
人类拥有令人赞叹的能力——可以快速学习新事物。给一个孩子看一张长颈鹿的图片,他们可能终生都能认出长颈鹿。让一位经验丰富的程序员学习一门新语言,他们常常能在几天内就熟练使用,借助的是已有的知识体系。这种快速适应能力正是人类智能的显著特征。
相比之下,我们最强大的深度学习模型依然“数据饥渴”,适应速度缓慢。它们可以在特定任务上表现出超人般的能力——比如下围棋或分类数百万张图像——但这一切的前提是,在海量数据集上经过数千小时的训练。如果哪怕任务稍有变化,模型往往就需要从零开始重新训练。
人类与机器在学习方式上的这种差异,催生了一个令人兴奋的研究方向——元学习 (meta-learning) , 或称“学会学习”。其愿景是构建能够像人类一样,从多任务经验中迁移知识,仅凭少量样本就掌握全新任务的模型。
本文将探讨该领域的一个里程碑式成果: 《一种简单的神经注意力元学习器》 (A Simple Neural Attentive Meta-Learner) 。 研究者提出了 SNAIL , 一种简单而强大的架构,在多个元学习基准测试中取得了突破性成绩。SNAIL 巧妙地将神经序列建模中的两个关键组件——时间卷积和注意力机制——融合在一起,从而有效克服了元学习模型长期存在的记忆瓶颈。
究竟什么是元学习?
在深入探讨 SNAIL 之前,让我们先澄清一下元学习的含义。
在传统机器学习中,模型学习的是针对单一静态任务的输入与输出映射关系——例如图像中的动物分类。我们向它提供大量的猫与狗的样例,它学会了在同一数据分布下对新图像进行正确分类。
元学习则进一步提升了这一学习层次。 元学习器 (meta-learner) 并非在一个任务上训练,而是面向一个任务分布进行学习。每个任务都有自身的样本与目标,而元学习器的目的是掌握如何学习——即提炼一种可泛化的任务求解策略。
想象训练一个元学习器来解决数百个小型分类挑战,例如猫 vs. 狗、汽车 vs. 卡车、苹果 vs. 橙子。它并非记住具体的类别,而是学习分类这一过程的基本机制。当面对一个全新的任务——比如只凭少量样本去区分两种花——它可以快速推断出解决方案。
从数学上看,该目标可以形式化为最小化任务分布 \( \mathcal{T} \) 上的期望损失:
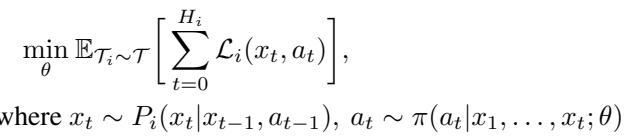
每个任务 \( T_i \) 提供输入–输出样本,元学习器的参数 \( \theta \) 经优化以最小化所有任务的平均损失,从而实现对新任务的快速适应。
在测试阶段,元学习器将面对来自相似但未见过的分布 \( \tilde{\mathcal{T}} \) 的任务,并需要像人类学习新技能那样,仅凭有限数据实现适应。
元学习中的记忆瓶颈
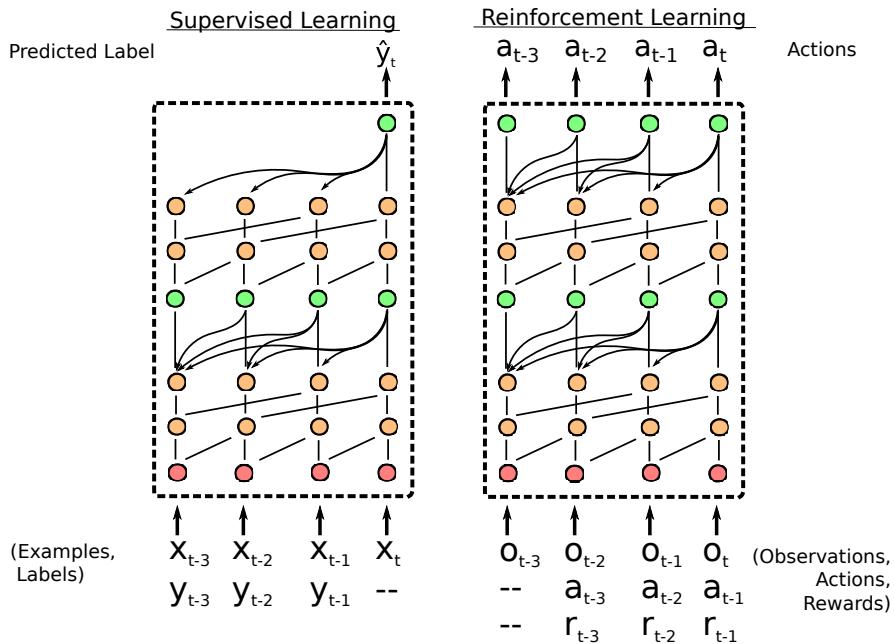
元学习任务天然具有序列特性: 模型逐步观察数据点,并需基于所有先前的经验做出预测。这提示我们可以使用循环神经网络 (RNN) , 如 LSTM 或 GRU,它们通过内部隐藏状态保留记忆。
但这种方法存在显著缺陷。传统 RNN 按时间步依次传播信息,要回忆很久之前的内容,就必须将该信息不断压缩穿过所有中间隐藏层。随着序列变长,旧信息逐渐衰减或被扭曲,形成所谓的记忆瓶颈 。
为克服这一问题,一些研究者尝试采用硬编码的学习策略。例如, 模型无关元学习 (MAML) 显式利用梯度下降作为学习机制,寻找一组可以快速微调到新任务上的初始参数。虽然效果不错,但此类硬编码方案限制了通用性。真正灵活的元学习器应能自主发现学习算法,而非被规定如何适应。
这一挑战——构建能存储、检索并推理过去经验的模型——正是促成 SNAIL 诞生的动因。
探秘 SNAIL: 简单而强大的方法
SNAIL 背后的关键思想十分直观: 序列建模中的两种强大技术——时间卷积 (temporal convolutions) 与因果注意力 (causal attention) ——提供了互补能力。将二者结合,模型既能进行高效局部推理,又能实现灵活远程记忆访问。
- 时间卷积 (TCs) : 高效的局部推理
- 定义: 一维时间卷积,可并行处理序列。作者使用了因果卷积,确保时间 \( t \) 的输出仅依赖于此前的时间步。
- 优点: 提供高带宽的局部上下文,使模型能细致地处理短期依赖关系。
- 缺点: 上下文范围有限。若要记住远距离事件,需要指数级扩大的空洞率堆叠层,这会导致远程访问信息粗糙。
- 因果注意力: 精准的长程记忆
- 定义: 注意力机制计算序列中元素间的加权关联,每个时间步产生一个查询 (query) ,与所有过去的键 (key) 对比,从而检索相关值 (value) 。
- 优点: 可准确定位并获取序列中任意位置的重要信息,无论距离多远。
- 缺点: 标准注意力忽略时间顺序,将序列视作无序集合,从而限制时间依赖建模。
通过交替结合两种机制,SNAIL 在获取短期上下文与长期记忆间取得平衡。
SNAIL 在时间卷积与因果注意力层之间交替堆叠,使其既能高效聚合上下文,又能灵活回忆关键细节。
在监督学习中,SNAIL 顺序处理样例–标签对,并预测新样例的标签。在元强化学习中,它顺序处理观测–动作–奖励三元组,随着情境变化持续调整策略。
构建模块
SNAIL 的架构是模块化设计,由两个核心组件组成:
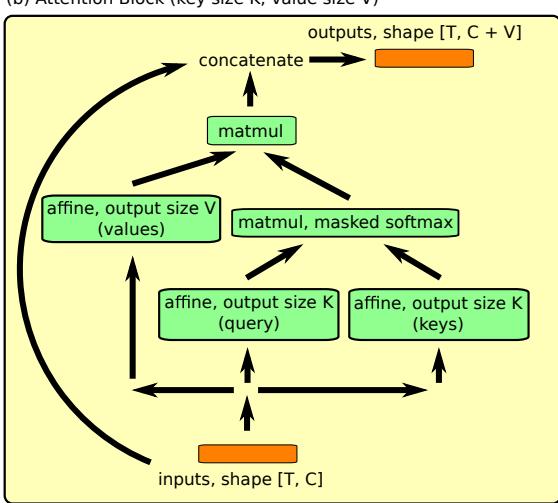
(a) 密集块执行因果卷积并与输入拼接。(b) 注意力块执行因果键值匹配,选择性地提取过去的信息。
密集块 (Dense Block) : 时间卷积层的核心。每个密集块执行一次空洞因果卷积,并将输出与原始输入拼接,从而保留跨层信息。通过堆叠具有指数级增长空洞率的密集块,可高效扩展感受野范围。
注意力块 (Attention Block) : 实现因果自注意力。每一时间步的输入被映射为查询、键和值。查询通过掩码 softmax 操作仅访问过去的时间步,防止模型窥视未来信息。
通过交替使用这两类模块,SNAIL 构建出能直接从序列数据中习得复杂算法的深度网络。
实验: 检验 SNAIL 的实力
作者在多个标准基准任务上评估了 SNAIL,涵盖监督式小样本学习与强化学习 , 并与专门方法及强基线进行了比较。
小样本图像分类
小样本分类是元学习的经典任务: 在仅有每类 \( K \) 个样本的情况下,学习区分 \( N \) 个类别。
- Omniglot: 包含超过 50 种字母的手写字符,被称为“元学习界的 MNIST”。
- Mini-ImageNet: ImageNet 的高难度子集,视觉多样性与复杂度更高。
SNAIL 在 5-way 与 20-way 任务下、1-shot 与 5-shot 设置中均取得了领先成绩,超越以往所有方法,包括专门设计的网络与早期元学习算法。
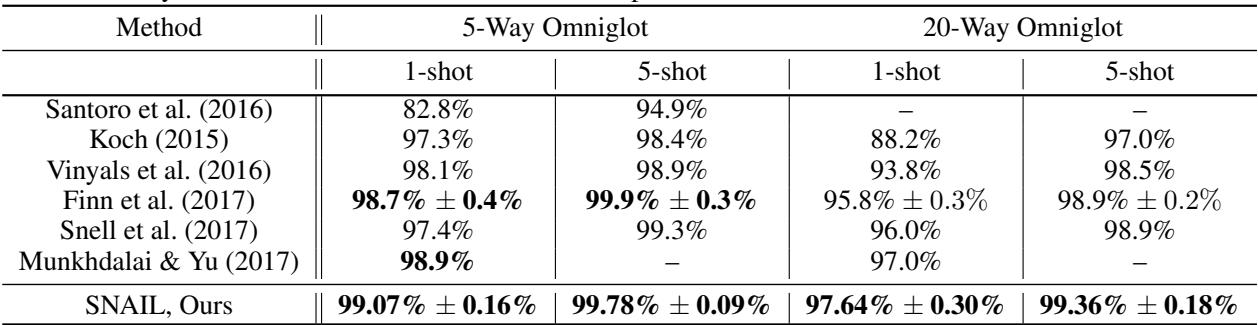
在 Omniglot 数据集中,SNAIL 准确率几乎达到完美,超越专为小样本分类设计的模型。
在更具挑战性的 mini-ImageNet 数据集上,提升尤为显著。
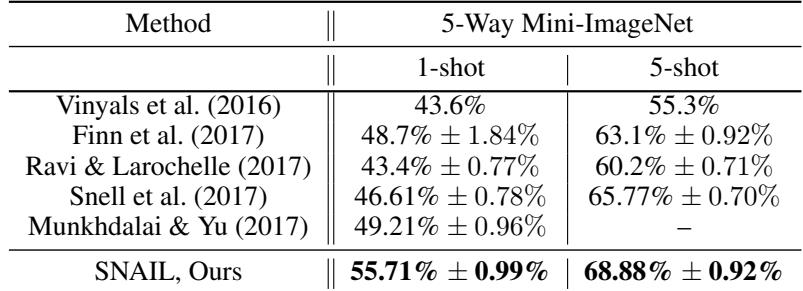
在 1-shot 场景中,SNAIL 的准确率比所有先前模型高出 6% 以上,凸显出其架构的强大优势。
更重要的是,消融实验证实这些提升源于核心设计本身,而非更好的图像嵌入。去掉时间卷积或注意力机制中的任意一个都会导致性能下滑,说明两者均为关键组成。
强化学习
研究者进一步在多样化的元强化学习任务中验证 SNAIL,其中智能体需学习策略并在不同环境中自适应。
1. 多臂老虎机与表格型马尔可夫决策过程 (MDP)
任务要求智能体平衡探索 (尝试多种动作以获取知识) 与利用 (选择当前最优动作) 。SNAIL 成功习得高效探索策略,甚至超过具备理论最优保证的传统算法。
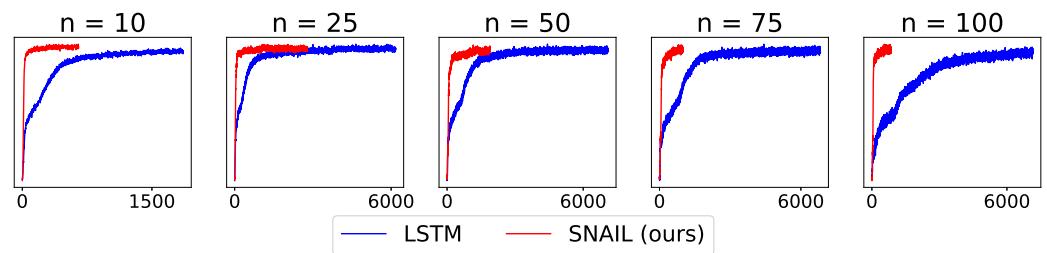
在多种设置下,SNAIL 展现出比传统基于 LSTM 的元学习器更快的学习速度与更高的回报。
2. 连续控制
在物理控制任务中,如操控模拟机器人 (蚂蚁与猎豹) ,SNAIL 能快速适应未见目标——学习向前或向后跑,或匹配指定速度。MAML 需多次梯度更新才能调整,而 SNAIL 几乎能即时适应。
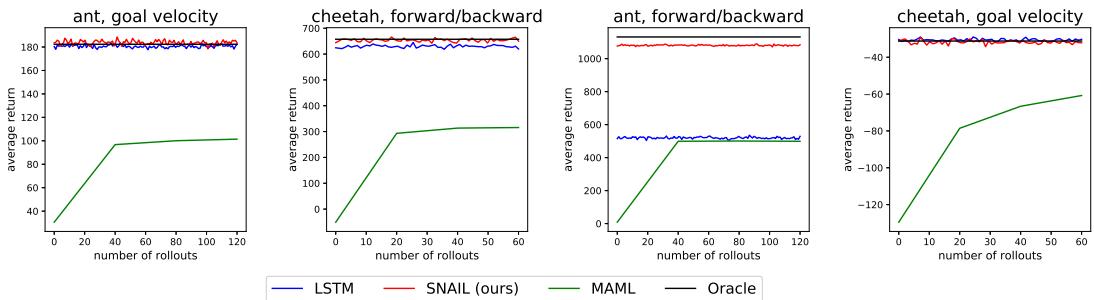
SNAIL 的即时适应反映了其在最初几步中就能识别任务结构的学习能力。
3. 视觉导航
最直观的展示来自视觉导航任务。在该任务中,智能体必须仅凭第一人称视觉在迷宫中寻找目标。它在每个迷宫中进行两次试验。
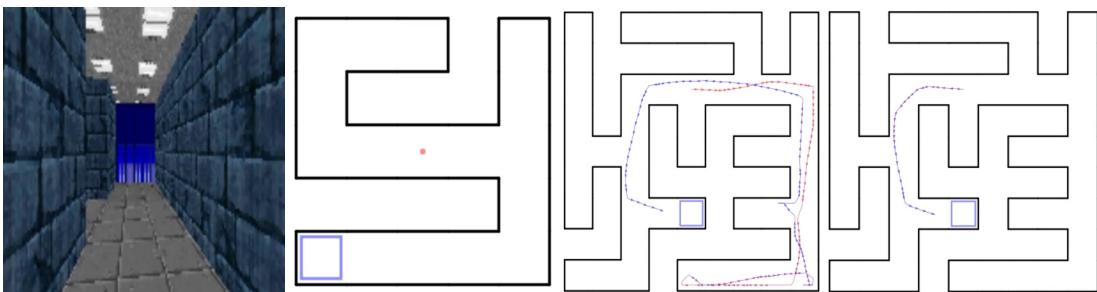
SNAIL 在首次试验中探索环境,随后在第二次试验中精准回忆目标位置并直接到达,展现出类似人类的学习行为。
量化结果进一步说明其表现:
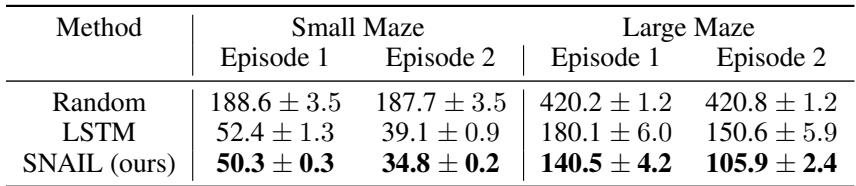
SNAIL 找到目标的速度最快,并在试验间显示出最大性能提升,体现其卓越的记忆与适应能力。
结论: 强大学习器的简洁之道
SNAIL 架构彰显了设计中的“简而不凡”。通过融合时间卷积与因果注意力,模型有效突破了此前元学习器的记忆瓶颈。无需依赖手工策略或领域特定调整,它便能在多样环境中快速推断、推理与适应。
SNAIL 的成功表明,真正的灵活性与组合性 , 而非复杂性,才是构建自适应智能的关键。这不仅是元学习领域的一次重要进步,更是一份构建能够真正学会如何学习的模型的蓝图。