最先进的系统 (如 GPT-4 或 Claude) 。随着模型被整合到从邮件过滤到自主代理等关键系统中,这些漏洞从单纯的新奇事物转变成了安全风险。
这就引出了一个至关重要的问题,而这个问题直到现在很大程度上仍未得到解答: “越大越好”的规则适用于安全性吗? 随着我们扩大模型规模,它们是自然而然地对攻击变得更具鲁棒性,还是仅仅变成了更聪明的靶子?
在这篇文章中,我们将深入探讨一项题为 “Scaling Trends in Language Model Robustness” (语言模型鲁棒性的缩放趋势) 的综合研究。研究人员跨越不同的模型家族 (Pythia 和 Qwen2.5) 、不同的规模 (从 700 万到 140 亿参数) 以及不同的攻击策略,进行了大规模的实证调查。他们的发现描绘了一幅攻击者与防御者之间正在进行的军备竞赛的复杂图景,其中计算量是弹药,而规模则是战场。
缩放视角
要理解 AI 安全的未来,我们不能仅仅看当前模型的快照。我们需要看趋势 。 这就是作者所说的“缩放视角”。
在标准的能力研究中,我们期望看到平滑的幂律曲线: 计算量翻倍,损失值可预测地下降。研究人员将这种严格的数学视角应用到了鲁棒性上。他们提出了以下问题:
- 攻击缩放: 如果攻击者将计算量翻倍 (运行攻击的时间更长) ,他们的成功率会增加多少?
- 防御缩放: 如果防御者将计算量翻倍 (在更多对抗性样本上训练) ,模型的鲁棒性会提高多少?
- 模型缩放: 如果我们只是把模型做大,它会变得更安全吗?
为了科学地回答这些问题,研究人员避开了模糊的“聊天机器人”评估 (因为很难评分) ,转而专注于分类任务 。
设置: 将 LLM 转化为分类器
评估模型是否“拒绝”了一个有害提示往往是主观的。为了获得确凿的数据,研究人员在标准分类任务上对 LLM 进行了微调,例如:
- 垃圾邮件检测 (Spam Detection) : 这封邮件是垃圾邮件还是正常邮件?
- 情感分析 (IMDB) : 这篇电影评论是正面的还是负面的?
- 合成任务: 比如“密码匹配 (PasswordMatch) ” (两个字符串是否匹配?) 或“单词长度 (WordLength) ” (哪个单词更长?) 。
通过强制 LLM 输出特定的类别 (例如,“SPAM”) ,研究人员可以运行精确的对抗性攻击。如果攻击迫使模型将原本判断正确的样本错误分类,则认为攻击成功。
该研究使用了两个主要的模型家族:
- Pythia: 一套参数范围从 14M 到 12B 的模型,专为缩放研究设计。
- Qwen2.5: 一个前沿模型家族,参数范围从 0.5B 到 14B。
第一部分: 被动鲁棒性的神话
论文的第一个主要发现挑战了一个普遍的假设。你可能会认为,一个 120 亿参数的模型,由于阅读了更多的文本并拥有更深层次的语言理解能力,自然会比一个微小的 1400 万参数的模型更难被欺骗。
事实证明, 仅靠规模并不是盾牌。
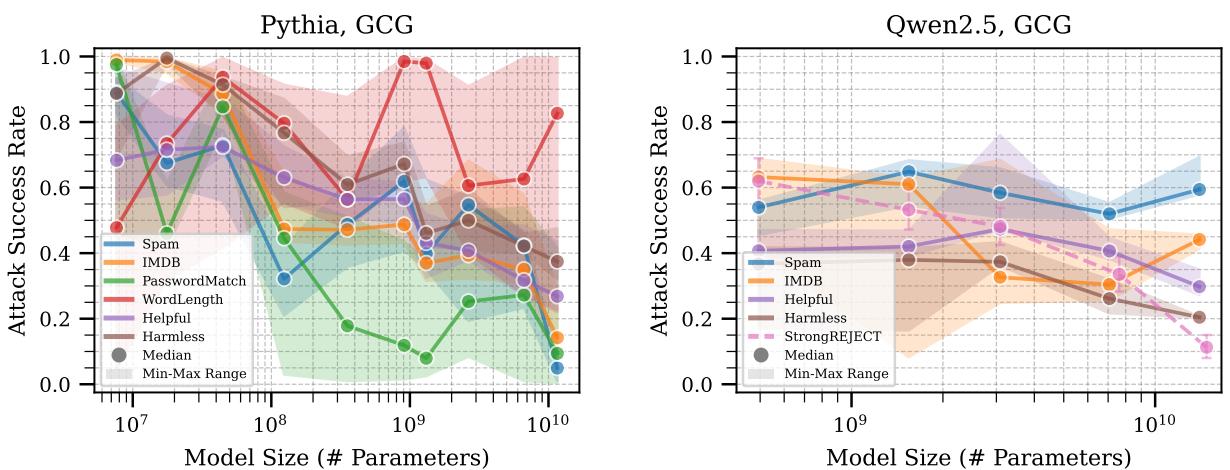
请仔细观察上面的图 2 。 图表绘制了攻击成功率 (y轴) 与模型尺寸 (x轴) 的关系。
- 左面板 (Pythia): 看那条蓝线 (垃圾邮件任务) 。随着模型变大 (向右移动) ,攻击成功率在某些区域实际上增加了,然后才下降。在单词长度任务 (红线) 上,模型尺寸似乎与鲁棒性几乎无关。
- 右面板 (Qwen2.5): 趋势更加平坦。虽然巨大的规模 (最右侧) 略有帮助,但不能保证更大的模型就更安全。
结论: 在没有明确进行安全训练的情况下,仅仅让模型变大并不能持续提高其鲁棒性。在某些情况下,更大的模型甚至可能更容易受到攻击,因为它们更忠实地遵循指令 (即使是恶意的指令) 。
攻击者的优势: 算力为王
如果模型尺寸不能保证安全,那么什么能保证攻击成功呢? 计算量 (Compute) 。
研究人员测试了几种攻击方法,包括 GCG (Greedy Coordinate Gradient,贪婪坐标梯度) 。 GCG 是一种优化方法,它寻找一串“乱码”字符 (对抗性后缀) ,当将其添加到提示词中时,会强制模型输出特定的目标内容。
研究发现,攻击成功率随着投入的计算量平滑增加。
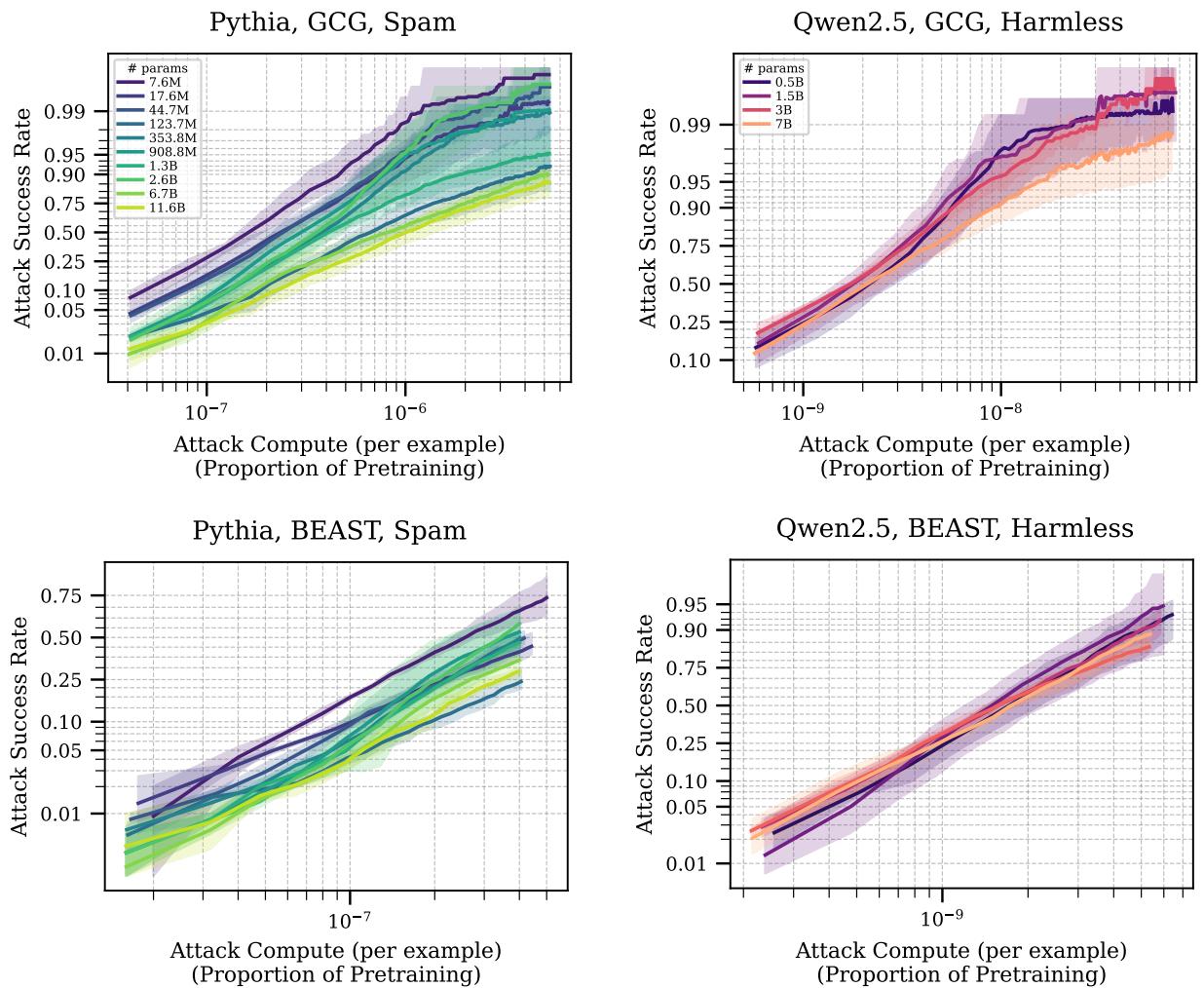
在图 3 中,我们看到了攻击者的投入 (花费的计算量) 与其成功率之间的关系。
- x轴代表攻击的计算成本 (相对于预训练的比例) 。
- y轴是攻击成功率 (ASR) 。
注意那一致的上升趋势。无论模型尺寸如何 (不同颜色的线) ,如果攻击者愿意花费更多的 FLOPs (浮点运算次数) 来更长时间地运行他们的优化算法,他们终将攻破模型。
有趣的是,看 Qwen2.5 的图 (右侧) ,不同模型尺寸的线条聚集在一起。这加强了之前的观点: 在拥有算力的坚定攻击者面前,70 亿参数的模型并不一定比 5 亿参数的模型难攻破多少。
第二部分: 防御者的反击 (对抗训练)
被动鲁棒性失效了。那么,当我们主动尝试防御模型时会发生什么?
防御的黄金标准是对抗训练 (Adversarial Training) 。 这是一个迭代过程,你需要:
- 取一个模型。
- 攻击它以生成对抗性样本 (欺骗它的数据) 。
- 在这些样本上训练模型以识别这种欺骗。
- 重复上述步骤。
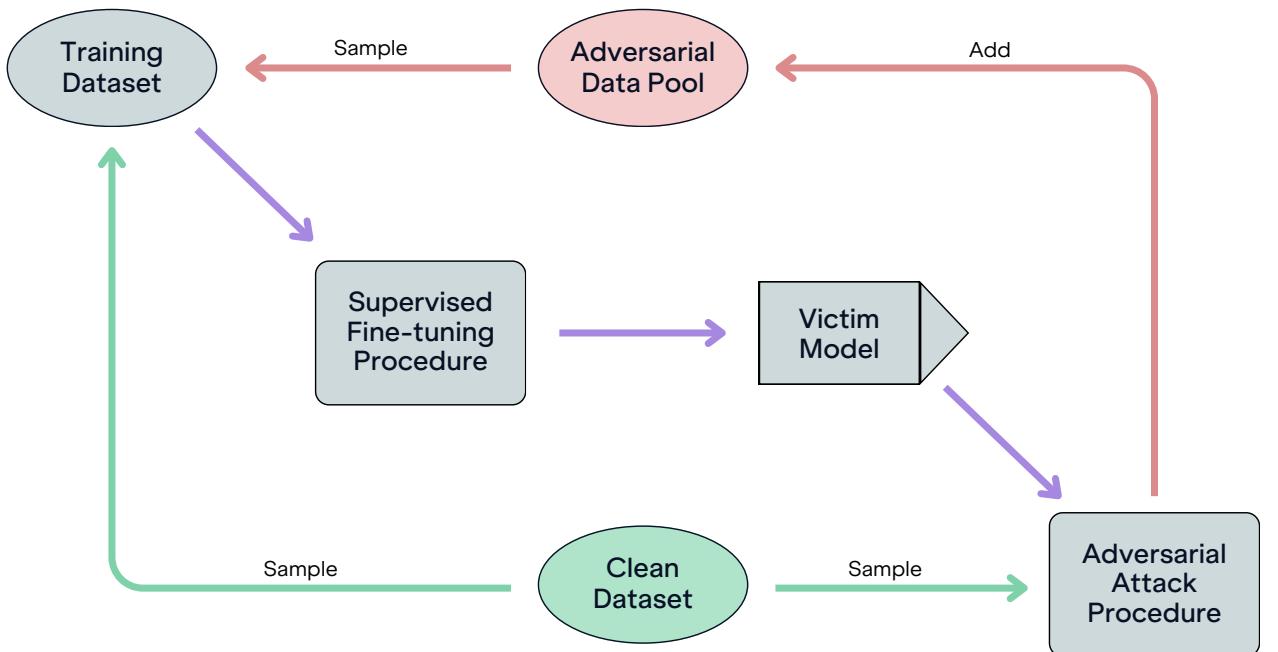
研究人员实施了如图 26 所示的循环。他们维护了一个不断增长的对抗性数据池,将其与干净数据混合以微调受害模型。
样本效率 vs. 计算效率
这是缩放行为变得迷人的地方。模型尺寸如何影响防御的学习?
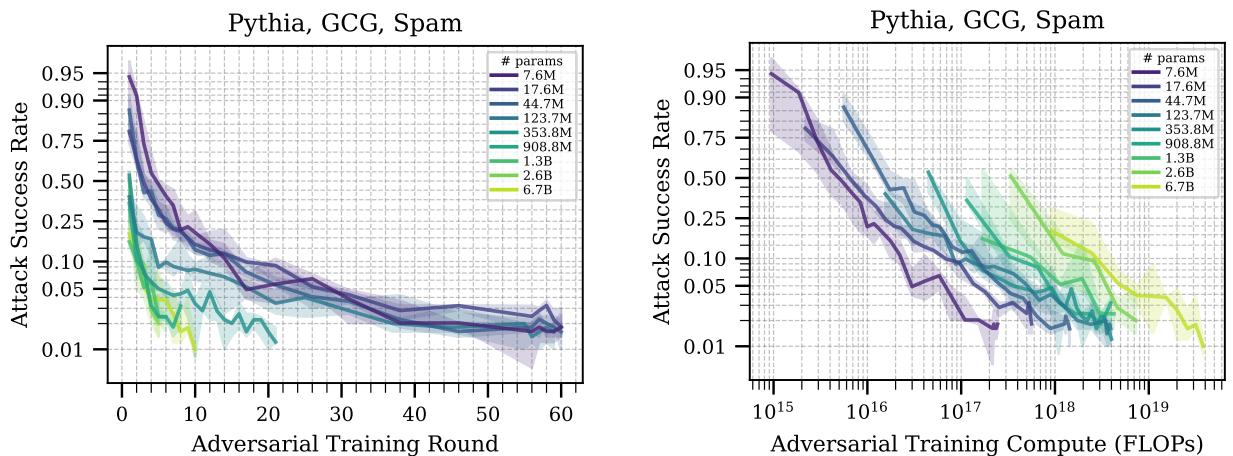
图 5 揭示了一个关键的权衡:
- 样本效率 (左图) : x轴是“训练轮数”。较大的模型 (浅色/黄色线) 比小模型 (深色/紫色线) 更快地降低攻击成功率。这意味着大模型更“聪明”——它们用更少的例子就能学会保护自己。它们更快地概括出“不要被欺骗”的概念。
- 计算效率 (右图) : x轴是“计算量 (FLOPs) ”。在这里,曲线发生了翻转或聚集。因为运行一个大模型非常昂贵,即使它在更少的步骤中学会了,要达到同样的安全水平,它花费的计算量也显著更多。
对于预算有限的防御者来说,保护一个小模型实际上更便宜。但对于不惜成本追求最大安全性的防御者来说,大模型学到的教训更透彻。
第三部分: 攻防平衡
我们已经确定攻击者和防御者都从计算量的扩展中受益。
- 攻击者花费计算量来寻找更好的越狱方法。
- 防御者花费计算量进行对抗训练来修补漏洞。
这就产生了一个动态的对抗博弈。 谁占据优势?
为了回答这个问题,研究人员将他们的数据整合成一个单一的、强大的可视化图表,比较攻击成本与防御成本。
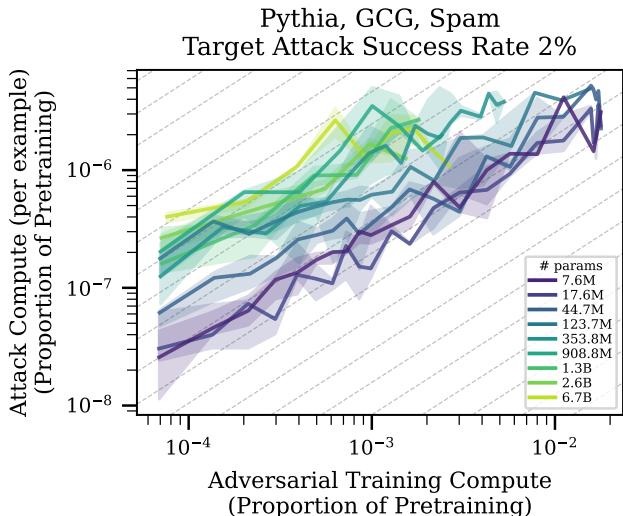
图 1 可以说是论文中最重要的一张图表。它绘制了:
- X轴: 防御计算量 (投入到对抗训练中的努力有多少) 。
- Y轴: 攻击计算量 (攻破模型 2% 的概率所需的努力有多少) 。
解读斜率: 灰色虚线代表斜率为 1。如果数据沿这条线分布,意味着防御支出每翻一倍,攻击者也必须翻倍支出才能攻破。这将是一种僵局。
现实情况: 彩色线的斜率普遍小于 1 。 这对防御者来说是坏消息。这意味着如果防御者将预算翻倍,攻击者只需要增加少于一倍的预算就能维持他们的成功率。在目前的机制下, 进攻比防御更具缩放优势。 破坏比建设更便宜。
希望 (截距) : 然而,看看线条的位置。大模型 (浅色线) 的线条位置更高且更靠左。这意味着虽然增长率有利于攻击者,但攻破一个经过对抗训练的大模型的绝对成本要高得多。
如果这些趋势持续下去——如果随着模型增长到 1000 亿或 1 万亿参数,曲线继续向“左上方”移动——我们可能会达到一个交叉点。最终,攻破前沿模型的初始成本可能会变得天价,以至于对于任何合理的对手来说都不可行,即使缩放斜率在理论上有利于他们。
鲁棒性迁移: 规模的隐藏力量
大模型还有最后的一线希望: 泛化能力 (Generalization) 。
在现实世界中,防御者不知道究竟会有什么攻击方法被用来对付他们。他们针对攻击 A 进行训练,但黑客可能会使用攻击 B。
研究人员通过训练模型防御 GCG 攻击,然后使用另一种称为 BEAST 的攻击方法,以及不同的威胁模型 (比如将攻击字符串放在提示词的中间而不是末尾) 来评估它们。
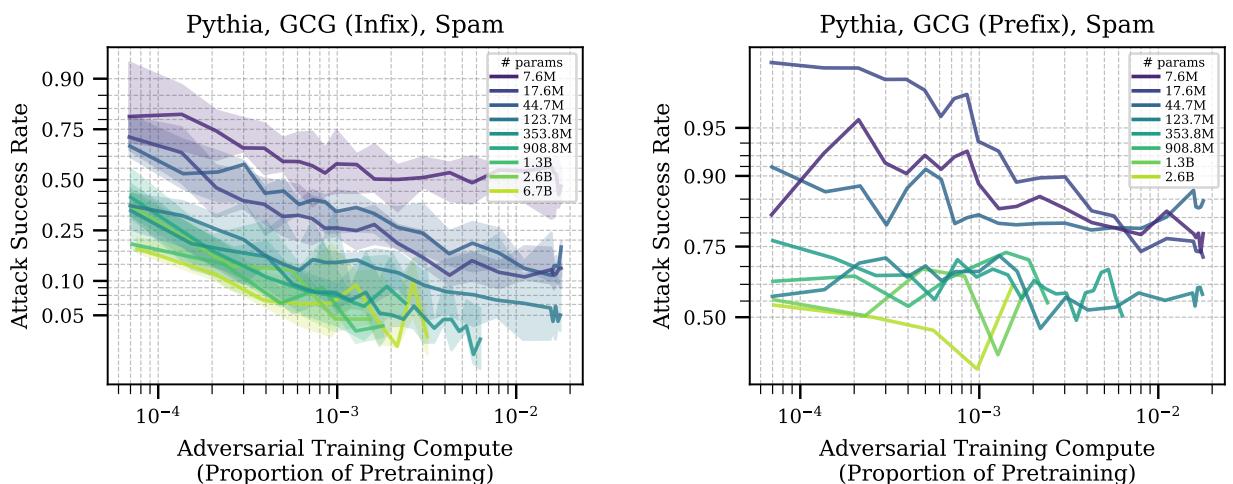
图 7 展示了这种迁移的结果。
- 左图 (中缀攻击) : 对抗训练 (针对后缀攻击进行) 能够相当好地迁移到“中缀”攻击 (插入在中间) 。关键是, 更大的模型 (浅色线) 迁移效果更好。 它们的曲线下降得更低,意味着它们更擅长将防御应用到略有不同的情况中。
- 右图 (前缀攻击) : 当攻击被移到提示词的开头 (前缀) 时,几乎所有模型的迁移都失败了。这是“分布外 (out of distribution) ”的情况。
然而,观察攻击算法之间的迁移 (例如,在 GCG 上训练并在 BEAST 上测试) ,通常显示防御确实可以迁移,并且大模型通常拥有更强的能力将安全训练泛化到未见过的攻击上。
结论: 持久战
这篇题为 “Scaling Trends in Language Model Robustness” 的论文为 AI 安全提供了一个冷静的、数据驱动的视角。它打破了规模本身就能解决安全漏洞的迷思。
以下是给学生和从业者的主要启示:
- 没有免费的午餐: 你不能简单地训练一个更大的模型就期望它是安全的。没有特定的防御训练,140 亿参数的模型和 5 亿参数的模型一样脆弱。
- 军备竞赛目前有利于进攻: 目前,攻击一个模型的计算效率比防御它更高。随着算力变得更便宜,攻击者获得了优势。
- 规模是防御者的希望: 尽管攻击者有优势,但规模改变了竞技场。更大的模型是样本效率更高的学习者,并且能更好地泛化其防御能力。
作者得出了一个微妙的结论。虽然缩放曲线的斜率目前有利于攻击者,但大模型所能支持的防御绝对量级最终可能会扭转局面。如果我们继续同时扩大模型规模和对抗训练,我们最终可能会制造出这样的模型: 成功攻击的成本超过任何合理对手的资源。
在那之前,猫鼠游戏仍将继续——而算力则是这个领域的通行货币。