](https://deep-paper.org/en/paper/file-2777/images/cover.png)
LlamaDictionary: 当大语言模型变身动态词典
在自然语言处理 (NLP) 的世界里,我们面临着一点可解释性的问题。当最先进的模型处理一个单词时,它将其转换为向量——代表高维几何空间中该单词的一长串数字。虽然这些向量 (嵌入) 在数学上很强大,但对人类来说却是不透明的。如果你看一个向量,你无法“读出”模型认为这个词是什么意思。
另一方面,我们有词典。它们是人类可解释性的黄金标准。如果你想知道“bank”在特定句子中的意思,词典会给你一个清晰的文本定义。然而,词典是静态的;它们并不总能捕捉到单词在全新语境或创造性隐喻中的细微差别。
如果我们能将两者结合起来呢?如果模型能根据单词在特定句子中的用法,即时生成词典风格的定义呢?关键是,我们能否将这些生成的定义作为一种计算意义的新方法?
这就是论文 “Automatically Generated Definitions and their utility for Modeling Word Meaning” 背后的核心问题。研究人员介绍了 LlamaDictionary , 这是一个微调后的大型语言模型 (LLM) ,旨在生成简洁的义项定义,并证明这些定义可以在复杂的语义任务中达到最先进的结果。
生成式意义的转变
要理解这篇论文的重要性,我们需要回顾一下单词意义建模的历史。
- 静态嵌入 (如 Word2Vec) : 每个词只有一个固定的向量。“Apple” (水果) 和“Apple” (公司) 共享相同的表示。
- 上下文嵌入 (如 BERT) : “Apple”的向量取决于周围的词。这是一个巨大的飞跃,但表示仍然是数字向量——解释向量为什么变化需要复杂的探究。
- 生成式定义 (本方法) : 模型不仅仅生成向量,而是生成文本定义。
研究人员认为,自动生成的定义具有双重优势。首先,它们提取句子中的信息,剥离上下文的噪音以找到核心含义。其次,它们是可解释的。人类可以阅读输出并验证模型是否正确理解了这个词。
方法: 构建 LlamaDictionary
研究人员的方法简单优雅,但执行起来很复杂。他们将此视为文本生成任务。他们采用了两个强大的开源模型——Llama 2 (70亿参数) 和 Llama 3 (80亿参数) ——并对其进行了微调,使其专门扮演词典编纂者的角色。
1. 数据
为了教 LLM 编写定义,你需要高质量的词典。团队使用的数据集来自:
- 牛津英语词典 (The Oxford English Dictionary)
- WordNet
- 维基词典 (Wiktionary)
这些数据集提供包含以下内容的三元组:
- 一个 目标词 (\(w\))。
- 一个 例句 (\(e\)),其中包含该词。
- 一个 定义 (\(d\)),解释该词在句子中的具体含义。
2. 指令微调
模型通过 指令微调 (Instruction Tuning) 进行微调。这涉及向模型输入明确告诉它该做什么的提示词。提示词结构大致如下:
“Please provide a concise definition for the word TARGET in the sentence: EXAMPLE.” (“请为句子: EXAMPLE 中的单词 TARGET 提供简洁的定义。”)
模型被训练输出正确的定义 (\(d\))。由于微调大型模型计算成本高昂,研究人员使用了 LoRA (低秩自适应) , 这是一种冻结主模型权重仅训练少量适配器层的技术。这使得过程更加高效。
3. 流程: 从文本到向量
这是该方法最有趣的地方。生成文本定义只是第一步。为了将其用于计算任务 (比如测量两个词的相似度) ,文本需要转回数学格式。
流程如下:
- 输入: 一个单词及其上下文。
- LlamaDictionary: 生成文本定义。
- SBERT: 一个 Sentence-BERT 模型将该定义编码为向量。
也就是嵌入单词的定义,而不是直接嵌入单词标记 (像标准 Transformer 那样) 。
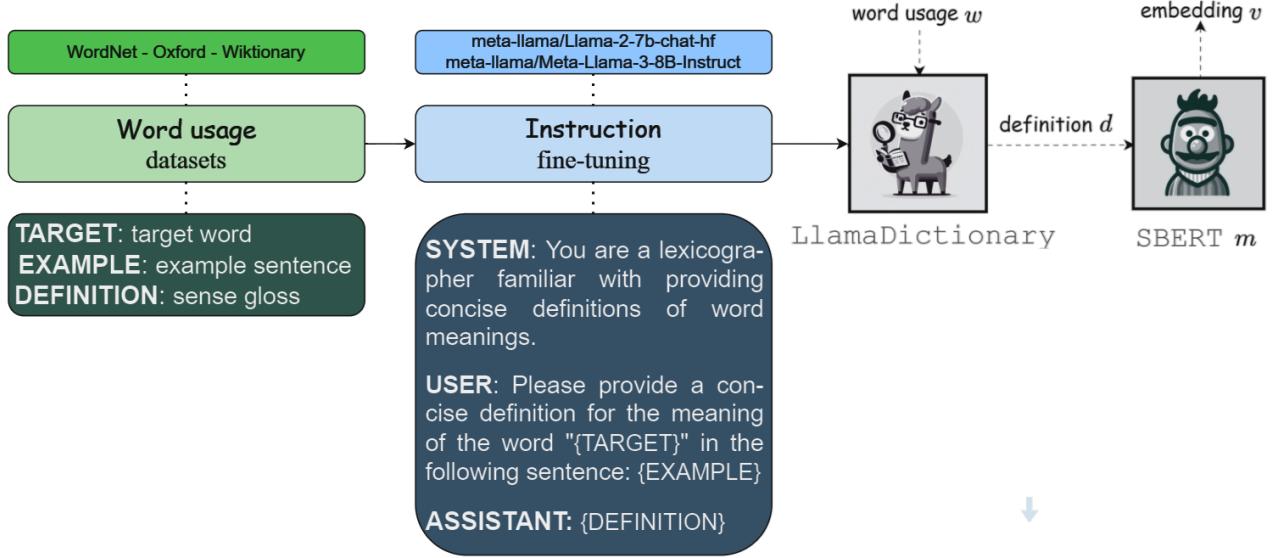
如 图 1 所示,模型获取单词用法 (例如关于食物句子中的“revitalize”) ,生成人类可读的定义 (“Give new life or energy to”/赋予新生命或能量) ,然后将该定义转换为向量 (\(v\))。
实验 1: 它能写出好的定义吗?
第一个评估很简单: LlamaDictionary 能写出好的定义吗?
研究人员在“可见”基准 (训练分布中的数据集,如 Oxford 和 WordNet) 和“不可见”基准 (模型未微调过的数据集,如 Urban Dictionary 和 Wikipedia) 上测试了模型。
他们将 LlamaDictionary 与 Flan-T5-Definition 进行了比较,后者是基于 T5 架构的先前最先进模型。
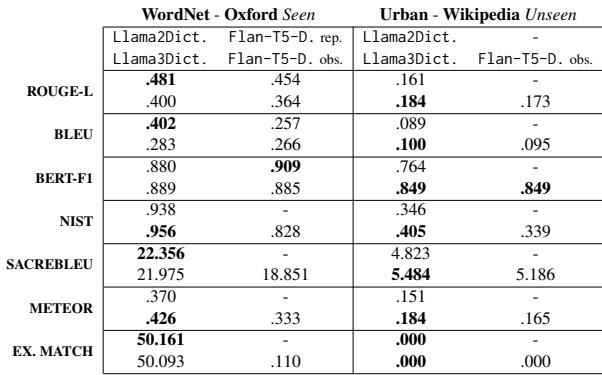
表 6 总结了结果。
- 可见基准 (Seen Benchmarks) : LlamaDictionary (Llama 2 和 3 版本) 在几乎所有指标上都优于基于 T5 的模型,包括 BLEU (词汇重叠) 和 BERT-F1 (语义相似度) 。
- 不可见基准 (Unseen Benchmarks) : 结果很有趣。虽然语义得分 (BERT-F1) 仍然很高,但 Urban Dictionary 的词汇得分有所下降。
为什么在 Urban Dictionary 上表现下降? 研究人员推测“安全微调”是罪魁祸首。Llama 模型经过训练要安全和礼貌。而 Urban Dictionary……并非如此。模型可能拒绝生成真实数据中存在的俚语、冒犯性或高度非正式的定义,导致即使捕捉到了语义,精确匹配得分也会降低。
实验 2: 上下文词义判断 (WiC)
现在进行实用性测试。 上下文词义判断 (WiC) 任务提出一个二元问题: 给定一个词在两个不同句子中的用法,它们的意思是否相同?
句子 A: “He played a nice tune on the piano.”
句子 B: “She hummed a tune.”
答案: True (意思相同)。
句子 A: “The bank of the river.”
句子 B: “I put money in the bank.”
答案: False (意思不同)。
研究人员为两个句子中的目标词生成定义,使用 SBERT 对其进行编码,并计算两个向量之间的余弦相似度。
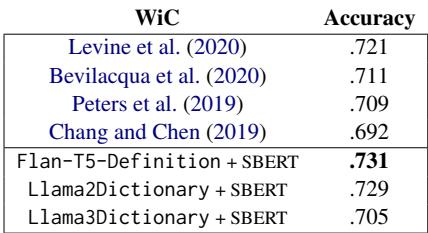
如 表 7 所示,使用生成的定义产生了极好的结果。 Flan-T5-Definition + SBERT 方法达到了 0.731 的新最先进准确率,Llama2Dictionary 以 0.729 紧随其后。这证明生成的定义足够准确地捕捉单词的独特含义,以区分细微的差别。
实验 3: 词汇语义变化 (LSC)
语言是进化的。“Mouse”几个世纪以来一直指一种小型啮齿动物;最近,它开始指一种计算机设备。 词汇语义变化 (LSC) 的任务涉及根据单词在两个时间段内意义变化的程度对单词进行排名。
研究人员使用他们的定义向量测试了两种方法:
- APD (平均成对距离) : 单词在时间段 1 与时间段 2 中所有定义之间的平均距离。
- APDP (原型间平均成对距离) : 首先对定义进行聚类以找到“义项”,然后测量这些义项聚类之间的距离。
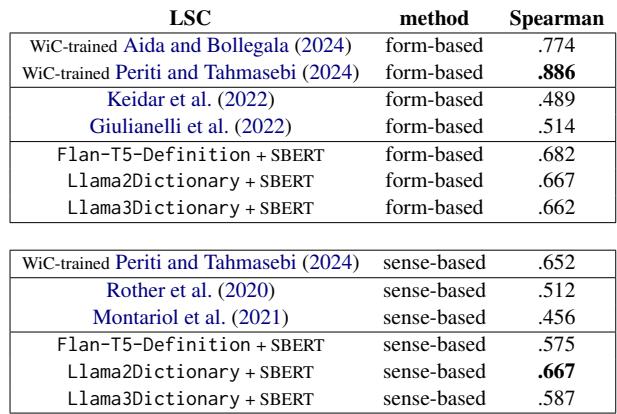
表 8 强调了这些发现。基于定义的方法 (特别是利用 Llama2Dictionary) 在使用聚类方法 (APDP) 时,以 0.667 的相关性为 可解释的、无监督 LSC 检测 设定了新的最先进水平。
他们发现的一个迷人细节与句子长度有关。
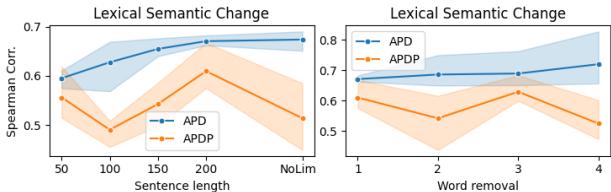
图 3 (左) 显示,当模型能够访问更长的上下文 (最多 200 个字符) 时,表现更好。如果上下文太短,模型难以“幻觉”出精确的定义,从而降低性能。右图显示,从生成的定义中删除“停用词” (短词) 有助于 T5 模型,但对 Llama 模型影响不大,这可能是因为 LlamaDictionary 被训练得更加简洁。
实验 4: 词义归纳 (WSI)
最后是 词义归纳 (WSI) 。 这项任务是自动发现一个词有多少种含义,并将用法示例聚类到这些含义中。例如,给模型 100 个包含“bank”的句子,让它自动将它们分为“金融”堆和“河流”堆。
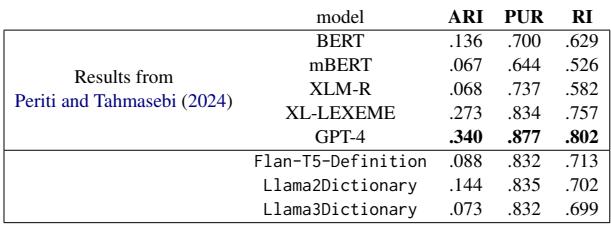
表 9 显示 LlamaDictionary 明显优于 BERT 和 XLM-R 等标准预训练模型。虽然它没有击败 GPT-4 (后者可能在海量训练运行中见过测试数据) ,但它为聚类词义提供了一个极具竞争力的开源替代方案。
结论与启示
这项研究弥合了神经网络“黑盒”与词典可解释性之间的鸿沟。通过微调 Llama 模型生成定义,作者创建了 LlamaDictionary , 这个工具不仅解释了单词在上下文中的含义,而且生成了数学上足够稳健的表示,可以在语义任务中达到最先进的结果。
影响是广泛的:
- 可解释性: 我们可以通过阅读模型生成的定义来验证为什么模型认为两个词是相似的。
- 资源创建: 这项技术可以自动为低资源语言或专业领域 (如医学或法律文本) 生成词典,在这些领域人工编纂词典太昂贵了。
- 语义变化: 它提供了一个更清晰的窗口来了解语言是如何演变的,从抽象的向量转移变为具体的定义变化。
通过教 LLM 像词典编纂者一样行事,我们不仅得到了更好的定义;我们得到了一种更好的语言意义建模方法。