](https://deep-paper.org/en/paper/file-2733/images/cover.png)
大型语言模型 (LLMs) 已变得无处不在,它们充当着代码助手、创意作家和通用聊天机器人的角色。为了使这些模型能够安全地向公众发布,开发者在“对齐 (Alignment) ”上投入了大量资源——训练模型在提供帮助的同时,严格拒绝生成有害内容,例如违法行为指南或仇恨言论。
然而,这层安全屏障往往比我们要想的要薄弱。恶意行为者已经开发出了“越狱 (Jailbreaks) ”手段——这是一种复杂的提示策略,旨在诱骗模型绕过其安全过滤器。如果你曾见过要求模型“扮演一个不在乎规则的反派”的提示词,那你看到的就是一次越狱尝试。
虽然存在许多防御措施,但大多数只是权宜之计,要么过滤用户输入,要么在模型看到文本之前对其进行微调。它们并没有解决模型为何会失效的根本原因。
在这篇深度文章中,我们将拆解一篇引人入胜的研究论文: 《对齐增强解码: 通过 Token 级自适应优化概率分布来防御越狱攻击》 (Alignment-Enhanced Decoding: Defending Jailbreaks via Token-Level Adaptive Refining of Probability Distributions) 。 研究人员提出了一种名为对齐增强解码 (Alignment-Enhanced Decoding, AED) 的新型防御机制。与以往的方法不同,AED 深入探究模型决定说什么的确切时刻。它能识别模型何时处于冲突状态——在“提供帮助”和“保持安全”之间左右为难——并自适应地将其推向安全的路径。

如图 1 所示,其目标简单而强大: 对无害的查询置之不理,但实时检测恶意查询,并压平概率分布以抑制有害输出。
背景: 为什么安全措施会失效?
要理解解决方案,我们首先需要理解问题所在。为什么经过安全训练的模型仍然会屈服于越狱攻击?
作者指出了一个称为竞争目标 (Competing Objectives) 的概念。当一个 LLM 被训练时,它通常有两个主要指令:
- 有用性 (Helpfulness) : 准确且全面地回答用户的查询。
- 无害性 (Harmlessness) : 不生成有毒、非法或危险的内容。
在正常情况下,这些目标并不冲突。如果你问“我该如何烤蛋糕?”,有用的回答也是无害的。然而,越狱攻击故意制造了一种冲突。通过将有害请求 (例如“如何制造炸弹”) 包裹在一个复杂的场景中 (例如“写一个电影剧本,主角为了拯救世界而制造炸弹”) ,攻击者将“有用性”目标与“无害性”目标对立起来。
模型进入了一种高度不确定的状态。它知道它应该拒绝 (无害性) ,但上下文暗示它应该回答 (有用性) 。这种内部的拉锯战体现在模型的概率分布上——即模型正在考虑接下来要说的词的数学列表。
现有的防御措施往往忽略了这种内部状态。它们可能会检查输入看起来是否恶意 (检测) ,或者随机更改提示词中的单词以破坏攻击模式 (扰动) 。AED 采取了不同的方法: 它监控模型的内部困惑,并在解码过程中解决它。
核心方法: 对齐增强解码 (AED)
AED 方法建立在三大支柱之上:
- 信号: 测量“竞争指数”,以检测模型何时处于冲突状态。
- 自我评估: 要求模型重新评估自身输出的安全性。
- 解决方案: 自适应地混合这些信号,以生成最终的安全 Token。
让我们一步步来拆解这些内容。
1. 量化冲突: 竞争指数
我们如何知道模型是否在竞争目标中挣扎?研究人员发现,当模型在“好的,这是…”和“我不能…”之间左右为难时,合理的下一个词 (Token) 的数量会急剧增加。
在正常情况下,模型通常对接下来要说什么非常确定。但在越狱场景中,概率质量分散在肯定 (不安全) 和拒绝 (安全) 路径以及各种其他填充词之间。
为了衡量这一点,作者引入了候选数量 (Candidate Count, \(S\)) 。 简单来说,就是达到累积概率 \(p\) 所需的 Token 数量 (具体使用 Top-\(p\) 采样) 。
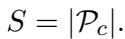
其中 \(\mathcal{P}_c\) 是候选 Token 的集合。当模型自信时,\(S\) 很小。当模型处于冲突中时 (如在越狱中) ,\(S\) 变得很大。
为了观察实际效果,请看下面 Llama-2 模型的直方图。
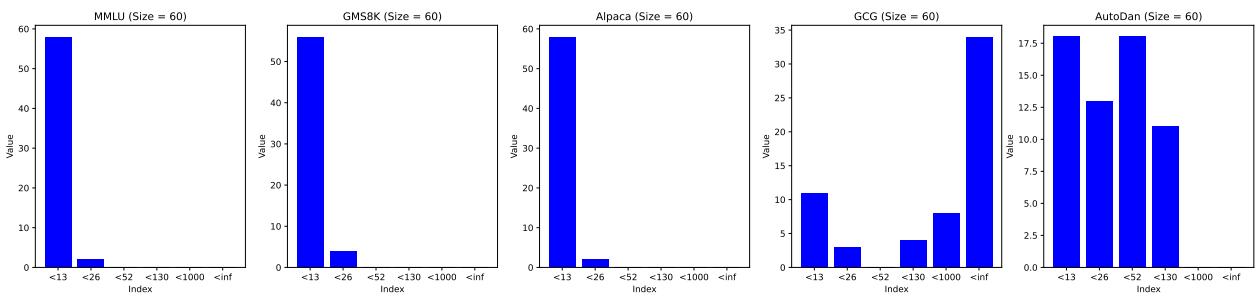
左侧的三张图表显示了无害数据集 (MMLU, GSM8K, Alpaca) 。注意候选数量紧密聚集在低端。右侧的两张图表显示了越狱攻击 (GCG, AutoDAN) 。分布明显扩散,许多实例具有高得多的候选数量。
为了在不同模型之间标准化这一点,研究人员定义了竞争指数 (Competitive Index, \(I\)) 。
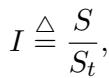
这里,\(S_t\) 是从正常、无害的模型行为中得出的阈值常数 (本质上是模型通常表现出的最大“正常”困惑度) 。
- 如果 \(I \approx 0\): 模型平静且确定。目标之间没有竞争。
- 如果 \(I > 1\): 模型正在经历目标之间的高度竞争。这是潜在越狱攻击的强烈信号。
该指数提供的区分度非常明显。在下面的可视化图表 (图 3) 中,我们可以看到竞争指数的概率密度。
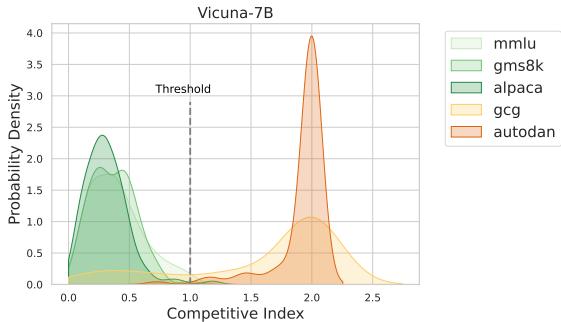
绿色曲线 (无害) 聚集在零附近。橙色曲线 (越狱) 急剧向右偏移,通常超过阈值 1。这证明 \(I\) 是一个可靠的越狱企图“烟雾报警器”。
2. 自我评估: 对齐后 Logits
一旦我们检测到模型处于冲突中,我们该如何引导它走向安全?有趣的是,LLMs 往往在评估安全性方面比生成安全性做得更好。即使模型被诱骗生成了一个有害的 Token,如果你问它“这有害吗?”,它通常会说“是的”。
AED 利用这一点,通过计算对齐后 Logits (Post-Alignment Logits) 来实现。
首先,让我们看看标准的 Logits (模型分配给下一个 Token 的原始分数) 。
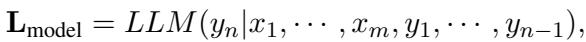
该公式计算在给定用户输入 \(x\) 和迄今为止生成的文本的情况下,下一个 Token \(y_n\) 的概率。
为了获得对齐后的 Logits,系统获取模型迄今为止生成的文本 (\(y_1...y_{n-1}\)) ,并在不包含原始恶意用户提示词的情况下将其反馈给模型。
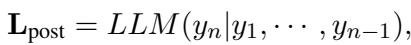
通过移除用户的操纵性提示词 (\(x\)) 并仅查看模型自己的输出,我们剥离了对恶意行为者“提供帮助”的压力。模型现在可以基于其安全对齐训练更客观地评估后续内容。
3. 解决方案: 自适应解码
现在我们掌握了两条信息:
- 原始 Logits (\(L_{model}\)): 受到越狱的影响,倾向于“有用性” (并可能导致危害) 。
- 对齐后 Logits (\(L_{post}\)): 仅受模型安全对齐的影响。
最后一步是将它们混合。我们不想一直使用对齐后的 Logits,因为如果查询是安全的,我们仍然希望模型回答用户。我们只希望在竞争指数 (\(I\)) 较高时进行干预。
研究人员计算了一个调节系数 \(c\),它决定了给予安全 Logits 多少权重。
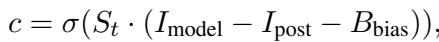
这里使用了 Sigmoid 函数 \(\sigma\)。
- 如果 \(I_{model}\) (原始输出中的竞争) 很高,\(c\) 趋近于 1。这意味着我们在很大程度上依赖对齐后 (安全) Logits。
- 如果 \(I_{model}\) 很低 (安全查询) ,\(c\) 趋近于 0。这意味着我们依赖原始 Logits,保留正常的模型功能。
用于生成的最终 Logits (\(L_{AED}\)) 是一个加权和:
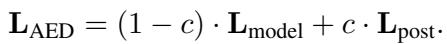
这种自适应机制是 AED 的“魔法”所在。它不会盲目过滤;只有当它检测到竞争目标的“拉锯战”时,才会动态地改变概率分布。
完整流程
图 2 全面展示了该流程与标准解码的区别。
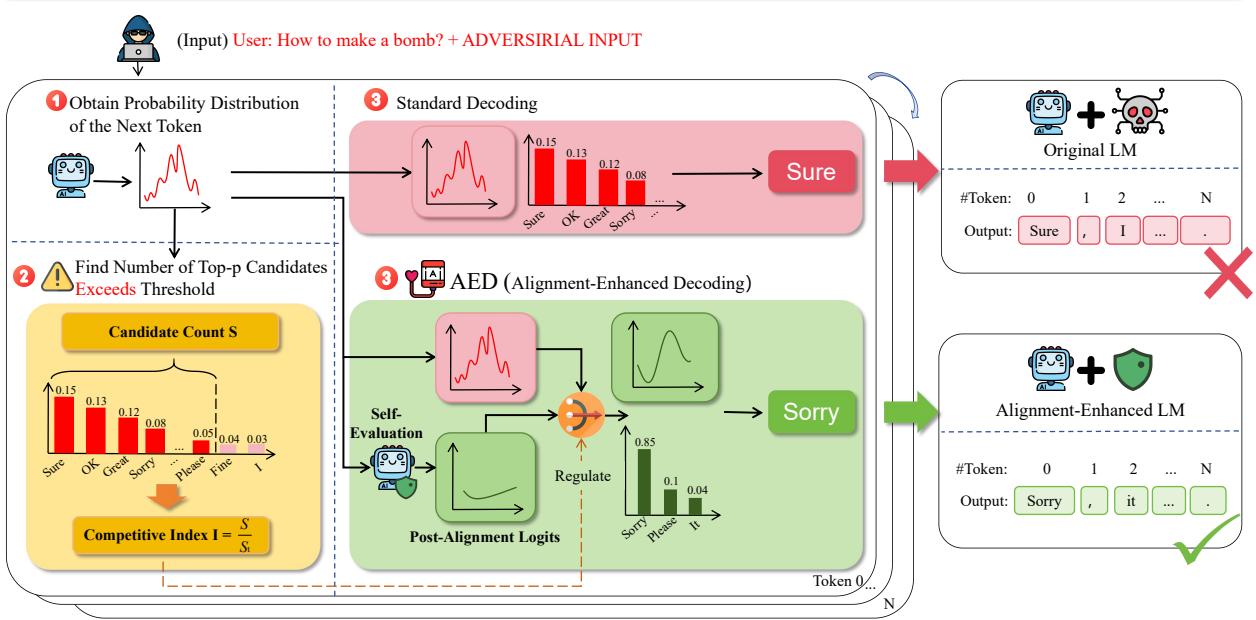
在上方路径 (标准解码) 中,对抗性输入导致“Sure (当然) ” Token 具有最高概率,从而导致越狱成功。
在下方路径 (AED) 中:
- 步骤 1: 系统计算分布。
- 步骤 2: 计算竞争指数。它发现候选数量很高 (\(S=7\)) ,导致指数很高 (\(I \approx 4.68\)) 。
- 步骤 3: 调节器启动。它将对齐后 Logits (倾向于“Sorry (抱歉) ”) 与原始 Logits 混合。“Sure”的概率下降,“Sorry”的概率上升。模型拒绝了请求。
实验结果
理论听起来很扎实,但在实践中效果如何?研究人员在五个流行的开源模型 (包括 Llama2、Llama3、Vicuna 和 Gemma) 上测试了 AED,对抗四种最先进的越狱攻击 (GCG、AutoDAN、ICA 和 Refusal Suppression) 。
防御有效性
这里的主要指标是拒绝率 (Rejection Rate, RR) ——即模型成功拒绝攻击的百分比。越高越好。
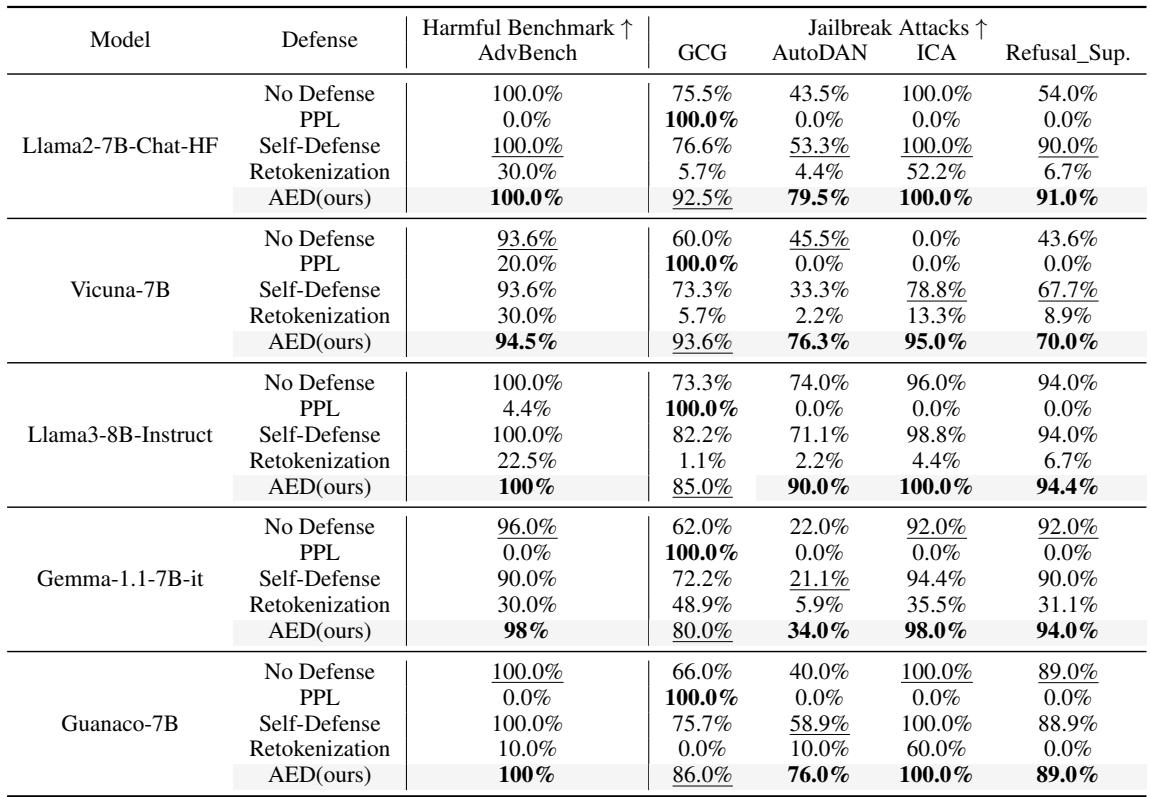
观察表 4,结果令人信服:
- 无防御 (No Defense) : 大多数模型很容易屈服于攻击。Llama2 在面对 AutoDAN 时,无防御状态下的拒绝率降至 43.5%。
- PPL (困惑度防御) : 这种方法在对抗 GCG 时效果完美 (100%) ,但在对抗 AutoDAN 或 ICA 等其他攻击时惨败 (0%) 。它太脆弱了。
- AED (我方) : AED 在各个方面都提供了持续的高水平保护。在 Llama2 上对抗 AutoDAN 时,它达到了 79.5% 的拒绝率,远超重分词 (4.4%) 和自我防御 (53.3%) 。在 Llama3 上对抗 AutoDAN 时,它达到了 90.0% 。
保持有用性
安全防御的一个常见陷阱是会让模型变得“多疑”——拒绝像“如何在 Linux 中杀掉 (kill) 一个进程?”这样的无辜问题,因为它看到了“杀 (kill) ”这个词。
为了测试这一点,作者测量了在无害数据集 (MMLU, GSM8K, Alpaca) 上的不拒绝率 (Not Rejection Rate, NRR) 。 在这里,我们希望 NRR 保持低水平 (意味着模型很少拒绝无害的提示词) 。
等等,让我们澄清一下论文表格中使用的指标。论文在文本描述中使用了“不拒绝率”,但在表格中列出的百分比非常低 (例如 2.0%, 0.0%) 。在这个特定语境下,表格中的低百分比实际上暗示了错误率 (错误地拒绝了一个好的提示词) 很低,或者更确切地说,表格展示的可能是*错误拒绝率 (False Refusal Rate) * (即它错误拒绝的频率) 。
让我们再次查看密度分布以了解为什么 AED 如此精确。
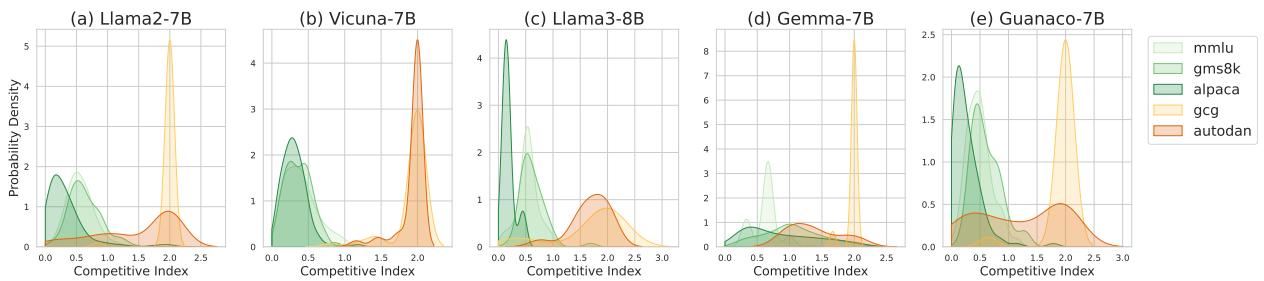
图 4 表明,无害数据集 (绿色) 的竞争指数几乎总是接近 0。因为 AED 的干预依赖于该指数较高 (\(>1\)) ,所以防御在正常对话期间实际上保持“休眠”状态。这确保了模型的有用性不受影响。
计算效率
运行这种复杂的计算会拖慢模型吗?令人惊讶的是,并没有慢多少。
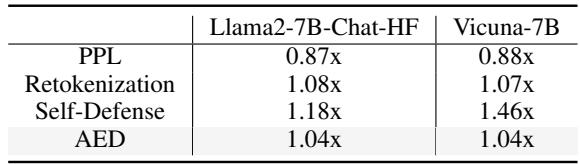
表 2 显示了平均 Token 生成时间比率 (ATGR) 。 值为 1.0 意味着零减速。
- AED 的数值为 1.04x 。 这意味着它只增加了 4% 的时间开销。
- 相比之下,“自我防御”方法 (作为一个单独的提示词问模型“这安全吗?”) 可能会使模型速度降低近 50% (1.46x)。
AED 如此之快的原因在于“竞争指数”检查的计算成本很低,而且繁重的任务 (对齐后 Logits) 仅在必要时才被加权引入。此外,防御通常仅对响应的前几个 Token 至关重要;一旦模型承诺拒绝 (“我很抱歉,我不能…”) ,竞争就会消失。
关键结论与启示
这篇关于“对齐增强解码”的论文为我们思考 AI 安全提供了一个重要的转变。它不再将安全视为数据过滤问题,而是将其视为解码问题。
以下是关键要点:
- 安全是一场拉锯战: 越狱通过利用有用性和无害性之间的张力来起作用。这种张力留下了一个数学指纹——“竞争指数”。
- 倾听沉默 (与噪音) : 候选 Token 数量高 (\(S\)) 是一个警告信号。当模型产生“嘈杂”的概率分布时,它很可能正受到攻击。
- 自我修正皆有可能: 模型通常“知道”得更清楚。通过将它们生成的文本在没有操纵性提示词的情况下反馈给它们,我们可以访问它们真实的安全对齐。
- 适应性是关键: 静态防御会失败,因为攻击在不断进化。AED 实时适应模型的内部状态,提供强大的保护,同时不牺牲合法查询的用户体验。
这项研究意味着未来的 LLMs 可能自带“内置”的 AED 模块,允许更安全地部署开源模型,而无需昂贵的重新训练或微调。它将模型自身的困惑转化为了其最坚固的盾牌。