](https://deep-paper.org/en/paper/file-2801/images/cover.png)
引言
在社交媒体时代,自动化内容审核已不仅仅是一种奢侈品,而是一种必需品。各大平台依靠复杂的人工智能模型来过滤有毒言论、骚扰和仇恨言论,以维护网络社区的安全。然而,这些数字安全的守护者自身却存在一个隐形缺陷: 它们往往带有偏见。
设想这样一个场景,用户输入: “我是一个自豪的男同性恋者。”一个有毒内容分类器可能会将其标记为“有毒”或“仇恨言论”。为什么?并不是因为这句话本身带有仇恨,而是因为模型在训练过程中学到了“gay (同性恋) ”这个词与有毒内容之间的虚假相关性。这种现象被称为非预期偏见 (unintended bias) 或假阳性偏见 (false positive bias) 。
解决这种偏见通常涉及昂贵的方案: 从头开始重新训练模型、用数千个新样本增强数据集,或者添加复杂的对抗层。这些方法会消耗大量的计算资源和时间。
但是,如果我们能够“窥探”AI 的大脑内部,精确地找出哪些神经元保留了这些偏见关联,然后简单地……将它们清除掉呢?
这就是 BiasWipe 的前提,这是由印度巴特那理工学院、伦敦国王学院和印度焦特布尔理工学院的研究人员提出的一项新技术。在这篇文章中,我们将探讨 BiasWipe 如何利用模型可解释性,在无需重新训练的情况下,从 Transformer 模型 (如 BERT、RoBERTa 和 GPT) 中外科手术式地消除偏见。
问题的根源: 数据分布
要理解解决方案,我们首先需要了解为什么像 BERT 或 GPT-2 这样的模型会产生这些偏见。答案在于训练数据。
语言模型基于统计数据运行。如果一个特定的人口统计学术语 (如“穆斯林”、“同性恋”或“黑人”) 频繁出现在训练数据的有毒评论中,模型就会开始过度泛化。它会建立一条捷径: 如果这个词出现,那么这句话很可能是有毒的。
研究人员分析了维基百科讨论页 (Wikipedia Talk Pages, WTP) 数据集,这是一个用于有毒内容检测的通用基准。他们发现的统计失衡令人震惊。
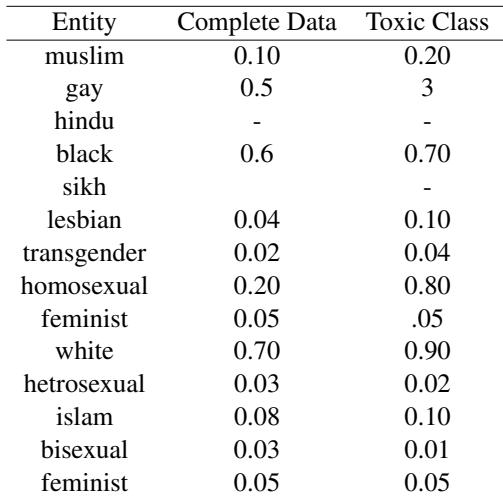
如上表 1 所示,请看实体 “Gay” 。 它仅占完整数据集的 0.5%,但却出现在了 3% 的有毒评论中。同样, “Homosexual” 出现在 0.20% 的有毒评论中,但在整个数据集中却很少见。
由于这种偏差,模型学到“Gay”是有毒内容的强信号,而忽略了上下文。这导致包含这些身份术语的中性或正面句子出现极高的假阳性率 (FPR) 。
测量公平性差距
我们如何量化这种不公平性?研究人员利用从模板数据集中得出的两个特定指标: 假阳性平权差异 (FPED) 和假阴性平权差异 (FNED) 。
在一个理想、公平的世界里,无论提到哪个人口统计群体,模型的错误率都应该是一致的。FPED 衡量的是特定群体的假阳性率与整体平均水平的偏差。
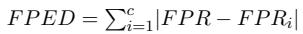
同样,FNED 衡量的是假阴性的偏差 (即模型未能捕捉到针对特定群体的有毒内容) 。
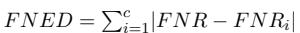
如果这些数字很高,说明模型存在偏见。BiasWipe 的目标是在不破坏模型整体准确性的前提下,将这些数字降至接近零。
介绍 BiasWipe
现有的修复这些指标的方法通常涉及“处理中方法 (In-processing) ” (改变模型的学习方式) 或数据增强。 BiasWipe 采取了一种不同的方法: 通过遗忘进行的后处理 (Post-processing via Unlearning) 。
其核心思想简单而强大:
- 识别: 在预训练模型内部找到导致偏见的特定权重 (神经元) 。
- 剪枝: 将这些权重设为零 (擦除它们) ,有效地让模型“遗忘”这种带有偏见的关联。
至关重要的是,这是在模型训练之后完成的。你不需要重新启动昂贵的训练过程。
方法论: 外科手术式的方法
让我们分解一下 BiasWipe 的架构。该过程利用了反事实 (Counterfactuals) 和 SHAP (Shapley Additive Explanations) , 这是一种流行的博弈论方法,用于解释机器学习模型。
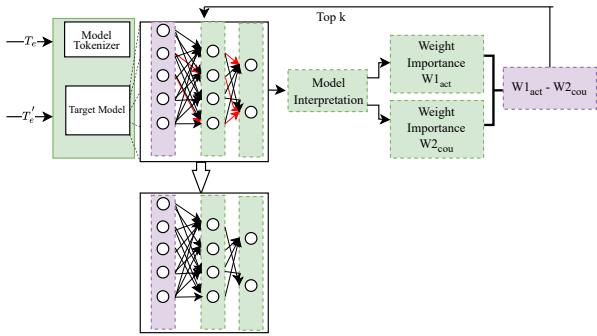
如图 1 所示,该工作流程由三个主要阶段组成:
1. 反事实数据集
为了发现偏见,研究人员首先创建了一个“模板数据集”。这些是一对除了人口统计学术语是否存在外完全相同的句子。
- 实际 (\(T_{act}\)): “Abdul is a fantastic gay.” (包含实体)
- 反事实 (\(T_{cou}\)): “Abdul is a fantastic.” (实体被移除)
如果模型预测第一句话是“有毒的”,但预测第二句话是“无毒的”,我们就知道“gay”这个词触发了偏见。
2. 层层剥离: Transformer 神经元
Transformer 模型堆叠了包含自注意力机制和前馈网络 (FFN) 的层。研究人员专注于 FFN,因为这些层通常编码特定的模式和概念。
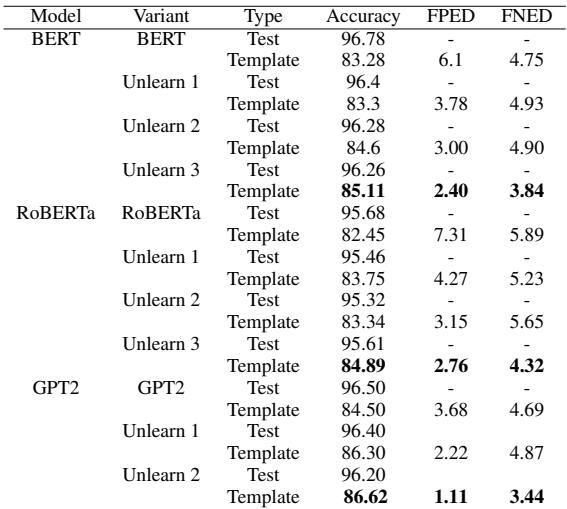
从数学上讲,Transformer 层中的 FFN 如下所示:
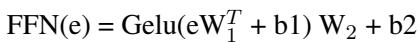
这里,\(W_1\) 和 \(W_2\) 是权重矩阵。这些权重决定了模型如何处理信息。BiasWipe 旨在找出 \(W_1\) 和 \(W_2\) 中哪些特定值导致了“Gay = 有毒”的判定。
3. SHAP 和权重剪枝
这是算法的核心。研究人员应用 SHAP 来计算每个神经元权重对给定预测的重要性评分 。
他们计算两组重要性评分:
- \(W1_{act}\) : 处理包含人口统计学术语的句子时的权重重要性。
- \(W2_{cou}\) : 处理不含人口统计学术语的句子时的权重重要性。
通过相减这两个矩阵 (\(W1_{act} - W2_{cou}\)) ,他们分离出了那些对人口统计学术语的存在有特定反应的权重。
差异最大的权重就是罪魁祸首。这些就是导致非预期偏见的神经元。BiasWipe 随后执行剪枝 : 它选择前 \(k\) 个偏见最严重的权重并将它们设为零。这有效地切断了身份术语与有毒分类之间的联系。
实验结果
这种外科手术式的程序真的有效吗?研究人员使用维基百科讨论页数据集,在三个主要语言模型上测试了 BiasWipe: BERT、RoBERTa 和 GPT-2 。
遗忘前的偏见可视化
首先,让我们看看在应用 BiasWipe 之前,模型的偏见有多严重。
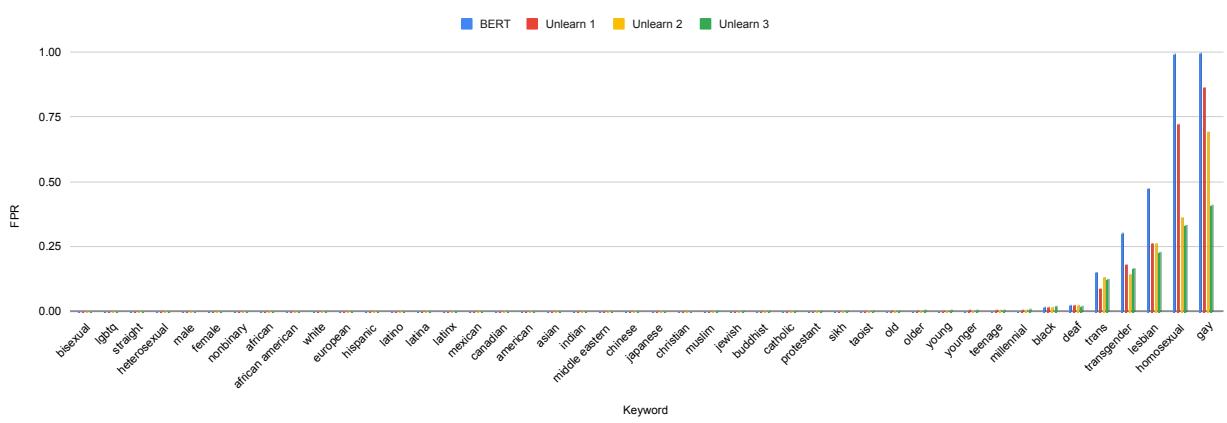
图 2 显示了 BERT 的假阳性率 (FPR) 。请看代表“Gay”、“Homosexual”和“Lesbian”的蓝色柱状条。它们非常高,意味着模型几乎总是认为包含这些词的句子是有毒的。
我们在 GPT-2 上看到了类似但略有不同的模式:
在图 3 (蓝色柱状条) 中,GPT-2 对“Gay”和“Homosexual”实体表现出严重的偏见,FPR 接近 1.0 (100% 假阳性) 。
“遗忘”效应
研究人员分步骤应用 BiasWipe (“Unlearn 1”,“Unlearn 2”等) ,逐一针对不同的偏见实体。
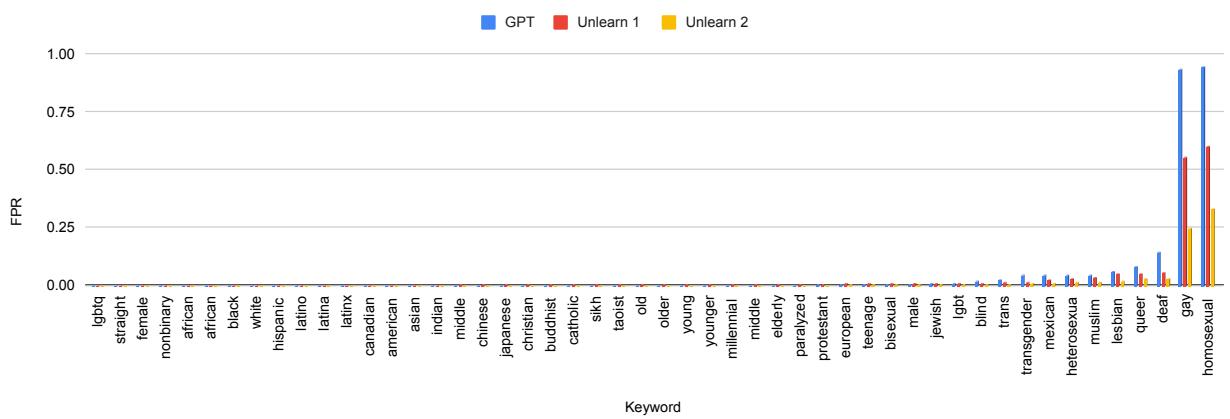
下表 2 总结了结果,令人印象深刻。
让我们分析该表中的 BERT 部分:
- 原始模型: FPED (偏见指标) 为 6.1 。 模板集上的准确率为 83.28% 。
- Unlearn 3 之后: FPED 显著下降至 2.40 。
- 准确率: 关键是,测试准确率保持稳定 (从 96.78% 到 96.26%) 。
这证实了 BiasWipe 成功减少了偏见 (降低了 FPED) ,且没有破坏模型检测实际有毒内容的能力 (稳定的测试准确率) 。
我们应该剪枝多少权重? (消融研究)
有人可能会问: 为什么不剪枝所有权重?或者为什么停在 10 或 100 个?
剪枝是一种平衡行为。如果你剪枝太少的权重,偏见依然存在。如果你剪枝太多,就会开始破坏模型的通用知识,导致准确率下降或假阴性增加。
研究人员进行了消融研究以寻找“最佳平衡点”。
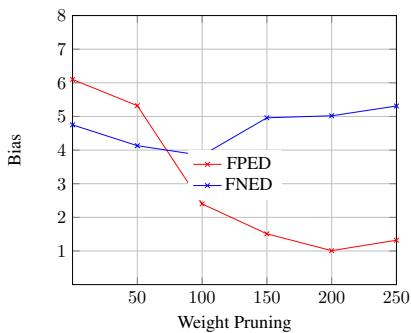
在图 4 中,我们看到了剪枝数量对 BERT 偏见指标的影响。
- X 轴: 剪枝权重的数量。
- 红线 (FPED): 随着我们剪枝更多权重 (向右移动) ,偏见急剧下降。
- 蓝线 (FNED): 如果我们走得太远 (超过 100-150) ,假阴性率开始攀升。
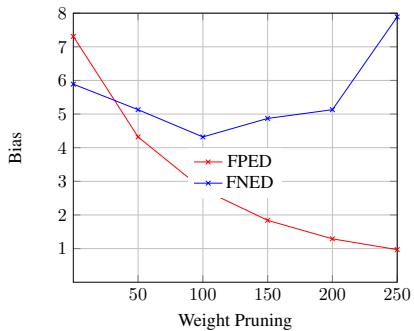
图 5 展示了 RoBERTa 的相同情况。趋势表明,剪枝大约 100 个权重 通常是最小化偏见同时保持模型稳定性的最佳策略。
我们还可以看看对整体准确率的影响:
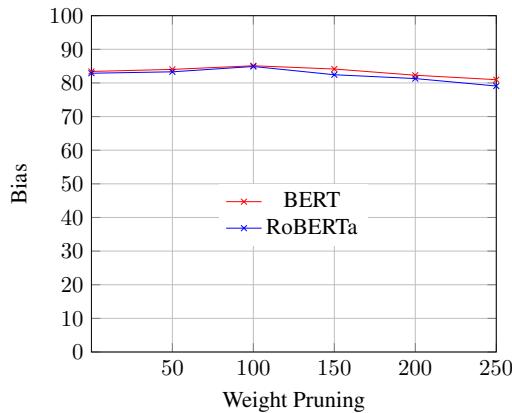
图 6 证实,在剪枝大约 100 个权重之前,准确率保持相对稳定。超过这个数值,外科手术式的切除变得过于激进,病人 (模型) 开始遭受性能退化。
定性分析: 观察转变
为了证明模型的“推理”实际上发生了变化,研究人员使用 SHAP 提取了模型在 BiasWipe 程序前后关注的关键词。
考虑这句话: “Abdul is a fantastic gay.”
- 原始 BERT: 严重关注 “gay” 一词并预测为 有毒 。
- BiasWipe BERT: 转移关注点到 “fantastic” 一词并预测为 无毒 。
这种定性转变证明,模型不再依赖身份术语作为有毒信号,而是开始关注实际带有情感色彩的形容词。
结论
BiasWipe 代表了在追求公平 AI 道路上迈出的重要一步。它解决非预期偏见这一顽疾的方法,不是通过使用海量新数据集重新训练模型,而是通过解释和修改模型的内部表示。
这项研究的关键要点是:
- 效率: BiasWipe 是一种后处理技术。它节省了重新训练大型语言模型所带来的巨大环境和财务成本。
- 精确性: 通过使用 Shapley 值,它只针对导致偏见的特定神经元,保留了模型其余的知识。
- 通用性: 该方法在不同的架构 (BERT、RoBERTa、GPT-2) 上都被证明有效,表明它可以成为 Transformer 去偏的通用工具。
随着 AI 模型的规模和复杂性不断增长,像 BiasWipe 这样的“外科手术式”技术可能会成为开发者工具箱中的标准工具,确保我们的自动化系统在保护用户的同时也保护边缘群体的声音。未来的工作旨在将这种方法扩展到多语言和代码混合环境,确保不同语言和文化背景下的公平性。