](https://deep-paper.org/en/paper/file-2741/images/cover.png)
引言
在人工智能飞速发展的世界中,像 GPT-4 这样的大型语言模型 (LLMs) 树立了极高的性能标杆。它们最令人印象深刻的功能之一是执行思维链 (Chain-of-Thought, CoT) 推理的能力——即在得出答案之前,将复杂问题分解为一步步的逻辑解释。这种能力彻底改变了模型处理数学应用题、符号逻辑和多步规划的方式。
然而,这其中存在一个问题: 这种推理能力通常只在拥有数十亿参数的巨型模型中才会“涌现”。较小的模型虽然更具成本效益且部署速度更快,但往往难以独立完成复杂的推理任务。为了解决这个问题,研究人员使用了一种称为蒸馏 (distillation) 的技术,即由大型“教师”模型生成推理步骤,让小型“学生”模型去模仿学习。
但在当前的研究领域中存在一个巨大的空白: 大多数蒸馏工作几乎只关注英语。随着人工智能成为一种全球性的工具,我们如何在多语言环境中有效地将推理能力迁移到较小的模型上?我们应该用英语还是母语来教它们?此外,如果我们不仅告诉学生该做什么,还告诉他们不该做什么,能否改进这一过程?
在这篇文章中,我们将深入探讨一篇题为 “An Empirical Study of Multilingual Reasoning Distillation for Question Answering” 的论文。作者提出了一种名为 d-CoT-nR 的新方法,即包含负面理据的多样化思维链 (Diverse Chain-of-Thought with Negative Rationales) 。 通过利用错误的推理路径作为“负面指导”,他们证明了我们可以显著提升小型多语言模型的性能。
背景: 推理蒸馏的基础
在解析新方法之前,让我们先建立理解这篇论文所需的基础概念。
思维链 (Chain-of-Thought, CoT)
在标准的问答 (QA) 中,模型接收上下文和问题,然后直接预测答案 (\(Input \rightarrow Answer\)) 。而在思维链推理中,模型会生成一个中间的推理步骤序列 (\(Input \rightarrow Rationale \rightarrow Answer\)) 。这模仿了人类解决问题的方式,通常能在复杂任务上带来更高的准确率。
知识蒸馏
为每个用户查询运行一个巨大的 LLM (教师) 既昂贵又缓慢。蒸馏将教师的能力迁移到一个更小、更高效的模型 (学生) 上。在推理的背景下,教师生成包含问题、正确答案以及导致这些答案的理据 (推理步骤) 的训练数据。然后,学生模型在这些数据上进行微调。
学生模型的标准训练目标是最小化其预测与教师理据之间的差异。在数学上,这通常表示为最大化在给定输入 (\(\boldsymbol{x}\)) 的情况下生成正确理据 (\(\boldsymbol{r}\)) 和答案 (\(\boldsymbol{y}\)) 的对数似然。
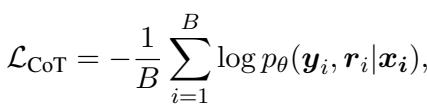
在这里,\(\theta\) 代表学生模型的参数。目标是最大化正确序列的概率 \(p_\theta\)。
多语言挑战
研究人员发现,虽然蒸馏在英语中得到了充分研究,但在多语言环境中应用它引入了新的变量。他们的研究围绕三个关键设计决策展开,这也是他们方法论的支柱。
1. 语言因素: 母语 vs. 英语
在训练多语言学生模型 (如 mT5 或 XGLM) 回答土耳其语或越南语等语言的问题时,推理步骤应该使用什么语言?
- 英语 CoT: 无论输入语言是什么,教师都将推理过程翻译成英语。
- 母语 CoT: 教师生成与问题语言相同的推理步骤。
先前关于大型模型的研究表明,用英语提示通常更优,因为模型主要是在英语数据上预训练的。然而,对于将特定的推理技能蒸馏到较小的模型中,情况是否依然如此?
2. 多样性因素: 多样化 CoT (d-CoT)
一种解释就足够了吗?标准蒸馏通常依赖于教师生成的单一推理路径 (贪婪解码) 。然而,教师模型可以生成多种解决问题的有效方法。作者探索了多样化 CoT , 即从教师那里采样多条推理路径 (理据) ,并过滤掉错误的,只保留导致正确答案的路径。
这种方法让学生接触到更丰富的逻辑结构和词汇。损失函数经过调整,对多个多样化的理据 (\(D\)) 进行平均:
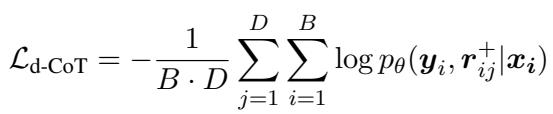
3. 负面因素: 从错误中学习 (d-CoT-nR)
这是论文的主要贡献。当教师模型生成多样化的理据时,它并不总是能得出正确答案。它经常会产生负面理据——那些听起来合理但导致错误答案的推理路径。
通常,这些数据会被丢弃。作者认为这些“错误”是有价值的数据。通过明确地教导学生模型避免这些错误的推理模式,他们可以优化模型的决策边界。这就引出了他们提出的方法: d-CoT-nR (包含负面理据的多样化思维链) 。
方法论: d-CoT-nR
为了直观地展示这些方法的对比,让我们看看研究人员设计的架构流程。

如图 1 所示,流程始于语言选择 (英语 vs. 母语) 。然后进入多样化环节。
- 顶部: 标准 CoT (单一路径) 。
- 中间 (灰色) : d-CoT (多条正面路径) 。
- 底部 (彩色) : d-CoT-nR,使用正面 (绿色) 和负面 (红色) 理据。
d-CoT-nR 如何工作
d-CoT-nR 的训练目标是标准多样化损失 (学习该做什么) 和新的“负面”损失 (学习不该做什么) 的加权组合。
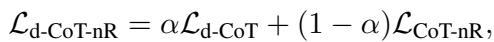
这里,\(\alpha\) 是平衡两个目标的超参数。有趣的部分是 \(\mathcal{L}_{\mathrm{CoT}-\mathrm{nR}}\)——我们究竟如何在数学上告诉模型“不要这样做”?作者实验了三种不同的利用负面理据的技术:
1. 非似然训练 (Unlikelihood Training)
这是最简单且如我们稍后所见最有效的方法。它修改了损失函数,明确降低负面理据 (\(\boldsymbol{r}^-\)) 中出现的 token 的生成概率。本质上,如果模型开始听起来像错误的推理,它就会受到惩罚。
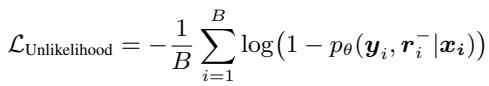
2. 对比学习 (CLICK)
这种方法试图确保正面理据的概率总是比负面理据高出一个特定的边际 (\(\gamma\)) 。它在好的和坏的推理之间创造了一个“差距”。
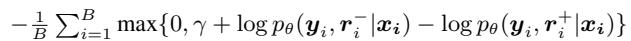
3. 偏好优化 (ORPO)
基于人类反馈强化学习 (RLHF) 中使用的方法,这将问题视为偏好任务。它使用胜率比 (odds ratios) 来增加正面理据相对于负面理据的可能性,而不需要单独的奖励模型。
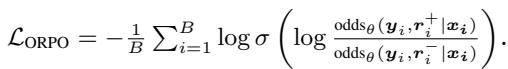
实验设置
为了验证这些假设,作者进行了严格的实证研究。
- 数据集: EXAMS,一个包含多种语言、涵盖各学科 (生物、历史等) 的高中多项选择题基准测试。
- 教师模型: GPT-3.5-turbo。
- 学生模型:
- mT5-base (580M): 编码器-解码器模型。
- XGLM (564M): 仅解码器模型。
- Gemma-Instruct (2B): 一个更大、更强的基线,用于观察趋势是否在更强的模型上依然成立。
- 语言: 他们将语言分为头部语言 (TPL,资源丰富) 和尾部语言 (BPL,资源较少) 。
结果与分析
结果提供了一些挑战领域内常见假设的有趣见解。
发现 1: 母语 CoT 优于英语 CoT
与巨型 LLMs 的趋势 (英语提示通常获胜) 相反,对于蒸馏小型模型 , 使用母语更优。
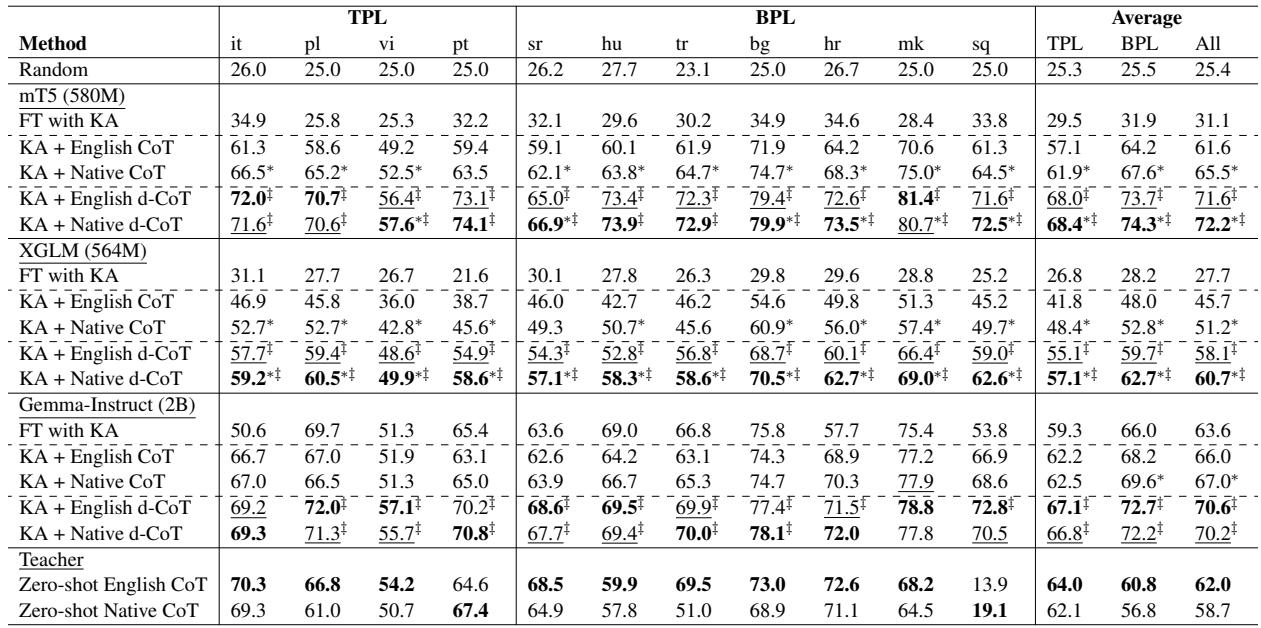
查看表 1 , 我们看到对于 mT5 和 XGLM, 母语 CoT 在几乎所有语言中都显著优于英语 CoT。
- 对于 mT5,英语 CoT 达到了 61.6% 的准确率,而母语 CoT 达到了 65.5% 。
- 这表明,虽然大型模型是以“英语为中心”的,但小型模型很难跨越英语推理与非英语问题之间的鸿沟。教它们用目标语言进行推理更为有效。
发现 2: 多样性是关键
表 1 还强调了 d-CoT (多样化 CoT) 的影响。当教师提供多种解决问题的方法 (母语 d-CoT) 时,性能进一步跃升——对于 mT5,从 65.5% 提升到了 72.2% 。 这证实了看到不同的推理模式比只看一条死板的路径能帮助学生模型更好地泛化。
发现 3: 负面理据很强大 (d-CoT-nR 的胜利)
最关键的结果涉及提出的方法 d-CoT-nR。向模型展示错误的推理有帮助吗?
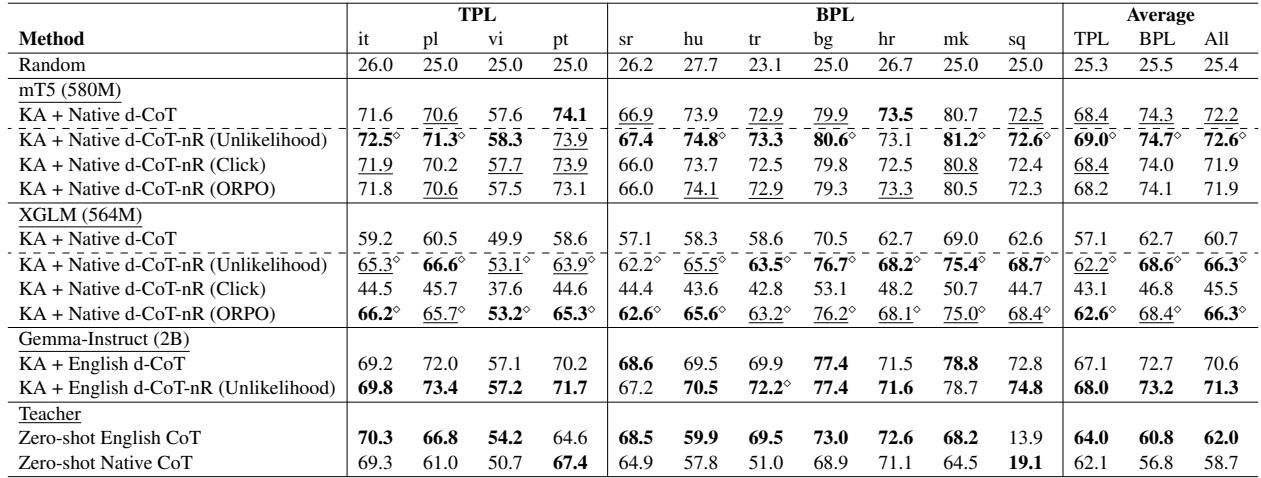
表 2 将标准多样化方法与三种“负面”训练策略 (非似然、CLICK、ORPO) 进行了比较。
- 非似然获胜: 最简单的方法,即非似然训练,始终提供最佳的提升。对于 XGLM 模型,使用非似然训练将准确率从 60.7% 推高至 66.3% 。
- 原因? 作者推测,非似然训练有效地“退化”了不需要的序列。它充当了一个硬性的护栏,主动降低已知错误推理路径的概率,从而优化了推理过程中的搜索空间。
- 与架构无关: 这种改进在不同的模型架构 (编码器-解码器 vs. 仅解码器) 和规模 (500M vs 2B 参数) 上都被观察到了。
发现 4: 对未见语言的泛化能力
多语言 AI 的一个主要问题是跨语言迁移。如果我们教模型用法语和德语推理,它在西班牙语上会变得更好吗?
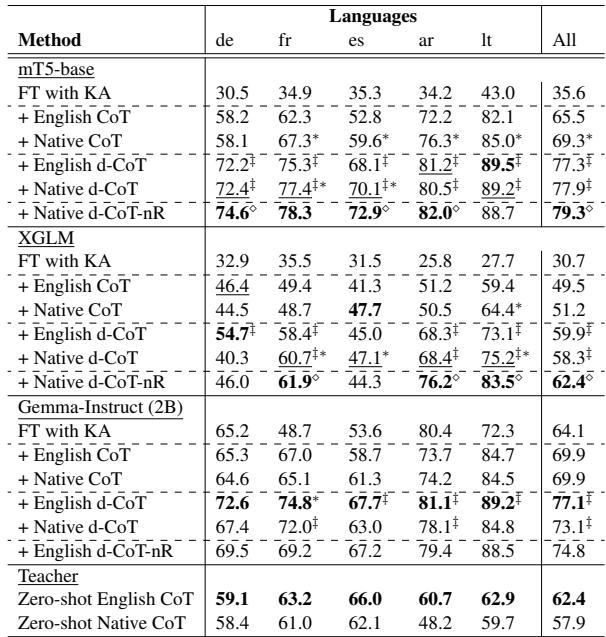
表 3 展示了模型在未微调过的语言上的表现。
- d-CoT (使用多样化的正面理据) 显示出比标准训练在未见语言上有巨大的提升。
- d-CoT-nR (添加负面理据) 对于像 mT5 和 XGLM 这样的模型进一步推动了这一提升。
- 这意味着通过学习推理的结构以及要避免的逻辑陷阱,模型获得了可以跨越语言障碍的抽象能力。
结论与启示
这项研究揭示了我们如何普及推理能力。我们并不总是需要巨大、昂贵的模型来执行复杂的任务。通过精心设计蒸馏过程,我们可以训练小型、高效的模型在多种语言中有效地进行推理。
主要结论:
- 使用母语: 训练小型模型时,用目标语言而不仅仅是英语来蒸馏推理能力。
- 拥抱多样性: 不要将训练数据限制为一条“正确”路径;多样性建立鲁棒性。
- 从失败中学习: 将“负面理据”——错误的推理路径——与非似然目标结合起来,起到强大的负强化作用。它不仅教模型如何思考,还教它不该如何思考。
d-CoT-nR 的引入为未来的研究提供了一个充满希望的方向。它表明我们通常过滤掉的“垃圾”数据——教师模型的幻觉和逻辑错误——实际上可能是一个金矿,用于训练下一代鲁棒、高效的 AI。通过向学生展示陷阱,我们帮助他们更自信地找到通往正确答案的道路。