](https://deep-paper.org/en/paper/file-2856/images/cover.png)
引言: 教师的困境
如果你曾经教过课或指导过年轻同事,你就会明白其中的挣扎: 提供好的反馈很难。而大规模地提供好的反馈几乎是不可能的。
在教育界,反馈是进步的引擎。学生写文章,收到评论,然后 (希望如此) 修改作品使其变得更好。这个循环帮助学生培养批判性思维、自我评估能力以及对学科的掌握。然而,对于教育工作者来说,为几十甚至上百名学生提供详细、可执行且个性化的反馈是一个巨大的时间黑洞。
大型语言模型 (LLM) 登场了。像 GPT-4 和 Llama 这样的工具已经展示了令人难以置信的文本生成能力。自然地,教育科技领域热衷于利用这些模型来批改论文并提供反馈。但是存在一个巨大且经常被忽视的问题: 仅仅因为 AI 擅长写作,并不意味着它懂得如何教学。
目前大多数 AI 反馈系统都是通过提示 (Prompt) 来“扮演老师”,但我们实际上并不知道它们的反馈是否有助于学生进步。礼貌的建议比直接的纠正更有帮助吗?AI 是关注表面的语法问题还是深层的论证逻辑?
为了解决这个问题,来自密歇根大学和苏黎世联邦理工学院的研究人员提出了一种名为 PROF (PROduces Feedback,即生成反馈) 的新颖框架。他们的方法反转了剧本: 不再训练 AI 反馈看起来应该是什么样的,而是基于什么样的方法有效来训练它。为了在不对成千上万名真实学生进行实验的情况下做到这一点,他们构建了一个天才般的东西: 学生模拟器 (Student Simulators) 。
在这篇文章中,我们将深入探讨 PROF 论文,探索他们如何创建一个闭环系统,让 AI 老师向 AI 学生学习,从而产生不仅有效而且符合教学法的反馈。
核心问题: 有效性的“黑盒”
在理解解决方案之前,我们必须理解为什么训练 AI 提供反馈如此困难。
在标准的机器学习中,我们使用“基本事实 (Ground Truth) ”——即经过验证的正确答案来训练模型。如果我们想让模型分类猫的图片,我们会给它看成千上万张标记为“猫”的图片。但在写作教学中,并不存在单一的“正确”反馈。
- 主观性: 不同的老师侧重不同的方面 (语法 vs. 内容) 。
- 有效性的延迟: 我们只有在学生修改论文之后,才知道反馈是否有效。
- 数据稀缺: 我们有数百万篇论文,但包含 文章 \(\rightarrow\) 反馈 \(\rightarrow\) 修改后的文章 这种三元组的数据集非常少。
用真人收集这些数据既缓慢又可能涉及伦理问题 (你不想为了看会发生什么而给真实学生提供糟糕的实验性反馈) 。这就是 PROF 方法发挥作用的地方。
PROF 流程: 一个反馈循环
研究人员的假设简单而有力: 有效的反馈是由它所激发的修改质量来定义的。
如果 AI 建议了一个改动,结果文章变得明显更好了,那么这个反馈就是“好的”。如果结果文章变差了或没有变化,那么这个反馈就是“坏的”。
为了实现这一点,他们构建了一个包含两个主要 AI 代理 (Agent) 的流程:
- 反馈生成器 (The Feedback Generator) : 试图学习如何教学的模型。
- 学生模拟器 (The Student Simulator) : 一个受过训练、能够像学生修改作业一样行事的模型。

如图 1 所示,该过程在一个循环中运行:
- 初始写作: 过程始于一篇草稿文章 (\(x^j\)) 。
- 生成: 反馈生成器 (\(M_t\)) 查看文章并提出几条不同的反馈建议 (\(f_k\)) 。
- 模拟: 学生模拟器 (\(S\)) 接收文章和反馈,然后重写文章 (\(y_k\)) 。
- 评估: 一位“裁判” (在本例中是扮演论文评分员的 GPT-4) 对修改后的文章进行评分。
- 偏好建立: 系统识别哪条反馈导致了最好的修改 (\(f_+\)) ,哪条导致了最差的修改 (\(f_-\)) 。
- 优化: 更新反馈生成器,使其在未来更多地生成 \(f_+\),更少地生成 \(f_-\)。
这创造了一个自我改进的循环。模型不仅仅是在模仿人类老师;它正在针对学生修改的结果进行优化。
优化数学原理 (简化版)
训练机制使用了一种称为直接偏好优化 (Direct Preference Optimization, DPO) 的技术。与传统的强化学习 (需要创建一个复杂的奖励模型) 不同,DPO 直接根据偏好对 (更好 vs. 更差) 来优化语言模型。
目标是更新模型 (\(M_{t+1}\)) 以最小化损失函数:
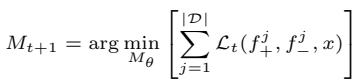
损失函数本身的设计目的是增加生成“获胜”反馈的概率,同时降低生成“失败”反馈的概率。它看起来像这样:
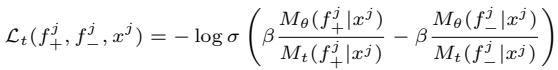
简单来说,这个方程式利用“模拟学生”的表现作为基本事实,促使模型区分有用的建议和无用的建议。
学生模拟器: 模拟课堂
整个 PROF 流程依赖于学生模拟器的真实性。如果模拟器盲目接受每一条建议 (即使是糟糕的建议) ,反馈生成器就会学会对学生指手画脚。如果模拟器过于随机,生成器将学不到任何东西。
研究人员使用来自经济学 101 课程的数据集训练了他们的模拟器 (使用 Llama-3-8b 和 GPT-3.5) 。数据包括初始论文、同伴反馈以及真实学生提交的最终修改论文。
模拟器有多像“人类”?
为了测试真实性,作者调整了模型的“温度 (Temperature) ”。在 AI 中,温度控制创造力或随机性。低温意味着模型是可预测的;高温则使其更加狂野。
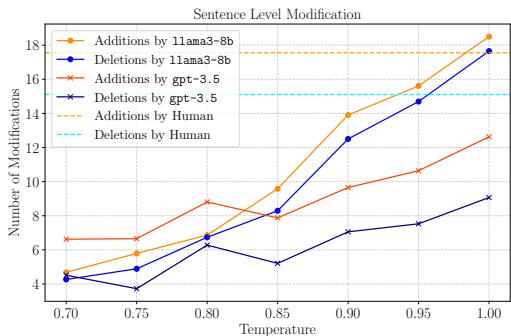
图 2 展示了一个有趣的趋势。随着温度升高 (x 轴) ,模拟器进行了更多的修改 (增加和删除) 。
- 虚线/点线 (AI 模拟器) 显示随着温度升高,修改量急剧增加。
- 水平线 (人类) 显示了真实学生行为的静态基准。
这告诉我们,我们可以“调节”模拟器以表现得像不同类型的学生——几乎不改动草稿的保守修改者,或者重写一切的激进修改者。
然而,数量不代表质量。模拟器真的改进了文章吗?
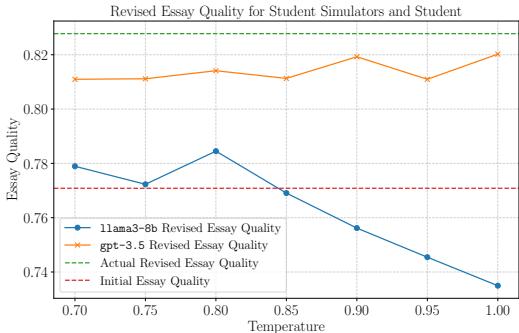
图 3 揭示了一个差距。顶部的绿色点线代表真实修改后的论文质量 (真实学生达到的水平) 。橙色 (GPT-3.5) 和蓝色 (Llama-3-8b) 线是模拟器。
- 结论: 真实学生在修改方面仍然比 AI 模拟器更好。他们更善于整合反馈以提高分数。
- 含义: 这实际上使 PROF 模型的训练更加困难。它必须提供非常好的反馈,才能让这些“固执”的 AI 模拟器提高分数。
忠实度: 模拟器听话吗?
研究中最有趣 (也最人性化) 的发现之一是关于“忠实度 (Faithfulness) ”的。仅仅因为你给了学生反馈,并不意味着他们会听。
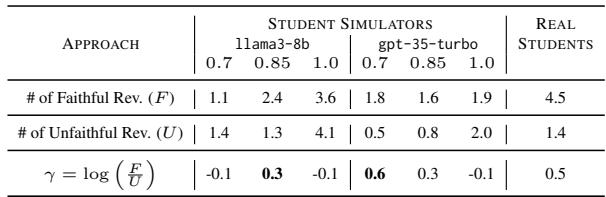
表 1 比较了“忠实修改” (按要求做) 与“不忠实修改” (做些随机的事) 。真实学生 (右栏) 通常有较高的忠实修改比例。模拟器,尤其是在较高温度下,倾向于“幻觉式修改”——进行未被要求的更改。研究人员必须仔细选择合适的温度 (0.85) ,以平衡真实性和响应性。
PROF 真的有效吗? (结果)
研究人员将他们的 PROF 模型 (基于相对较小的 80 亿参数 Llama-3 模型) 与巨头进行了对比: GPT-3.5 和 GPT-4 。
他们通过两种方式评估模型:
- 内在评估: 反馈在教学法上看起来好吗?
- 外在评估: 反馈实际上改进了文章吗?
1. 教学质量 (内在评估)
他们使用 GPT-4 根据四个教育标准来评判反馈:
- RGQ: 尊重引导性问题 (Respects Guided Questions - 是否遵循了作业评分标准?)
- EAL: 鼓励主动学习 (Encourages Active Learning - 是否让学生思考?)
- DM: 加深元认知 (Deepens Metacognition - 是否指出了错误和误解?)
- MSSC: 激发学生好奇心 (Motivates Student Curiosity - 语气是否积极/鼓励?)
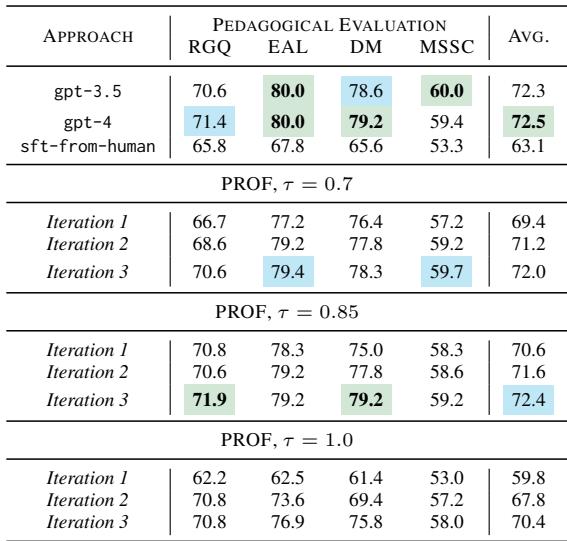
表 2 显示了结果。基线“sft-from-human” (在人类同伴互评数据上进行的监督微调) 得分很低 (平均 63.1) 。
- PROF (Iteration 3, \(\tau=0.85\)) 得分为 72.4 , 实际上与 GPT-4 (72.5) 持平,并击败了 GPT-3.5 (72.3) 。
- 关键见解: PROF 仅通过针对学生成果进行优化,就使用更小的开源模型达到了企业级的教学质量。
2. 执行效用 (外在评估)
这是真正的考验。他们提取了不同模型生成的反馈,将其输入给学生模拟器 (“测试”学生) ,并对最终的论文进行评分。
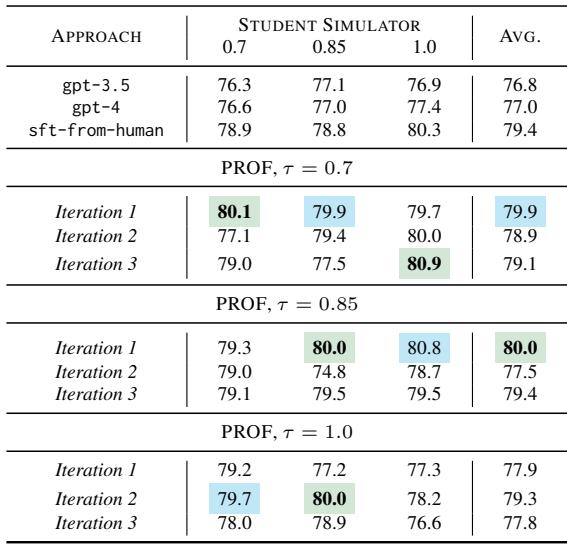
表 3 凸显了 PROF 方法的胜利。
- 绿色表示最佳表现; 蓝色为第二佳。
- PROF 在几乎所有指标上都持续优于 GPT-3.5 和 GPT-4 。
- 尽管 GPT-4 是一个更“聪明”的模型,但 PROF 经过专门优化以引发改进。它准确地学会了什么样的提示能触发更好的修改。
AI 学到了什么教学经验?
这项研究最深刻的一个方面是分析 PROF 模型在三次训练迭代中如何改变其行为。记住,研究人员并没有告诉模型“要友善”或“要严格”。模型纯粹是在追求更高的论文分数。
空洞表扬的消亡
教育心理学告诉我们,“空洞的表扬” (例如,“做得好!”,“好文章!”) 虽然让人感觉良好,但无助于学习。PROF 从数学上发现了这一点。
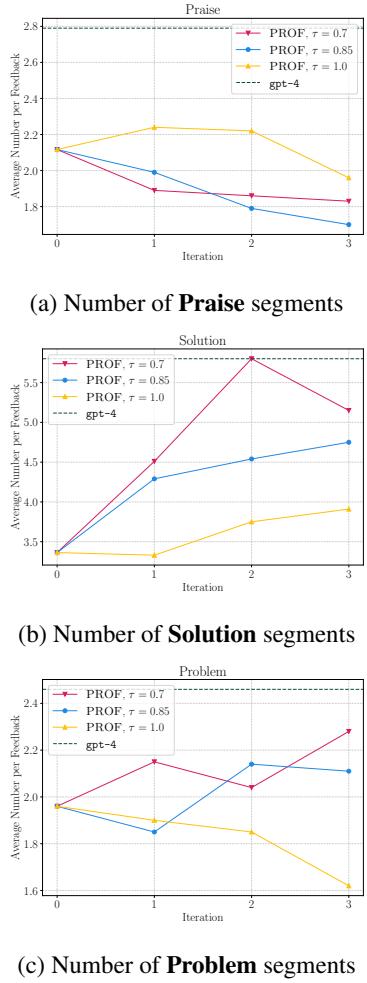
看图 4 中的 Chart (a) 。 随着模型训练的进行 (迭代 0 到 3) , 表扬片段 (Praise segments) 的数量 (品红/蓝/黄线) 显着下降。模型“学到”了浪费 Token 去恭维并不能提高最终的论文分数,所以它停止了这种做法。
相反,看 Chart (b) 。 解决方案片段 (Solution segments) (可执行的建议) 的数量激增。模型学到,要获得更高的分数,它必须提供具体的解决方案。
特异性很重要
研究人员还分析了反馈的“范围 (scope) ”——是模糊/全局的,还是具体/局部的。
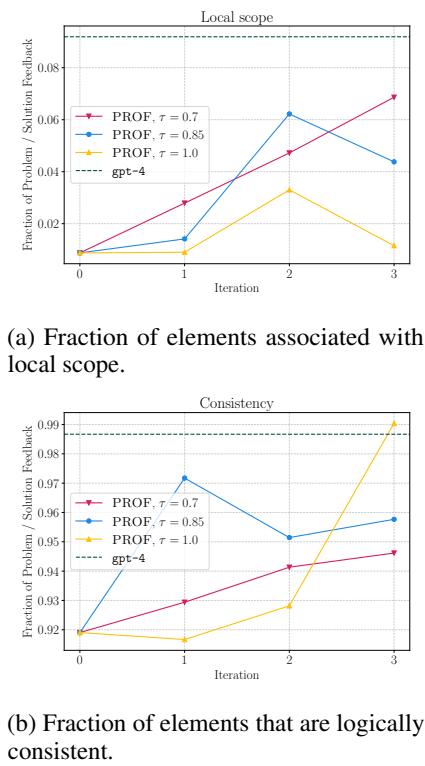
图 5 (a) 显示,PROF 学会了增加局部范围 (Local Scope) 的反馈 (针对特定的句子或单词) 。像“写出更好的论点”这样模糊的反馈对于模拟器 (以及真实学生) 来说很难执行。像“修改第 3 段中供给曲线的定义”这样具体的反馈则是可执行的。
此外, 图 5 (b) 显示反馈的逻辑一致性 (Logical Consistency) 随着时间的推移而提高。模型意识到提供矛盾或错误的建议会导致糟糕的修改,因此它自我修正以变得更具逻辑性。
结论与启示
PROF 论文代表了 AI 辅助教育向前迈出的重要一步。它超越了“AI 作为内容生成器”的范式,转向了“AI 作为结果优化器”。
通过闭环——使用模拟学生来测试教学效果——研究人员创建了一个符合实际教学目标的系统,而无需昂贵的人工标注。
主要收获:
- 基于结果的训练: 我们不仅可以训练 AI 听起来像老师,还可以训练它们像老师一样带来改变。
- 小模型也能赢: 一个专门的 80 亿参数模型 (PROF) 在特定的教学任务中超越了庞大的 GPT-4。
- 模拟是可行的: 虽然并不完美,“学生模拟器”足够准确,可以作为训练的代理,解决了教育 AI 中的数据瓶颈问题。
随着这些模拟器变得更加“像人” (也许通过加入拖延症或误解能力!) ,在其上训练的 AI 老师的质量只会越来越高。目前,PROF 向我们展示了,在未来的课堂里,老师可能是 AI,而它的第一个学生可能也是 AI。