](https://deep-paper.org/en/paper/file-2818/images/cover.png)
想象一位经验丰富的医生正在查看病人的档案。他们不仅仅是看一堆数字——血压 140/90,心率 100——然后从统计学上计算心脏病发作的几率。相反,他们会进行临床推理 。 他们综合分散的数据点,运用几十年来学到的外部医学知识,并构建关于病人主要生理进展的叙述。他们可能会想: “病人的肌酐在升高,同时血压不稳定,考虑到他们的糖尿病史,这表明急性肾损伤正在使心血管状况复杂化。”
将此与医疗保健领域的传统深度学习模型进行对比。虽然功能强大,但它们本质上是模式匹配机器。它们摄取大量的电子健康记录 (EHR) 数据——诊断代码、实验室数值、时间戳——并输出一个概率。它们是数据驱动的“黑盒”,在数据稀缺时往往表现挣扎,并且缺乏解释为什么做出该预测的能力。
这引出了一篇引人注目的新研究论文: CARER (Clinical Reasoning-Enhanced Representation,增强临床推理的表征学习) 。 CARER背后的研究人员提出了一个根本性的问题: 我们能否通过注入由大型语言模型 (LLM) 生成的类人临床推理能力,来增强深度学习模型?
在这篇文章中,我们将解构 CARER 框架。我们将探讨它如何使用“思维链” (Chain-of-Thought) 提示来模仿医生的逻辑,如何将原始数据与高层推理对齐,以及为什么这种方法在健康风险预测方面显著优于最先进的模型。
问题: 数据驱动医学的局限性
EHR 数据既复杂又多模态。它包括:
- 结构化数据: ICD 诊断代码、人口统计学信息和连续的实验室数值 (如血糖水平) 。
- 非结构化数据: 工作人员撰写的临床笔记。
标准方法通常为这些模态训练单独的编码器 (如 RNN 或 Transformer) 并将它们融合。然而,这些模型面临三个主要障碍:
- 数据效率低: 它们需要海量数据集才能具有良好的泛化能力。在医学领域,高质量的标注数据往往稀缺且昂贵。
- 缺乏外部知识: 标准模型只知道训练集中的内容。除非它从头开始学习统计相关性,否则它不“懂”医学教科书或病理生理学。
- 语义鸿沟: “局部”视角 (特定病人的原始数值) 与“全局”视角 (解释这些数值的医学推理) 之间存在脱节。
CARER 通过使用 LLM 来解决这些问题,不仅仅是为了阅读笔记,而是为了主动推理病人的病史,实际上是在回路中充当辅助“专家”。
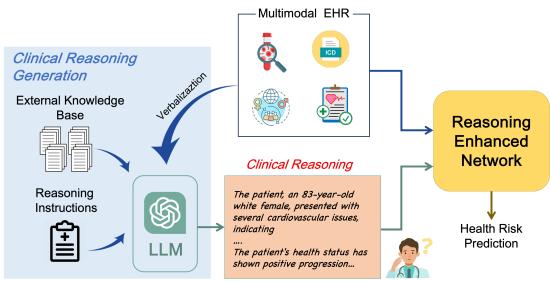
如图 1 所示,CARER 引入了一个双路径系统。一条路径处理原始 EHR 数据,而另一条路径生成并处理临床推理叙述。这两条路径随后被对齐并融合以做出最终预测。
CARER 框架: 深度剖析
CARER 的架构非常复杂,融合了经典深度学习与现代生成式 AI 技术。让我们将其分解为三个明显的阶段: 准备、推理和对齐 。
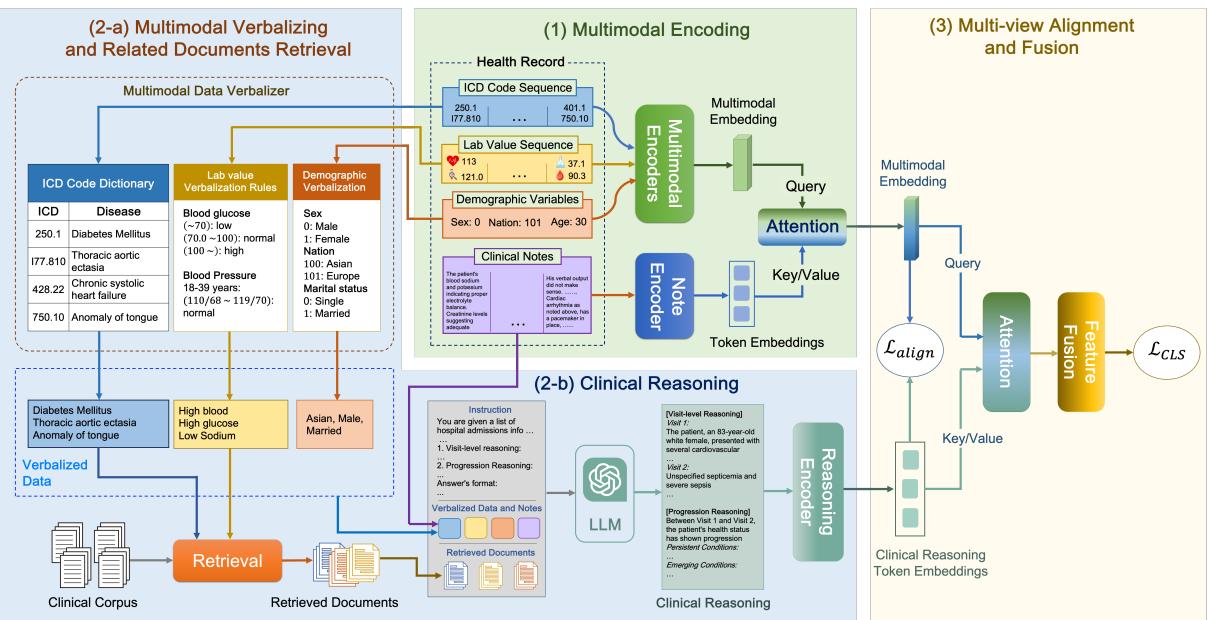
第 1 阶段: 语言化和检索 (上下文)
LLM 擅长处理文本,但在解释原始数值矩阵或晦涩的数据库代码方面却臭名昭著。为了让 LLM 对病人进行推理,我们需要首先将病人的数据“翻译”成 LLM 能理解的语言。
语言化 (Verbalization) : 研究人员开发了一个基于规则的系统,将结构化数据转换为文本。
- ICD 代码: 转换为其描述性名称 (例如,代码
250.00变为“2型糖尿病”) 。 - 实验室数值: 这很关键。原始数字如“115”如果没有上下文是无意义的。CARER 将其转换为语义字符串: “高血糖,115 mg/dL”。它根据医学标准将数值分类为低、正常或高。
- 人口统计学: “年龄: 80,性别: 男”。
检索增强生成 (RAG) : 即使是能力强大的 LLM 也会产生幻觉。为了使推理建立在医学事实之上,CARER 采用了 RAG。它使用语言化后的病人数据作为查询,从知识库 (具体为 PrimeKG )中检索相关的医学文档。
如果病人患有“高血糖”和“高血压”,系统会检索解释糖尿病与血压之间关系的文档。这为 LLM 提供了一份经过验证的医学知识“备忘录”来支持其推理。
第 2 阶段: LLM 辅助的临床推理
现在来到了核心创新点。CARER 使用 思维链 (Chain-of-Thought, CoT) 提示来引导 LLM (本研究中使用的是 GPT-3.5) 完成结构化的推理过程。
模型不仅仅被要求“预测风险”。正如图 3 所示,它被指示执行两种特定类型的推理:
- 就诊级推理 (Visit-Level Reasoning) : 分析当前的入院情况。有哪些诊断?实验室数值是否异常?这张快照说明了病人当前的什么健康状况?
- 进展级推理 (Progression Reasoning) : 观察随时间的变化。哪些病情是持续的?哪些是新发的?肾功能是否在多次就诊中恶化?

提示词结合了语言化数据 (\(S\)) 、特定的推理指令 (\(T\)) 以及检索到的医学文档 (\(\hat{P}\)) 。
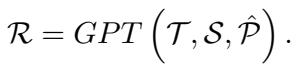
输出结果 \(\mathcal{R}\) 是对病人健康轨迹的综合文本分析。然后,该文本被输入到一个 Clinical-Longformer 编码器 (一种专门处理长临床文本的 Transformer 模型) 中,以创建推理的密集向量表示,记为 \(z_R\)。
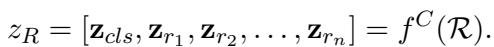
第 3 阶段: 多视图对齐 (数学粘合剂)
此时,网络拥有该病人的两种截然不同的表征:
- \(z_E\) (多模态编码) : 来源于处理原始代码、数值和原始笔记的标准编码器的向量。这代表了 “局部视图” ——病人的具体事实。
- \(z_R\) (推理编码) : 来源于 LLM 生成叙述的向量。这代表了 “全局视图” ——通过外部医学知识镜头对这些事实的解释。
挑战: 这两个向量来自不同的源头,可能存在于不同的“语义空间”中。如果我们只是将它们拼接起来,模型可能难以将原始的心率数值与 LLM 关于“心动过速”的句子联系起来。
解决方案: 跨视图对齐损失 (Cross-View Alignment Loss) 。 研究人员提出了一种机制来强制这两个视图保持一致。他们计算一批病人的相似度矩阵。
- \(Q_E\): 病人 A 的原始数据与病人 B 的原始数据有多相似?
- \(Q_R\): 病人 A 的临床推理与病人 B 的临床推理有多相似?
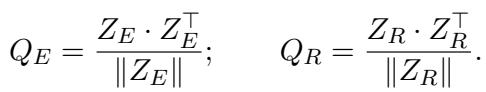
如果病人 A 和病人 B 拥有相似的原始数据,他们的临床推理叙述也应该相似。因此,矩阵 \(Q_E\) 和 \(Q_R\) 应该看起来是一样的。 对齐损失 (\(L_{align}\)) 最小化了这两个矩阵之间的差异:
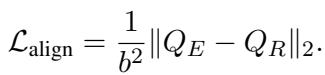
这迫使编码器学习在原始数据和高层推理之间一致的特征。
第 4 阶段: 融合与预测
最后,模型融合了对齐后的特征。它使用一种注意力机制,其中原始数据 (\(z_E\)) 作为查询 (Query) ,从推理向量 (\(z_R\)) 中提取最相关的信息。
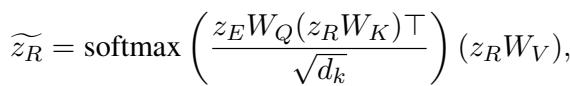
这些组合特征通过一个多层感知机 (MLP) 以输出最终的风险预测 (例如,心力衰竭的概率) 。
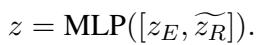
总损失函数结合了标准分类损失 (预测误差) 和我们前面定义的对齐损失。
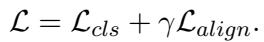
实验与结果
为了验证 CARER,研究人员在两个大型公共数据集上进行了测试: MIMIC-III 和 MIMIC-IV 。 他们专注于两个困难的任务:
- 心力衰竭预测: 二分类任务 (病人是否会患上心力衰竭?) 。
- 全诊断预测: 多标签分类任务 (预测未来的疾病代码) 。
击败基准
结果令人印象深刻。CARER 与几个强基准模型进行了比较,包括 RETAIN、HiTANet 以及像 MedHMP 和 MUFASA 这样的多模态模型。
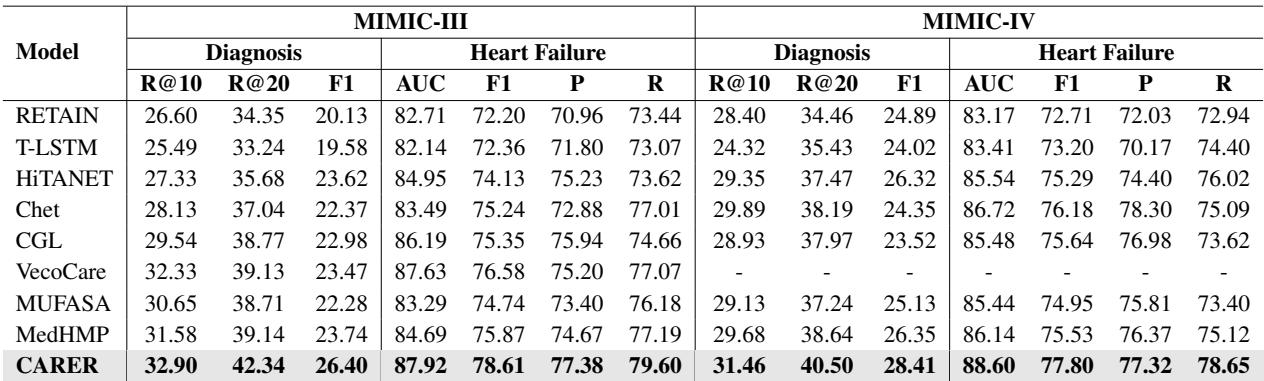
如表 2 所示,CARER 在所有方面都达到了最先进的性能 (SOTA) 。在 MIMIC-III 的全诊断预测任务中,它在 Recall@10 指标上超过了次优模型 11% 以上。在心力衰竭预测方面的提升虽然较小但很稳定,达到了接近 0.80 的 F1 分数。
数据效率: 事半功倍
最重要的发现之一是 CARER 在“低数据”环境下的表现。研究人员仅使用训练数据的一小部分 (10%、25%、50%) 来训练模型。
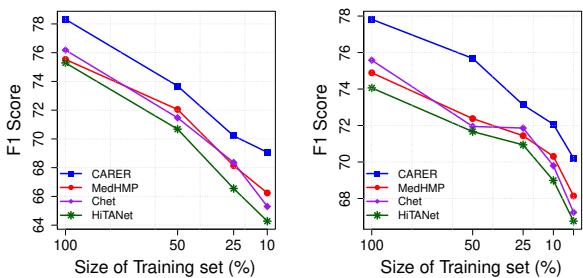
图 4 (左图) 生动地说明了这一点。当数据变得稀缺时,基准模型 (如 HiTANet 和 Chet) 的性能急剧下降,而 CARER 仍保持高性能。即使仅使用 10% 的训练数据,CARER 也能达到接近 70% 的 F1 分数。
这表明 LLM 提供的“临床推理”充当了一个强大的正则化项。它利用预先编码在 LLM 中的通用医学知识,补充了训练样本的不足。
推理真的重要吗?
你可能会想: 这种复杂的架构有必要吗?也许只添加 LLM 的文本就足够了?研究人员进行了消融实验来找出答案。
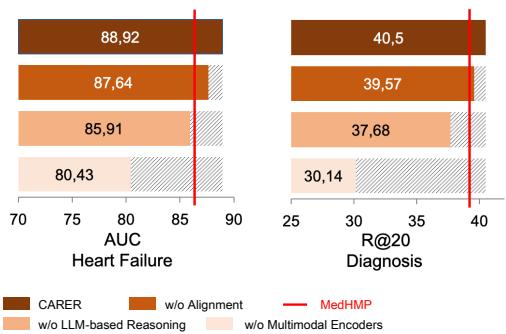
图 6 展示了移除组件后的情况:
- w/o Alignment (无对齐) : 移除原始数据与推理之间的数学对齐会导致性能明显下降。模型需要这种“胶水”来连接不同的视图。
- w/o LLM-based Reasoning (无 LLM 推理) : 完全移除推理会导致显著的下降。
- w/o Multimodal Encoder (无多模态编码器) : 有趣的是,仅依赖 LLM 推理 (没有原始数据编码器) 的表现最差。这证实了 LLM 不能替代传统的编码器;它们是增强器。你需要原始数据的精确性和推理的广度。
可解释性: 透视推理内部
最后,CARER 的最大优势之一是可解释性。因为模型使用基于文本的推理,我们可以检查模型关注了什么。

在表 3 中,我们看到一个案例研究,模型正确预测了慢性肾脏病。通过分析注意力权重,我们可以看到模型聚焦于讨论“急性肾衰竭”和“血肌酐升高”的句子。这种透明度让临床医生能够信任预测,因为他们可以验证其背后的逻辑。
结论
CARER 代表了医疗 AI 向前迈出的重要一步。它超越了“将数字输入黑盒”的范式,转向模仿人类专家认知过程的系统。
通过结合 检索增强生成、思维链提示和新颖的 跨视图对齐 机制,CARER 实现了三个主要目标:
- 更高的准确性: 它树立了风险预测的新基准。
- 数据效率: 即使在病人数据有限的情况下,它也能表现出色。
- 可解释性: 它在预测的同时提供了可理解的基本原理。
对于医疗保健 AI 领域的学生和研究人员来说,CARER 证明了未来不仅仅在于更大的模型或更多的数据——而在于能够弥合统计学习与语义推理之间鸿沟的架构。