](https://deep-paper.org/en/paper/9408_mechanistic_unlearning_ro-1600/images/cover.png)
引言
想象一下,你训练了一个庞大的大型语言模型 (LLM) 。它聪明、善辩且博学。不幸的是,它同时也记住了一位名人的家庭住址,或者学会了某种化学武器的危险配方,又或者它仅仅是固执地认为迈克尔·乔丹是打棒球的 (虽然这在 90 年代确实有过一段短暂而令人困惑的经历,但并非事实的全貌) 。
你需要修复这个问题。你需要让模型“遗忘”敏感数据,或者“编辑”错误的知识,同时又不能破坏它说英语或回答其他问题的能力。
这就是 知识编辑与遗忘 (Knowledge Editing and Unlearning) 面临的挑战。目前的技术通常试图定位事实存储的位置并调整权重。然而,一篇题为 “Mechanistic Unlearning: Robust Knowledge Unlearning and Editing via Mechanistic Localization” 的新论文揭示了我们通常做法中的一个致命缺陷。大多数现有方法就像是用胶带封住模型的“嘴”——它们针对的是输出机制。如果你撕掉胶带 (或者换一种提示方式) ,秘密就会泄露出来。
在这篇文章中,我们将深入探讨这项研究。我们将探索作者如何利用 机械可解释性 (Mechanistic Interpretability) 来区分模型是在哪里 获取 事实,以及在哪里 说出 事实。通过针对源头——即“事实查找 (Fact Lookup) ”机制——他们实现了更稳健、更持久且更安全的遗忘效果。
背景: “输出追踪”的问题
要理解这篇论文的创新之处,我们需要先看看现状。当研究人员想要编辑模型时 (例如,将“埃菲尔铁塔在巴黎”改为“埃菲尔铁塔在罗马”) ,他们需要找到需要更改的参数。
标准方法是 输出追踪 (Output Tracing, OT) 。 诸如 *因果追踪 (Causal Tracing) * 之类的方法通过分析模型的哪些组件在被破坏或恢复时对输出 token (例如“巴黎”) 的最终概率影响最大来工作。
这听起来很合理: 如果某个层强烈影响输出词“巴黎”,那知识肯定就存储在那里,对吧?
未必。这篇论文的作者认为,OT 方法通常识别出的是 提取机制 (Extraction Mechanism) ——负责获取内部概念并将其格式化为正确的下一个单词的层。它们遗漏了 事实查找机制 (Fact Lookup Mechanism) ——即从模型记忆中实际检索概念的较早层级。
如果你只编辑提取机制,你并没有移除知识;你只是切断了与特定输出单词的联系。模型在潜在空间中仍然“知道”这个事实,并且可以通过不同的句子结构或多项选择题将这些知识诱导出来。
核心方法: 机械式遗忘
研究人员提出了一种新范式: 机械式遗忘 (Mechanistic Unlearning) 。 他们不再关注什么影响输出,而是关注模型处理信息的内部机制。
两种机制: 查找 vs. 提取
该论文建立在先前的可解释性工作之上,这些工作指出 Transformer 模型通常分两个不同阶段处理事实:
- 事实查找 (Fact Lookup, FLU) : 这通常发生在中间层 (特别是多层感知机,即 MLP) 。模型看到主语 (例如“迈克尔·乔丹”) ,并用属性 (例如“篮球”) 丰富内部数据流。
- 事实提取 (Fact Extraction) : 这发生在较后的层级。注意力头和 MLP 读取那些丰富后的数据流,并决定下一个预测什么词。
作者的假设简单而有力: 要稳健地编辑一个事实,你必须针对查找机制,而不是提取机制。
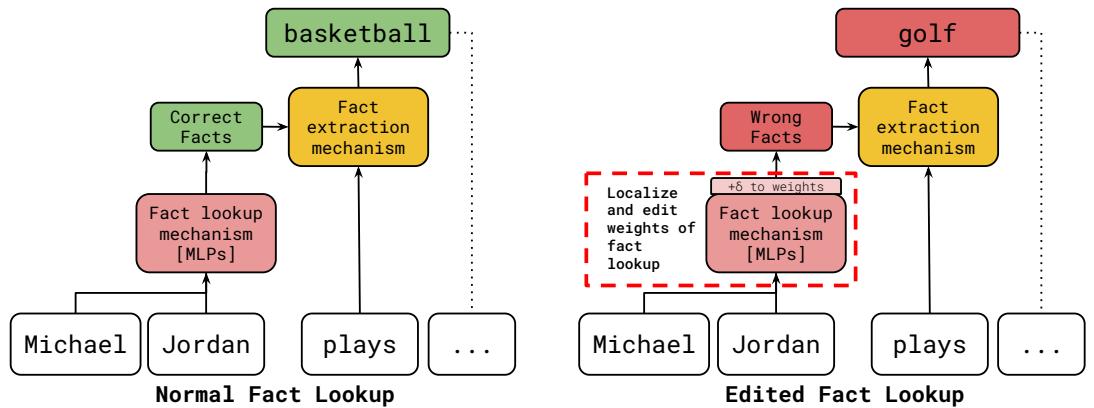
如上图 1 所示,机械式遗忘专注于定位和编辑“事实查找”框中的权重。通过在提取阶段 之前 更改关联,无论问题如何表述,这种编辑都会成为模型内部现实的基础。
他们如何找到“查找”层?
找到这些特定的组件需要针对不同类型的数据使用不同的技术。作者重点关注了两个数据集: Sports Facts (关系型数据) 和 CounterFact (通用知识) 。
1. 针对体育事实的探测
对于体育数据集,作者使用了 线性探针 (linear probes) 。 探针是在每一层的模型内部激活值上训练的小型分类器。他们训练这些探针来预测运动员的运动项目 (例如,已知输入是“泰格·伍兹”,探针能否从第 5 层的数据中预测出“高尔夫”?) 。
他们发现探针的准确率在特定的 MLP 层范围内飙升。这表明运动项目的“概念”正是在这些层被检索并添加到残差流中的。这就是 FLU 定位 。
2. 针对 CounterFact 的路径修补
对于通用事实,探针较难使用,因为答案不限于一小组类别 (如体育项目) 。相反,作者使用了 路径修补 (Path Patching) 。
他们反向追踪信息流。首先,他们找到了“提取”头——即直接影响输出 Logits 的最后一层的组件。然后,他们寻找对这些提取头有强烈 直接影响 的较早 MLP 层。这使他们能够识别出向输出机制提供信息的 MLP。
编辑过程
一旦确定了负责事实查找的特定 MLP (定位步骤) ,作者就应用了 局部微调 (Localized Fine-Tuning) 。
他们 仅 更新那些已识别组件的权重,使用的损失函数旨在:
- 注入 新的/遗忘的事实 (最小化目标上的损失) 。
- 保留 通用知识 (确保其他事实未受损) 。
- 维持 流畅性 (保持模型正确说英语) 。
实验与结果
研究人员在 Gemma-7B、Gemma-2-9B 和 Llama-3-8B 等模型上,将他们的机械式遗忘方法与标准基线 (如因果追踪和非局部微调) 进行了对比测试。
结果凸显了 鲁棒性 (Robustness) 方面的巨大差异。
1. 多项选择题 (MCQ) 测试
打破标准模型编辑最简单的方法之一是改变提示的格式。如果你用提示“埃菲尔铁塔位于…”将模型编辑为相信埃菲尔铁塔在罗马,模型可能会说“罗马”。但如果你问一个多项选择题: “埃菲尔铁塔在哪里?A) 巴黎 B) 罗马”,编辑不佳的模型通常会恢复原来的真相 (“巴黎”) 。
作者对此进行了广泛测试。他们观察了 MCQ 遗忘错误率 (MCQ Forget Error) (模型“意外”记住旧事实的频率) 和 MCQ 编辑准确率 (MCQ Edit Accuracy) (它持续选择新事实的频率) 。
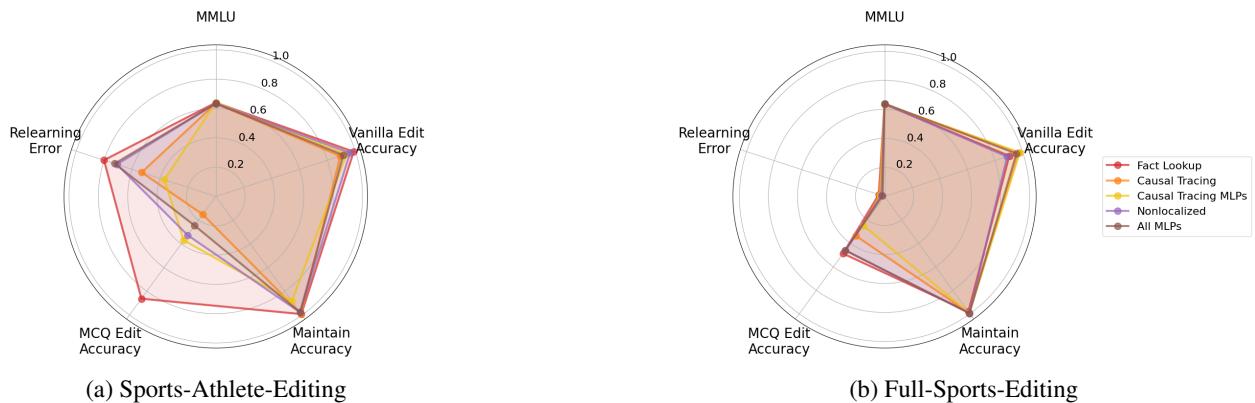
图 2 (上图) 中的雷达图讲述了一个令人信服的故事。注意“MCQ Edit Accuracy”轴。 事实查找 (FLU) 方法 (红色) 的得分明显高于 因果追踪 (橙色) 或 非局部 (Nonlocalized) 方法 (紫色) 。这表明 FLU 编辑真正改变了模型的知识,而 OT 方法仅仅是过拟合了特定的训练提示句式。
我们在下面的条形图中可以更清楚地看到这一点。
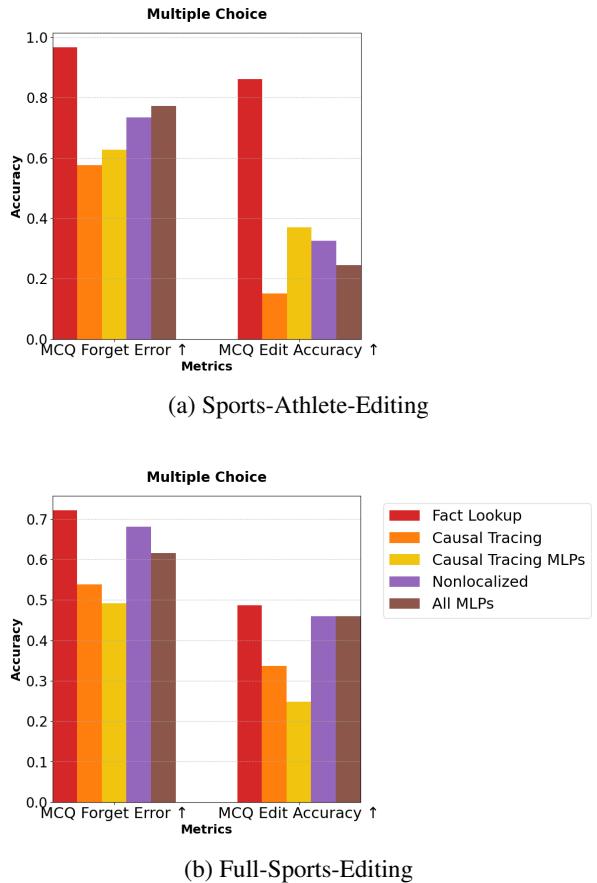
在图 3(a) 中,请看右侧的 MCQ Edit Accuracy 。 红色条 (FLU) 遥遥领先。标准的输出追踪 (橙色) 在这里表现糟糕,在某些情况下仅略好于随机猜测。这证实了输出追踪编辑是“脆弱的”——当提示格式改变时,它们就会崩溃。
2. 对抗性重学习
遗忘的另一个严格测试是 重学习 (Relearning) 。 如果你从电脑中删除了一个文件但没有清空回收站,它很容易恢复。同样,如果一种遗忘方法只是抑制了一个事实,那么仅用 少量 相关数据重新训练模型可能会让原始记忆涌现回来。
研究人员将他们的“遗忘集”分成两半。他们编辑模型以遗忘这些事实,然后仅用原始真实事实的前半部分对模型进行轻微的重新训练。接着,他们测试模型是否“记起”了后半部分。
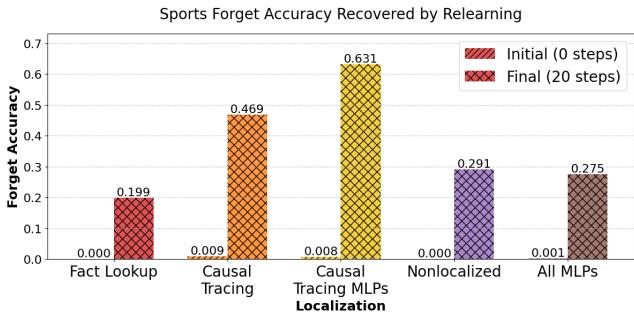
图 6 可能是针对当前方法最有力的证据。
- 初始状态 (红色斜纹条) : 大多数方法最初都成功抑制了事实。
- 重学习后 (橙色交叉纹) : 看看 因果追踪 (Causal Tracing) 。 准确率飙升回 60% 以上。模型并没有遗忘;它只是隐藏了信息,一点点训练就把它带回来了。
- 事实查找 (最左侧) : 准确率保持在接近零的水平。模型真的无法检索该信息,因为该事实的内部机制已被打乱。
3. 探究潜在空间
为了验证 为什么 会发生这种情况,作者再次使用线性探针窥视了模型的“大脑”内部。他们想知道: 即使输出不同,原始事实是否仍然漂浮在隐藏层中?
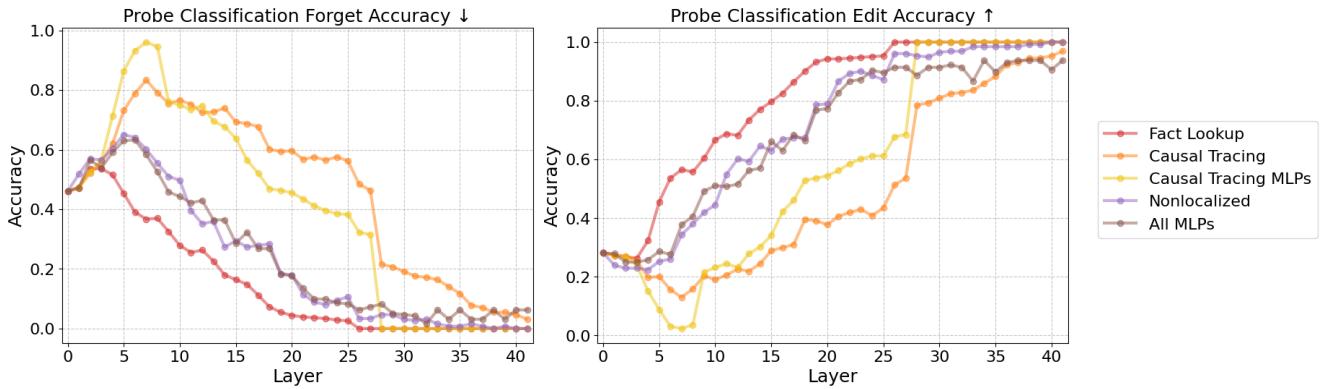
图 40 (左) 揭示了内部状态。Y 轴代表探针从模型的激活值中解码 原始 (被遗忘) 事实的准确程度。
- 橙线 (因果追踪) : 注意它在早期/中间层 (0 到 15) 保持得多高。模型在内部 仍然知道真相。编辑只是在最后阶段抑制了它。
- 红线 (事实查找) : 线条下降并保持在低位。旧事实的内部表征已被清除。
这证实了“贴胶带封嘴”的比喻。因果追踪保留了内部思维完整无缺;机械式遗忘则移除了思维本身。
讨论与启示
这篇论文对 AI 安全性和实用性做出了重要贡献。随着模型越来越融入社会,对它们进行选择性且稳健的编辑能力是不可或缺的。
为什么定位很重要
这里的关键结论是 并非所有参数都是生而平等的 。 你可以通过编辑模型的不同部分在特定提示上达到相同的“测试准确率”,但该编辑的 泛化能力 完全取决于你在 哪里 进行了更改。
- 提取编辑 (OT) : 改变思维到语言的翻译。适用于表面更改,不适用于深度知识移除。
- 查找编辑 (FLU) : 改变概念的检索。对于真正的遗忘是必要的。
参数效率
有趣的是,作者还发现机械式遗忘是高效的。与编辑整个模型或随机层相比,通过针对 FLU 机制,他们修改了更少的参数却取得了更好的结果。
潜在知识的威胁
关于潜在知识的发现 (图 40) 与安全性尤为相关。如果使用输出追踪让模型“遗忘”危险知识,危险仍然存在于权重中。拥有权重访问权限 (或使用微调 API 访问权限) 的恶意行为者可以轻松地浮现这些潜在知识。机械式遗忘为抵御此类攻击提供了更强大的防御。
结论
论文“Mechanistic Unlearning”教导我们,要修复语言模型,我们必须像神经外科医生那样思考,而不是像化妆师。我们不能简单地粉饰输出;我们必须定位检索记忆的特定神经回路并在那里进行操作。
通过区分 事实查找 和 事实提取 , 作者证明了我们可以执行稳健的编辑,这些编辑对改写具有鲁棒性,能抵抗重学习,并且能有效地清除模型的内部潜在状态。
随着我们继续扩展 LLM,像这样利用 机械可解释性 来指导模型工程的技术,对于创建不仅博学,而且可控且安全的 AI 将至关重要。
这篇博客文章解释了 Guo 等人发表的研究论文 “Mechanistic Unlearning: Robust Knowledge Unlearning and Editing via Mechanistic Localization” (2025)。