](https://deep-paper.org/en/paper/file-2835/images/cover.png)
引言: 过度自信的机器
想象一下,当你向 AI 助手咨询医疗建议或法律先例时,它给出的回答反应迅速、语法完美,语气也极具权威性。但存在一个问题: 这个答案完全是编造的。
这种现象通常被称为“幻觉 (Hallucination) ”,它是将 LLaMA 或 GPT-4 等大型语言模型 (LLM) 应用于关键现实场景时的最大障碍之一。核心问题不仅仅在于模型会犯错——人类也会犯错。问题在于,LLM 往往缺乏能力去感知自己何时犯错了。它们经常表现得“错得理直气壮”。
对于人类来说,表达不确定性是很自然的。如果你对某个答案不确定,你可能会说: “我觉得是巴黎,但我只有 60% 的把握。”然而,标准的 LLM 很难准确地用语言表达这种内在的概率。
在一篇题为 “Can LLMs Learn Uncertainty on Their Own?” (LLM 能否自行学会不确定性?) 的精彩研究论文中,来自澳门大学和哈尔滨工业大学的研究人员提出了一种新颖的方法来解决这个问题。他们认为,我们可以教导 LLM 将其口头表达的置信度与其真实的正确概率对齐。结果如何?一个知道自己何时不知道的模型,从而能够在必要时寻求帮助——比如搜索网络。
在这篇文章中,我们将详细拆解他们的方法——不确定性感知指令微调 (UaIT) , 并探讨他们是如何实现不确定性表达能力 45.2% 的巨大提升的。
衡量不确定性的挑战
在深入探讨解决方案之前,我们需要了解为什么这很难。一直以来,衡量神经网络“不确定”程度的方法主要有两种:
- 语言化置信度 (Verbalized Confidence) : 简单地提示模型: “你确定吗?给我一个 0 到 100 的分数。”研究表明,LLM 在这方面通常表现很差;它们往往是过度自信的阿谀奉承者。
- 基于采样的估计 (Sampling-Based Estimation) : 你问模型同一个问题 10 次。如果它给出 10 个不同的答案,那它就是不确定的。如果它 10 次都给出相同的答案,那它就是自信的。虽然这种方法准确,但计算成本高昂,且对于实时聊天应用来说太慢了。
研究人员寻求一种“两全其美”的方法: 一个既能实时表达准确置信度 (像方法 1) ,又具有数学估计的可靠性 (像方法 2) 的模型。
解决方案: 不确定性感知指令微调 (UaIT)
该论文的核心思想是 自训练 (Self-Training) 。 研究人员意识到,他们可以利用缓慢但准确的方法 (采样) 来生成训练数据集,然后利用该数据集教导模型即时表达不确定性。
如下图 图 1 所示,该过程是一个包含三个阶段的流水线: 不确定性估计、指令微调和决策制定 。
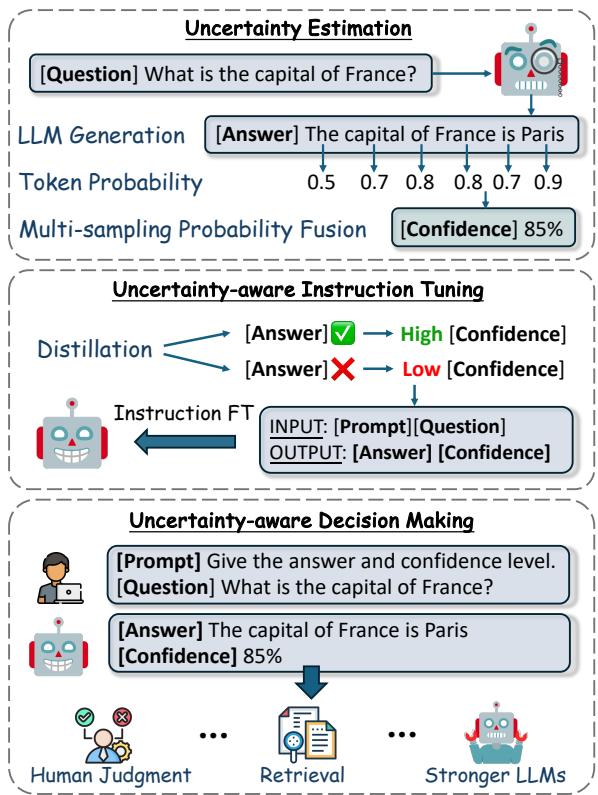
让我们详细拆解这些阶段。
第一阶段: “老师” (不确定性估计)
为了训练一个模型学会谦逊,我们首先需要不确定性的“真值 (ground truth) ”。研究人员利用了一种称为 SAR (Shifting Attention to Relevance,将注意力转移到相关性上) 的方法。
标准的不确定性测量通常关注 预测熵 (Predictive Entropy, PE) 。 这是一种计算模型对下一个词的概率分布有多“分散”的复杂说法。
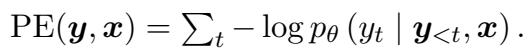
然而,SAR 认为并非所有的词都是平等的。如果模型对句子开头的“The”感到不确定,这无关紧要。但如果它对具体的实体“Paris”感到不确定,这就很重要了。
SAR 对标准熵进行了改进,它为每个 Token 计算一个相关性权重 (\(R_T\)) 。具体做法是从句子中移除一个 Token,看句意发生了多大变化。如果句意变化剧烈,则该 Token 具有高相关性。
Token 级 SAR 的方程结合了 Token 的概率及其语义相关性:
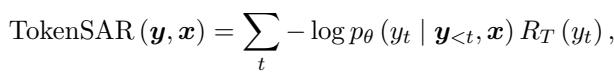
这里,\(R_T\) 代表相关性权重。研究人员通过比较包含和不包含该 Token 的句子的语义相似度来计算此相关性,数学定义如下:
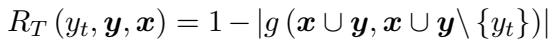
此外,他们利用 句子级 SAR 将其扩展到句子层面。通过采样多个答案 (比如 5 个不同的变体) 并进行比较,该算法会赋予那些与大多数其他生成答案语义相似的句子更高的置信度。
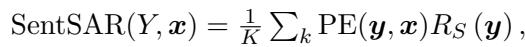
其中句子相关性 (\(R_S\)) 是通过将当前句子与其他采样句子的相似度相加计算得出的:
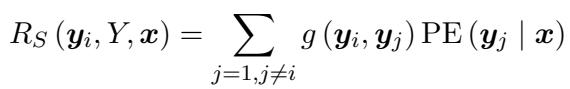
通过结合这些方法,研究人员为 LLM 生成的任何答案获得了一个高度准确但计算缓慢的“置信度分数”。这个分数将作为训练阶段的标签。
第二阶段: 课程 (数据蒸馏)
现在我们有了给置信度打分的方法 (“老师”) ,我们需要为“学生” (LLM 本身) 制作一本教科书。
研究人员使用了一个数据集 (TriviaQA) 并让 LLM 回答问题。然后,他们计算每个答案的 SAR 置信度分数。但仅仅把这些反馈给模型是不够的。他们应用了 蒸馏 (Distillation) 策略。
他们过滤数据,只保留最具指导意义的例子:
- 高一致性正确: 模型回答正确 且 计算出的置信度很高 (高于某个阈值,例如 80%) 的情况。
- 高一致性错误: 模型回答错误 且 计算出的置信度很低 (低于某个阈值) 的情况。
这种过滤移除了一些“令人困惑”的数据点,即模型可能只是侥幸猜对 (低置信度但正确) 或者虽然自信但错了 (幻觉) 。这为模型学习创造了一个清晰的信号: “这就是确定的感觉”以及“这就是不确定的感觉”。
第三阶段: “学生” (指令微调)
最后,研究人员对 LLM 进行微调。输入是用户的问题,目标输出是 答案 + 置信度分数 。
优化目标是最小化模型预测输出与这个精心策划的数据集之间的差异。
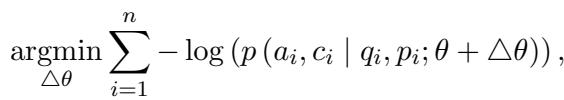
通过在带有精确数学标签的自身过往行为上进行训练,LLM 内化了不确定性的概念。它学会了将特定的内部状态——即当它缺乏知识时出现的神经元激活模式——与低百分比分数的输出联系起来。
实验与结果
这真的有效吗?研究人员在三个数据集上使用 LLaMA-2 和 Mistral 模型测试了这种方法: TriviaQA (常识) 、SciQA (科学) 和 MedQA (医学) 。
他们使用 AUROC (接收者操作特征曲线下面积) 作为主要指标。通俗地说: 如果你取一个正确答案和一个错误答案,AUROC 衡量的是模型给正确答案分配更高置信度分数的概率。
- 0.5 = 随机猜测。
- 1.0 = 完美校准 (总是对正确答案有更高的置信度) 。
校准能力的巨大提升
结果如下表所示,令人震惊。
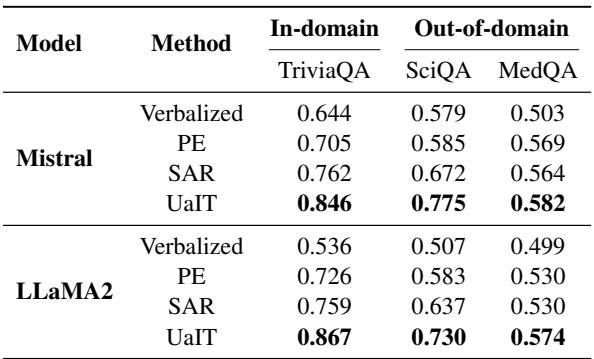
数据中的关键结论:
- 语言化置信度失效: 直接问原生模型“你确定吗?” (“Verbalized” 行) ,其 AUROC 分数仅在 0.5 或 0.6 附近。模型在自我评估方面几乎不比随机猜测好多少。
- UaIT 占据主导: 提出的方法 (UaIT) 在 TriviaQA 上实现了 0.846 和 0.867 的 AUROC 分数。这比基线有了巨大的提升。
- 青出于蓝: 令人惊讶的是,UaIT 的表现通常优于 SAR (用于生成训练标签的方法) 。通过从训练数据中归纳总结,模型学会了比提供的原始数学近似值更稳健的不确定性表示。
蒸馏的作用
第二阶段的过滤步骤有多重要?研究人员分析了不同的数据蒸馏阈值如何影响性能。
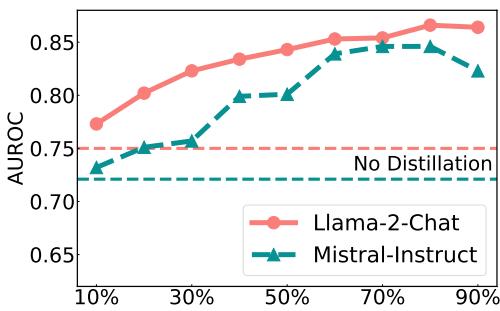
如 图 2 所示,随着蒸馏变得更加严格 (在 x 轴上向右移动) ,性能通常会提高。使用 85% 左右的阈值产生了最好的结果。这证实了在“干净”的信号 (准确性与置信度一致) 上进行训练对于模型的有效学习至关重要。
泛化能力
机器学习中的一个主要担忧是过拟合。如果我们在 TriviaQA 上训练模型,它是否只会估算琐事问答的不确定性?
回顾 表 1 , 我们可以看到 SciQA 和 MedQA 的列。尽管模型仅在 TriviaQA 上进行了微调,但它在科学和医学问题上仍保持了强劲的表现。这表明 UaIT 教会了模型一种可泛化的技能 : 内省自身知识的能力,而无论主题如何。
现实应用: 不确定性感知决策
我们为什么关心置信度分数?因为它允许我们构建更智能的 AI 系统。研究人员提出了一个决策框架,在该框架中,AI 根据其置信度采取不同的行动。
该逻辑形式化如下:
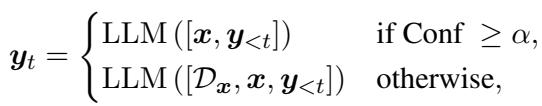
简单来说:
- 如果置信度 \(\ge\) 阈值: 立即输出答案。
- 如果置信度 < 阈值: 检索外部文档 (RAG) 或向更强 (更大) 的模型求助。
案例研究: 修正幻觉
研究人员提供了一个具体的实际案例。

在 表 5 中,模型最初认为是 “Ronald Haeberle” 揭露了美莱村大屠杀。然而,UaIT 标记出的置信度很低,仅为 49.7% 。 这个低分触发了检索步骤。模型阅读了一篇关于 Seymour Hersh 的外部文档,意识到了自己的错误,并将答案修正为 “Seymour Hersh”。
如果没有 UaIT,模型只会自信地陈述错误的名字。
决策制定中的定量成功
这不仅仅是一个孤立的例子。研究人员系统地测试了这一策略。他们设置了一个系统,在该系统中,置信度最低的 25%、50% 或 75% 的答案会触发检索步骤。
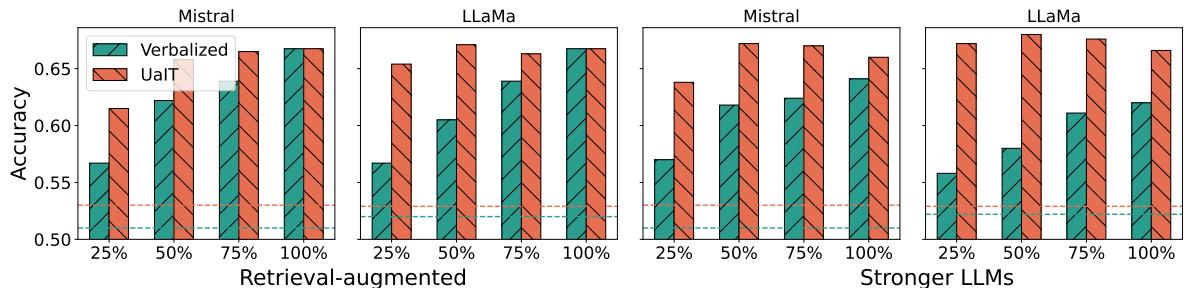
图 3 展示了结果:
- 青色柱状图 (Verbalized) : 依赖模型的标准置信度是不稳定的。
- 橙/红色柱状图 (UaIT) : 使用训练后的置信度能够持续带来更高的准确率。
值得注意的是,仅在 UaIT 指示低置信度 (“25%”标记处) 时检索信息,系统就能在不为每个查询都检索文档 (节省计算成本) 的情况下,实现显著的准确率提升。
结论与启示
论文 “Can LLMs Learn Uncertainty on Their Own?” 为构建可靠的 AI 迈出了令人信服的一步。通过使用“老师”算法 (SAR) 来标记数据,并使用“学生”过程 (指令微调) 来内化它,LLM 可以被教导去识别自身的局限性。
其影响是深远的:
- 效率: 我们可以在不需要昂贵的多重采样的情况下实时获得高质量的不确定性估计。
- 可靠性: 系统可以在困惑时自动“求助外援” (浏览网络) ,从而减少幻觉。
- 自我意识: 我们正朝着拥有功能性元认知——知道自己知道什么和不知道什么——的模型迈进。
对于 AI 开发者和学生来说,这突显了 校准 (calibration) 与 准确性 (accuracy) 同样重要。一个知道自己错了的模型,比一个认为自己总是对的模型要有用得多。