](https://deep-paper.org/en/paper/9548_self_supervised_masked_gr-1595/images/cover.png)
引言: 随机性的问题
试想一下学习一门新语言的过程。你不会一开始就尝试写一篇复杂的哲学论文。你会从字母表开始,然后是简单的单词、句子,最后才是复杂的段落。这种由易到难的循序渐进过程是人类学习的基础。它能建立信心,并确保在处理困难概念之前已经掌握了基础知识。
在机器学习领域,特别是图神经网络 (GNNs) 中,这个概念经常被忽视。
图结构数据无处不在——社交网络、化学分子和引文图谱。为了在没有昂贵人工标注的情况下分析这些数据,研究人员使用了自监督学习 (SSL) 。 SSL 中一种流行的方法是掩码图自编码器 (Masked Graph Autoencoder) 。 其思路很简单: 隐藏 (掩盖) 图的一部分,并让 AI 猜测缺失了什么。如果它能重建缺失的部分,就说明它“理解”了这张图。
然而,大多数现有的方法都是随机掩盖图的。它们将每条边和每个节点都视为具有相同的重建难度。这就像是一天把微积分试卷交给幼儿园学生,第二天又把字母表练习册交给大学生一样。
本篇博客将探讨一篇引人入胜的研究论文 “Self-supervised Masked Graph Autoencoder via Structure-aware Curriculum” , 该论文介绍了 Cur-MGAE 。 这个新框架使用课程 (curriculum) 来训练 GNN——从简单的模式开始,逐步引入复杂的结构依赖关系。
背景: 图、掩码与自监督
在深入了解新方法之前,让我们先建立一下背景知识。
标签的挑战
深度学习模型非常依赖大量数据。在监督学习中,每条数据都需要一个标签 (例如,“这个节点是机器人”或“这个节点是人类”) 。获取这些标签既昂贵又耗时。自监督学习 (SSL) 通过创建“前置任务 (pretext tasks)”解决了这个问题——即无需外部标签,直接在数据本身上训练模型。
生成式与对比式
图 SSL 主要有两种流派:
- 对比式 (Contrastive): 模型学习区分图与其自身的损坏版本。虽然功能强大,但它严重依赖于“数据增强 (augmentations)” (即调整图的方式) ,而这往往难以设计。
- 生成式 (Generative): 模型充当侦探的角色。我们要移除图的一部分 (边或节点特征) ,然后让模型尝试重新生成它们。这就是我们要关注的重点。
课程学习的缺失
现有的生成式模型 (如 GraphMAE) 已取得了巨大成功。然而,它们缺乏细微的差别。在一个真实的图中,有些边是显而易见的 (例如,两篇非常相似的论文之间的连接) ,而另一些则是令人惊讶或复杂的。通过将所有边一视同仁,标准模型往往只能获得次优的学习效果。它们可能在训练早期被困难样本压垮,或者在后期对简单样本感到厌倦。
核心方法: Cur-MGAE
研究人员提出了 Cur-MGAE (课程掩码图自编码器) 。其目标是捕捉边的潜在难度,并设计一个随模型能力提升而扩展的重建任务。
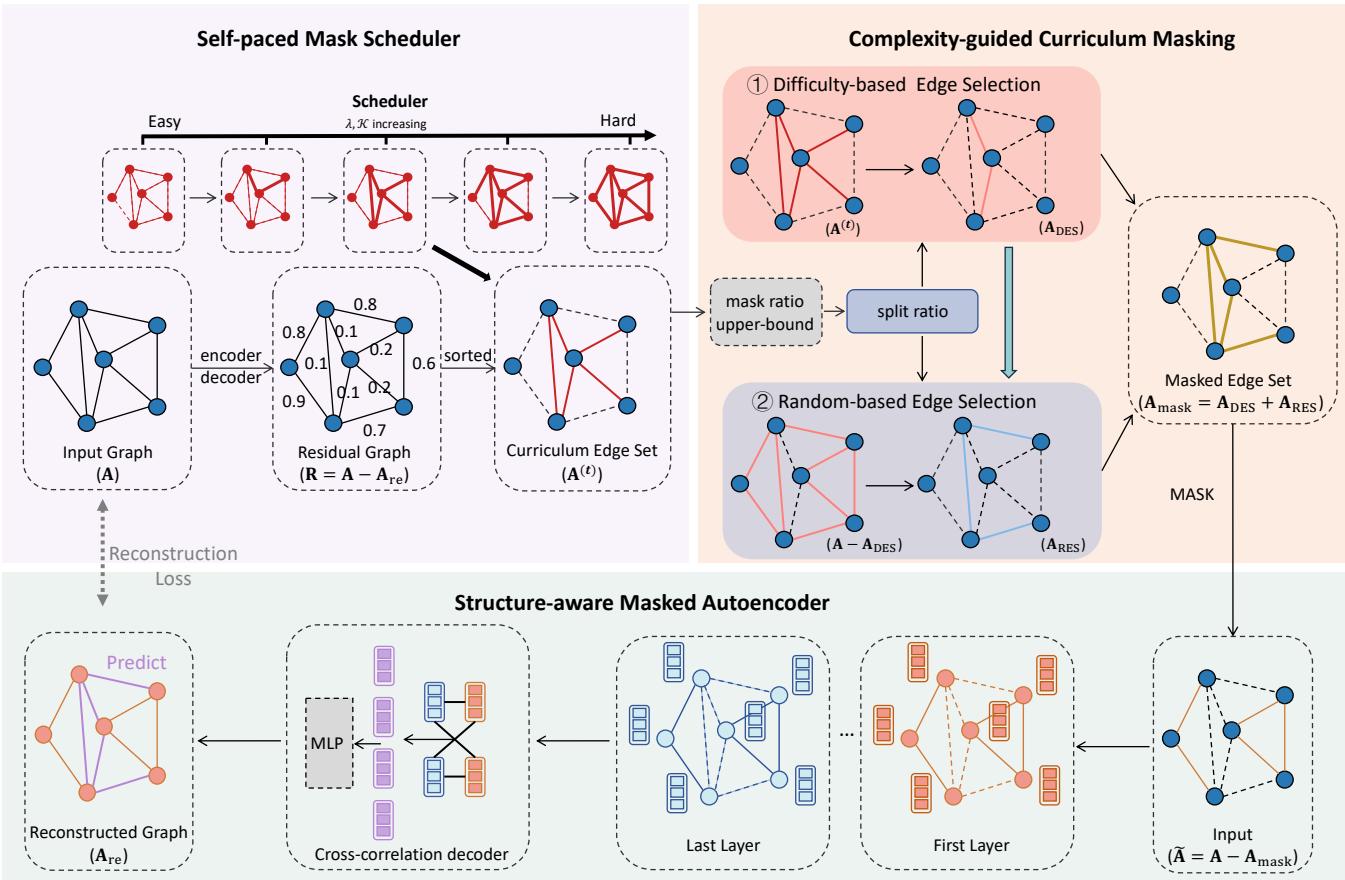
如上图 Figure 1 所示,该框架由三个集成的组件组成:
- 结构感知掩码自编码器 (Structure-aware Masked Autoencoder): 学习表示的引擎。
- 复杂度引导的课程掩码 (Complexity-guided Curriculum Masking): 决定哪些边是简单或困难的“老师”。
- 自步掩码调度器 (Self-paced Mask Scheduler): 决定何时引入更难任务的“调度员”。
让我们一步步拆解这些组件。
1. 结构感知掩码自编码器
系统的核心是自编码器。它接收一个移除了部分边 (被掩盖) 的图,并试图预测这些边应该在哪里。
编码器 (The Encoder) 编码器是一个标准的图神经网络 (如 GCN 或 GraphSAGE) 。它聚合节点邻居的信息以创建一个“节点嵌入 (node embedding)”——即代表该节点的数值向量。
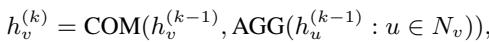
这里,\(h_v^{(k)}\) 是节点 \(v\) 在第 \(k\) 层的嵌入。该函数聚合来自邻居 (\(N_v\)) 的消息,并将其与节点之前的状态结合。
互相关解码器 (The Cross-Correlation Decoder) 以前的大多数模型只是简单地计算两个节点嵌入的点积,以此来判断它们是否应该连接。Cur-MGAE 的作者认为这太简单了。相反,他们提出了一个互相关解码器 。
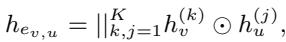
这个公式看起来很复杂,但直觉很简单: 解码器不仅仅检查两个节点是否相似,而是查看网络不同层之间节点的逐元素交互 (\(\odot\))。这能更有效地捕捉共享特征,过滤掉噪声,并专注于指示连接的强信号。
重建损失 (The Reconstruction Loss) 模型通过最小化其预测与实际图结构之间的差异来学习。
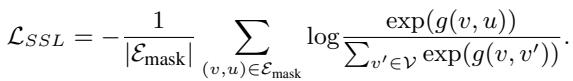
这个损失函数 (\(L_{SSL}\)) 强制模型对那些被掩盖的边 (\(E_{mask}\)) 分配高概率,确保学到的表示能够捕捉图的真实结构。
2. 复杂度引导的课程掩码
这就是“课程”开始的地方。我们如何确定一条边重建起来是“简单”还是“困难”?
作者使用了一个聪明且动态的指标: 重建残差 (Reconstruction Residual) 。
- 模型尝试利用其当前的知识重建整个图。
- 我们计算每条边的误差 (残差) 。
- 低残差: 模型很容易就预测出了这条边。这是一条“简单”的边。
- 高残差: 模型很难预测这条边。这是一条“困难”的边。
这个策略有些反直觉但非常精妙: 首先掩盖简单的边。
为什么?因为如果你掩盖了一条“困难”的边 (即使它存在,模型也会产生很高的误差) ,模型就没有上下文来猜测它。通过掩盖“简单”的边 (那些模型有信心的边) ,你可以让模型在它确实能解决的任务上进行练习,在继续前进之前巩固其基础理解。
3. 自步掩码调度器
我们不能永远停留在简单的边上。为了学习得更稳健,模型最终必须处理困难的边。 自步掩码调度器负责管理这种过渡。
研究人员将边的选择视为一个优化问题。他们希望选择一组要掩盖的边 (由矩阵 \(\mathbf{S}\) 表示) ,以平衡当前的难度和正则化项。
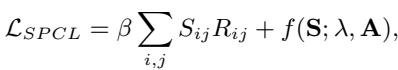
- \(R_{ij}\) 是残差 (难度) 。
- \(S_{ij}\) 是选择 (如果掩盖则为 1,否则为 0) 。
- \(f(\mathbf{S}; \lambda, \mathbf{A})\) 是由 \(\lambda\) 控制的正则化项。
Lambda (\(\lambda\)) 的作用 参数 \(\lambda\) 就像是一个调节阀。随着训练的进行,\(\lambda\) 会增加。较高的 \(\lambda\) 会鼓励模型选择更多的边,而且重要的是,选择难度分数更高的边。
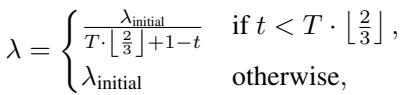
这个公式确保了一个平滑的逐步上升过程。在训练早期 (\(t\) 很小) ,\(\lambda\) 很小,所以我们只选择最简单的边。随着 \(t\) 接近总 epoch 数 \(T\),\(\lambda\) 增长,迫使模型掩盖并重建图中越来越复杂的部分。
平衡探索与利用
如果我们仅仅根据难度来选择边,模型可能会过度拟合特定的模式。为了防止这种情况,作者引入了分割比例 (Split Ratio) 。
- 基于难度的选择 (\(A_{DES}\)): 一部分边被选中是因为它们符合当前的课程难度。
- 随机选择 (\(A_{RES}\)): 剩余的边是随机选择的。
这种混合确保了模型在遵循课程的同时,保持足够的随机性以有效地探索整个图结构。
统一的目标
最后,模型同时优化自监督重建和课程调度。
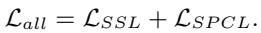
这导致了一个双层优化问题,其中模型参数和掩码策略和谐地共同进化。
实验与结果
教 AI “由易到难”地学习真的有效吗?作者在几个基准数据集 (Cora, Citeseer, PubMed, OGB) 上测试了 Cur-MGAE,并与 GraphMAE, MaskGAE 等强基线模型以及 DGI 等对比式方法进行了比较。
1. 节点分类
在这个任务中,模型在没有标签的情况下学习表示,然后在其上训练一个简单的分类器来预测节点类别。
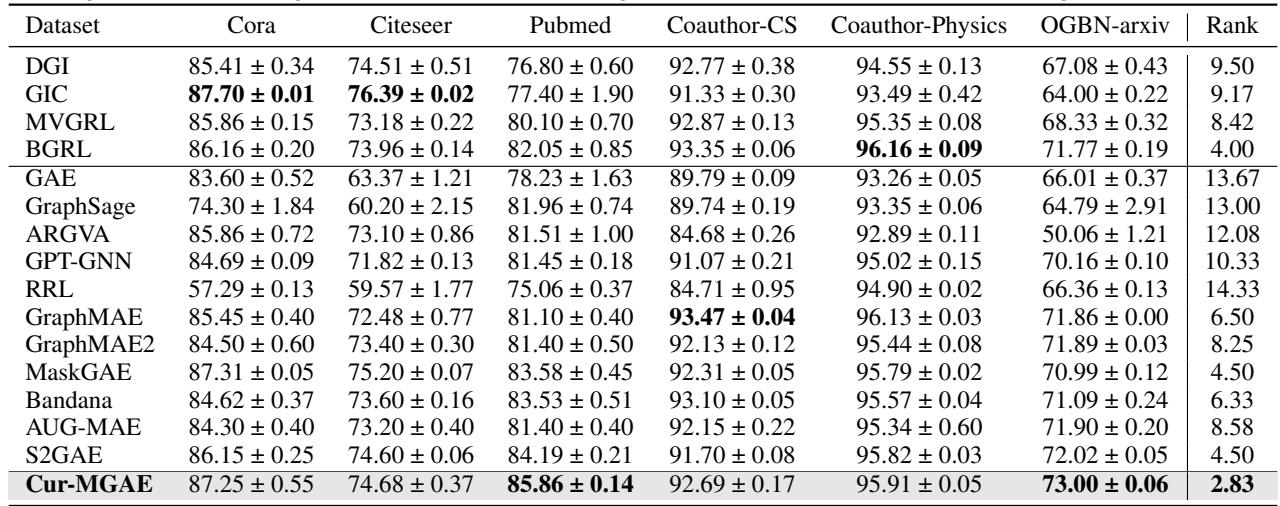
结论: Cur-MGAE 在所有数据集上都取得了最佳平均排名 。 在 PubMed 数据集上,它的准确率比最强的基线模型提高了 1.67%。这证实了课程学习有助于编码器学习对分类更有用的区分性特征。
2. 链路预测
在这里,模型必须预测图中缺失的连接——这项任务与预训练目标直接一致。
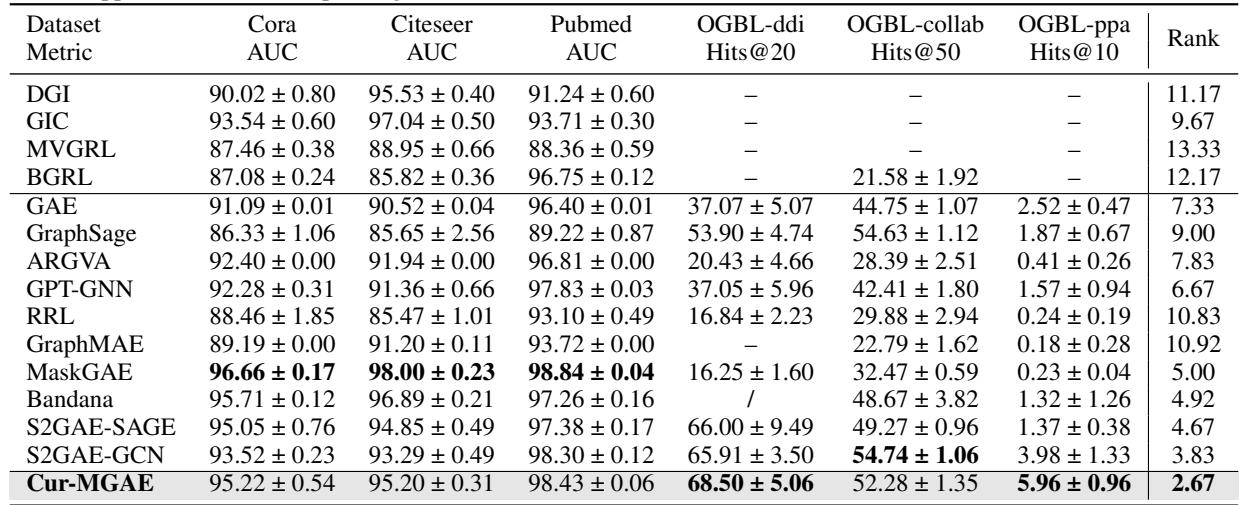
结论: Cur-MGAE 再次显示出一致的优势,特别是在像 OGBL-ppa 这样的大规模数据集上。在这里,生成式模型通常优于对比式模型,但 Cur-MGAE 自适应选择训练样本的能力使其优于 MaskGAE 等其他生成式模型。
3. 课程可视化
为了证明模型实际上是在进行“由易到难”的学习,研究人员创建了一个合成数据集,在这个数据集中他们知道每条边的真实难度。
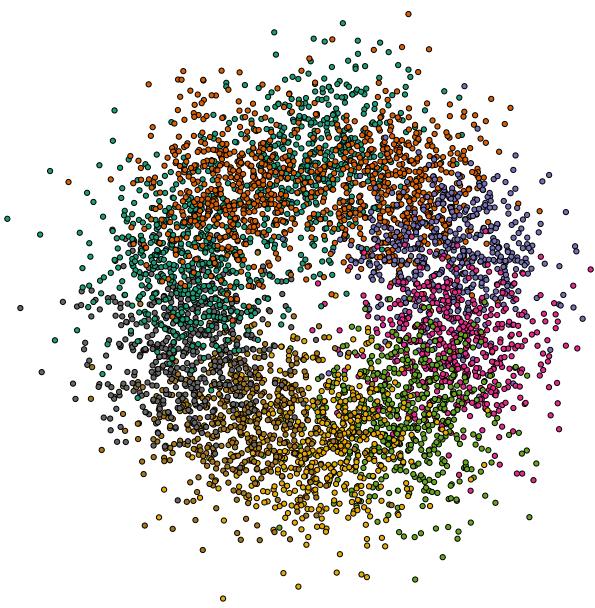
在这个可视化中,边根据颜色相似性连接节点。相同颜色的连接是“简单”的,而远距离颜色之间的连接是“困难”的。
研究人员随后追踪了模型随着时间的推移选择掩盖哪些边。
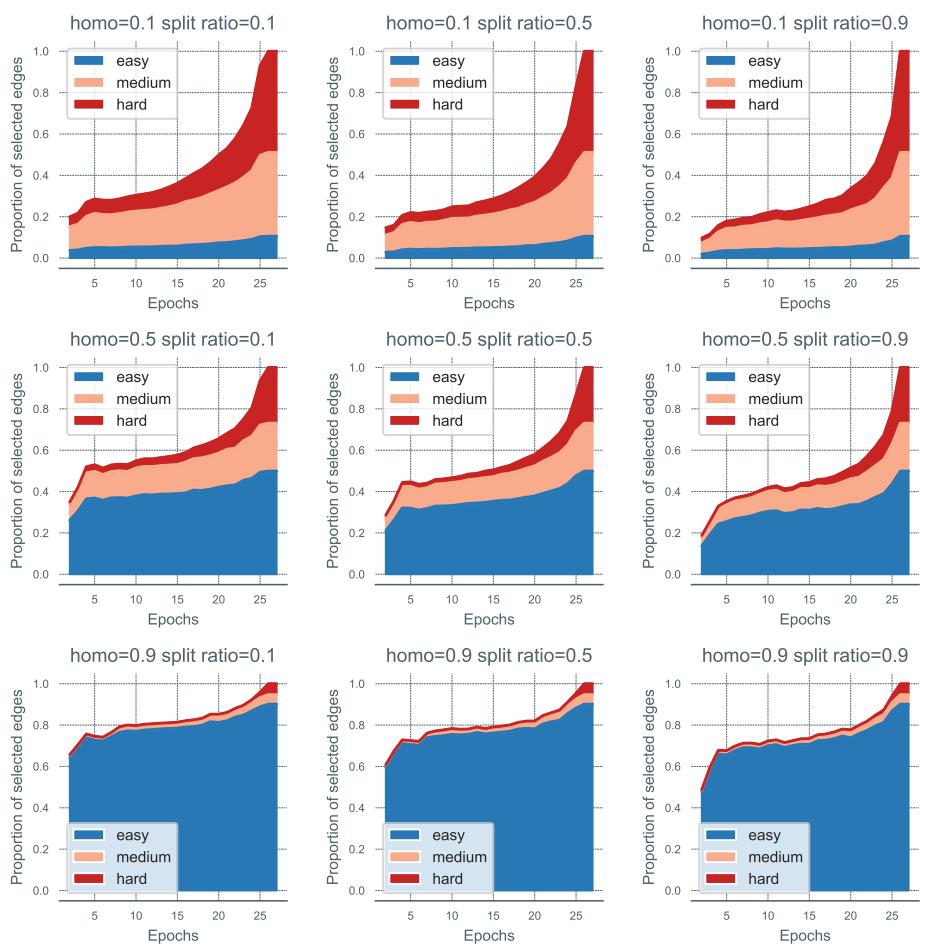
看看上面的图表。 蓝色区域代表“简单”边, 橙色代表“中等”, 红色代表“困难”。
- 早期 Epoch (X 轴左侧) : 选择由蓝色 (简单) 主导。
- 后期 Epoch (X 轴右侧) : 红色 (困难) 区域显著扩大。
这在经验上证明了自步调度器正如预期的那样工作,能够自主发现并提升难度。
4. 消融实验: 我们需要所有组件吗?
科学需要验证。作者移除了模型的部分组件以观察结果。
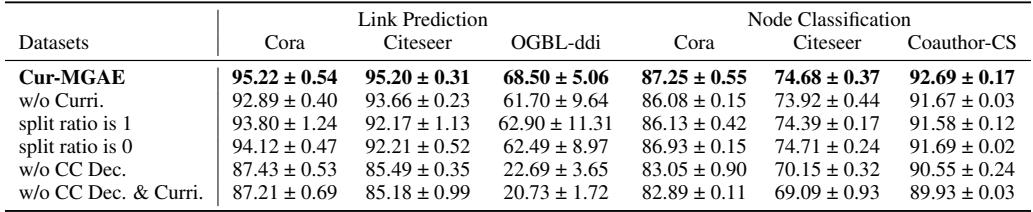
- w/o Curri: 移除课程并使用随机掩码,性能显著下降。
- Split ratio is 1: 仅使用基于难度的选择 (无随机性) 导致过拟合和结果降低。
- w/o CC Dec: 将互相关解码器替换为简单的点积,性能大幅受损,表明了高级解码器的重要性。
5. 参数敏感性
模型对超参数的变化有多稳健?
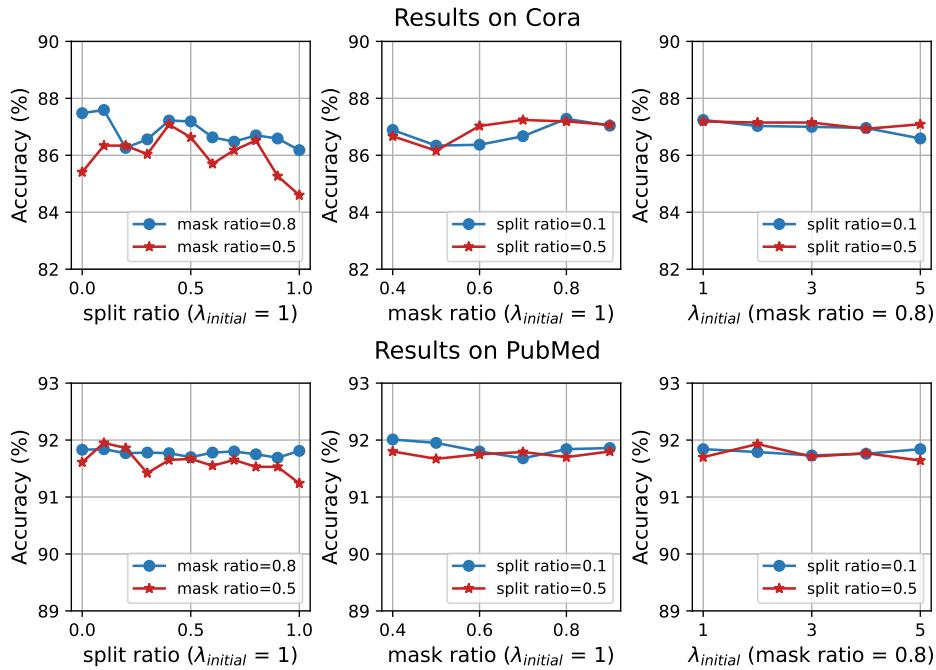
图表显示在合理的范围内性能是稳定的。 分割比例 (Split Ratio) (左列) 表明,平衡 (大约 0.5 到 0.8) 比极端值 (0 或 1) 更好,证实了混合课程和随机性的必要性。
理论分析: 为何收敛
人们可能会担心动态改变训练数据 (掩码) 会使训练变得不稳定。作者提供了严格的理论证明。
他们使用海森矩阵 (二阶导数) 分析了收敛性。
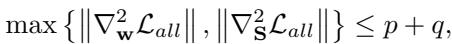
通过证明目标函数是平滑且有界的 (利普希茨连续梯度) ,他们论证了算法 1 保证收敛到一个驻点。简单来说: 尽管课程是一个移动的目标,数学证明了模型最终会稳定在一个解上。
结论
Cur-MGAE 这篇论文强调了学习中的一个基本真理: 信息的顺序很重要。通过摒弃随机掩码并采用结构感知的课程,作者创造了一种能更高效、更有效学习的图自编码器。
关键要点:
- 上下文很重要: 重建边不仅仅关于存在/不存在;它关乎相对于剩余结构的难度。
- 从简单开始: 首先掩盖简单的边可以打下基础。
- 混合策略: 僵化的课程会导致过拟合;混合随机探索能保持模型的鲁棒性。
这项工作为更智能的自监督学习铺平了道路,有可能使 GNN 在无需数百万人工标签的情况下,处理生物学、社交媒体和物理学中更大、更复杂的网络。就像学生一样,当教学大纲规划得当时,AI 的学习效果最好。