](https://deep-paper.org/en/paper/file-2814/images/cover.png)
在人工智能飞速发展的世界里,我们要么惊叹于大语言模型 (LLM) 能用英语写诗,要么看着它们用 Python 调试代码,或者以近乎人类的准确度将法语翻译成德语。然而,这场技术革命的分配并不均匀。对于数十亿人来说,数字世界在他们的母语中仍然基本无法触及。
这就是低资源语言 (Low-Resource Languages) 所面临的挑战——这些语言缺乏训练现代 AI 系统所需的海量数字文本档案。
今天,我们将深入探讨埃马库瓦语 (Emakhuwa) 迈出的重要一步。这是一种班图语,约有 25% 的莫桑比克人口使用该语言。尽管它是该国使用最广泛的土著语言,但在历史上,埃马库瓦语在 NLP 社区中几乎是隐形的。最近的一篇研究论文*《Building Resources for Emakhuwa》*旨在改变这一现状。研究人员为埃马库瓦语构建了首批实质性的数据集和基准,解决了两个关键任务: 机器翻译 (MT) 和新闻主题分类。
在这篇文章中,我们将探讨他们如何收集这些数据,他们面临的独特语言挑战,以及最先进的模型在学习这种复杂的非洲语言时的表现。
埃马库瓦语背景
在研究算法之前,我们需要了解这种语言。埃马库瓦语主要通行于莫桑比克北部和中部。它是一种黏着语 (agglutinative language) ,这意味着单词是通过将各种语素 (有意义的小单位) 串联起来形成的。这导致了长而复杂的单词,这些单词所传达的含义在英语或葡萄牙语中可能需要整整一句话来表达。
此外,埃马库瓦语具有声调属性,且拼写系统尚未完全标准化。这些特征使得它对于标准 NLP 模型来说特别困难,因为这些模型通常依赖于英语等语言中一致的拼写和较短的单词形式。
直到现在,如果你想为埃马库瓦语构建一个翻译应用程序,你会碰壁: 因为数据根本不存在。
第一部分: 数据搜寻
这篇论文的核心贡献是创建了一套“全栈”资源。研究人员不仅仅是抓取网络数据;他们采用了多管齐下的策略来收集高质量文本。
1. “黄金标准”: 平行新闻语料库
研究人员创建了首个葡萄牙语 (莫桑比克的官方语言) 与埃马库瓦语之间的平行新闻语料库。这并非由 AI 完成,而是由人类完成的。
他们精选了近 1,900 篇涵盖政治、经济、文化和体育的新闻文章。随后,他们聘请专业翻译人员将这些文章从葡萄牙语翻译成埃马库瓦语。这产生了超过 18,000 个高质量的平行句子。
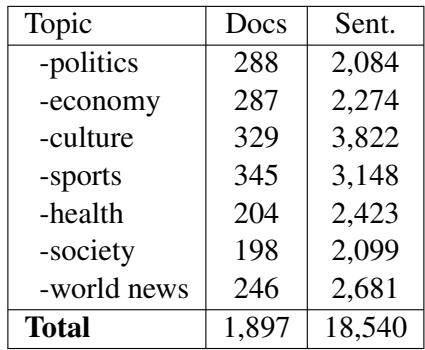
如上方的表 1 所示,该数据集涵盖了广泛的主题。这种多样性至关重要,因为仅在“政治”内容上训练的模型,在尝试翻译关于“健康”或“体育”的句子时可能会彻底失败。
2. 通过 OCR 拯救数据
低资源语言的一个主要问题是,许多文献仅存在于实体书中,而不在互联网上。为了解决这个问题,团队数字化了 Método Macua 一书,这是一本富含文化叙事和故事的文本。
他们使用光学字符识别 (OCR) 扫描该书,随后的手动校正阶段由志愿者修正扫描错误。

表 2 突出了这一努力。虽然数量 (1,911 个句子) 比新闻语料库少,但这些数据在语言学上是独特的。它捕捉了传统的叙事和对话,这与新闻报道的正式语气截然不同。
3. 单语数据
最后,为了理解一种语言的结构,模型需要阅读大量的该语言文本,即使没有对应的翻译。研究人员抓取了在线杂志和埃马库瓦语维基媒体孵化器,以收集纯埃马库瓦语文本。
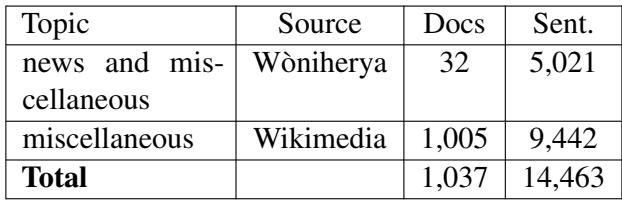
表 3 详细说明了这一收集过程。虽然 14,000 个句子与英语数据集 (数以十亿计) 相比可能显得微不足道,但对于低资源语言来说,每一个句子都至关重要。这些数据对于“回译 (back-translation) ”至关重要,我们将在稍后讨论这一技术。
最终的数据集生态系统
在清洗和处理之后,研究人员将数据组织成训练集、验证集 (Dev) 和测试集。这种严格的划分确保了在评估模型时,测试的是模型从未见过的文本。
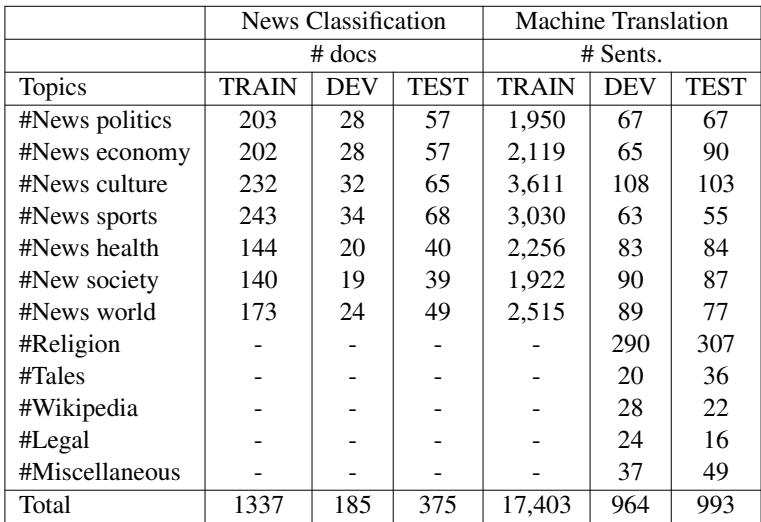
表 4 提供了最终数据集的路线图。请注意“新闻分类”与“机器翻译”的具体分配。这种结构化的方法允许未来的研究人员重现这些结果,并在同一个排行榜上进行竞争。
第二部分: 机器翻译基准
手握数据,研究人员着手回答一个紧迫的问题: 现代多语言模型真的能学会埃马库瓦语吗?
他们并没有从零开始。相反,他们使用了迁移学习 (Transfer Learning) 。 他们采用了在数百种语言上预训练过的大型模型,并在新的埃马库瓦语数据集上对它们进行“微调”。这些模型包括:
- MT5 & mT0: Google 的大型多语言 Transformer。
- ByT5: 一种逐字节处理文本的“无 Token (token-free) ”模型 (对拼写复杂的语言非常有用) 。
- NLLB (No Language Left Behind): Meta 的尖端翻译模型。
- M2M-100: 专为多对多翻译设计的模型。
结果: 谁是翻译之王?
评估使用了两个主要指标: BLEU (单词匹配的精确度) 和 ChrF (字符级匹配) 。ChrF 通常更适合像埃马库瓦语这样的黏着语,因为它认可正确获取复杂单词的部分内容,即使整个单词并非完美匹配。
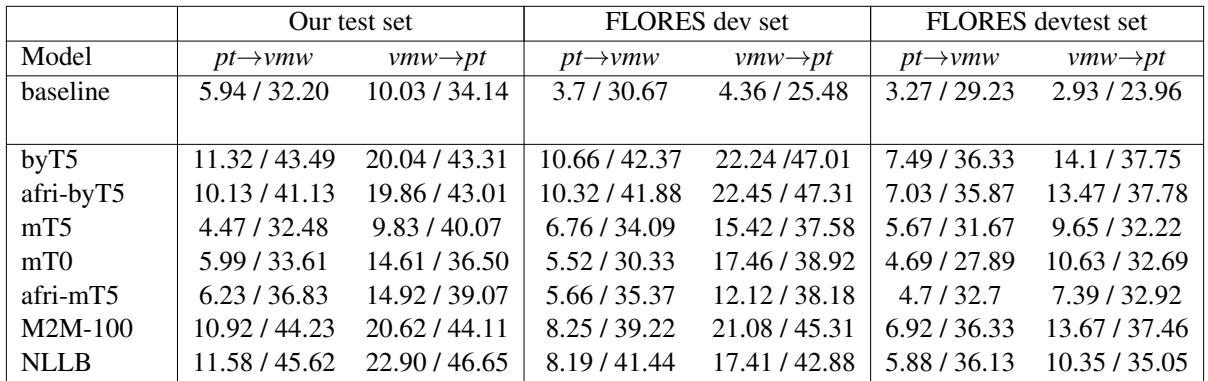
表 6 揭示了排行榜。表现突出的是 NLLB 和 ByT5 。
- NLLB 取得了最高分,证明在大量语言上预训练的模型能很好地适应新语言。
- ByT5 表现出人意料地好,击败了标准的 mT5。这验证了一个假设: 无 Token 架构对于具有丰富形态和拼写变体的语言更具优势,因为它们不会被“未知”的子词 (sub-words) 绊倒。
然而,请注意两个方向之间的差距。翻译成埃马库瓦语 (pt -> vmw) 比从埃马库瓦语翻译 (vmw -> pt) 要难得多。这是意料之中的;生成合法的、语法复杂的埃马库瓦语单词比生成葡萄牙语是一项更艰难的生成任务。
为了理解这种难度,请看下方的表 10 。 它展示了葡萄牙语源文本、英语参考以及不同模型生成的埃马库瓦语翻译。

你可以看到基线模型经常产生幻觉或生成乱码。相比之下,NLLB 生成的结果更接近基本真值 (“vmw”) ,尽管捕捉“海洋下方较薄 (thinner under the maria) ”的确切细微差别仍然是一个挑战。
更多数据有帮助吗? (数据增强实验)
研究人员并未止步于简单的微调。他们想看看混合不同的数据源是否会提高性能。他们使用 NLLB 模型设置了一个渐进式实验:
- System 1: 仅旧数据 (Ali-2021)。
- System 2: 旧数据 + 新新闻数据。
- System 3: 以上所有 + OCR 数据。
- System 4: 以上所有 + 合成数据 。
等等,什么是合成数据? 利用前面看到的单语文本,他们训练了一个模型将埃马库瓦语反向翻译成葡萄牙语。然后,他们将这些机器生成的配对视为训练数据。这被称为回译 (Back-Translation) 。
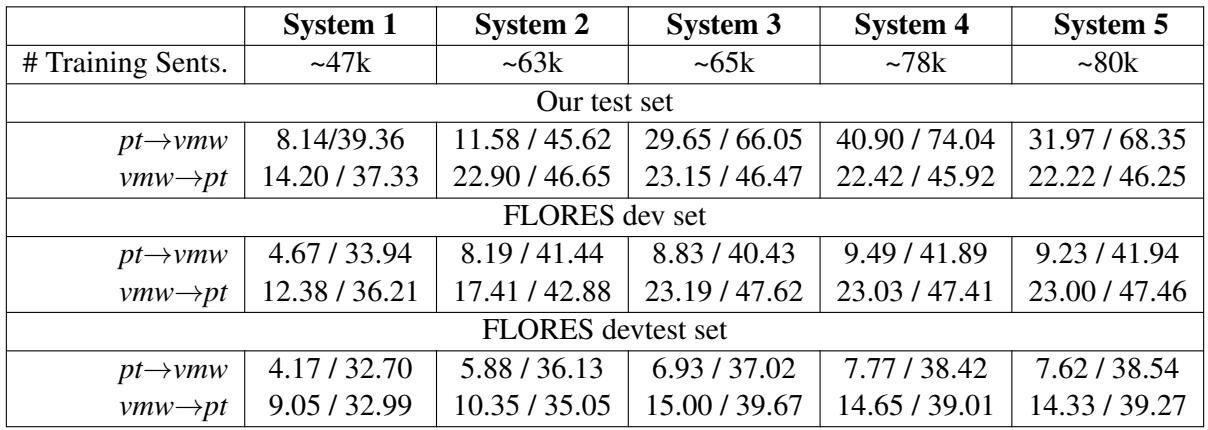
表 7 讲述了一个引人入胜的故事。
- 新闻数据起到了火箭助推器的作用: 从 System 1 到 System 2 带来了质量的巨大飞跃。高质量的人工翻译是无可替代的。
- 合成数据有效: System 4 (使用回译数据) 提供了最佳的整体性能。
- OCR 陷阱: 有趣的是,添加混合了其他来源的 OCR 数据 (System 3) 有时反而会损害性能或相较于合成数据收益递减。研究人员推测这是由于领域漂移 (Domain Shift) 造成的。OCR 数据充满了民间故事和古老的习语,而测试集是现代新闻。风格的转变可能使模型感到困惑。
第三部分: 新闻主题分类
第二个主要任务是教 AI 对新闻文章进行分类。给定一个标题或整篇文章,模型能否预测它是关于政治、体育、健康还是文化?
团队比较了两种方法:
- 经典机器学习: 像朴素贝叶斯 (Naive Bayes) 和 XGBoost 这样的轻量级算法。
- 微调语言模型: 像 XLM-R、AfriBERTa 和 AfroLM 这样的重量级模型。
“大卫对抗歌利亚”的结果
令人惊讶的是,经典的朴素贝叶斯分类器击败了几个复杂的深度学习模型,在使用标题和正文时取得了 72.83% 的 F1 分数。
为什么?许多“以非洲为中心”的大语言模型 (如 AfroLM) 并没有专门针对埃马库瓦语进行预训练。没有这些基础知识,它们庞大的神经网络还不如一个仅统计词频的简单统计方法有效。
然而,模型在某些类别上仍然很吃力。
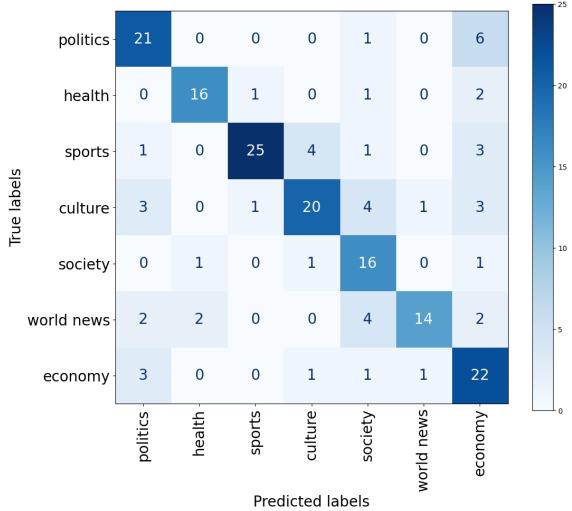
混淆矩阵 (图 1) 可视化了这些错误。
- 深蓝色对角线: 模型非常擅长识别体育 (Sports) (25 个正确分类) 。体育词汇 (进球、比赛、球员) 可能非常独特。
- 混淆: 看一下“政治 (Politics) ”和“经济 (Economy) ”部分。它们之间存在错误分类。这是合理的——关于经济的新闻通常涉及政府决策,模糊了这两个话题之间的词汇界限。“社会 (Society) ”和“国际新闻 (World News) ”也显示出明显的重叠,这可能是由于这些类别的广泛性质。
挑战与未来
虽然这些结果很有希望,但论文强调了未来的研究人员必须解决的重大局限性:
- 拼写不一致: 埃马库瓦语没有统一的书写标准。一个翻译可能将“莫桑比克”写成 Mosampikhi,而另一个则写成 Mocampiiki。这种变体使模型感到困惑,因为模型会将它们视为完全不同的单词。
- 外来词: 翻译人员经常将葡萄牙语单词 (如“Governo”表示政府) 按发音调整为埃马库瓦语 (“Kuveru”) ,而不是使用埃马库瓦语的本土术语。这种“懒惰翻译”使得数据集充斥着葡萄牙语的衍生词。
- 评估指标: 如果模型不匹配参考文本的确切拼写,像 BLEU 这样的标准指标会严厉惩罚模型,考虑到缺乏标准化的拼写,这是不公平的。
结论
这项研究代表了埃马库瓦语在数字时代的分水岭时刻。通过创建首个稳健的平行语料库并建立严格的基准,作者为未来的创新奠定了基础。
关键要点很明确:
- 高质量的人类数据无可替代。 手动翻译的新闻语料库带来了最大的性能提升。
- 多语言模型很强大,但不是魔法。 NLLB 和 ByT5 是很好的起点,但如果没有足够的特定语言数据,它们仍然举步维艰。
- 简单可能更好。 对于分类任务,经典算法与庞大的神经网络不分伯仲,证明了在低资源环境中我们不应抛弃传统方法。
最重要的是,这些资源现在已向开源社区开放。这邀请学生、开发者和语言学家接过接力棒,完善这些模型,并帮助确保埃马库瓦语的使用者不会在 AI 革命中被落下。