](https://deep-paper.org/en/paper/file-2726/images/cover.png)
像 GPT-4 和 Llama 3 这样的大型语言模型 (LLM) 已经彻底改变了我们要与文本交互的方式。它们可以总结小说、编写代码,甚至通过律师资格考试。然而,当涉及到特定的医疗诊断时——例如通过语音模式检测痴呆症——这些强大的模型往往会碰壁。
尽管它们拥有海量的训练数据,但标准的提示策略 (比如直接问模型“这个人有痴呆症吗?”) 产生的结果通常仅比抛硬币略好一点。原因何在?痴呆症的语言标记往往微妙、不一致且定义模糊,这使得 LLM 难以有效地利用其内部知识。
在这篇文章中,我们将深入探讨一篇题为 “Adversarial Text Generation using Large Language Models for Dementia Detection” (利用大型语言模型进行对抗性文本生成以检测痴呆症) 的引人入胜的论文。研究人员提出了一种名为对抗性文本生成 (Adversarial Text Generation, ATG) 的新方法。这种方法不再简单地要求 LLM 给出诊断,而是利用模型生成一个专门的“特征上下文 (Feature Context) ”——某种意义上的作弊条——以此最大化健康语音与痴呆症语音之间的差异。这种方法不仅将准确率从约 65% 提升到了 85% , 还为分类结果背后的原因提供了人类可读的解释。
问题所在: 为什么标准提示会失败
要理解解决方案,我们首先需要理解任务本身。痴呆症筛查的黄金标准之一是曲奇窃取图片描述任务 (Cookie Theft Picture Description Task) 。 患者会看到一幅混乱的厨房场景线条画——一个男孩从凳子上摔下来偷曲奇,一位母亲心不在焉地洗碗,而水槽里的水正在溢出——并被要求描述正在发生的事情。
对于健康人来说,这很简单。对于痴呆症患者来说,描述可能缺乏连贯性,遗漏关键细节 (如溢出的水) ,或者跑题。
问题在于这些“症状”很难编纂成规则。如果你将这种描述的转录文本输入 Llama 3,并使用少样本提示 (few-shot prompting) (给模型几个例子) 或思维链 (Chain-of-Thought) (要求它逐步思考) ,模型会表现得很挣扎。
正如研究人员指出的:
“挑战在于痴呆症检测的中间步骤没有很好的定义……甚至人类专家也无法清楚地理解什么样的语言标记可以用来准确地检测痴呆症。如果没有清晰的理解,人类就无法编写有效的中间步骤演示……因此,LLM 可能难以将其内部知识与痴呆症检测联系起来。”
在他们的实验中,标准的提示策略准确率仅在 55-75% 之间。这对于医疗筛查来说显然是不够的。
背景知识: 困惑度的力量
在剖析新方法之前,我们需要理解 NLP 中的一个基本概念: 困惑度 (Perplexity, PPL) 。
困惑度衡量的是语言模型对一段文本序列感到多么“惊讶”。
- 低困惑度: 文本符合模型预期的模式 (它符合模型的知识) 。
- 高困惑度: 文本是出乎意料的、混乱的或让模型困惑的。
在数学上,它的形式如下:
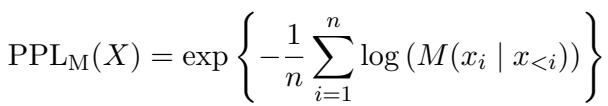
在这个背景下,\(M(x_i | x_{ 假设很简单: 一个在标准、健康人类语言上训练的模型,应该会发现健康对照组的转录文本具有较低的困惑度 (较少惊讶) ,而痴呆症患者的转录文本则具有较高的困惑度 (更多惊讶/不规则) 。然而,仅使用原始困惑度分数并不够精确。我们需要增强信号。 研究人员提出的解决方案, 对抗性文本生成 (ATG) , 彻底颠覆了标准的分类流程。他们不要求模型给出标签,而是利用模型生成一段特定的文本描述 (即特征上下文 ),迫使健康组和痴呆组的困惑度分数拉开差距。 该过程分为两个明显的阶段,如下图所示: 看图 1 的左侧。系统接收一个训练集 (标记为健康和痴呆的转录文本) 和一个指令 (Instruction) 。 然后,它使用 LLM 生成一段称为特征上下文 (Feature Context) 的文本。 这种生成之所以是“对抗性”的,是因为模型不仅仅是随意写作。它选择的词语旨在优化一个特定目标: 困惑度极化 (Perplexity Polarization) 。 如果生成的上下文描述了“一个关于母亲和两个孩子的连贯故事”,那么健康的转录文本将与该上下文一致。而支离破碎的痴呆症转录文本则无法与之对齐,从而导致其困惑度分数飙升。 一旦生成了这个特征上下文,它就充当了诊断的“透镜”。 模型如何知道在特征上下文中写什么?研究人员探索了三种策略来指导 ATG 过程,如图 2 所示。 这是最简单的方法。人类写一个提示,如“总结图片描述”或“列出语言特征”。ATG 尝试根据此命令生成上下文。 这里我们变得稍微抽象一点。我们要 LLM 先生成一个指令,然后使用那个指令来生成特征上下文。这允许模型构建人类可能忽略的复杂步骤。 这种策略产生了最好的结果。它利用了 LLM 比较文本的能力。 通过首先找到实际差异,模型能够针对性地捕捉痴呆症言语模式中的具体弱点。 用于这种基于差异生成的提示模板在表 1 中列出: 研究人员在 ADReSS-2020 数据集上测试了他们的方法,这是痴呆症检测的标准基准。他们将 ATG 与标准提示基线 (零样本、少样本和思维链) 进行了比较。 结果非常明显。 表 2 的关键要点: 有趣的是,当研究人员明确要求模型寻找语言学特征 (如“类符-形符比”或“动词百分比”——见下方的表 7 )时,模型表现不佳 (准确率约为 54%) 。 这表明痴呆症检测不仅仅是数动词或名词 (简单的统计模型就能做到) 。它关乎语义内容——即所讲述故事的意义和连贯性。LLM 擅长理解场景,而不仅仅是语法。 文本生成的一个担忧是稳定性。如果生成的特征上下文变成了乱语,那就没用了。研究人员使用 Top-p (核) 采样来确保生成的文本保持连贯和人类可读。 如图 3 所示,将 Top-p 设置为大约 0.9 (绿线) 能获得最佳的 AUC 分数。如果采样太严格或太随机,性能都会下降。 ATG 最大优势之一是可解释性 。 在标准的神经网络分类器中,决策逻辑是权重的“黑盒”。在 ATG 中,“分类器”实际上就是一段文本 (特征上下文) 。我们可以阅读它来看看模型认为什么是重要的。 例如,当指令是 “讨论任何值得注意的事情” 时,模型生成的上下文讨论了“厨房混乱”、“水槽溢出”和“母亲的忽视”。 当指令是 “清晰度” 时,模型生成了一个详细的分类,说明清晰的描述应该如何区分动作、事件和设置。 这证实了模型正在使用视觉语义——图片本身的逻辑——来区分患者。健康的参与者清楚地描述了溢出的水槽和倒下的凳子。痴呆症患者往往会遗漏这些因果联系。 论文《Adversarial Text Generation using Large Language Models for Dementia Detection》代表了医疗 NLP 领域向前迈出的重要一步。 虽然目前的工作集中在文本转录上,但作者指出,未来的工作可以结合多模态 LLM 来直接分析音频 (捕捉停顿、语调和口吃) 以及图片信息。 通过将分类任务转化为文本生成任务,ATG 使我们能够利用 LLM 强大的推理能力进行精确、可解释的医疗诊断。核心方法: 对抗性文本生成 (ATG)
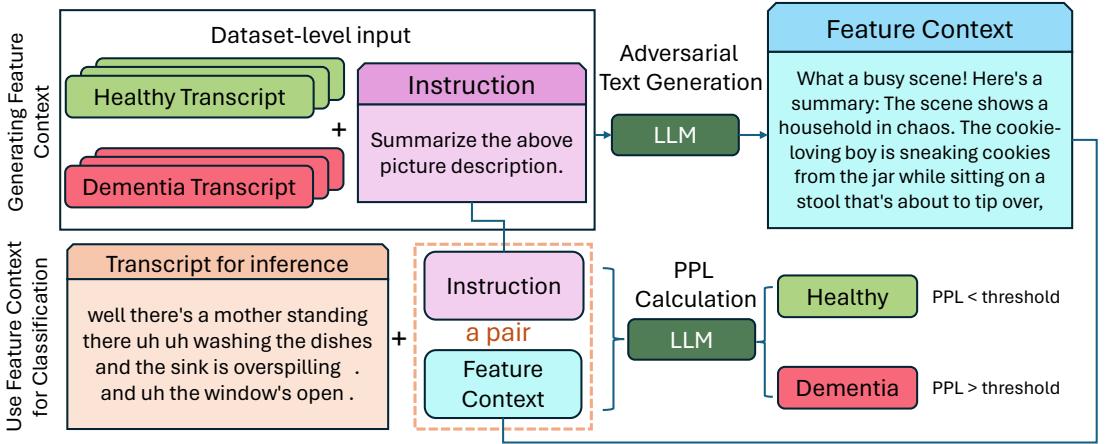
第一阶段: 生成特征上下文
第二阶段: 基于困惑度的分类
优化生成过程

1. 直接指令 (Direct Instructions)
2. 元指令 (Meta-Instructions)
3. 基于差异的指令 (Difference-Based Instructions) —— 突破点

实验与结果
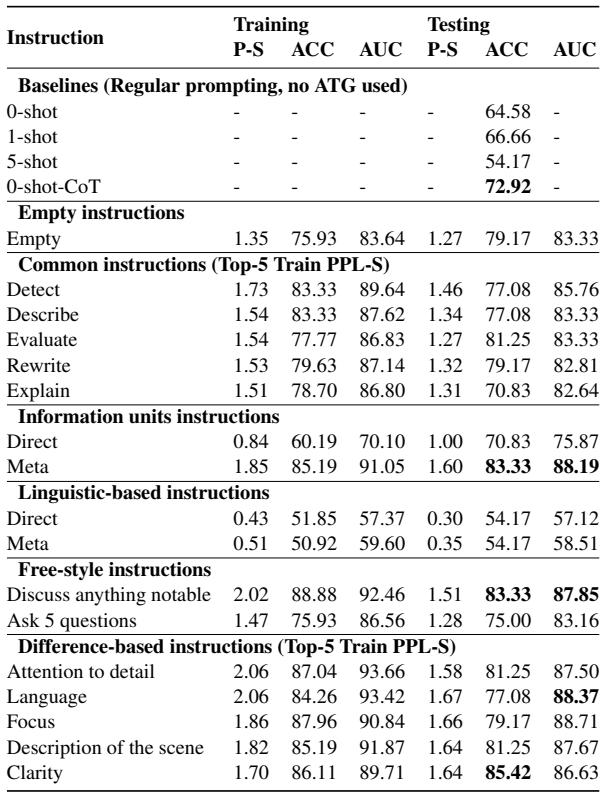
为什么“基于语言学”的指令失败了?

稳健性与参数

可解释性: 模型发现了什么?
结论与启示