](https://deep-paper.org/en/paper/file-2802/images/cover.png)
引言
生物医学文献的发表速度惊人。每天都有成千上万篇新论文发布,详细介绍最新的药物相互作用、基因发现和疾病机制。对于研究人员和临床医生来说,跟上这股信息洪流几乎是不可能的。然而,隐藏在这些非结构化文本中的,正是通往新疗法和治愈方法的关键。
为了管理这些信息,我们依赖信息提取 (Information Extraction, IE) 技术——使用 AI 自动解析文本并将其转化为结构化数据库。这通常涉及两个步骤: 命名实体识别 (NER) (识别独特的项目,如“阿司匹林”或“TP53”) 和关系提取 (RE) (确定它们如何相互作用,例如“阿司匹林抑制 TP53”) 。
然而,解析生物医学文本众所周知地困难。它充满了歧义术语、嵌套名称和复杂的句子结构。传统的 AI 模型在这里往往难以奏效,特别是在缺乏足够标注训练数据的情况下。
在这篇文章中,我们将深入探讨由清华大学和哈佛大学的研究人员提出的一个迷人的解决方案: Bio-RFX (生物医学关系优先提取) 。 该模型通过先识别关系以更好地理解实体,从而颠覆了传统的提取方法,即使在低资源场景下也能取得最先进的结果。
生物医学文本的挑战
在理解解决方案之前,我们必须先认识到问题的所在。通用领域的 NLP 模型 (如用于新闻或维基百科的模型) 应用在生物医学领域时,往往会彻底失败。为什么呢?
1. 歧义性
在普通英语中,“Apple”通常指一种水果或一家公司。而在生物学中,同一个缩写根据上下文的不同,可能意味着完全不同的事物。
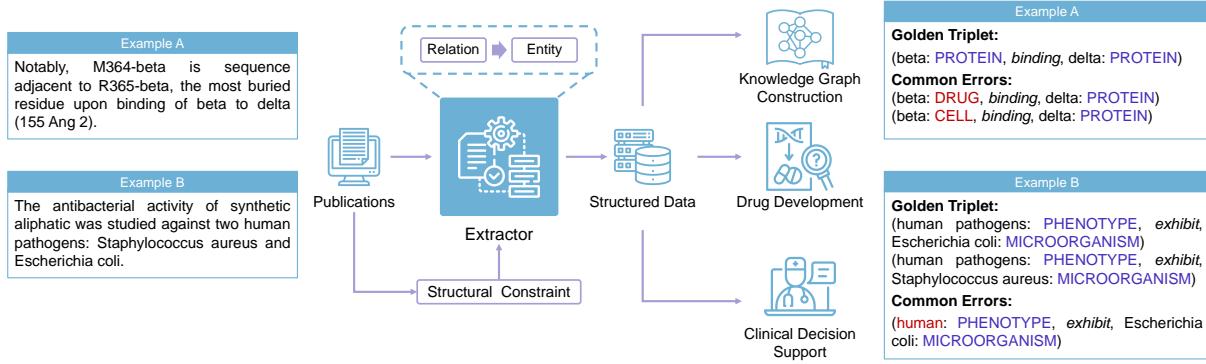
请看下面的 图 1 。 在示例 A 中,术语“beta”和“delta”极其模糊。它们可能是细胞类型、药物或蛋白质。然而,句子提到了结合 (binding) 关系。如果我们知道它们在结合,就可以推断它们很可能是蛋白质。那些试图在理解关系之前识别实体的传统模型,通常会错误分类这些术语。
2. 嵌套和重叠的实体
生物医学名称通常很长且具有描述性。看图 1 中的示例 B。“Human” (人类) 是一个实体。“Human pathogen” (人类病原体) 是另一个实体。“Staphylococcus aureus” (金黄色葡萄球菌) 是第三个。模型需要足够智能,能够提取“human pathogen”作为句子的主语,而不是仅仅提取“human”,同时在无关紧要时忽略这种重叠。
3. 低资源瓶颈
深度学习模型极其依赖数据。它们通常需要数千个手工标注的句子来学习模式。在生物医学领域,标注数据需要博士级别的专家,这使得过程昂贵且缓慢。我们需要能够从仅仅几百个示例中有效学习的模型。
Bio-RFX 方法: 关系优先
大多数提取系统遵循“流水线”方法: 先找到实体,再寻找关系。如果模型未能正确找到实体 (例如,将基因误认为是药物) ,关系提取步骤就毫无成功的机会。
Bio-RFX 提出了一种不同的理念: 关系优先 (Relation-First) 。
其假设很简单: 句子中表达的关系通常比实体的具体边界更容易检测,而且知道关系为何种类型,能为实体是什么提供强有力的线索。
该框架分四个不同的阶段运行,利用一个称为“结构约束 (Structural Constraints) ”的概念来指导 AI。
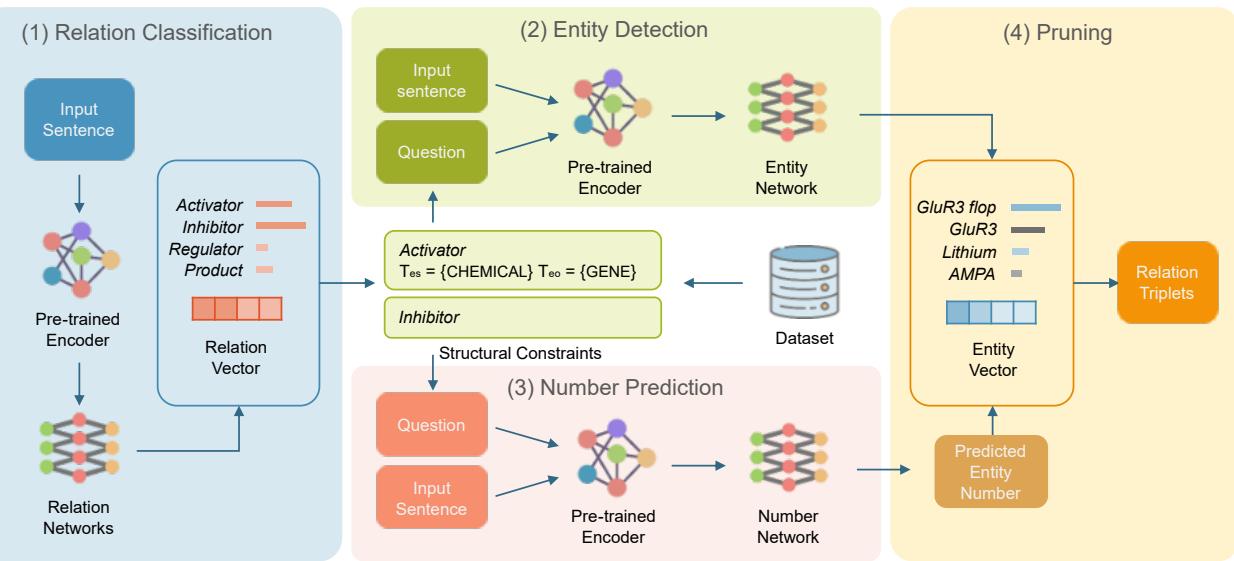
让我们拆解图 2 中展示的架构。
第 1 步: 关系分类
Bio-RFX 不是立即寻找单词,而是首先阅读整个句子以确定存在哪种类型的相互作用。它使用预训练的语言模型 (SciBERT) 来创建句子的向量表示。
然后它执行多标签分类。例如,它可能会看一个句子并得出结论: “这个句子包含一个*激活剂 (Activator) 关系和一个抑制剂 (Inhibitor) *关系。”
这是使用标准的交叉熵损失函数进行训练的:
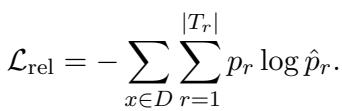
通过首先在句子层面检测关系,模型过滤掉了不可能的关系类型,缩小了后续步骤的搜索空间。
第 2 步: 特定于关系的实体提取
一旦模型知道存在“激活剂”关系,它就会切换到问答 (QA) 模式来寻找实体。
这是对自然语言处理的一种巧妙运用。模型不是进行通用的标记,而是根据第 1 步中发现的关系构建一个查询。
- 标准 NER: “找到所有化学物质。”
- Bio-RFX RE: “这种化学物质激活了什么基因?”
注意到这种特异性了吗?这就是结构约束发挥作用的地方。模型利用先验知识,即“激活”相互作用通常发生在化学物质 (主语) 和基因 (宾语) 之间。对于这种特定关系,它不会浪费时间去寻找疾病或细胞系。
模型使用注意力机制为文本的不同跨度 (spans) 分配分数,以查看它们是否回答了这个问题:
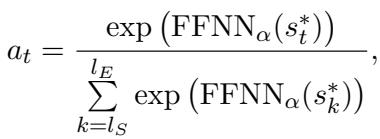
它通过结合起始 token、结束 token 和宽度嵌入 (短语有多长) 来生成潜在实体跨度 (\(s\)) 的表示:
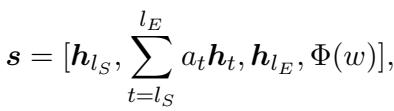
然后训练模型最小化识别特定关系下的特定跨度时的误差:
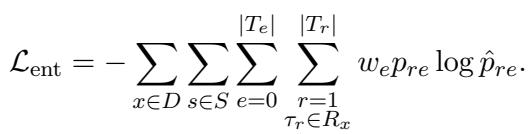
第 3 步: 数量预测
提取中的一个常见问题是知道要寻找多少个实体。句子提到了两种药物吗?还是五种?
Bio-RFX 包含一个专用模块,用于预测与关系相关联的实体数量 (\(k\)) 。它将其视为一个回归问题。如果基准真值 (ground truth) 说是 2 种化学物质,而模型预测是 5 种,它会通过以下损失函数进行调整:
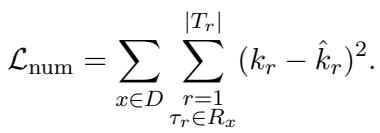
第 4 步: 使用 Text-NMS 进行修剪
最后,模型需要清理结果。因为生物医学术语经常相互嵌套 (例如,“肺癌”嵌套在“非小细胞肺癌”中) ,模型可能会建议重叠的跨度。
Bio-RFX 使用文本非极大值抑制 (Textual Non-Maximum Suppression, Text-NMS) 算法。它获取预测的实体数量 (来自第 3 步) ,并选择与该计数匹配的最佳、非重叠跨度,丢弃冗余或置信度较低的猜测。
实验结果
研究人员将 Bio-RFX 与几个强大的基线模型进行了对比,包括:
- PURE 和 PL-Marker: 强大的流水线模型。
- KECI: 使用外部知识库的基于图的模型。
- GPT-4: 在少样本 (few-shot) 设置下进行测试。
他们使用了四个基准数据集: DrugProt, DrugVar, BC5CDR 和 CRAFT 。
标准数据集上的表现
如 表 1 所示,Bio-RFX 在所有数据集中取得了最佳的平均排名。它始终优于以前的最先进模型。
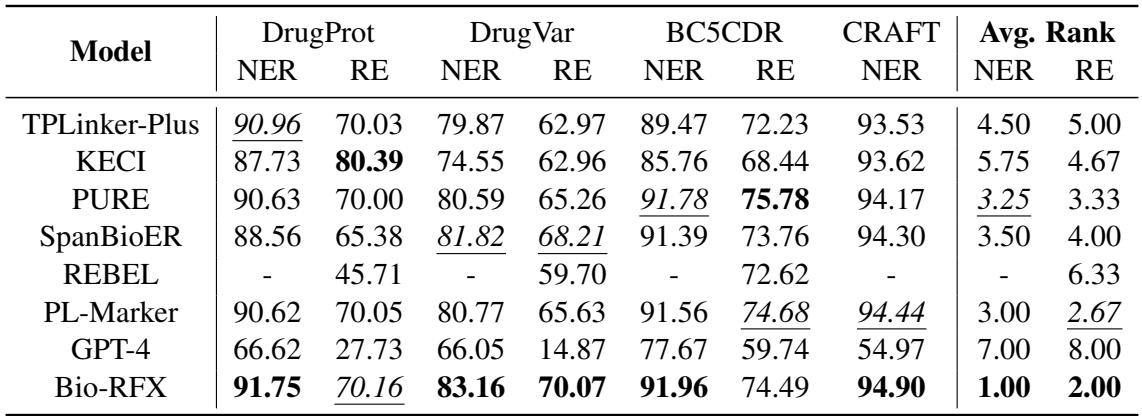
值得注意的是,像 KECI 这样的模型虽然在关系提取 (RE) 方面表现良好,但在命名实体识别 (NER) 方面往往很吃力。Bio-RFX 被证明是一个平衡的执行者,在两方面都表现出色。有趣的是, GPT-4 明显落后。虽然大型语言模型令人印象深刻,但在需要高精度和领域特定结构理解的任务中,像 Bio-RFX 这样的专用微调模型仍然占据主导地位。
“低资源”下的胜利
最令人印象深刻的结果来自低资源实验。研究人员创建了数据集的较小版本,仅使用一小部分训练数据 (例如,仅 200 或 500 个句子) 。
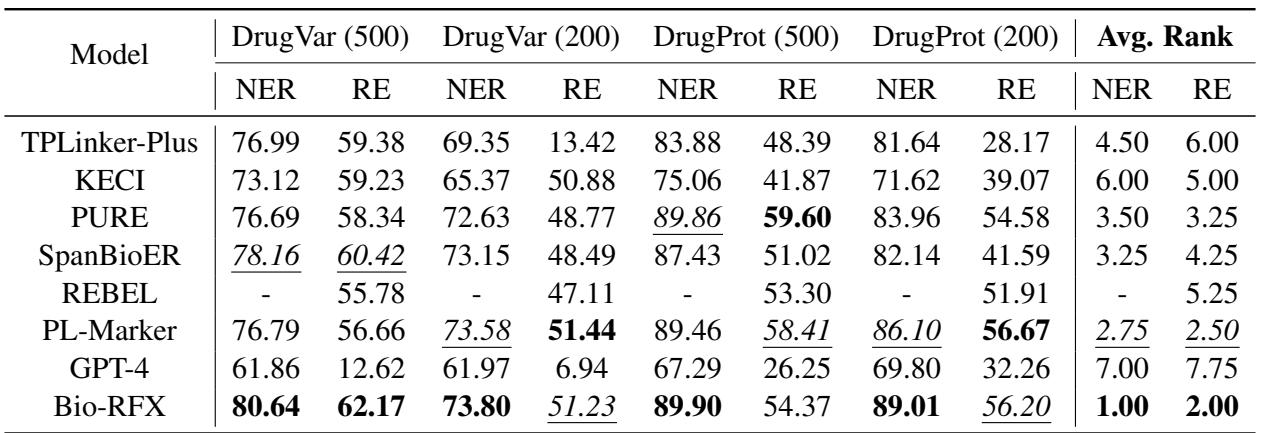
在这些数据稀缺的场景下 (表 2) ,Bio-RFX 的架构最为耀眼。
- 稳定性: 复杂的联合模型 (如 TPLinker) 在数据很少的情况下崩溃了,因为它们的标记方案太复杂而无法学习。
- 独立性: 因为 Bio-RFX 拆分了任务 (关系预测 -> 实体提取) ,单独的模块比一个巨大的网络更容易训练。
- 约束: 通过强制执行“化学物质激活基因”等规则,模型不需要从头开始学习这些规则——它是受结构引导的,这节省了数据需求。
消融实验: 约束重要吗?
为了证明他们的设计选择是有效的,作者进行了一项“消融实验 (ablation study) ”——移除模型的部分组件以观察什么会失效。
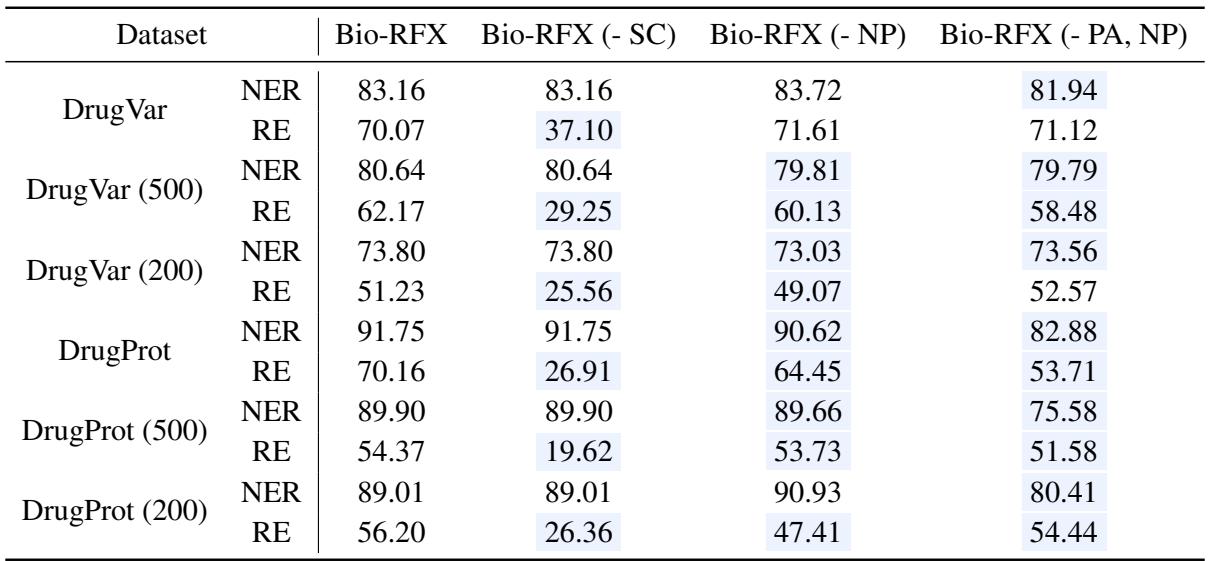
在 表 3 中,“Bio-RFX (- SC)”代表没有结构约束的模型。你可以看到关系提取 (RE) 性能大幅下降 (例如,在 DrugVar 上从 70.07% 降至 37.10%) 。这证实了基于关系类型约束搜索空间是该方法的“秘诀”。
处理歧义: 案例研究
最后,让我们看一个定性的例子,看看 Bio-RFX 如何处理我们在引言中讨论的歧义。

在 案例 A (图 3) 中,术语“Abeta”很棘手。它可以是一种化学肽,也可以是一种蛋白质产物。然而,句子讨论的是“形成 (formation) ”。在 DrugProt 数据集的背景下,模型根据关系约束正确地识别了它。
在 案例 B 中,“血管紧张素 II (angiotensin II) ”在结构上是一种肽 (化学物质) ,但在描述的相互作用背景下起着信号蛋白的作用。模型正确地将其识别为 GENE/PROTEIN (基因/蛋白质) , 与基准真值相符,而其他模型可能会因其化学性质而感到困惑。
结论与启示
Bio-RFX 代表了自动化生物医学研究向前迈出的重要一步。通过优先考虑关系 , 该模型模仿了专家的阅读方式: 我们通过寻找相互作用来理解参与者。
这项研究的主要收获是:
- 上下文为王: 首先预测关系提供了解决实体歧义的基本上下文。
- 约束至关重要: 硬编码结构规则 (例如,允许的主语-宾语对) 大大减少了搜索空间,使模型能够在更少数据的情况下更快地学习。
- 分而治之: 将巨大的提取任务分解为更小的模块化子任务 (分类 -> 问答 -> 修剪) ,创建了一个稳健且稳定的系统,即使在标注数据稀缺的情况下也是如此。
随着生物医学数据的持续增长,像 Bio-RFX 这样的工具对于将原始文本转化为结构化知识图谱、加速药物发现和临床决策支持系统将至关重要。虽然 GPT-4 和生成式 AI 占据了头条新闻,但高度专业化、结构受限的架构仍然是精密科学的黄金标准。