](https://deep-paper.org/en/paper/file-2776/images/cover.png)
打破界限: 如何在杂乱的临床数据中分割句子
如果你曾尝试处理自然语言处理 (NLP) 项目的文本数据,你会知道第一步往往最具欺骗性。在你能够进行情感分析、命名实体识别 (NER) 或机器翻译之前,你必须回答一个简单的问题: 一个句子在哪里结束,下一个句子又从哪里开始?
在正式写作中——比如小说或新闻文章——这很简单。你只需寻找句号、问号或感叹号,然后分割文本即可。但是,如果文本是医生在病患之间匆忙写下的呢?如果文本是意识流、生命体征列表,或者是像“病人镇静对语言刺激无反应”这样的碎片化笔记呢?
在这篇文章中,我们将深入探讨一篇名为 《真实世界数据中临床记录叙述的自动句子分割》 (Automatic sentence segmentation of clinical record narratives in real-world data) 的研究论文。我们将探讨为什么传统工具在临床文本上彻底失效,并解析一种无需依赖标点符号,利用深度学习和巧妙的滑动窗口算法来解决这一问题的新颖方案。
隐形难题: 为什么分割很重要
句子分割是 NLP 金字塔的基础层。几乎所有复杂的下游模型都期望输入的是连贯的句子。
想象一个英西翻译模型。如果你喂给它两个混在一起的半句,翻译结果将是一团糟。同样,在临床 NLP 中,如果我们想提取诊断结果或药物清单,系统需要知道思维的边界。这里的错误会向上传播。如果分割器失败,它可能会破坏指代消解 (弄清楚“他”指的是谁) 或摘要任务的性能。
“句号”谬误
几十年来,解决这个问题的标准方法是基于规则的。我们假设句子是一个符合语法的单词序列,并以特定的标点符号 (PM) 结尾,通常是 . ? 或 !。
像 Stanford CoreNLP 或 NLTK 分词器这样的标准工具严重依赖这些规则。它们可能会使用正则表达式或简单的机器学习分类器来判断一个句点究竟是句号还是缩写的一部分 (如“Dr.”或“U.S.”) 。
这对于《华尔街日报》来说非常有效。但对于电子健康记录 (EHRs) 来说,这是灾难性的。
临床笔记是“真实世界”的数据。它们的特点是:
- 碎片化: 不完整的句子 (如“无发热。”) 。
- 缺失标点: 思维之间通过换行符或仅仅是空格分隔,而不是句号。
- 复杂布局: 标题、要点和表格不遵循标准语法。
如果医生输入“BP 120/80 HR 70”,标准的基于规则的系统可能会将其视为一个句子。但在语义上,这是两个不同的测量值,可能需要分别处理。
方法: 序列标注优于规则
提出这一新方法的研人员决定放弃寻找“句末标点符号” (EPMs) 的想法。他们重新构建了这个问题。他们不再问“这个字符是句号吗?”,而是问“这个词是新句子的开头吗?”
他们将句子分割视为一项序列标注任务 。
BIO 标注方案
为了训练模型在没有标点符号的情况下识别句子,作者使用了 BIO 标注方案。这是命名实体识别中的常用技术,但在这里被应用于句子边界。
对于文档中的每个 token (词) ,模型会分配以下三个标签之一:
- B (Beginning,开始): 该 token 是句子的第一个词。
- I (Inside,内部): 该 token 在句子内部 (但不是开头) 。
- O (Outside,外部): 该 token 不属于句子 (用于忽略元数据、标记或标题) 。
通过观察词语的上下文而不是仅仅关注标点符号,深度学习模型 (特别是 BERT) 可以学习到,跟在血压读数后面的“HR” (心率) 通常标志着新思维的B (开始) ,即使它们之间没有句号。
核心创新: 滑动窗口算法
使用 BERT 处理这项任务引入了一个重大的工程挑战。基于 BERT 的模型有严格的输入限制,通常是 512 个 token 。
临床笔记可能非常长——出院总结通常有数千字。你不能简单地将整个文档塞进 BERT。
为什么简单的切分会失败
天真的解决方案是将文档切分成 512 个 token 的块,分别处理,然后再把它们拼回去。但是,如果切分点 (第 512 个 token) 正好落在句子中间怎么办?模型会失去该句子后半部分的上下文,导致边界预测错误。
动态滑动窗口
研究人员提出了一种动态滑动窗口算法 , 该算法根据模型的预测进行调整。这使他们能够“即时”处理无限长度的文档,同时确模型始终拥有足够的上下文。
让我们看看这在概念上是如何工作的:
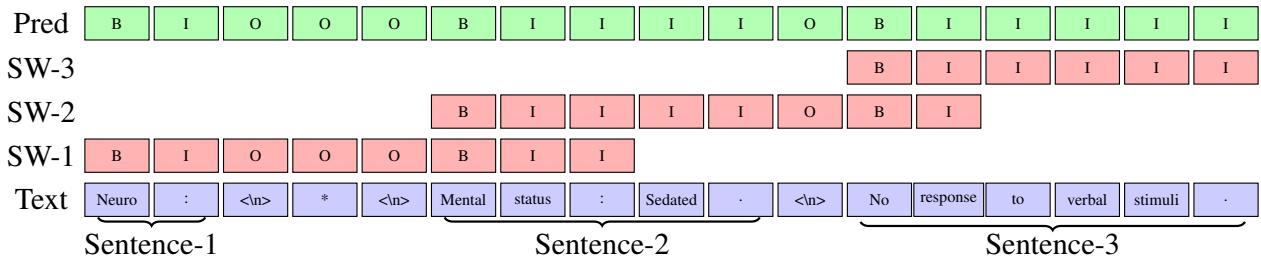
图 1: 运行中的滑动窗口算法。注意窗口 (SW-1、SW-2、SW-3) 是如何重叠以确保上下文被保留的。
在图 1 中,我们看到一段短文本: “Neuro : * Mental status : Sedated . No response to verbal stimuli .” (神经: * 精神状态: 镇静。对语言刺激无反应。)
以下是该算法使用的分步逻辑:
- 填充窗口: 算法从文档中抓取一段文本 (达到最大长度 \(l\)) 。在图中,
SW-1代表第一轮。 - 预测: BERT 模型预测该窗口内所有内容的 B/I/O 标签。
- 寻找“安全”切分点: 这是关键步骤。算法查看预测结果,并识别窗口中第二个句子的开始位置 (标记为 \(b_{i+1}\)) 。
- 滑动: 算法不是滑动固定数量的 token,而是滑动窗口,使其正好从那个第二个句子 (\(b_{i+1}\)) 开始。
这确保了下一个窗口 (SW-2) 以一个新鲜、完整的句子上下文开始。第一个句子被最终确定并保存,然后重复该过程。
如果模型在当前窗口中找不到第二个句子 (可能这是一个巨大的连贯句) ,它默认滑动最大长度 \(l\)。
以下是该过程背后的形式化逻辑:

通过观察算法 1 , 我们可以看到变量 \(w_i\) 跟踪文本中的当前位置。第 9-11 行完成了繁重的工作: 识别第一个完整句子的边界 (\(b_i\) 到 \(e_i\)) 和下一个句子的开始 (\(b_{i+1}\)) ,有效地“锁定”第一个句子并将窗口移动到下一个句子的开始。
数据缺口
为了证明这种方法有效,研究人员面临一个障碍: 没有公开可用的、人工标注的临床笔记句子分割数据集。大多数现有数据集都是“银标准”——由 CoreNLP 等工具自动生成的——这恰恰强化了本文旨在解决的错误。
作者基于 MIMIC-III 语料库 (一个著名的去标识化健康数据库) 创建了一个新数据集。他们人工标注了 90 份临床笔记。
这一标注过程揭示了临床数据与用于训练 NLP 工具的标准语料库有多么不同。让我们看看统计数据:
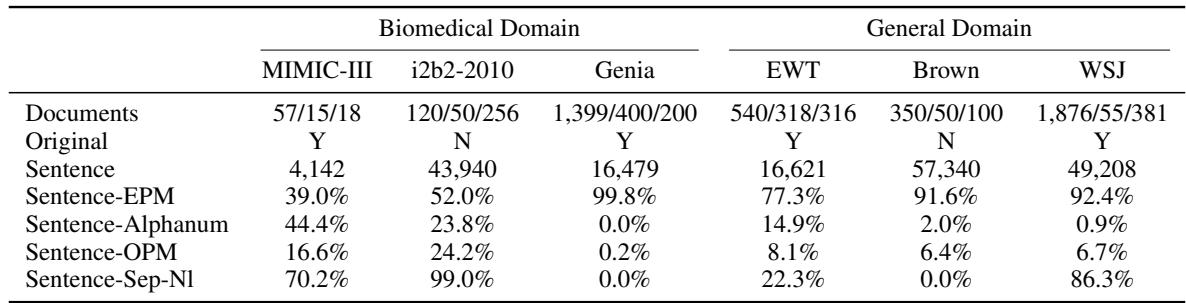
仔细看看表 1 , 特别是 Sentence-EPM (以标点结尾的句子) 这一行。
- 在 Genia 数据集 (生物医学摘要) 中, 99.8% 的句子以标准标点符号结尾。
- 在 WSJ (华尔街日报) 中, 92.4% 以标点符号结尾。
- 在 MIMIC-III (临床笔记) 中,只有 39.0% 的句子以标点符号结尾。
仅仅这一项统计数据就解释了为什么现成的工具会失败。如果你的工具通过寻找句号来发现句子,它将漏掉临床笔记中 61% 的句子。
此外,看看 Sentence-Alphanum (以字母数字结尾的句子) 。在 MIMIC-III 中, 44.4% 的句子以字母或数字结尾 (例如,“Pt denies pain”即“病人否认疼痛”) 。在《华尔街日报》中,这种情况发生的概率仅为 0.9%。这是语言结构上的根本差异。
实验与结果
研究人员将他们的 Segmenter (分割器) 与七种行业标准工具进行了比较: NLTK、CoreNLP、cTAKES (专为临床文本设计) 、Syntok、spaCy、Stanza 和 Trankit。
他们训练了两个版本的模型:
- Segmenter-Data: 专门在目标数据集上训练。
- Segmenter-Domain: 在同一领域的数据集组合上训练 (例如,所有生物医学数据组合) 。
临床数据上的表现
MIMIC-III 数据集上的结果令人震惊。
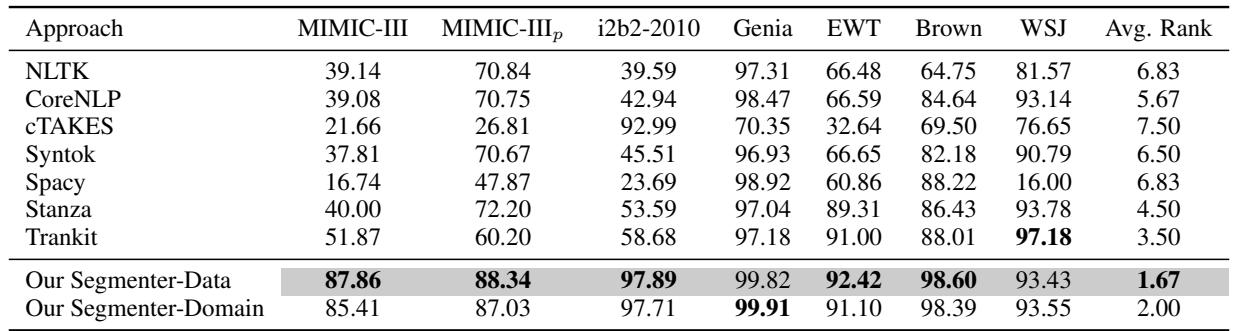
在 表 2 中,看看 MIMIC-III 这一列。
- cTAKES (临床工具) 获得了 21.66 的 F1 分数。
- spaCy 获得了 16.74 。
- CoreNLP 获得了 39.08 。
- 我们的 Segmenter-Data 获得了 87.86 。
这不是微小的改进;这是范式的转变。与标准工具相比,F1 分数 (结合了精确率和召回率的指标) 跃升了近 50 分。
即使作者试图“帮助”其他工具 (MIMIC-III_p 列) ,通过手动清理输出规则,他们的模型仍然比最好的竞争对手高出 15% 以上。
泛化能力
对在特定数据上训练的深度学习模型的一个普遍担忧是,它们会“过拟合”,并在遇到正常文本时失效。然而,结果表明这种方法具有鲁棒性。
在 WSJ 和 Brown 语料库 (标准英语) 上,该 Segmenter 的表现具有竞争力 (93-98% F1) ,经常击败或匹配专为标准英语设计的工具。
跨领域鲁棒性
作者还测试了在一个领域训练的模型在另一个领域上的表现。
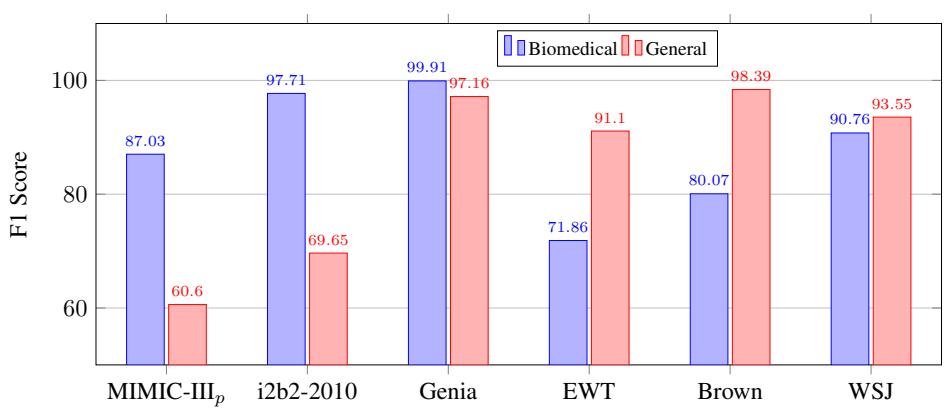
图 3 展示了这种稳定性。
- 蓝色柱 代表在生物医学文本上训练的模型。
- 红色柱 代表在通用文本上训练的模型。
虽然生物医学模型在生物医学数据 (MIMIC, i2b2, Genia) 上表现最好,但它在通用文本 (EWT, Brown, WSJ) 上仍保持了可观的性能。这表明序列标注方法学习到了句子结构的基本规律,而不仅仅是领域特定的词汇。
为什么它会赢?边缘情况
为了理解究竟是从哪里获得了改进,研究人员按句子类型分解了性能。
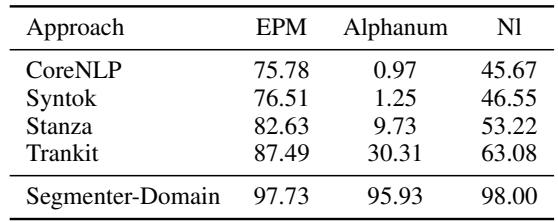
表 3 揭示了这种方法的“杀手级特性”。
- Sentence-EPM (以标点结尾) : 大家在这里都做得不错。
- Sentence-Alphanum (以文本/数字结尾) : 这是一个改变游戏规则的地方。
- CoreNLP: 0.97% 召回率。
- Trankit: 30.31% 召回率。
- Segmenter-Domain: 95.93% 召回率。
因为 Segmenter 使用上下文 (嵌入) 而不是显式规则,它可以识别出句子已经结束,即使作者没有输入句号。它看到了词语中的语义转换。
结论与启示
本文提出的研究为 NLP 的学生和从业者强调了一个重要的教训: 数据决定架构。
为互联网或正式文献构建的工具依赖于某些假设 (如正确的标点符号) ,而这些假设在医疗保健等高风险环境中根本不成立。通过从基于规则的视角转变为序列标注的视角,并利用动态滑动窗口解决长度限制,作者创建了一个符合临床数据混乱现实的系统。
关键要点
- 上下文为王: 标点符号是有用的信号,但不是定义句子的必要条件。深度学习模型可以从语义上下文中推断边界。
- 动态处理: 滑动窗口算法允许基于 BERT 的模型处理真实世界的文档长度,而无需任意地分割句子。
- 领域特异性: 虽然通用工具越来越好,但领域特定的训练 (在实际临床笔记上) 对于医疗应用中的可用性能仍然至关重要。
对于像提取患者症状或自动生成账单代码这样的下游任务,分割上的这种改进决定了一个系统是有效工作还是产生幻觉。随着我们迈向医疗保健领域更多的 AI 集成,像句子分割这样“枯燥”的基础设施任务将成为推动这场革命的无声引擎。