](https://deep-paper.org/en/paper/8491_large_language_model_driv-1758/images/cover.png)
在计算机科学和运筹学领域,规模扩展 (Scaling) 是终极挑战。解决十辆送货卡车的物流问题可能只是个作业;但要解决一万辆卡车、不断变化的交通状况和时间窗口限制的问题,简直就是计算噩梦。
这些巨大的挑战通常被构建为混合整数线性规划 (MILP) 问题。虽然我们拥有像 Gurobi 和 SCIP 这样强大的商业求解器,但在问题规模爆炸式增长时,它们往往会遇到瓶颈。搜索空间呈指数级增长,使得在合理的时间范围内找到精确解变得不可能。
多年来,研究人员一直依赖启发式算法 (heuristics) ——即捷径或“经验法则”——来快速找到足够好的解。但设计这些启发式算法需要深厚的专家知识和长达数月的反复试验。最近,我们看到机器学习 (ML) 试图学习这些启发式算法,但深度学习模型往往难以泛化,并且需要海量且昂贵的训练数据集。
LLM-LNS 登场了,这是清华大学研究人员在 2025 年的一篇论文中提出的新框架。这种方法本质上是在问: 如果与其训练神经网络来解决问题,不如让大语言模型 (LLM) 编写求解算法的代码,会怎么样?
在这篇深度文章中,我们将探讨 LLM-LNS 如何利用双层自进化智能体来自动化设计优化算法,并在极少训练数据的情况下,在大规模问题上取得最先进的结果。
核心问题: MILP 与邻域搜索
在剖析解决方案之前,让我们先明确问题。混合整数线性规划 (MILP) 问题的数学形式如下:
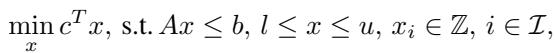
你需要最小化成本 (\(c^Tx\)) ,同时满足约束条件 (\(Ax \leq b\)) ,其中某些变量必须是整数 (\(x_i \in \mathbb{Z}\)) 。
精确求解器的局限性
像分支定界法 (Branch-and-Bound) 这样的精确算法试图探索整数组合树。对于小问题,它们非常完美。对于大规模问题 (例如数百万个变量) ,它们在计算上是不可行的。
LNS 替代方案
为了处理大规模问题,从业者使用大邻域搜索 (LNS) 。 其逻辑直观明了:
- 从一个解开始 (即使是一个很差的解) 。
- 破坏 (Destroy) : 将大多数变量固定为当前值,但“释放”其中的一小部分。这就创建了一个“邻域”。
- 修复 (Repair) : 使用精确求解器仅优化那一小部分自由变量。
- 重复此过程,直到解足够好。
LNS 中最关键的问题是: 你释放哪些变量? 如果你随机选择变量,求解器将无法找到改进。你需要一个聪明的策略来选择一个可能包含更好解的“邻域”。设计这种策略通常需要运筹学的博士学位。
LLM-LNS 登场: 自动化算法设计
研究人员提出了 LLM-LNS , 这是一个 LLM 充当智能代理的框架,用于生成邻域选择策略 (即选择要释放哪些变量的代码) 。
这不是一个静态过程。LLM 不仅仅是一次性编写代码;它会进化代码。该框架的功能就像一个生物进化模拟器,其中的“生物”是 Python 函数,“适应度”是这些函数解决 MILP 问题的能力。
系统架构
该架构的新颖之处在于它将进化过程分为两个不同的层。
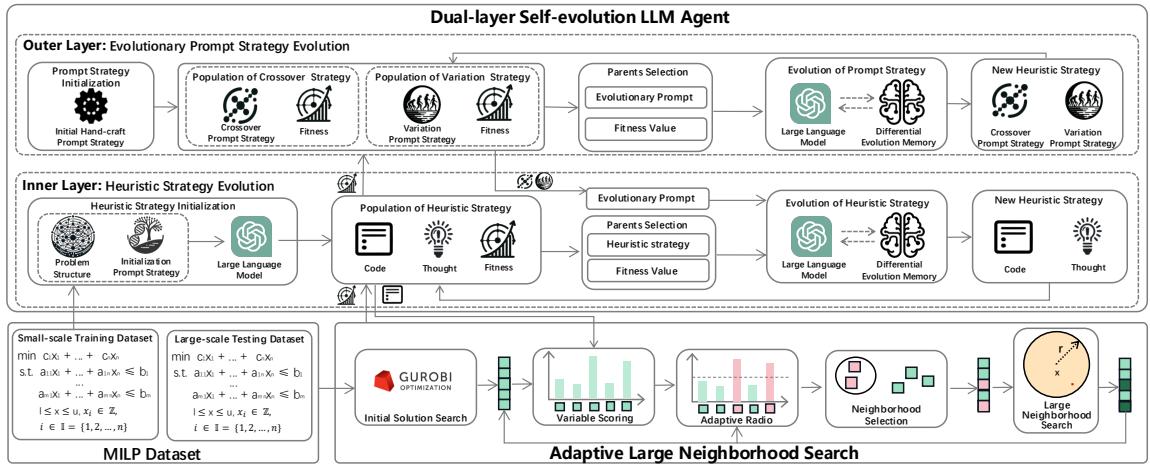
如上图 1 所示,该框架包括:
- 外层 (策略家) : 进化提示词策略 (Prompt Strategies) 。 它弄清楚如何要求 LLM 提供更好的代码 (例如,“尝试关注高成本变量”与“尝试增加随机性”) 。这保持了多样性。
- 内层 (执行者) : 进化启发式策略 (Heuristic Strategies) 。 它接收提示词并编写实际的 Python 代码。它快速迭代以收敛到一个有效的算法。
- 差分记忆: 一个反馈循环,帮助 LLM 从过去的成功和失败中学习。
让我们分解这些组件。
1. 双层自进化机制
为什么要分两层?以前的尝试,如 FunSearch 或 Evolution of Heuristics (EOH) , 主要集中在进化代码 (启发式算法) 本身。问题在于 LLM 可能会陷入“局部最优”——即使效果不佳,它们也会不断生成相同代码结构的变体。
外层充当多样性管理者。如果内层 (代码生成器) 停滞不前且停止改进,外层会检测到这一点并进化提示词本身。它可能会将指令从“提高效率”切换为“探索一种完全不同的数学方法”。
这种协同作用使系统能够平衡开发 (Exploitation) (在内层完善好的代码) 和探索 (Exploration) (通过外层尝试新想法) 。
2. 用于定向进化的差分记忆
标准的进化算法通常依赖于随机交叉 (结合两个父代) 和变异。然而,LLM 是聪明的——它不需要依赖随机性。它可以推理。
研究人员引入了差分记忆 (Differential Memory) 。 系统不只是给 LLM 两个父代算法并说“结合这些”,而是为 LLM 提供好策略和坏策略的历史记录及其性能评分。
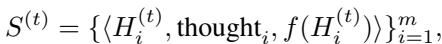
系统向 LLM 提供一组元组 \(S^{(t)}\),其中包含代码 (\(H\)) 、推理过程 (“thought”) 和适应度评分 (\(f\)) 。
然后,系统提示 LLM 明确地从表现好和表现差的策略之间的差异中学习。它要求 LLM 识别是什么让好的策略奏效而坏的策略失败,从而充当优化器而不仅仅是文本生成器。
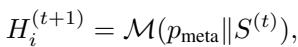
3. 进化路径
这在实践中是什么样子的?下图可视化了智能体在解决装箱问题 (Bin Packing) 的 20 代进化过程中的“思维”。
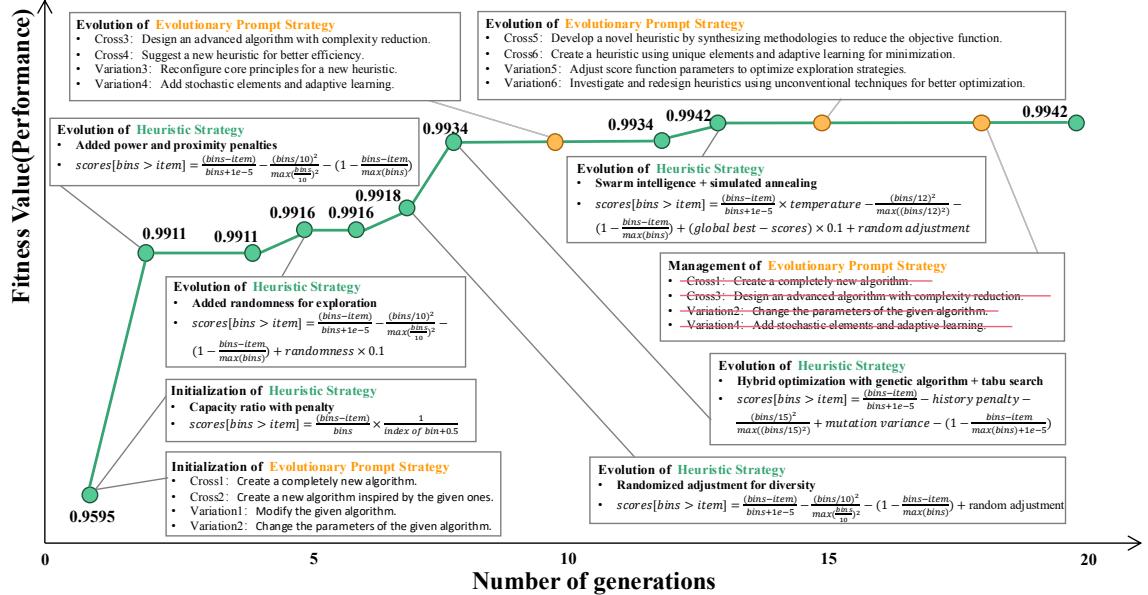
注意这个轨迹:
- 第 0 代: 智能体从基本的直觉逻辑开始 (例如,“容量比率惩罚”) 。
- 第 5-8 代: 它意识到自己陷入了困境,因此引入了“随机性”和“混合优化” (遗传算法 + 禁忌搜索) 。
- 第 12 代以上: 它进化出了复杂的“群体智能”概念。
适应度值 (绿线) 稳步攀升。这里的关键点是,LLM 自行发明了这些复杂的策略 (模拟退火、禁忌搜索) 来解决手头的特定问题。
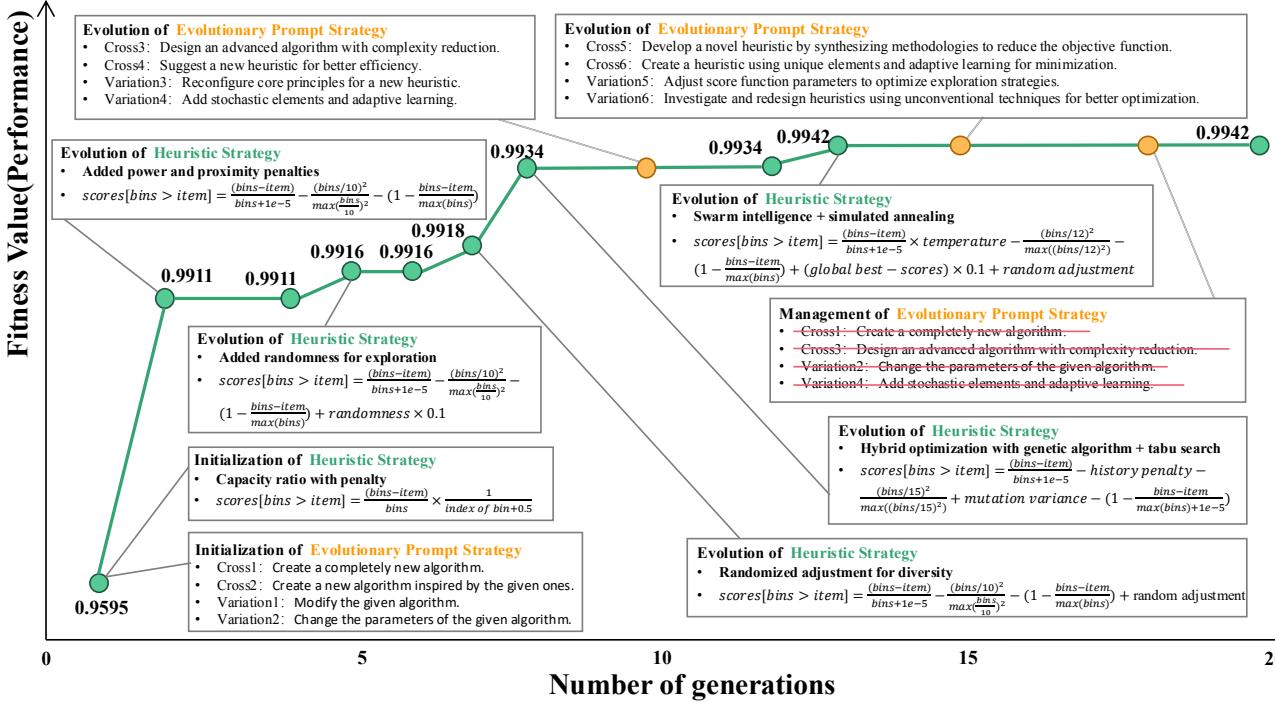
下图更详细地展示了具体代码和思维过程的进化。你可以看到随着“提示词”从简单的指令演变为关于参数设置的复杂指令,代码也变得越来越复杂。
应用: 自适应大邻域搜索 (ALNS)
LLM 生成的代码并不直接解决 MILP;它是作为自适应大邻域搜索 (ALNS) 循环中的“评分函数”运行的。
生成的 Python 函数接收问题的当前状态 (变量、约束) ,并为每个变量输出一个分数。然后,ALNS 算法选择前 \(k\) 个变量进行“破坏” (释放以进行优化) 。
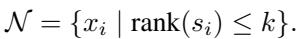
通过在小规模问题 (数千个变量) 上进行训练,LLM 学习到了关于哪些变量“重要”的一般规则。令人惊讶的是,这些规则在无需重新训练的情况下,就能很好地扩展到大规模问题 (数百万个变量) 。
实验结果
研究人员在两个方面验证了 LLM-LNS: 组合优化 (标准谜题) 和大规模 MILP (工业级数学问题) 。
1. 组合优化: 击败 FunSearch
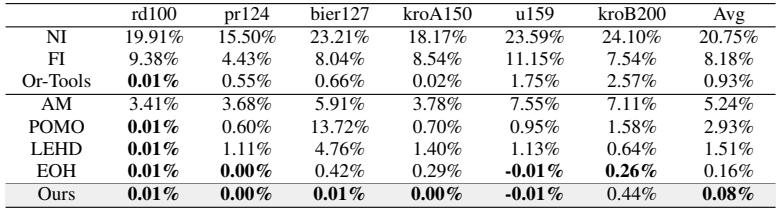
首先,他们在在线装箱 (Online Bin Packing) 问题上测试了智能体。他们将 LLM-LNS 与 FunSearch (DeepMind 的 Nature 论文方法) 和 EOH 进行了比较。

在表 2 (上图) 中,数字越低越好 (使用的多余箱子越少) 。LLM-LNS 取得了 1.63% 的平均得分,显著优于 FunSearch (2.31%) 和 EOH (2.09%)。这证明了双层智能体是比以前基于 LLM 的方法更好的“算法设计者”。
他们在旅行商问题 (TSP) 中也观察到了类似的优势,LLM-LNS 发现的启发式算法使解决方案比 POMO 或 LEHD 等神经基线方法更接近最优解。
2. 重头戏: 大规模 MILP
终极测试是将此应用于 MILP 数据集: 集合覆盖 (SC) 、最小顶点覆盖 (MVC) 、最大独立集 (MIS) 和背包问题 (MIKS) 。
他们在小实例上训练智能体,并在拥有多达 200 万个变量的大规模实例上进行测试。

表 4 展示了关键结果。以下是列代表的含义:
- Gurobi/SCIP: 黄金标准的商业和开源求解器。
- GNN&GBDT / Light-MILPOPT: 使用图神经网络的现代机器学习方法。
- LLM-LNS (Ours): 本文提出的方法。
结果: 在几乎每一个大规模实例上,LLM-LNS 都能比 Gurobi 和 SCIP 找到更好的解 (最小化问题更低,最大化问题更高) 。值得注意的是,在巨大的 SC2 (集合覆盖) 实例上,LLM-LNS 找到的解成本为 158,878 , 而 Gurobi 卡在 320,240 。 这是一个巨大的效率差距。
此外,传统的 ML 方法如 GNN&GBDT 完全无法解决背包问题 (MIKS) (由 * 表示) ,而 LLM-LNS 则能稳健地处理这些问题。
3. 收敛速度
这不仅仅关乎最终分数;还关乎达到目标的速度。
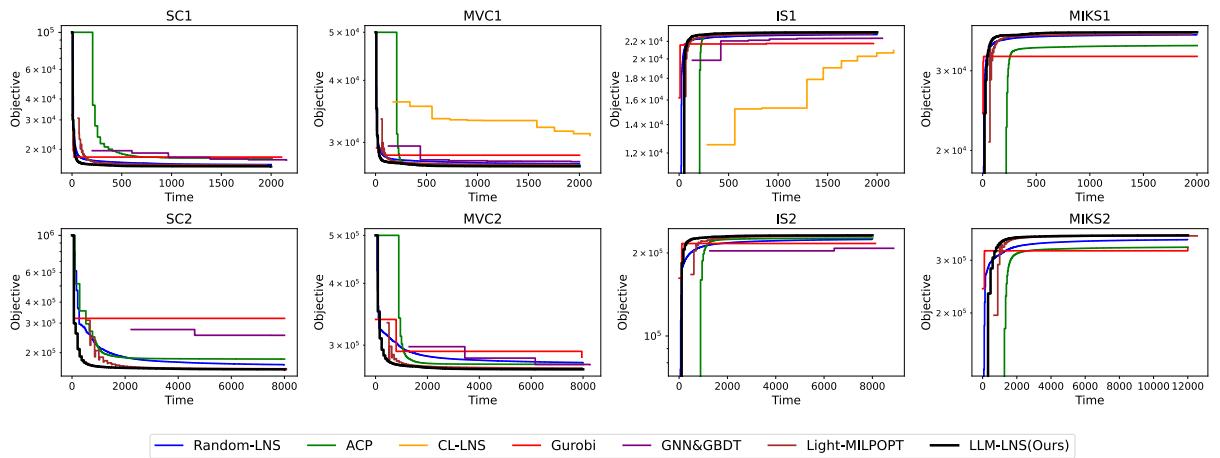
在图 3 中,黑线代表 LLM-LNS。你可以看到它的下降 (改进) 速度始终快于其他彩色线条。在 SC2 和 MVC2 图中,差异非常明显——LLM 驱动的方法几乎立即就能找到高质量的解,而传统求解器则难以取得进展。
这为何重要?
这项研究代表了我们处理优化问题方式的范式转变。
- 克服冷启动: 传统的 ML 需要海量的已解决问题数据集来“学习”启发式算法。LLM-LNS 只需要几个小例子,因为 LLM 已经具备了一般的推理和编码能力。
- 可扩展性: 大多数在小图上训练的神经网络在应用于大 100 倍的图时都会失败。LLM-LNS 生成的是逻辑 (代码) ,而不仅仅是权重。像“优先考虑系数高的变量”这样的逻辑,无论你有 100 个还是 1,000,000 个变量,都是有效的。
- 可解释性: 因为输出是 Python 代码,人类专家可以阅读启发式算法。你可以查看在第 20 代生成的代码,并理解算法为什么做出这些决定。
结论
LLM-LNS 成功地证明了,大语言模型不仅仅能聊天或总结文本;它们还可以充当自动化研究员。通过将 LLM 封装在具有差分记忆的双层进化框架中,研究人员创建了一个能够设计出优于人类专家或传统深度学习的优化算法的系统。
随着我们在能源网、供应链和制造业中迈向日益复杂的全球系统,自动设计可扩展、高效算法的能力将成为一个关键工具。LLM-LNS 便是朝这个方向迈出的重要一步。