](https://deep-paper.org/en/paper/file-2827/images/cover.png)
超越症状: 语境和不确定性如何改进心理健康 AI
心理健康障碍影响着全球超过十亿人。随着社交媒体的兴起,网络平台已成为人们自我表露的空间,为研究人员提供了海量数据集,以帮助早期发现抑郁症或焦虑症等疾病。
然而,从文本中检测心理障碍也是出了名的困难。早期的深度学习模型就像“黑盒”——它们可以预测某种障碍,却无法解释原因。近年来的“基于症状”的方法对此进行了改进,它们首先识别特定症状 (如“失眠”或“疲劳”) ,然后预测障碍。但即使是这些模型也有一个关键缺陷: 它们往往忽略了语境 (Context) 。
想象一下两个人说“我感到难过”。一个人是因为昨天考试不及格;另一个人则是这种感觉已经持续了两个月。标准的症状检测器会在两者中都看到“难过”。但精神科医生根据 DSM-5 (精神障碍诊断与统计手册) 知道,持续时间和起因至关重要。
在这篇文章中,我们将深入探讨 CURE (Context- and Uncertainty-aware Mental DisoRder DEtection,语境和不确定性感知心理障碍检测) ,这是由成均馆大学和三星医疗中心的研究人员提出的一种新颖框架。该论文提出了一种方法,不仅计算症状,还能理解其语境,并识别模型自身何时可能存在不确定性。
仅基于症状检测的问题
要理解为什么需要 CURE,我们需要看看当前可解释模型的局限性。基于症状的模型通常按两步流程运作:
- 症状识别: 扫描帖子中表示症状的关键词或短语。
- 障碍检测: 使用这些症状来预测特定的障碍。
问题在于症状很少是非黑即白的。语境——持续时间、频率、起因以及对日常生活的影响——决定了诊断结果。
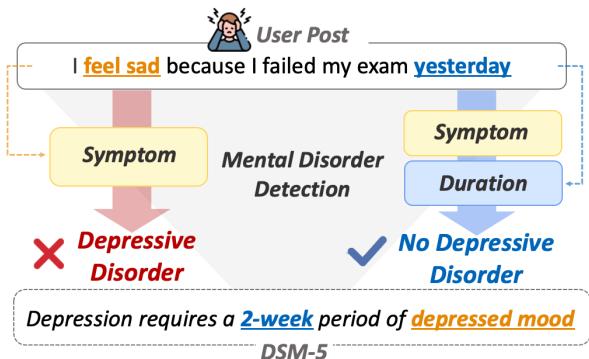
如 图 1 所示,用户发帖说“我感到难过,因为我昨天考试不及格”,其中包含一个症状 (难过) 。一个简单的模型可能会将其标记为抑郁。然而,语境 (“昨天”,由“考试”引起) 表明这是一种暂时的情绪反应,而非障碍。相反,提到难过持续“一个月”的帖子则符合重度抑郁障碍的 DSM-5 标准,该标准要求症状至少持续两周。
此外,这些模型容易产生不确定性误差 。 如果第一步 (识别症状) 稍有偏差或置信度较低,这种误差就会传播到最终诊断中。
KoMOS 数据集
在构建模型之前,研究人员需要高质量的数据。他们构建了 KoMOS (Korean Mental Health Dataset with Mental Disorder and Symptoms labels,带有心理障碍和症状标签的韩国心理健康数据集) 。与许多从一般社交媒体抓取的 (充满噪声的) 数据集不同,KoMOS 由来自 Naver Knowledge iN 的问答对组成,用户在其中询问他们的心理状态,并由认证的精神科医生给出回答。
这确保了真值标签在医学上是有效的。该数据集涵盖了四种主要障碍——抑郁障碍、焦虑障碍、睡眠障碍和进食障碍——以及一个“非疾病”类别,并标注了 28 种特定症状。
CURE 框架
CURE 框架旨在解决已确定的两个主要问题: 语境的缺失和对不确定性的处理不当。
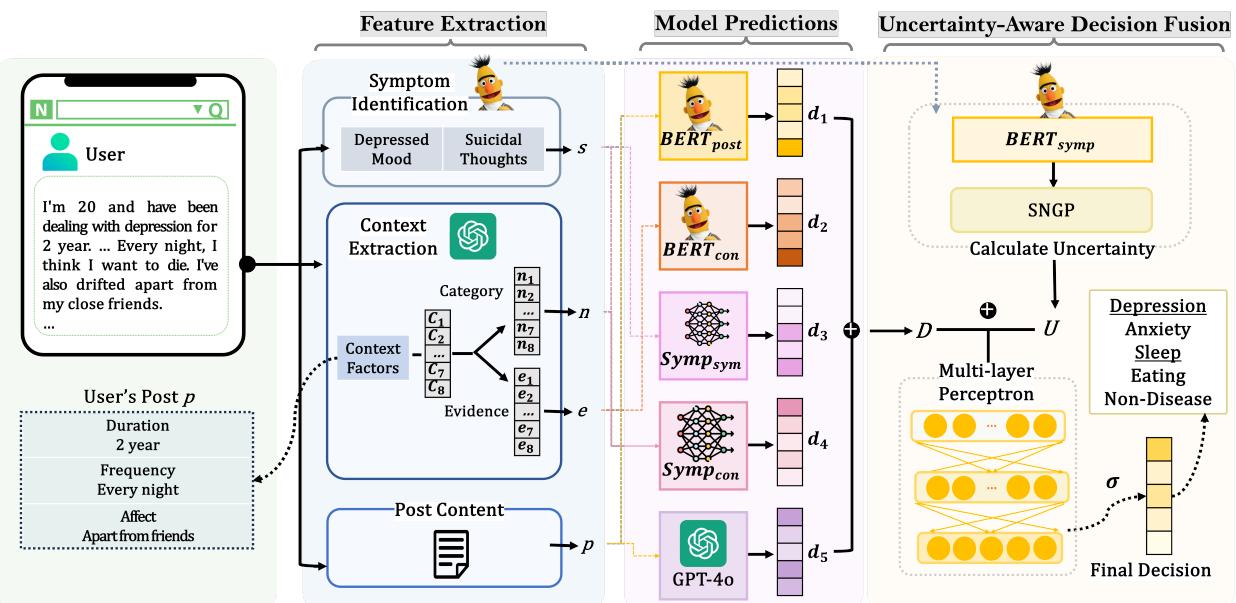
如 图 2 所示,该架构分为三个不同的阶段:
- 特征提取: 从文本中挖掘症状和语境。
- 模型预测: 使用多个子模型来分析这些特征。
- 感知不确定性的决策融合: 在考虑模型置信度的同时结合预测结果。
让我们逐步拆解这些步骤。
1. 特征提取
该模型从用户帖子中提取两类信息。
症状识别 首先,系统需要找到临床症状。研究人员使用了微调过的 BERT 模型。对于给定的帖子 \(p\),模型计算 28 种不同症状 (例如,“抑郁情绪”、“失眠”、“自杀念头”) 的可能性向量 \(S\)。
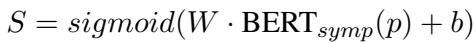
该方程本质上是将帖子的 BERT 表示通过一个分类器,以获得每种症状存在的概率。
通过大语言模型提取语境 这是 CURE 的创新之处。研究人员没有依赖简单的关键词匹配来获取语境,而是利用大语言模型 (具体为 GPT-4o) 提取精神科医生定义的八个特定语境因素:
- 起因 (Cause): 是否有特定的触发因素?
- 持续时间 (Duration): 这种情况发生了多久?
- 频率 (Frequency): 它发生的频率如何?
- 年龄 (Age): 用户多大年纪?
- 影响 (Affects) (4 种类型) : 它是否影响社交、学业、职业或危及生命?
研究人员使用“思维链 (Chain-of-Thought)”推理设计了特定的提示词 (Prompt) 来引导 LLM。


如上面的提示词所示,LLM 被要求对文本进行分类 (例如,持续时间: 0 表示未提及,1 表示 <1 个月,2 表示 >1 个月) 。这将非结构化文本转换为结构化的“语境类别”向量 (\(N\)) 和“语境证据”向量 (\(E\))。

2. 模型预测 (集成方法)
简单地将症状向量和语境向量拼接到一个模型中可能效率低下,因为这些特征的性质截然不同。相反,CURE 采用了五个子模型的集成,每个子模型从不同的角度观察数据:
- BERT-post: 查看帖子的原始文本。
- BERT-context: 使用 LLM 提取的语境证据。
- Symp-symptom: 仅使用症状可能性向量。
- Symp-context: 拼接症状向量和语境类别向量。
- GPT-4o: 来自 LLM 本身的直接预测。
这种多样性确保了如果一种方法失败 (例如,症状提取器遗漏了一个关键词) ,另一种方法 (例如,原始文本分析器) 可能会捕捉到它。
3. 感知不确定性的决策融合
这是拼图的最后一块,也许也是技术含量最高的一块。传统的深度学习模型通常“过度自信”——即使输入数据令人困惑或与它们之前见过的任何数据都不同 (分布外) ,它们也可能预测出很高的类别概率。
为了解决这个问题,研究人员使用了谱归一化神经高斯过程 (SNGP) 。 不深究数学细节的话,SNGP 是一种允许神经网络估计其预测不确定性的技术。
该框架专门为症状识别模型计算一个不确定性值 (\(U\))。然后,它使用多层感知机 (MLP) 将此不确定性与所有五个子模型的预测 (\(D\)) 进行融合。
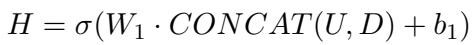
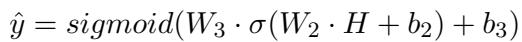
这里,\(H\) 是结合了预测 \(D\) 和不确定性 \(U\) 的隐藏层表示。最终输出 \(\hat{y}\) 是实际的诊断结果。
这为什么重要? 如果症状模型不确定 (高 \(U\)) ,融合网络学会减少对该模型的信任,并可能更多地依赖基于语境的子模型。
实验结果
研究人员将 CURE 与几个基线模型进行了比较,包括标准的 BERT 模型、其他基于症状的模型 (如 PsyEx) 以及原始 LLM (GPT-4o, MentalLLaMA) 。
性能比较
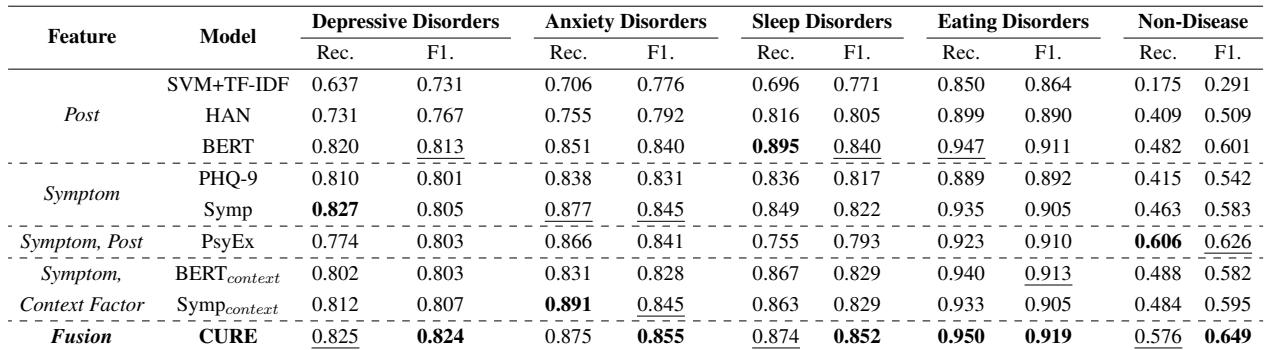
KoMOS 数据集上的结果令人印象深刻。下表重点列出了召回率和 F1 分数。
关键结论:
- 最佳整体性能: CURE 在几乎所有类别中都取得了最高的 F1 分数。
- 非疾病挑战: 看看“非疾病 (Non-Disease)”一列。大多数模型在这里都很吃力,因为它们倾向于过度诊断。CURE 明显优于其他模型 (F1 为 0.649,而次优模型为 0.626) ,证明语境有助于模型意识到何时不诊断障碍。
- 仅靠 LLM 是不够的: 有趣的是,虽然 GPT-4o 很强大,但直接用它进行诊断会导致高召回率但低精确率 (过度诊断) 。CURE 使用 LLM 进行特征提取 (语境) 而不是最终决策,这被证明更有效。
子模型的影响
使用五个不同的模型真的有帮助吗?研究人员进行了消融实验,一次移除一个模型,看看会发生什么。
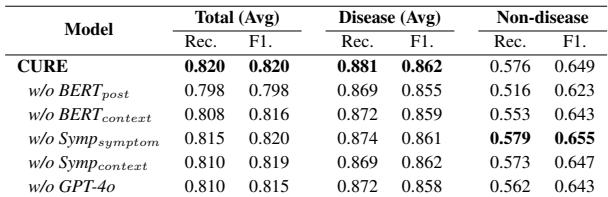
如 表 4 所示,移除任何单一子模型都会导致性能下降。值得注意的是,移除 BERT_post 或 BERT_context 对“非疾病”检测的损害最大。这证实了原始文本和语境证据对于过滤假阳性至关重要。
案例研究: 观察 CURE 的实际应用
为了具体说明这一点,让我们看看研究中的两个真实案例,在这些案例中 CURE 成功了,而其他模型失败了。
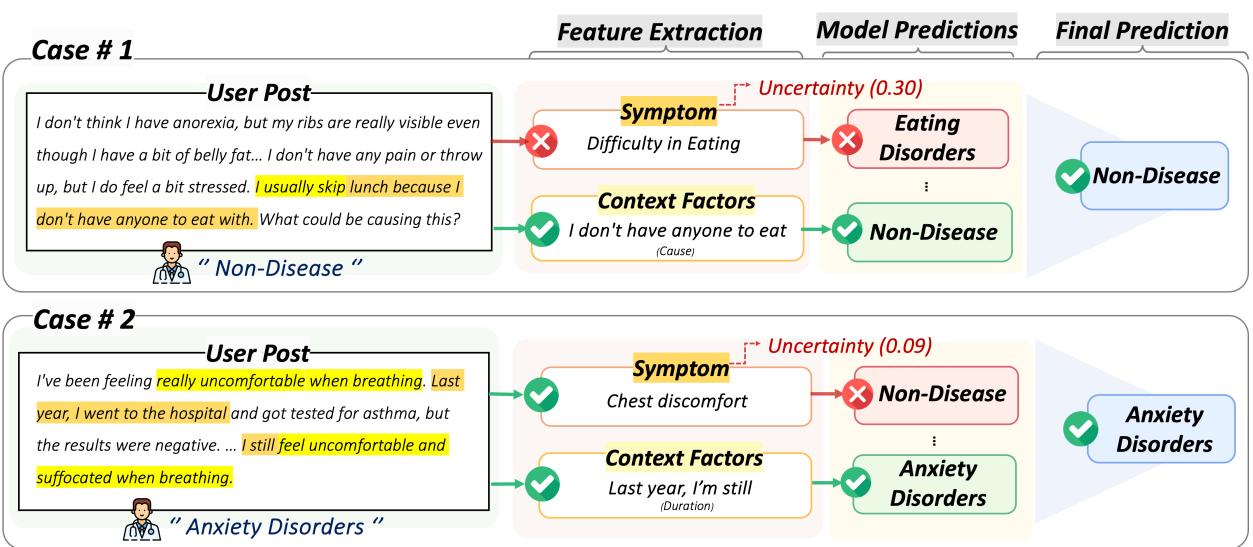
案例 #1 (左) :
- 用户发帖: “我不认为我有厌食症……通常不吃午饭是因为没人陪我吃。”
- 错误: 标准症状模型看到“不吃午饭”并标记为“进食困难”,预测为进食障碍 。
- CURE 的解决方案: 语境提取注意到了社交原因 (“没人陪我吃”) 。感知不确定性的融合权衡了相互矛盾的证据,并正确预测为非疾病 。
案例 #2 (右) :
- 用户发帖: “我呼吸时感到非常不舒服……从去年开始。”
- 错误: 症状模型看到了“胸部不适”,但错过了更广泛的情况,预测为非疾病 (可能认为这是身体问题) 。
- CURE 的解决方案: 语境提取强调了持续时间 (“从去年开始”) 。这种慢性特征结合症状,符合焦虑障碍 , 从而得出了正确的诊断。
结论
CURE 框架代表了自动化心理健康分析向前迈出的重要一步。通过超越简单的关键词定位并整合语境理解 (通过 LLM) 和不确定性量化 (通过 SNGP) ,该模型的运作方式更接近人类精神科医生。
这项工作的主要贡献是:
- 语境很重要: 区分暂时性痛苦和慢性障碍需要理解持续时间、频率和起因。
- 不确定性是有用的: 知道模型何时不确定,比盲目自信能做出更好的决策。
- KoMOS: 为韩国心理健康研究社区提供了一个有价值的、经专家标注的资源。
虽然目前主要关注韩语文本和四种特定障碍,但 CURE 背后的方法论——特别是混合使用 LLM 进行语境提取和感知不确定性的融合——是一个蓝图,可以应用于任何语言的心理健康检测。