](https://deep-paper.org/en/paper/file-2803/images/cover.png)
引言
在当前的自然语言处理 (NLP) 领域,Transformer 架构占据着统治地位。从 ChatGPT 到 Llama,自注意力机制 (Self-attention) 解锁了惊人的生成与推理能力。然而,这种能力伴随着巨大的计算成本。注意力机制随序列长度呈二次方增长,且键值 (KV) 缓存呈线性增长,这使得处理海量上下文在训练和部署时的成本日益昂贵。
这种扩展瓶颈重新点燃了人们对高效替代方案的兴趣,特别是 状态空间模型 (State Space Models, SSMs) 。 像 Mamba、S4 和 Hawk 这样的模型承诺了序列建模的“圣杯”: 线性扩展以及允许恒定成本推理的固定大小状态。理论上,它们是长上下文应用的完美解决方案。
然而,这里有个陷阱。虽然 SSM 高效,但它们历来在 上下文内检索 (in-context retrieval) 方面表现挣扎。如果你让 Transformer 查找 10,000 个 token 前提到的电话号码,它只需“回头看”那个确切的 token 即可。相反,SSM 必须依赖其压缩后的固定状态。如果该特定信息在传递过程中未被视为足够重要以压缩进状态,它就永远丢失了。
大多数解决此问题的尝试都集中在架构变更上,例如添加混合注意力层。在论文 “Birdie: Advancing State Space Language Modeling with Dynamic Mixtures of Training Objectives” 中,来自乔治梅森大学、斯坦福大学和 Liquid AI 的研究人员提出了不同的假设。他们认为问题不仅仅在于架构——而在训练。通过超越标准的“下一个 token 预测”并使用一种名为 Birdie 的新颖训练程序,他们证明了 SSM 可以被教会更有效地利用其固定状态,从而在检索密集型任务上显著缩小与 Transformer 的性能差距。
背景: SSM 的瓶颈
要理解为什么检索对 SSM 来说很难,我们必须看看它们如何处理数据。与保留所有先前 token 历史记录 (KV 缓存) 的 Transformer 不同,SSM 依赖于循环更新规则。在任何时间步 \(k\),模型根据前一个状态和当前输入 \(\mathbf{x}_k\) 更新隐藏状态 \(\mathbf{h}_k\)。
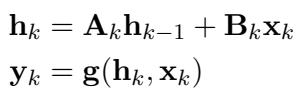
如上式所示,状态 \(\mathbf{h}_k\) 是模型对过去拥有的唯一记忆。这就产生了一个“瓶颈”。随着序列长度的增加,模型必须决定保留什么信息以及丢弃 (或“遗忘”) 什么信息,以便将所有内容装入这个固定大小的向量中。
大多数 SSM 使用 因果语言建模 (Causal Language Modeling, CLM) 进行训练,通常称为下一个 token 预测。研究人员认为,CLM 不足以训练 SSM 管理这种记忆瓶颈。在许多情况下,预测下一个词只需要局部上下文 (前几个词) ,这意味着模型很少因为未能记住长期依赖关系而受到惩罚。因此,模型从未学会有效地压缩和检索遥远的信息。
Birdie 方法
这篇论文的核心贡献是 Birdie , 一种旨在强制 SSM 最大化利用其固定状态的新预训练程序。Birdie 依赖于三个方法论支柱: 双向处理、新的预训练目标以及通过强化学习实现的动态混合 。
1. 双向处理
标准的 SSM 严格从左到右 (因果地) 处理文本。这对于生成文本是必要的,但在处理提示词 (前缀) 期间,整个上下文是可用的。Transformer 通常通过“前缀语言建模”利用这一点,允许模型一次性“看到”整个提示词。
Birdie 引入了一种 SSM 双向架构 。 其想法是在正向和反向两个方向上处理上下文,使模型能够捕获单次传递中可能遗漏的依赖关系。然而,要在之后保持因果生成文本的能力,需要巧妙的架构拆分。

如上图所示,状态被分为正向 (\(\mathbf{h}^{\text{forward}}\)) 和反向 (\(\mathbf{h}^{\text{rev}}\)) 分量。至关重要的是,研究人员在因果 (生成) 区域屏蔽了动力学,以确保来自未来的信息在生成阶段不会泄露到过去。这使得模型能够利用双向信息构建强大的提示词表示,然后无缝切换到因果生成。
2. 多样化的预训练目标
如果 CLM 太“简单”,无法强制有效地利用状态,那么解决方案就是让训练变得更难。Birdie 利用混合目标旨在对模型的记忆能力进行压力测试。

上表概述了所使用的目标:
- 全片段破坏 (Full Span Corruption, FSC) : 类似于 BERT 的掩码 (masking) ,但模型必须生成 整个 序列,而不仅仅是缺失的部分。这迫使模型在生成新文本的同时复制上下文。
- 去乱序 (Deshuffling) : 模型接收打乱的序列,必须重建原始顺序。由于局部语法被打乱破坏,模型无法依赖局部提示,必须使用其全局状态来理解词语关系。
- 复制 (Copying) : 简单地复现输入。
- 选择性复制 (Selective Copying) : 一项新颖的任务,模型必须在上下文中找到特定的片段 (由开始/结束 token 标记) 并复制它们。这模仿了像在数据库中查找特定条目这样的检索任务。
3. 通过强化学习实现的动态混合
有了这么多潜在的目标,一个新的问题出现了: 模型应该在每个任务上花费多少时间?固定比例 (例如,50% CLM,50% 复制) 在整个训练过程中很少是最佳的。
Birdie 使用由强化学习 (RL) 驱动的 多臂老虎机 (Multi-Armed Bandit) 方法来解决这个问题。一个“评价器 (critic) ”模型 (一个小型的 Gated SSM) 预测哪个目标在当前的训练阶段会产生最高的回报 (损失的改善) 。
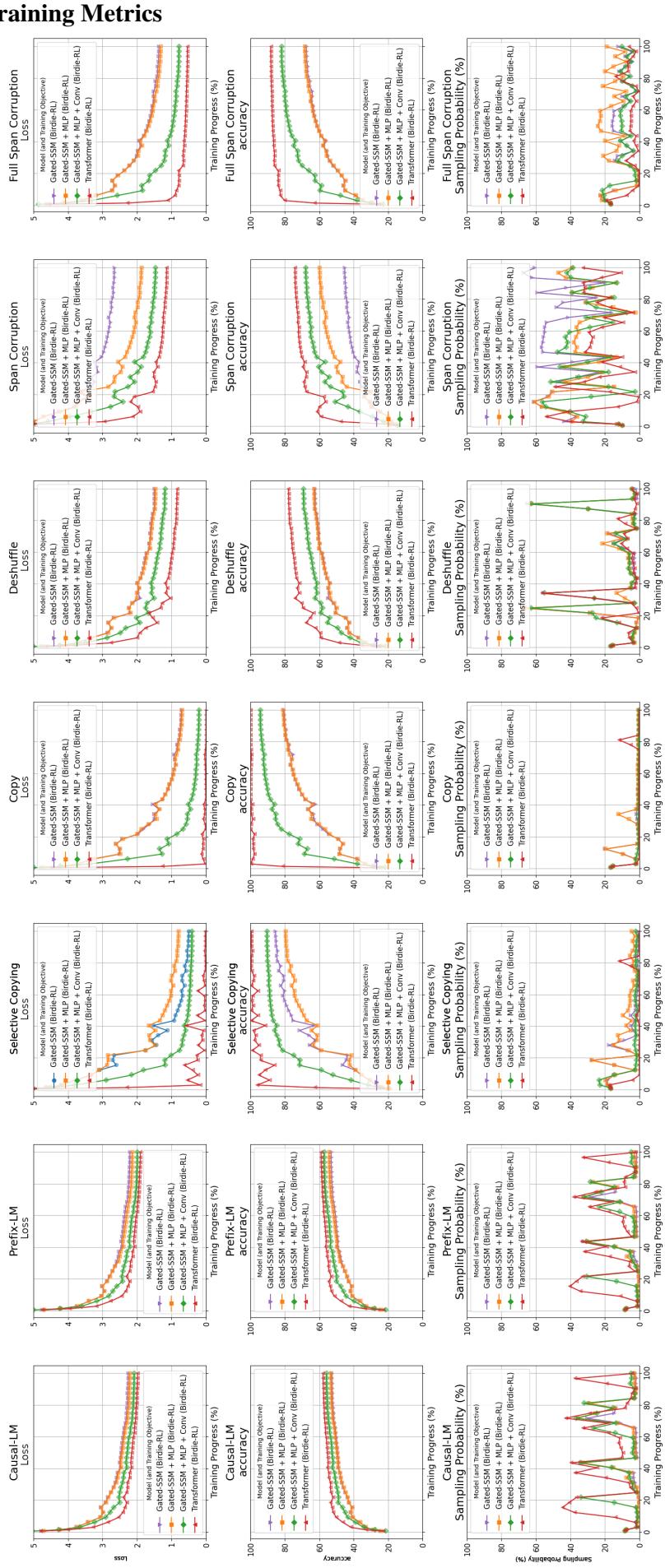
上面的可视化展示了这个动态过程。最下面一行 (“Sampling Probability”,采样概率) 特别有趣。我们可以看到模型动态地调整其关注点。例如,随着模型掌握了技能,“复制”任务的采样可能会减少,而其他任务则会增加。这种自动化课程允许模型专注于它在任何给定时间最需要学习的内容,避免了手动调整超参数的需求。
4. Gated SSM 基线
为了证明收益来自 训练 而不仅仅是特定的模型,作者在一个通用的 Gated SSM 基线上测试了 Birdie。该模型结合了线性循环和类似于 Mamba 或 LSTM 的门控机制。

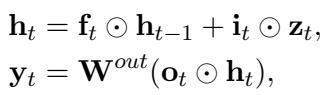
这种架构 (Gated SSM+) 包括一个 MLP 块和一个用于处理输入的短 1D 卷积,提供了一个与 Hawk 等最先进模型相当的强大基线。
实验与结果
研究人员将 Birdie 训练的模型与标准 CLM 训练的模型 (包括 Transformer、Hawk 和 Gated SSM) 在各种基准上进行了比较。
1. 通用性能 (“无害”测试)
第一个问题是,这些专门的目标是否会损害模型理解语言的通用能力。作者在 EleutherAI LM Harness 上评估了模型,这是一套包含 21 个标准 NLP 任务 (如 ARC、MMLU 和 BoolQ) 的套件。
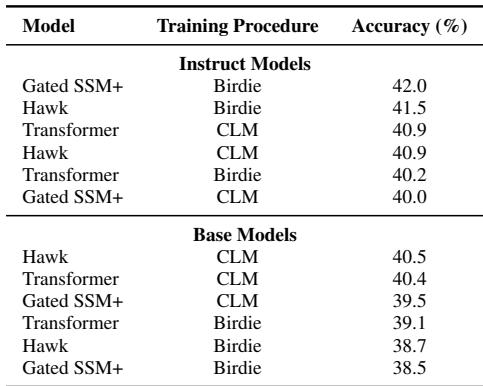
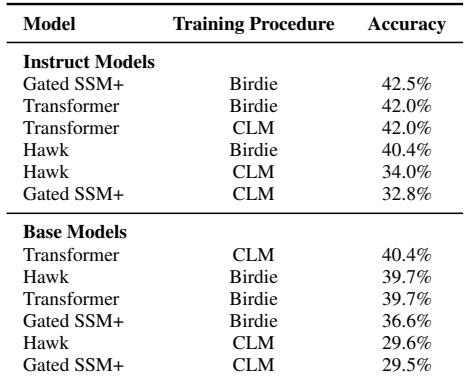
结果 (表 2) 表明,Birdie 训练的模型表现与 CLM 对应模型相当。这证实了专门的训练在 不 牺牲通用推理或语言理解能力的情况下提高了检索能力。
2. 电话簿检索测试
这是压力测试。模型会被给予一本包含生成姓名和号码的“电话簿”,随后是一个询问特定人电话号码的查询。这是纯粹的检索——没有推理,只有记忆。
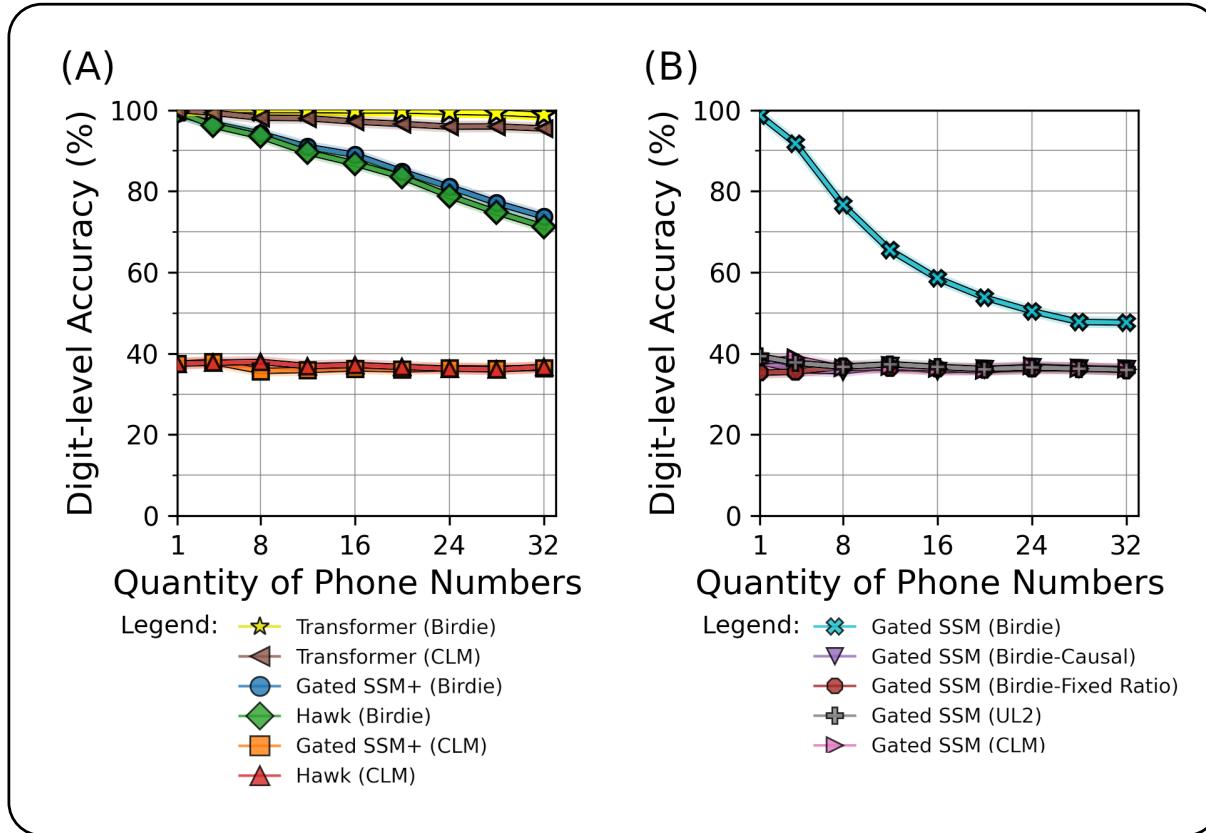
图 1 (上图) 讲述了一个令人信服的故事。
- 图表 A: 看看 Transformer (黄色/棕色) 与标准 SSM (橙色/红色) 之间的差距。标准 SSM 几乎立即就失败了。然而, Birdie 训练的 SSM (蓝色/绿色) 显著缩小了这一差距。虽然随着检索数量的增加它们的性能仍然会下降,但它们保持高准确率的时间远长于标准版本。
- 图表 B: 这项消融研究表明,仅靠双向处理 (Birdie-Causal) 或固定比例 (UL2) 是不够的。需要完整的 Birdie 方案 (青色) 才能实现高准确率。
3. 长篇问答 (SQuAD)
转向更现实的任务,作者使用了 SQuAD 数据集,该数据集涉及根据一段文本回答问题。
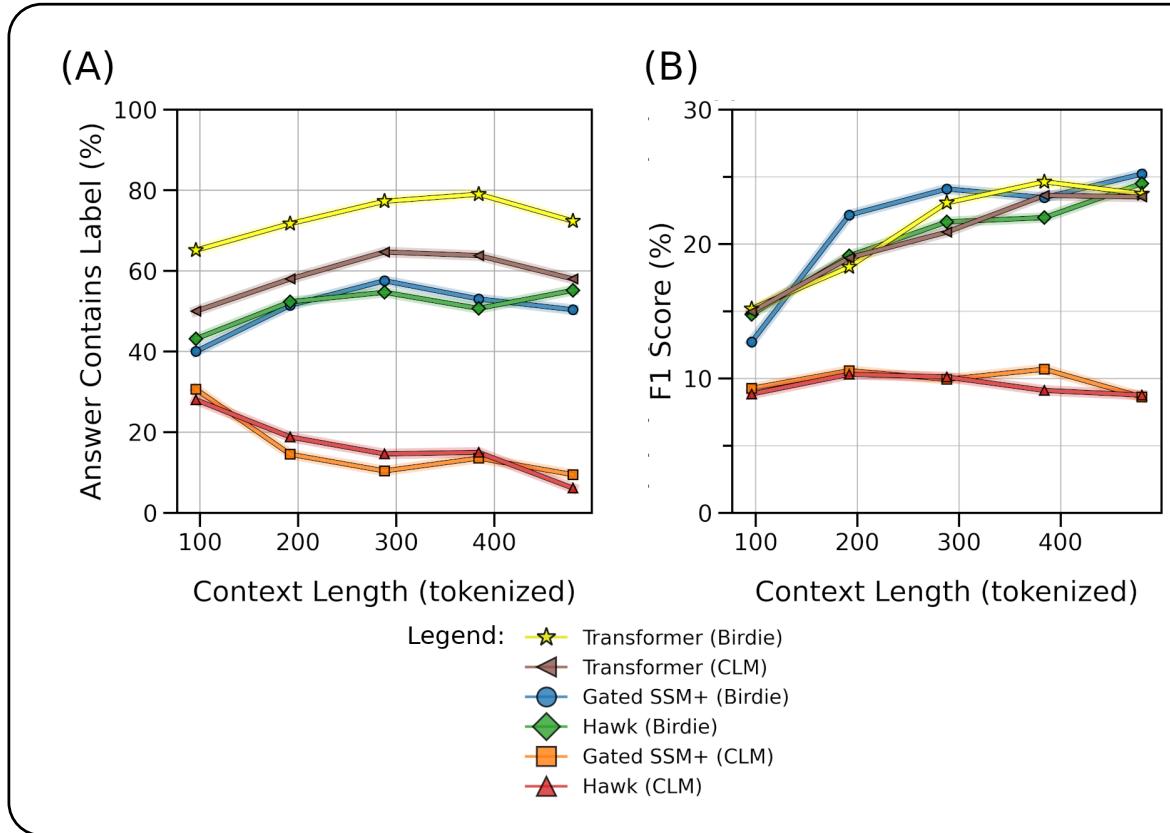
如图表 A (Answer Contains Label,答案包含标签) 所示,标准 CLM 训练的 SSM (橙色/红色) 随着上下文长度的增加迅速退化。如果段落太长,它们简直就是“忘记”了答案。相比之下, Birdie 训练的 SSM (蓝色/绿色) 保持了与 Transformer 媲美的性能曲线,即使在更长的上下文长度下也是如此。
4. 故事填充
最后,作者引入了一个新的“填充 (Infilling) ”数据集。模型阅读一个有缺失部分的故事,必须从多个选项中选择正确的文本来填补空白。这需要理解完整的上下文——包括空白之前和之后的内容。
同样,Birdie 训练的模型优于 CLM 基线。下面是该数据集的一个简短条目示例,用以说明任务:

以及一个需要更深层上下文的较长条目:

结论
“Birdie” 论文为高效语言模型的开发提供了关键的见解。长期以来,人们一直假设如果状态空间模型无法检索信息,那是架构的错。这项工作翻转了这种叙事,表明 我们如何教导 模型与其结构同样重要。
通过强迫 SSM 解决诸如去乱序和片段破坏等困难任务——并允许它们双向查看提示词——Birdie 教会了模型将信息更智能地压缩到其固定状态中。
虽然在检索任务的极端情况下与 Transformer 仍存在性能差距,但 Birdie 显著扩展了 SSM 的可用范围。这表明,有了正确的训练课程,我们可能不需要为了记忆而牺牲效率,从而为更快、更轻量且能力更强的大型语言模型铺平道路。