](https://deep-paper.org/en/paper/file-2714/images/cover.png)
引言
想象一下,你训练了一个最先进的 AI 模型来对文本进行分类。它在你的测试数据上运行完美。然而,一个恶意攻击者仅仅改变了输入句子中的一个词——把“bad”换成了“not good”——你的模型预测结果就突然完全反转了。这就是对抗性攻击 (Adversarial Attack) , 它是现代自然语言处理 (NLP) 中最大的漏洞之一。
为了解决这个问题,研究人员通常使用对抗训练 (Adversarial Training, AT) , 即在训练过程中强迫模型从这些棘手的例子中学习。然而,这种做法代价高昂:
- 计算成本: 你通常必须从头开始重新训练整个庞大的模型 (如 BERT 或 RoBERTa) 。
- 性能下降: 模型变得过于专注于识别欺骗手段,以至于在理解正常、干净的文本时表现变差 (这种现象通常被称为“灾难性遗忘”) 。
- 僵化: 如果明天发现了一种新型攻击,你必须重新开始整个训练过程。
如果有一种方法可以在不重新训练整个网络且不牺牲干净数据性能的情况下,使模型能够抵御攻击,那会怎样?
ADPMIXUP 登场了,这是由印第安纳大学伯明顿分校的研究人员提出的一种新颖框架。这种方法结合了 适配器 (Adapters) (AI 的微型插件模块) 的高效性与 Mixup (一种数据增强技术) 的数学威力。其结果是一个能够针对其接收到的每一个输入实时动态调整防御机制的系统。
在这篇文章中,我们将解构 ADPMIXUP 的工作原理,通过分析它为何是高效 AI 防御的游戏规则改变者,以及它如何设法处理从未见过的攻击。
背景: 构建模块
要理解 ADPMIXUP,我们需要简要回顾三个基本概念: 适配器、对抗训练和 Mixup。
1. 通过适配器进行参数高效微调 (PEFT)
预训练语言模型 (PLMs) 非常庞大。针对特定任务对其进行微调通常涉及更新其数十亿个参数。 适配器 (Adapters) 提供了一种更聪明的替代方案。我们不更新整个模型,而是冻结预训练模型,并在现有层之间插入小型的、可训练的层 (适配器) 。
这可以将你需要训练的参数数量减少到原始数量的 0.1% 甚至更少。你可以将适配器视为插入冻结大脑中的“技能”。你可以拥有一个用于正常阅读的“干净适配器 (clean adapter) ”和一个专门用于识别欺骗手段的“对抗适配器 (adversarial adapter) ”。
2. 对抗训练
对抗训练的标准公式如下所示:
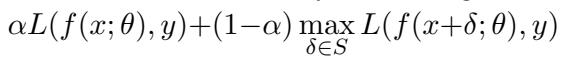
在这里,模型试图最小化干净样本 (\(x\)) 和对抗样本 (\(x + \delta\)) 上的误差。虽然有效,但这这就制造了一场拉锯战。使模型擅长处理干净数据的参数可能会与进行稳健防御所需的参数发生冲突。
3. Mixup 数据增强
Mixup 是一种最初为图像设计的技术。它通过将两张图像及其标签混合在一起来训练模型学习“虚拟”样本。
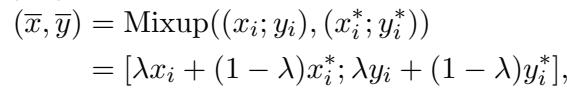
如果 \(\lambda\) 为 1,你得到的是一张干净图像。如果 \(\lambda\) 为 0,你可能得到的是一张对抗图像。Mixup 平滑了模型的决策边界,使其不那么脆弱。然而,将 Mixup 应用于文本是很困难的。你可以混合像素,但混合单词“cat”和“dog”会产生无意义的内容,这对模型学习语法或句法没有帮助。
动机: 从数据 Mixup 到模型 Mixup
研究人员意识到,虽然混合文本数据很混乱,但混合模型权重在数学上是优雅的——前提是模型足够相似。
这个概念与 Model Soup (模型汤) 有关,即对多个微调模型的权重进行平均以提高性能。
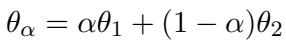
然而,如果你试图平均两个完全不同的大型语言模型,它会失败,因为它们的优化路径差异太大。这正是 适配器 拯救局面的地方。因为适配器很小,且是在同一个冻结的预训练模型之上训练的,它们在参数空间中保持着彼此接近的状态。
这引出了论文的核心洞察: 我们不必混合训练数据,而是可以训练独立的适配器 (一个干净的,一个对抗的) ,并在推理过程中动态混合它们的权重。
核心方法: ADPMIXUP
ADPMIXUP 的工作原理是用多个适配器微调 PLM: 一个在干净数据上训练,一个 (或多个) 在已知的对抗攻击上训练。在测试 (推理) 期间,系统智能地混合这些适配器以产生最终预测。
架构
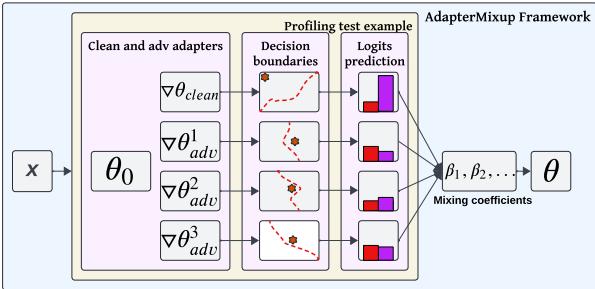
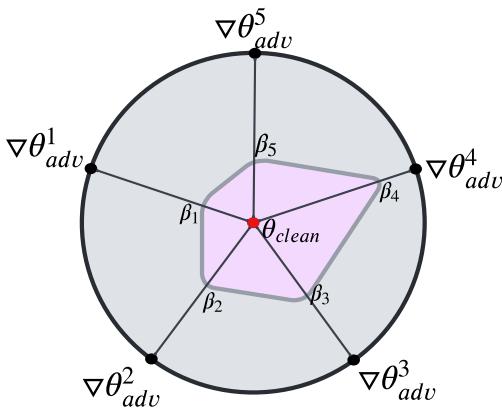
如 图 1 所示,该过程是动态的:
- 输入 \(x\) 被处理。
- 它同时通过 干净适配器 和 对抗适配器 。
- 框架计算混合系数 (\(\beta_1, \beta_2, \dots\)) 。
- 这些系数决定了每个适配器对最终决策边界 (由红色虚线表示) 的影响程度。
数学公式
混合发生在权重层面。如果我们有一个干净适配器 (\(\nabla \theta_{clean}\)) 和一个对抗适配器 (\(\nabla \theta_{adv}\)) ,特定输入的最终模型参数为:
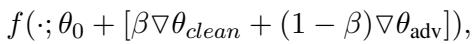
这里,\(\beta\) 是“混合系数”。
- 如果 \(\beta = 1\),模型仅使用干净适配器。
- 如果 \(\beta = 0\),模型仅使用对抗适配器。
- 理想情况下,我们需要介于两者之间的某种状态,以捕捉两全其美的效果。
“智能”开关: 通过熵实现的动态 \(\beta\)
ADPMIXUP 的精妙之处在于 \(\beta\) 不是一个固定的数字。它随模型读取的每一句话而变化。但是模型如何知道输入的句子是干净的还是攻击呢?
作者使用 熵 (Entropy) 作为不确定性的度量。
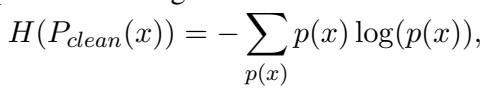
当一个仅在干净数据上训练的模型看到对抗性攻击时,它会感到困惑。它的预测概率分布会变平 (它不确定哪个类别是正确的) ,导致熵激增 。
- 低熵: 模型很自信。输入可能是干净的。\(\beta\) 应该很高 (接近 1) 。
- 高熵: 模型很困惑。输入可能是攻击。\(\beta\) 应该很低 (接近 0) ,从而激活对抗适配器。
系统根据当前熵与训练期间观察到的最大和最小熵的比较,计算干净适配器的特定权重 (\(\alpha^{clean}\)) :
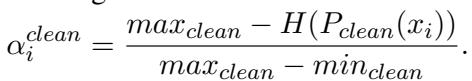
它对对抗适配器执行类似的计算,并将它们平均以找到最终的 \(\beta\)。这使得 ADPMIXUP 能够对输入进行画像,并落在权重的“鲁棒区域”,如下图粉红色区域所示:
处理多种攻击 (\(m > 1\))
在现实世界中,攻击者使用许多不同的策略 (例如,拼写错误、同义词替换) 。ADPMIXUP 可以同时结合一个干净适配器和多个对抗适配器。
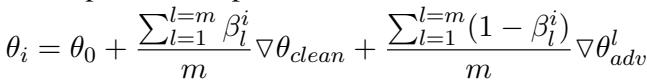
该公式表明,最终模型是干净适配器和所有可用对抗适配器的平均值,并由它们各自的动态 \(\beta\) 系数加权。这使得系统具有模块化特性——你可以简单地为新型攻击“插入”一个新的适配器,而无需重新训练其他适配器。
实验与结果
研究人员在 GLUE 基准上使用 BERT 和 RoBERTa 模型评估了 ADPMIXUP,并针对 TextFooler (词级) 和 DeepWordBug (字符级) 等各种攻击方法进行了测试。
1. 卓越的权衡
主要目标是在干净数据的准确性和对抗鲁棒性之间找到平衡。
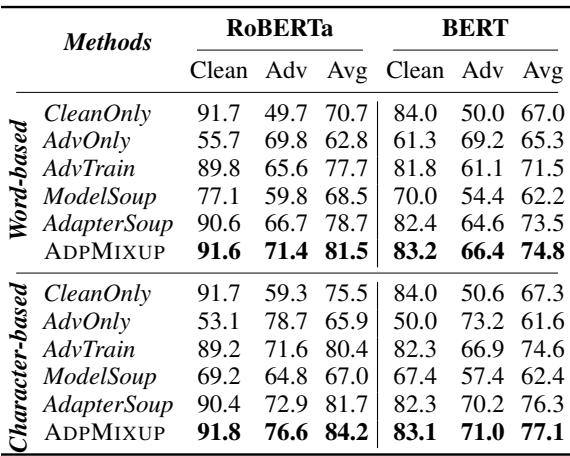
表 2 强调了结果。
- CleanOnly (仅干净数据) : 在干净数据上表现极佳 (91.7%) ,但在攻击下表现糟糕 (49.7%) 。
- AdvTrain (标准对抗训练) : 在攻击下表现良好,但降低了干净数据的准确性 (89.8%) 。
- ADPMIXUP: 保持了近乎完美的干净数据准确性 (91.6%) ,同时实现了卓越的对抗鲁棒性 (71.4%) 。它取得了最高的 平均 分数 (81.5%) ,击败了 Model Soup 和 Adapter Soup 等基准。
2. 对未知攻击的泛化能力
最艰巨的挑战之一是防御模型从未见过的攻击。研究人员在一种类型的攻击上训练模型,并在其他类型的攻击上进行测试。
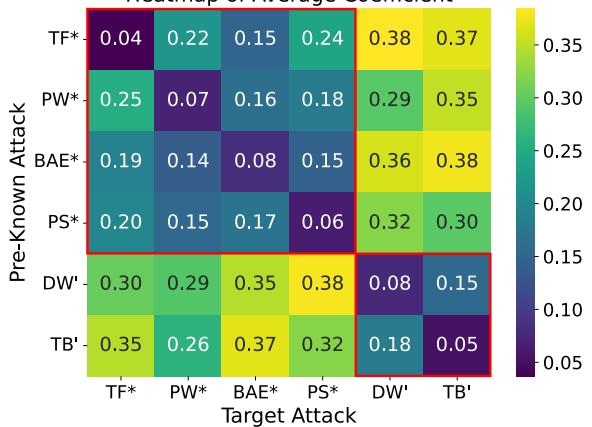
图 3 是混合系数 \(\beta\) 的热图。
- x 轴代表目标 (未知) 攻击。
- y 轴代表预先已知的攻击适配器。
- 颜色表明模型成功地对攻击进行了“画像”。当遭遇基于词的攻击 (如 TextFooler) 时,模型会自动为基于词的对抗适配器分配更高的权重 (颜色更深/\(\beta\) 更低) ,即使它是具体的算法不同。这证明 ADPMIXUP 可以迁移知识来防御未知威胁。
3. 经验最优性
动态 \(\beta\) 与理论上完美的混合有多接近?
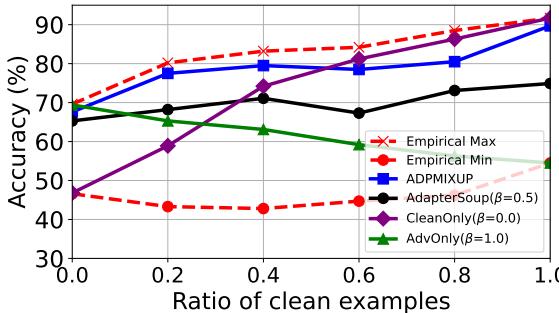
图 4 将 ADPMIXUP (蓝线) 与“经验最大值 (Empirical Max) ” (红星) 进行了比较——后者是如果你手动为每一批次选择完美 \(\beta\) 时可能得到的最佳结果。ADPMIXUP 非常紧密地追踪了最佳性能,远超静态混合策略 (如固定权重的 AdapterSoup) 。
4. 效率与复杂度
最后,它快吗?
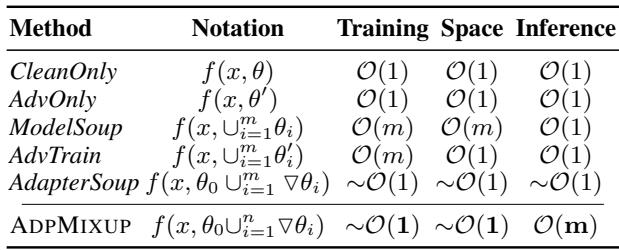
表 7 显示,相对于完整模型的大小,训练复杂度本质上是 \(O(1)\),因为我们只训练微小的适配器。
在推理过程中,计算 \(\beta\) 确实需要运行适配器,对于 \(m\) 种攻击,名义上是 \(O(m)\)。然而,因为我们可以使用熵阈值快速检测干净输入,所以我们并不总是需要激活对抗适配器。
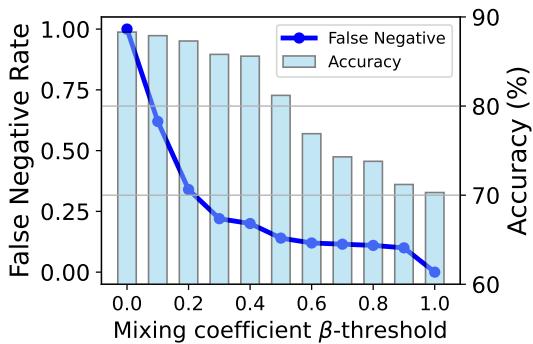
图 5 演示了通过设置 \(\beta\) 的阈值 (例如 0.4) ,系统创建了一个“短路”。如果输入看起来很干净 (高 \(\beta\)) ,系统就会跳过繁重的对抗计算。这显着降低了运行时复杂度,使其在现实世界的部署中切实可行。
结论与启示
ADPMIXUP 为 AI 中的“鲁棒性与效率”困境提供了一个令人信服的解决方案。通过将“Mixup”的概念从数据增强转变为 模型权重增强 , 并利用 适配器 的模块化特性,作者创建了一个具备以下特点的框架:
- 模块化: 新的防御措施可以作为新适配器添加,而无需重新训练基础模型。
- 高效: 它只需要完全对抗训练参数的一小部分。
- 智能: 它使用熵来动态剖析输入,确保干净数据得到正常处理,而攻击则遭到强有力的防御。
- 可解释: 混合系数提供了模型认为它正面临何种攻击的洞察。
随着大型语言模型 (LLMs) 继续融入关键系统 (金融、医疗、安全) ,在不降低通用性能的情况下快速有效地修补漏洞的能力至关重要。ADPMIXUP 为未来铺平了道路,在这个未来中,AI 模型不仅知识渊博,而且适应性强且安全。