](https://deep-paper.org/en/paper/file-2807/images/cover.png)
引言
想象一下,你正试着教计算机如何处理复杂的客服通话——例如,预订多程航班,同时预订酒店并购买当地景点的门票。在人工智能领域,特别是任务导向型对话 (Task-Oriented Dialogue, ToD) 系统中,这是一个巨大的挑战。
标准的方法是强化学习 (Reinforcement Learning, RL)。AI 与用户模拟器交谈,尝试满足请求,并且只有在完美完成整个任务时才会获得“奖励” (正向信号) 。如果失败了,它什么也得不到,甚至会受到惩罚。这就是所谓的稀疏奖励问题 (sparse reward problem) 。 这就像试图通过随机敲击琴键来学习弹奏钢琴协奏曲,而且只有当你第一次尝试就完美地弹奏出整首曲子时,才会有人告诉你“干得好”。
为了解决这个问题,研究人员通常使用课程学习 (Curriculum Learning, CL) 。 这个想法很简单: 先教 AI 简单的任务 (比如只订一张机票) ,一旦掌握了这些,再转移到更难的任务上。但这里有个问题: 这假设你已经有一份准备好的简单任务列表。在复杂的现实世界环境中,那些作为中间“垫脚石”的目标往往并不存在。AI 面对的是绝壁般的难度,没有任何抓手。
在这篇文章中,我们将深入探讨 Zhao 等人提出的一种解决方案,称为自举策略学习 (Bootstrapped Policy Learning, BPL) 。 这个框架不仅仅是寻找一条更容易的路径;它创造了一条路径。通过动态地将复杂目标分解为可解决的子目标 (目标分解) ,并逐步增加难度 (目标演化) ,BPL 允许对话智能体搭建通往成功的梯子。
问题所在: 缺失的梯级
要理解为什么 BPL 是必要的,我们首先需要看看当前方法的局限性。
在标准的流程中,对话策略 (聊天机器人的大脑) 根据当前的对话状态决定说什么。当使用 RL 训练这个策略时,智能体会探索不同的动作。然而,复杂的目标需要一系列正确的动作。
考虑以下用户目标的例子:

在完美的课程学习场景中,我们会先在 \(g_1\) (简单航班) 上训练智能体,然后是 \(g_2\) (航班 + 酒店) ,最后是 \(g_3\) (航班 + 酒店 + 景点) 。这提供了一个平滑的知识过渡 (knowledge transition) 。
然而,在许多数据集和现实场景中, \(g_1\) 和 \(g_2\) 可能根本不存在。 用户直接提出了 \(g_3\) 这样复杂的请求。标准的 CL 方法在这里会失效,因为它们无法对不存在的目标进行排序。如果你强迫智能体立即在 \(g_3\) 上训练,它会反复失败,永远得不到奖励,也就永远学不会。
解决方案: 自举策略学习 (BPL)
研究人员提出了一个框架,它既是老师又是学生。当策略在与用户交互中尝试并失败时,BPL 框架会观察这些交互,并修改目标以匹配智能体当前的技能水平。
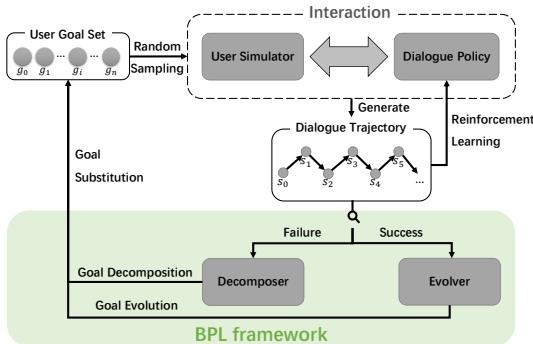
如上图 1 所示,BPL 框架位于训练循环内部。它由两个独特的机制组成:
- 分解器 (The Decomposer): 当智能体失败时激活。它将复杂的目标分解为智能体确实设法实现 (或接近实现) 的更简单的子目标。
- 演化器 (The Evolver): 当智能体成功时激活。它采用已掌握的子目标并重新引入复杂性,将目标演化回最初的困难任务。
这个循环创建了一个“自举 (Bootstrapped)”课程——一个根据智能体自身表现自我生成的课程。
核心方法: 目标塑造是如何工作的
这篇论文的核心是目标塑造 (Goal Shaping) 。 要理解分解器和演化器是如何工作的,我们首先需要定义系统如何看待一个“用户目标”。
定义目标
用户目标不仅仅是一句话;它是一组数据点。它通常由约束条件 (\(C\)) (用户提供的信息,如“我想从纽约出发”) 和请求信息 (\(R\)) (用户想要的信息,如“出发时间是什么时候?”) 组成。

目标的难度大致等同于所涉及的槽位总数 (\(|C| + |R|\))。槽位越多,对话就越难。
为了激励智能体完成整个目标而不仅仅是简单的部分,作者使用了一个塑造后的奖励函数:
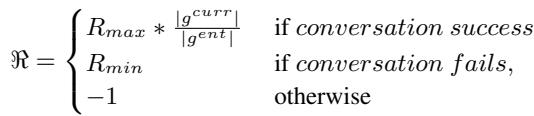
这个公式确保如果智能体只完成了一个子目标 (\(g^{curr}\)),它收到的奖励与该子目标占完整目标 (\(g^{ent}\)) 的比例成正比。这可以防止智能体变得懒惰并满足于部分的成功。
分解与演化的机制
目标在训练过程中如何变化的直观表示对于理解 BPL 至关重要。
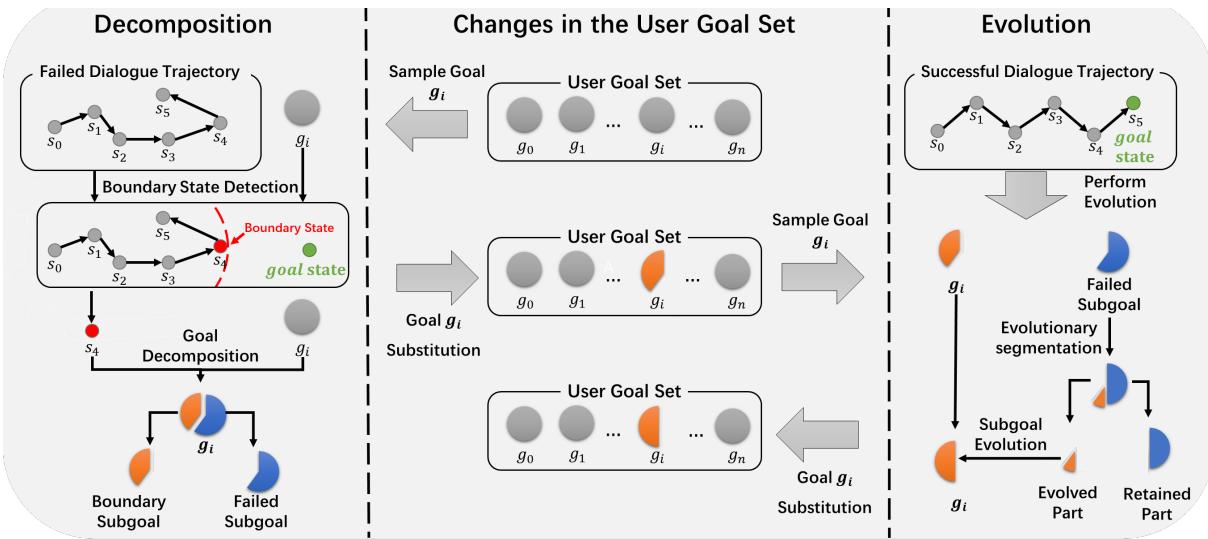
1. 分解器 (处理失败)
让我们看看图 2 的左侧。 假设用户想要一辆出租车 (目标: 目的地、出发时间、乘客人数) 。智能体开始对话。它成功地商定了目的地和出发时间 (状态 \(s_0\) 到 \(s_3\)) ,但在试图处理乘客人数 (状态 \(s_4\)) 时彻底失败了。
分解器会分析这个失败的轨迹。它将 \(s_3\) 识别为边界状态 (Boundary State)——这是对话顺利进行的最后一点。
- 它取原始目标并剥离智能体失败的部分。
- 它创建一个边界子目标 (Boundary Subgoal) (仅包含目的地 + 出发时间) ,并用这个更简单的版本替换原始目标。
- 智能体现在在这个新的、更简单的任务上取得了“成功”,这提供了正向奖励信号并稳定了学习。
2. 演化器 (处理成功)
现在看看图 2 的右侧。 一旦智能体在边界子目标上持续取得成功, 演化器就会介入。它不希望智能体停留在这个简单的水平上。
- 它查看失败的子目标 (Failed Subgoal) (我们之前移除的部分) 。
- 它执行演化分割 (Evolutionary Segmentation) 。 它取该失败部分的一块 (“演化部分”) 并将其加回当前目标。
- 目标变得稍微难了一点。如果智能体再次成功,演化器会添加更多块,直到恢复原始的复杂目标。
塑造策略
作者并没有只选择一种方法来做这件事;他们探索了关于何时分解和如何演化的几种策略。
分解条件:
- 随时失败 (A): 如果失败,立即分解。
- 基于时间 (T): 仅当智能体已经失败了 \(N\) 个 epoch 时才分解 (先给它尝试的时间) 。
- 连续失败 (C): 仅当智能体连续 \(M\) 次未完成同一目标时才分解。
演化策略:
- 固定数量 (F): 每次只加回一个槽位。 (稳扎稳打) 。
- 奖励控制 (R): 根据奖励的高低添加槽位。 (如果考试得了高分,下次考试就会难得多) 。
- 探索程度 (E): 根据“状态差分空间”添加槽位——这是一个衡量智能体对环境探索程度的指标。
实验与结果
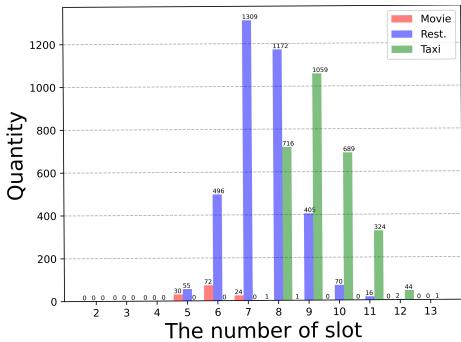
为了验证 BPL,研究人员在四个难度各异的数据集上对其进行了测试: 电影 (Movie) (简单) 、餐厅 (Restaurant) (中等) 、出租车 (Taxi) (困难) 以及著名的 MultiWOZ 2.1 (非常困难,多领域) 。
如下图的槽位分布图所示,这些数据集有着明显的难度曲线。例如,“出租车”领域平均需要处理的槽位比“电影”领域多得多。
与基准模型的对比
作者将 BPL 与标准的深度 Q 网络 (DQN) 以及几种最先进的课程学习方法 (如 SNA-DQN、SDPL 和 VACL) 进行了比较。
结果总结在表 2 中,非常有说服力。
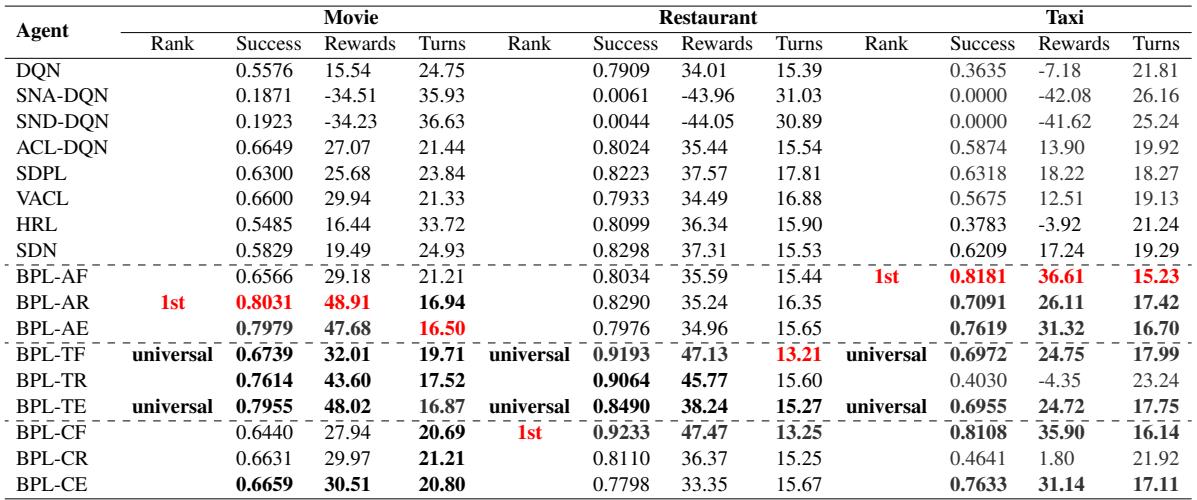
结果的核心要点:
- BPL 占据主导地位: 在几乎所有类别 (成功率、奖励) 中,BPL 的某种变体都优于基准模型。
- 难度很关键:
- 在简单 (电影) 数据集上, BPL-AR (总是分解,基于奖励演化) 效果最好。为什么?因为任务很简单,所以智能体可以激进一点 (快速演化) 。
- 在困难 (出租车) 数据集上, BPL-AF (总是分解,固定演化) 更胜一筹。困难的任务需要耐心——一次只增加一个槽位 (固定) 可以防止智能体不知所措。
- 通用模式: 研究人员确定 BPL-TF 和 BPL-TE 为“通用”模式。它们使用基于时间的触发器 (在简化之前等待一会) 以及固定或基于探索的演化。这些组合在所有数据集上都很稳健,使它们成为未知环境中的安全选择。
多领域表现 (MultiWOZ)
对任何对话系统真正的考验是 MultiWOZ,它涉及在不同领域之间跳转 (例如,先预订火车,然后找一家餐馆) 。
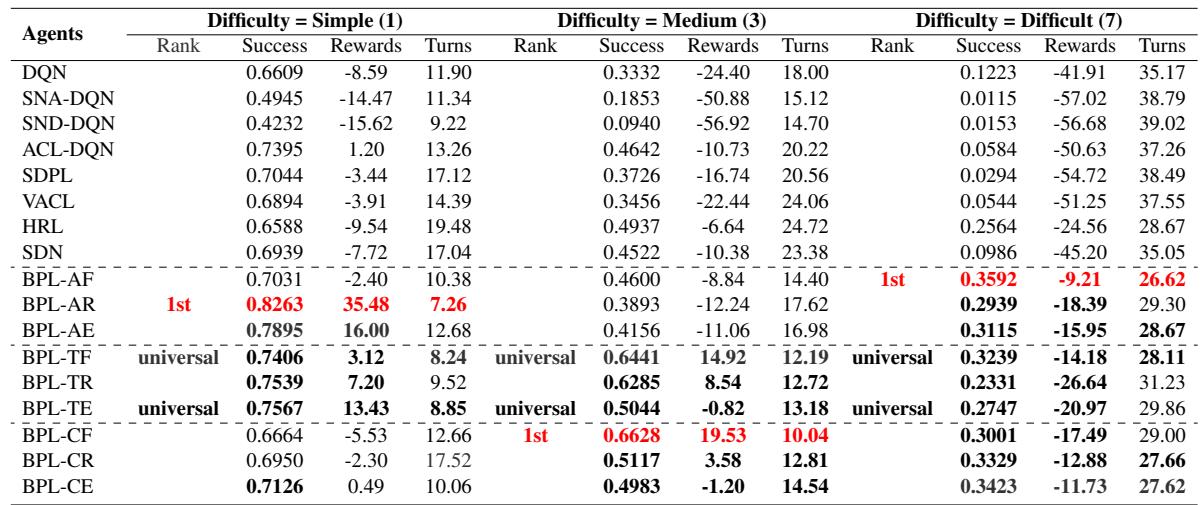
表 4 证实了这一趋势。即使随着领域难度 (规模) 的增加,BPL 变体 (特别是像 BPL-TF 这样的通用变体) 仍能保持较高的成功率。标准的 DQN 甚至一些高级的 CL 方法在这里都很挣扎,因为如果没有中间子目标,复杂度的“跳跃”实在太大了。
为什么有效? (消融实验)
是分解器还是演化器挑大梁?作者进行了一项消融研究来找出答案。
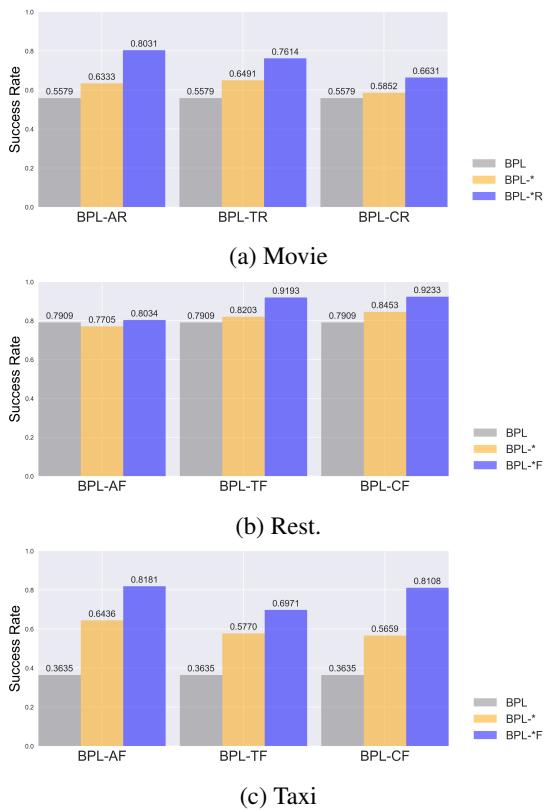
在图 6 中,灰色条 (BPL) 代表完整系统,而彩色条显示移除了组件或更改了组件的版本。
- 分解至关重要: 在困难数据集 (如出租车,图表 ‘c’) 中,分解器 (简化任务) 至关重要。没有它,智能体就会撞墙。
- 演化增加效率: 虽然分解可以防止彻底失败,但演化器确保智能体能够高效地进步回困难任务。
人工评估
模拟很好,但人类真的更喜欢与 BPL 智能体交谈吗?作者进行了一项有 98 名参与者的研究。
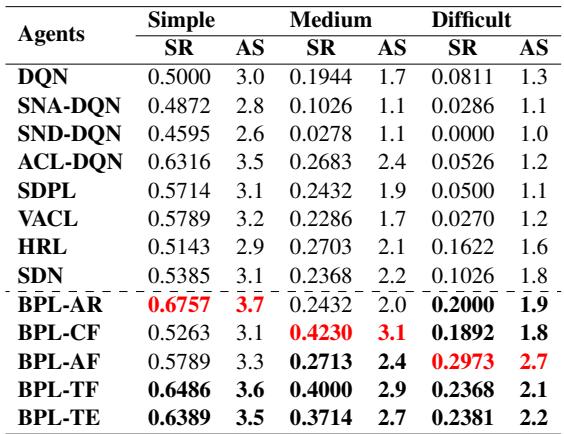
人工评估 (表 5) 与模拟结果一致。与基准相比,BPL 智能体在自然度和连贯性方面取得了更高的成功率 (SR) 和平均分 (AS)。
结论
自举策略学习框架代表了我们训练任务导向型对话系统方式的一个重大转变。BPL 不再依赖人工策划的课程,也不指望智能体能在稀疏奖励中碰运气,而是让智能体能够根据其自身当前的能力定制学习过程。
通过将失败不视为死胡同,而是视为生成子目标的数据源 (分解) ,并将成功视为增加复杂性的邀请 (演化) ,BPL 确保了平滑的知识过渡。这有效地填补了梯子上缺失的梯级,使 AI 能够从简单的交互攀升至复杂的多领域对话。
核心要点:
- 没有预设课程: BPL 在训练期间动态生成课程。
- 目标塑造: 分解目标 (分解) 和重建目标 (演化) 的结合解决了稀疏奖励问题。
- 通用性: 特定的配置 (如 BPL-TF) 无论具体数据集难度如何,都具有普遍良好的效果。
对于 RL 和 NLP 领域的学生和研究人员来说,这篇论文强调了自适应训练的重要性。它表明,稳健 AI 的未来可能不在于更好的数据集,而在于让智能体在我们已有数据上进行更好练习的方法。