](https://deep-paper.org/en/paper/file-2742/images/cover.png)
预测下一个重大发明: 图神经网络如何分析专利引用
创新是现代经济的引擎,而专利制度则是其燃料。每年都有数十万项专利获得授权,代表着数十亿美元的研发投入。但这里有一个价值万亿美元的问题: 这些专利中,究竟哪些才真正重要?
大多数专利最终都默默无闻,从未产生显著价值。然而,极少数专利会成为定义行业的基石技术。从历史上看,识别这些“高质量”专利一直是一场回顾性的博弈。我们往往是在一项专利被其他发明人引用数百次之后,才知道它是有价值的。但是,如果我们要仅凭专利本身的文本,在它产生影响之前就做出预测,这可能吗?
在论文《An Experimental Analysis on Evaluating Patent Citations》 (关于评估专利引用的实验性分析) 中,研究人员 Rabindra Nath Nandi、Suman Kalyan Maity、Sourav Medya 和 Brian Uzzi 解决了这一确切的挑战。他们提出了一种超越简单文本分析的新颖方法。通过构建专利的语义图 (Semantic Graph) 并应用图神经网络 (Graph Neural Networks, GNNs) , 他们证明了我们可以以惊人的准确率预测一项专利是否会被高频引用。
在这篇深度文章中,我们将探讨他们如何将法律文档数据库转化为具有预测能力的图谱,其神经网络背后的数学原理,以及这对未来创新追踪意味着什么。
创新版图
要理解解决方案,我们首先必须了解数据。美国专利商标局 (USPTO) 授予实用新型专利,以保护新的工艺、机器和物质构成。
研究人员重点关注了过去二十年的数据 (2000–2022) ,特别针对三个主要的联合专利分类 (CPC) 类别。这些类别代表了巨大的经济部门:
- A61: 医学或兽医学
- H04: 电通信
- G06: 计算

如上表 1 所示,这些类别包含数十万项专利。人工分析这些专利是不可能的。此外,这些专利的性质也在发生变化。
研究人员对元数据进行了描述性分析以发现趋势。如下图 2 所示,发明的复杂性正在上升。每项专利的平均发明人数量 (团队规模) 呈上升趋势,特别是在医学领域 (A61) 。协作正变得至关重要。

相反,虽然文档量 (附图和页数) 在增加,但具体的“权利要求 (claims) ”数量——即发明边界的法律定义——却呈下降趋势或保持平稳,如图 3 所示。这表明,虽然发明的描述变得更加复杂且需要更大的团队,但所主张的法律范围正变得更加聚焦。
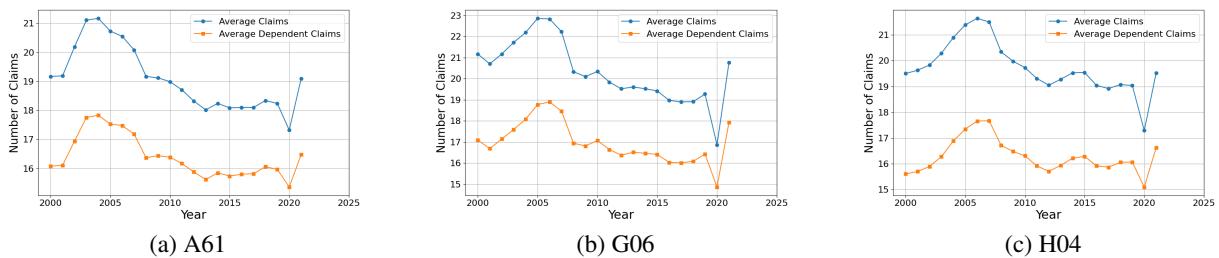
这种不断变化的格局使得历史回归模型难以使用。作者认为,要真正理解专利质量,我们需要理解专利之间的关系 , 而不仅仅是它们的个体统计数据。
定义预测问题
论文的核心前提是引用次数是质量的代理指标。如果一项专利被随后的专利频繁引用,这意味着该发明是未来技术的基石。
作者将其表述为一个二分类问题 。 他们不试图预测确切的引用次数 (回归任务) ,而是旨在将专利分类为: 高引用 (高质量) 与低引用 (低质量) 。
为了严谨地做到这一点,他们基于 \(d\) 年内的引用分布定义了一个阈值 (其中 \(d\) 为 3、5 或 10 年) 。
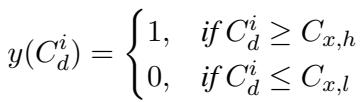
在这个公式中:
- \(y(C_d^i)\) 是标签 (1 代表高质量,0 代表低质量) 。
- \(C_{x,h}\) 是处于前 \(x\) 百分位数的引用次数 (例如,前 10%) 。
- \(C_{x,l}\) 是处于后 \(x\) 百分位数的引用次数。
通过隔离前 10% 和后 10% 的专利,研究人员创建了一个清晰的数据集,以测试他们的 AI 模型是否能区分“重磅炸弹”专利和“哑弹”专利。
方法: 从文本到图
这正是论文创新的地方。传统方法可能会将专利文本输入分类器并祈求好运。然而,作者假设专利版图的语义结构至关重要。
他们构建了一个语义图 (Semantic Graph) 。 在这个图中:
- 节点 (Nodes) 代表单个专利。
- 边 (Edges) 代表语义相似性。如果两项专利描述了类似的技术 (即使它们没有显式地相互引用) ,它们也会被连接起来。
第一步: 生成节点特征 (“什么”)
首先,每项专利的文本 (标题、摘要和权利要求) 需要转换为数值向量。作者采用了两种最先进的自然语言处理 (NLP) 技术:
- Doc2Vec: Word2Vec 的扩展,用于学习文档的固定长度特征表示。它捕捉专利文本的一般语义含义。
- PatentBERT: 著名的 BERT Transformer 模型的一个版本,专门在专利数据上进行了微调。这使得模型能够理解专利特有的复杂法律和技术术语。
第二步: 构建图结构 (“哪里”)
利用 Doc2Vec 的嵌入 (embeddings) ,研究人员计算每对专利之间的相似度。如果相似度得分超过特定阈值 (通常为 0.6 到 0.8) ,就在它们之间画一条边。
这这就形成了一个巨大的相关思想网络。一项关于新型手术机械臂的专利可能会与一项关于机械关节的专利相连,不是因为它们互相引用,而是因为它们的文本描述在数学上是相似的。
第三步: 图神经网络 (引擎)
图构建完成后,作者应用了图神经网络 (GNNs) 。 GNN 的设计初衷不仅是从单个节点的数据中学习,还要从其邻居的数据中学习。
GNN 的核心机制是消息传递 (Message Passing) 。 每个节点通过聚合其邻居的信息来更新自身的表示。

在这个公式中,\(h_u^{(l)}\) 是节点 \(u\) 的新状态。它是通过聚合 (\(AGGR\)) 其自身之前的状态及其所有邻居 \(N(u)\) 的状态而得出的。这允许模型在图上“平滑”特征——如果一项专利看起来像个“哑弹”,但在语义上被高质量专利包围,GNN 可以相应地调整其预测。
作者测试了三种特定的 GNN 变体:
1. 图卷积网络 (GCN) : GCN 使用谱卷积方法。本质上,它们对邻居的特征进行平均。
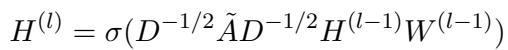
2. GraphSAGE: GraphSAGE 更加灵活。它学习特定的聚合函数 (如均值或最大池化) ,并将邻居信息与节点当前的信息拼接 (concatenate) ,从而允许进行更复杂的关系建模。
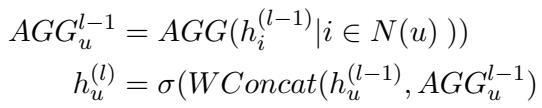
3. 图 Transformer 网络 (GTN) : 这些网络使用自注意力机制 (Self-attention) ,类似于大型语言模型中的机制。注意力机制计算权重 (\(Att\)) 以确定哪些邻居最重要,而不是平等对待所有邻居。
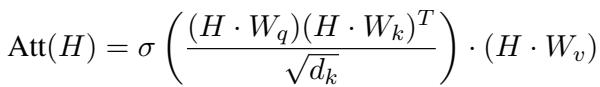
实验结果
研究人员按时间顺序分割数据以模拟真实场景: 在较旧的专利上进行训练,在较新的专利上进行测试。例如,使用 2000–2017 年的数据预测 2018–2019 年授权专利的引用情况。
识别高影响力专利
首要目标是召回率 (Recall) : 在所有真正的高影响力专利中,模型找到了多少?
结果如表 2 所示,令人印象深刻。基于 GNN 的方法 (GCN, GTN, GSAGE) 始终优于不使用图结构的基线 MLP (多层感知机) 模型。

在医学领域 (A61) 的 10 年预测窗口中, PatentBERT-GTN 模型实现了 0.94 的召回率 。 这意味着模型仅使用授权时可用的文本,就成功识别了 94% 的高价值专利。
F1 分数 (精确率和召回率的平衡) 也讲述了类似的故事,图基方法占据主导地位。

更难的分类任务
区分前 10% 和后 10% 是一回事,但模型能区分最好的和其余的吗?
作者进行了高引用 vs. 其余 (表 3) 和中等引用 vs. 低引用 (表 5) 的分类实验。

即使在噪音大得多的“高引用 vs. 其余”任务中,GraphSAGE (GSAGE) 和 GTN 模型仍保持了较高的准确率 (~73-74%) ,显著优于标准的 MLP 基线 (~50%) 。
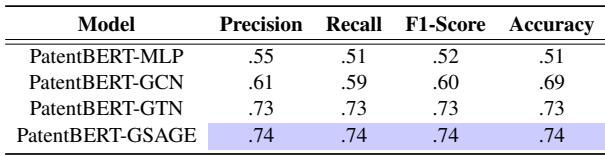
表 5 显示,模型甚至可以区分“平庸”专利和低质量专利,证明语义图捕捉到了细粒度的质量谱系,而不仅仅是极端情况。
打开黑盒: 为什么选中某项专利?
使用图神经网络的一个显著优势是可解释性 (explainability) 。 深度学习常被批评为“黑盒”,但由于 GNN 依赖于连接,我们可以可视化是哪些连接驱动了决策。
作者利用了一种名为 GNNExplainer 的技术。该工具可以识别出对模型预测影响最大的子图 (节点和边的特定集群) 。
图 1 展示了一项特定专利 (节点 7) 的解释子图,该专利名为*“Interchangeable shaft assemblies for use with a surgical instrument”* (用于手术器械的可互换轴组件) 。
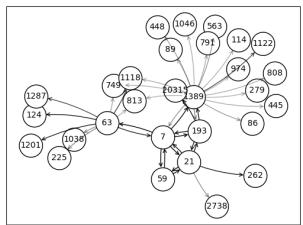
模型预测节点 7 将被高频引用。为什么?通过观察解释子图,我们发现节点 7 与其他节点 (如节点 21 和节点 63) 紧密相连。
当我们在表 7 中查看这些邻居的详细信息时,原因就变得清晰了。

这些邻居本身也是高引用专利,且标题都与类似的手术模块化有关。GNN 有效地进行了推理: “这项新专利在语义上处于一组其他非常成功的手术发明集群的中心;因此,它很可能也会成功。”
这证实了高质量专利倾向于在语义空间中聚集。它们形成了创新的密集邻域。相比于深深嵌入在繁荣技术生态系统中的专利,一个在语义图中处于稀疏区域的孤立专利获得关注的可能性较小。
结论与启示
这项研究弥合了自然语言处理和网络科学之间的差距,解决了一个关键的经济问题。通过将专利不视为孤立的文档,而是视为一个活的、不断演进的思想网络中的节点,作者证明了我们可以以高可靠性预测未来的影响。
主要结论:
- 文本是不够的: 理解专利版图的结构 (语义图) 与阅读专利文本同样重要。
- 语境为王: GNN 模型优于标准文本分类器,因为它们利用了“群体智慧”——聚合了相关发明的信号。
- 可解释性: 图模型提供了透明的视角来解释为什么做出预测,允许投资者和审查员看到一项发明的“邻域”。
随着创新步伐的加快和专利申请数量的激增,这类工具将变得至关重要。它们提供了一种穿透噪音的方法,在发明获得第一次引用之前,就能识别出那些将塑造我们未来的发明。