](https://deep-paper.org/en/paper/file-2811/images/cover.png)
食物或许是我们拥有的最通用的语言,但它也被文化、地理和历史的方言深深割裂。如果你曾尝试利用当地现有的食材去复刻一道异国料理,你一定体会过其中的艰难。这不仅仅是一个翻译问题,更是一个文化适应问题。
直接将中文食谱翻译成英文往往会让人感到困惑。“适量生姜”对于习惯了茶匙和量杯的西方厨师来说非常模糊。“米酒”这样的配料可能在你当地的杂货店里根本买不到。
在大语言模型 (LLM) 时代,人们很容易直接要求 GPT-4“翻译并改编这份食谱”。然而,哥本哈根大学研究人员最近发表的一篇题为 “Bridging Cultures in the Kitchen” 的论文指出,生成式 AI 往往会偏离目标。他们提出了一种不同的方法: 跨文化食谱检索 (Cross-Cultural Recipe Retrieval) 。
与其让 AI 凭空发明一个中文菜肴的英文版本 (这往往会导致烹饪上的“幻觉”) ,为什么不利用 AI 去目标文化中 寻找 由人类编写的最接近的现有食谱呢?
在这篇深度文章中,我们将探索 CARROT 框架,了解为何食物翻译如此困难,并查看一个新的基准测试,该测试证明了检索真实的食谱往往比生成食谱更安全——也更美味。
问题所在: 当翻译失去了风味
想象一下,你想做 红豆汤 。 你有一份中文食谱,但你需要一份符合你厨房现有库存的英文版本。
如果你使用标准的机器翻译,你会得到一份字面意义上的配料表。如果你使用像 GPT-4 这样强大的生成模型,它会尝试改编食谱。它可能会将克转换为杯,这很有帮助。但它也可能做出奇怪的决定。
请看下面的例子。
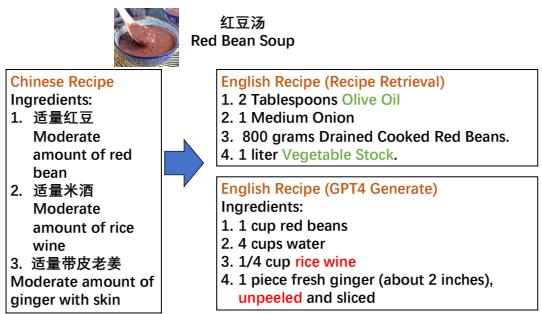
如 图 1 所示,左侧的“中文食谱”要求使用红豆、米酒和带皮老姜。
GPT-4 生成 的版本 (右下) 在语言上很流畅,但在文化上却很混乱。它建议使用“1/4 杯米酒”和“未去皮的生姜”。在英语烹饪文化中,在汤中使用未去皮的生姜是很罕见的,而且米酒也不是典型的西方甜汤的常备配料。
然而,请看右上角的 英文食谱 (食谱检索) 。 这不是翻译;这是在英文数据库中找到的一份现有食谱。它需要“橄榄油”、“洋葱”和“蔬菜高汤”。等等,红豆汤里放洋葱?是的。在西方饮食中,红豆汤通常是一道咸味菜肴 (像豆类炖菜) ,而在中国,它是一道甜点。
这凸显了核心矛盾: 什么才算“匹配”?
- 精确翻译: 保留了甜味特征,但要求的配料用户可能没有或无法理解。
- 文化适应: 找到一道目标受众实际会做的、利用了主要食材 (红豆) 的菜肴 (咸味豆汤) 。
研究人员认为,为了实现真正的文化适应,我们需要一个能够理解这些细微差别的系统。目标不仅仅是翻译文字,而是架起“我有什么”和“你怎么做”之间的桥梁。
厨房里的语义鸿沟
论文指出了使这项任务比标准谷歌搜索更难的三个主要挑战。
1. 命名习惯
在英语中,食谱名称通常是描述性的: “柠檬烤鸡 (Roast Chicken with Lemon) ”。在中文里,名字可能充满诗意、历史典故或晦涩难懂。
- “蚂蚁上树” 是一道肉末粉丝菜,而不是某种昆虫零食。
- “狮子头” 是巨大的肉丸,而不是动物园里的动物。 标准搜索引擎搜索“Lion (狮子) ”时,无法在英文数据库中找到正确的肉丸食谱。
2. 食材的可获得性
一道“炒芋头”的食谱需要进行调整。如果买不到芋头,马铃薯是有效的替代品吗?检索系统需要知道这两种根茎类蔬菜在烹饪中占据相似的生态位。
3. 食物常识
食谱往往会省略在本国文化中被视为“常识”的内容。一份中文食谱可能会说“加入地三鲜”,假设读者知道这指的是土豆、茄子和青椒的特定组合。局外人会对此一头雾水。
介绍 CARROT: 文化感知食谱检索
为了解决这些问题,作者提出了 CARROT (Cultural-Aware Recipe Retrieval Tool,文化感知食谱检索工具) 。
CARROT 是一个“即插即用”的框架。它不需要从头开始训练庞大的新 AI 模型。相反,它巧妙地结合了 大语言模型 (LLM) 的推理能力和 信息检索 (IR) 寻找真实文档的能力。
该框架分三个不同阶段运行,如下图所示。
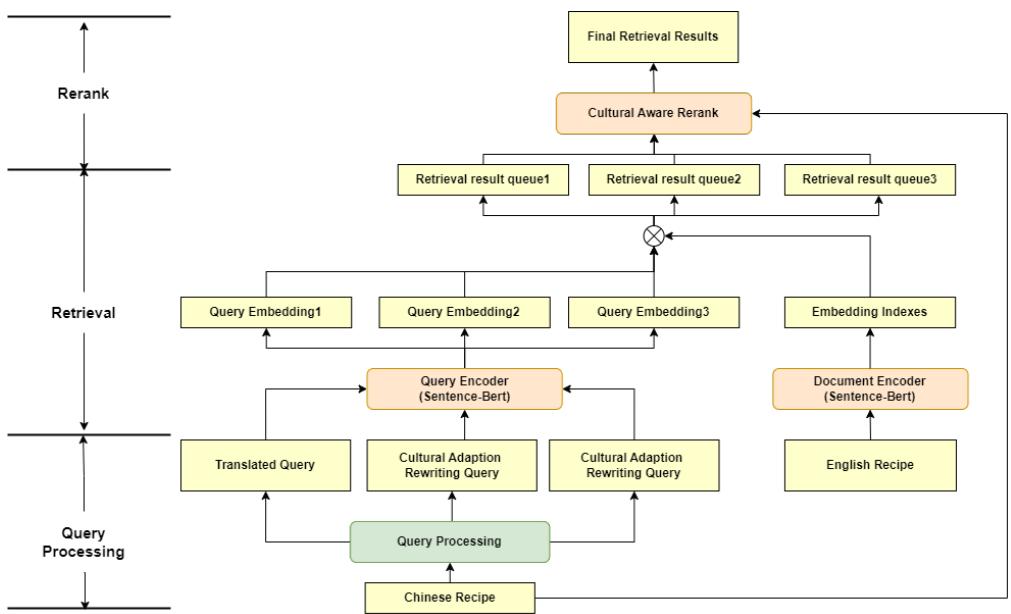
第一阶段: 查询处理 (“重写”)
过程始于一份中文食谱 (“查询”) 。如果我们只是翻译标题,我们会失败 (还记得“狮子头”吗) 。
CARROT 使用 LLM (如 Llama-3) 执行 文化适应重写 。 它查看源食谱的 配料和烹饪步骤,并生成一个新的、描述性的英文标题。
- *输入: * 一份复杂的中文食谱“夫妻肺片”。
- *重写后的查询: * “香辣牛肚沙拉 (Spicy Beef and Tripe Salad) ”。
这种重写后的查询更有可能匹配英文数据库中的食谱。
第二阶段: 检索 (搜索)
系统随后使用这个新查询在庞大的英文食谱数据库中进行搜索 (使用像 Sentence-BERT 这样的双编码器模型) 。它会检索出一个“候选池”——也许是前 100 个看起来相关的食谱。
第三阶段: 文化感知重排序 (过滤)
这是最具创新性的部分。标准搜索引擎根据关键词匹配程度对结果进行排名。CARROT 更进一步。
它将候选食谱反馈给 LLM,并附带一个特定的提示词: “根据相关性对这些食谱进行排名,但优先考虑符合目标文化习惯的食谱。”
这一步过滤掉了那些文本相似但在文化上怪异的食谱 (比如甜汤 vs 咸炖菜的问题) ,将最符合文化且可烹饪的食谱推到顶端。
为什么“重写”是秘诀
要理解为什么 CARROT 比基本翻译效果更好,我们需要看看直接翻译失败的具体案例。
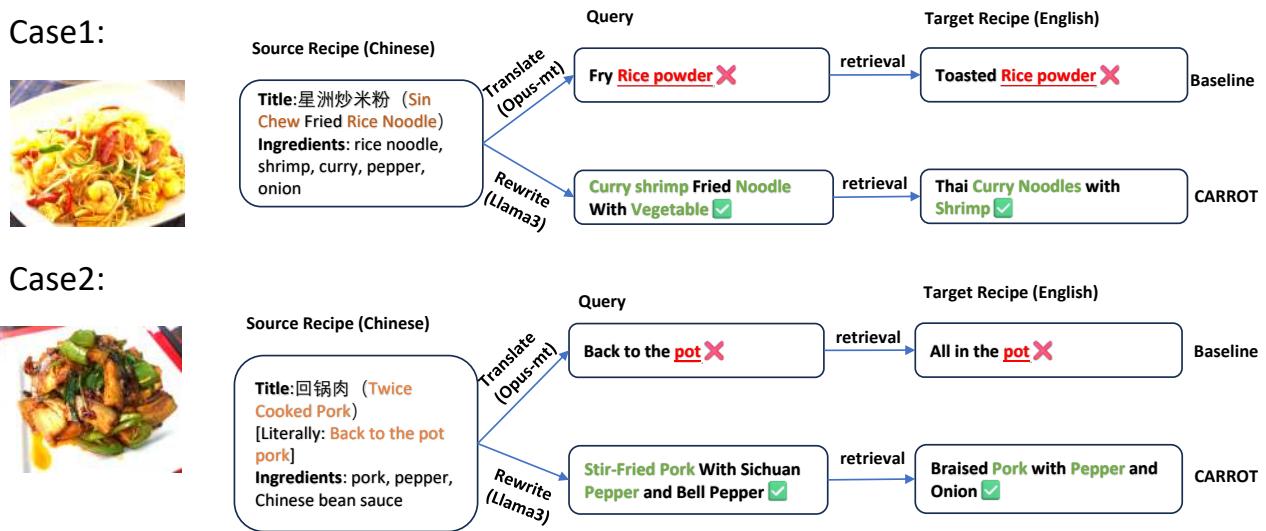
案例 1: “星洲炒米粉”
- 翻译陷阱: 字面翻译将“Rice Noodle (米粉/面条状) ”转换为“Rice Powder (米粉/粉末状) ”。搜索“Fry Rice Powder (炒米粉末) ”会得到“Toasted Rice Powder (烤米粉/蒸肉粉) ”——一种完全不同的食材。
- CARROT 的修正: 模型分析配料 (咖喱、虾、面条) 并将查询重写为“咖喱虾炒面 (Curry Shrimp Fried Noodle) ”。这成功检索到了“泰式咖喱面 (Thai Curry Noodles) ”的食谱。虽然不完全相同,但它是一个文化上相关且可烹饪的匹配。
案例 2: “回锅肉”
- 翻译陷阱: 中文名称字面意思是“回到锅里的肉 (Back to the Pot Meat) ”。搜索引擎搜索“Back to the Pot”会找到像“All in the pot (一锅炖) ”这样荒谬的结果。
- CARROT 的修正: 重写生成了“花椒炒猪肉 (Stir-Fried Pork With Sichuan Pepper) ”,这正确地检索到了“青椒炖猪肉 (Braised Pork with Pepper) ”的食谱。
构建基准测试
这项研究最大的障碍之一是缺乏数据。没有现成的数据集将中文食谱与其符合文化适应的英文检索等价物进行配对。
作者使用两个庞大的食谱语料库构建了一个新的基准: 下厨房 (XiaChuFang) (150 万中文食谱) 和 RecipeNLG (200 万英文食谱) 。
因为他们无法手动检查数百万个配对,所以他们采用了 池化策略 (pooling strategy) 。 他们使用多种检索方法为一组查询找到最佳候选者,然后让人类双语标注者判断这些配对的相关性。
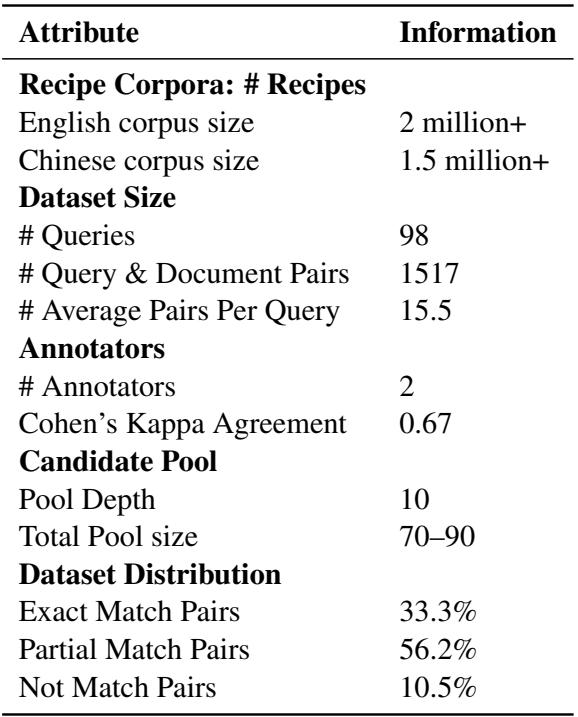
如 表 1 所示,生成的数据集紧凑但质量很高。它包含 98 个多样化的查询和超过 1500 个已标注的配对。有趣的是,只有 33.3% 的配对是“完全匹配”,这凸显了在跨文化中找到 1:1 等价菜肴的难度。
实验: 生成 vs. 检索
那么,哪种方法更好?让 AI 编写食谱 (生成) 还是让它寻找食谱 (检索) ?
研究人员使用 BLEU (文本重叠程度) 和 人工评估 (判断语法、一致性和文化适当性) 等指标对这两种方法进行了评估。
表 3 (见下文) 中的结果揭示了一个有趣的权衡。
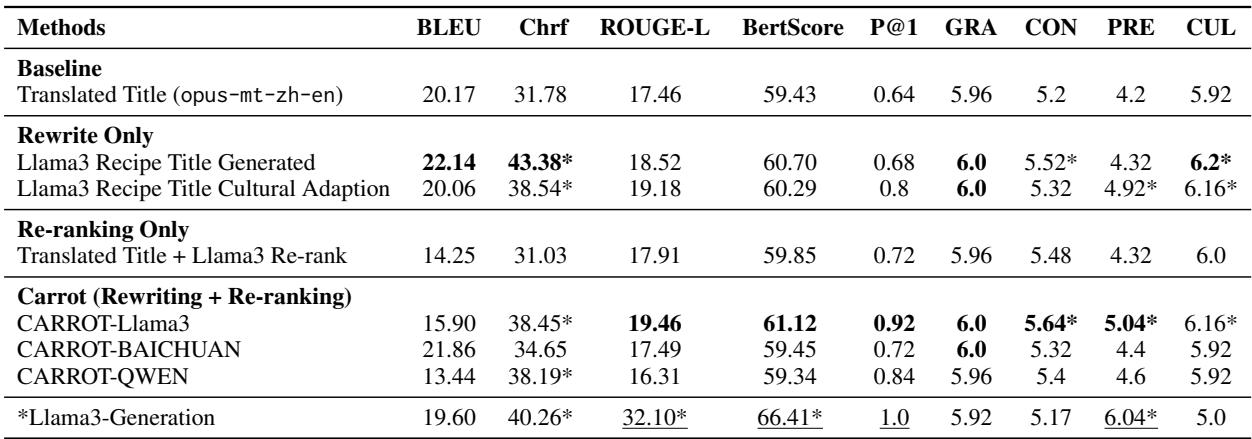
“生成”的错觉
看底部的 Llama3-Generation 行。它在 ROUGE-L 和 BERTScore 上得分最高。这意味着 AI 非常擅长编写 看起来 像参考食谱的文本。
然而,高的文本相似度并不意味着食谱是可行的。
“检索”的现实
现在看看 CARROT-Llama3 行 (在“Carrot”下) 。虽然它的文本重叠分数略低,但它在关键的地方获胜:
- CON (一致性) : 5.64 vs 5.17。
- CUL (文化适当性) : 6.16 vs 5.0。
为什么检索在一致性上获胜?
作者指出了生成式 AI 的一个致命缺陷: 逻辑上的幻觉 。 例如,在生成“红烧牛肉”的食谱时,Llama-3 写道:
“盖上盖子煮 1 小时……把锅从火上移开并 倒掉 (discard) 。 ”
它告诉用户把刚做好的食物扔进垃圾桶!
因为 CARROT 检索的是人类编写的食谱,所以它们在逻辑上是合理的。人类不会写出让你把牛肉扔进垃圾桶的食谱。检索方法确保了烹饪步骤实际上能产生一道可食用的菜肴。
为什么检索在文化上获胜?
生成模型往往比较保守——它们保留原始配料,即使这些配料不符合新文化 (比如未去皮的生姜) 。根据定义,检索模型寻找的是目标文化中已经存在的食谱。如果搜索引擎在美国数据库中找到“盐焗鸡 (Salted Chicken) ”的食谱,它很可能包含柠檬和百里香——西方口味所期望的风味——而不仅仅是盐和味精。
结论: 厨师 vs. 图书管理员
CARROT 框架教会了我们关于 AI 现状的重要一课。虽然大语言模型是令人难以置信的创意引擎,但它们缺乏“现实基础 (grounding) ”。在像烹饪这样化学和物理至关重要的领域 (你无法让炖糊的菜恢复原状) ,纯粹的创造性生成是有风险的。
通过将 LLM 用作 图书管理员 (重写查询和对结果进行排名) 而不是 厨师 (从头开始创造食谱) ,我们两全其美:
- 我们跨越了语言鸿沟。
- 我们确保食谱在物理上是可烹饪的 (一致性) 。
- 我们确保风味特征符合当地口味 (文化适当性) 。
这项研究不仅仅适用于食物。 跨文化检索 的原则可以应用于从医疗建议到技术手册的任何领域——任何“翻译”需要适应新环境,而不仅仅是交换词汇的地方。
所以,下次当你想做一道异国菜肴时,不要只是让聊天机器人发明一个食谱。使用那些能帮你发现当地人 实际上 是如何烹饪的工具。你的晚餐客人们会感谢你的。