](https://deep-paper.org/en/paper/file-2897/images/cover.png)
自然语言处理 (NLP) 通常处于工程学与语言学的交叉路口。一方面,我们拥有旨在高效处理文本的模型;另一方面,我们面对的是关于人类语言如何实际运作的深奥且复杂的理论。连接这两个世界最成功的尝试之一就是 通用依存库 (Universal Dependencies,简称 UD) 。
UD 是一个庞大的全球性计划,旨在为所有人类语言的语法 (句法) 创建一种标准的标注方式。如果你正在训练一个解析器来理解句子结构,你很可能就在使用 UD。然而,尽管名为“通用”,UD 却因在语言类型学家 (研究跨语言结构相似性和差异性的学者) 眼中并非真正“通用”而面临批评。
在论文 “Contribution of Linguistic Typology to Universal Dependency Parsing” (语言类型学对通用依存句法分析的贡献) 中,研究员 Ali Basirat 探讨了一个迷人的问题: 如果我们修改 UD 以严格遵循语言类型学原则,会让计算机更容易解析语言吗?
答案是一个令人信服的“是”。这篇文章将带你了解当前标准存在的问题、提出的基于类型学的解决方案,以及表明更好的语言学理论能带来更佳工程效果的实证结果。
问题所在: 通用依存库真的“通用”吗?
自 2014 年发布以来,通用依存库已成为形态句法标注的标准。它的目标是提供一种一致的标注方案,以便在英语上训练的解析器可能与在波斯语或芬兰语上训练的解析器共享结构逻辑。
然而,包括语言学家 William Croft 在内的批评者认为,UD 偏离了 类型学原则 。 类型学是研究语言共性 (在大多数或所有语言中都成立的模式) 的学科。批评者认为,UD 往往依赖于特定语言的策略 (通常偏向于欧洲语言) ,而不是真正通用的语法功能。
例如,UD 可能会根据英语如何通过形态学 (使用特定的词形) 来处理某种关系来进行标记,而类型学方法则关注该关系的 功能,无论特定语言是如何编码它的。
Croft 等人 (2017) 提出了一项针对 UD 的修订方案以修复这些理论上的缺陷。然而,在这项研究之前,尚不清楚这种理论上的纯粹性在实践中是否真能帮助 NLP 模型。一个更“符合语言学正确性”的树库 (treebank) 对 AI 来说是更难学还是更容易学?
解决方案: 基于类型学的转换
研究人员通过对现有的 UD 树库应用一种转换来测试这一点。他们将这种新方案称为 TUD (类型学通用依存库,Typological Universal Dependencies) 。
需要注意的是,这种转换从根本上改变了依存关系的 标签 (单词之间关系的名称) ,但保留了 拓扑结构 (树结构的实际形状) 。
该转换基于 Croft 提出的四个设计原则:
- 区分通用结构: 避免基于特定语言策略 (如英语的系词) 的标签。
- 相同功能使用相同标签: 如果两个结构起到相同的句法作用,它们应拥有相同的标签。
- 优先考虑信息包装: 将提供相似类型信息的修饰语归为一个标签,以创建一个更经济的标签集。
- 尊重依存等级: 根据层级区分论元 (arguments) 、修饰语 (modifiers) 和次要谓语 (secondary predicates) 。
转换的可视化
为了实施这些原则,研究人员设计了一个脚本,将标准 UD 标签转换为 TUD 标签。这涉及两种类型的操作: 合并 (Consolidation) (将多个 UD 标签合并为一个 TUD 标签) 和 分裂 (Fragmentation) (将一个 UD 标签拆分为多个 TUD 标签) 。

如 图 1 所示,转换逻辑从原始 UD 标签 (左/底部节点) 流向新的 TUD 标签 (目标节点) 。让我们分解图中说明的最关键的变化:
1. “主语”的合并
在标准 UD 中,主语被分为名词性主语 (nsubj) 和从句主语 (csubj) 。然而在类型学上,主语的功能就是主语,无论它是一个名词短语还是一个从句。
- 转换规则:
nsubj+csubj\(\rightarrow\)sbj - 原因: 这遵循了“相同功能使用相同标签”的原则。
2. “宾语”的简化
UD 区分直接宾语 (obj) 和间接宾语 (iobj) 。Croft 认为这种区分对于信息包装来说往往是多余的。
- 转换规则:
iobj+obj\(\rightarrow\)obj* - 原因: 这简化了标签集。当直接宾语与间接宾语的区别对依存结构并非绝对必要时,解析器不再需要纠结于两者之间的歧义。
3. “修饰语”的归并
也许最激进的合并涉及修饰语。UD 对限定词 (det) 、数词修饰语 (nummod) 和形容词修饰语 (amod) 有特定的标签。
- 转换规则:
det+nummod+amod\(\rightarrow\)mod - 原因: 这些都服务于修饰名词这一广泛功能。通过将它们分组,模型可以关注中心语-依存项 (head-dependent) 的关系,而不是依存项的具体词性类别。
4. “副词”的分裂
虽然之前的规则是合并标签,但对副词的处理增加了复杂性。UD 将几乎所有副词都归为 advmod。然而,副词的功能千差万别——有的表示方式 (“迅速地”) ,有的表示程度 (“非常”) ,有的表示情态 (“可能”) 。
- 转换规则:
advmod分裂为sec(方式/次要谓语) ,qlfy(程度/限定) ,aux(体/情态) ,和obl(位置/时间) 。 - 原因: 这尊重了“依存等级”原则。它试图捕捉一种语义现实,即方式副词的功能与情态副词不同。
实验设置
为了确定 TUD 在解析方面是否确实优于 UD,作者进行了严格的实证调查。
数据
他们从 UD 2.12 集合中选择了 20 种语言 , 涵盖了不同的语系,包括印欧语系 (英语、波斯语、印地语) 、亚非语系 (阿拉伯语) 、汉藏语系 (汉语) 和乌拉尔语系 (芬兰语) 。这种多样性对于确保结果不仅仅是某种特定语言类型的假象至关重要。
模型
他们训练了两种最先进的依存句法解析器:
- 基于转移的解析器 (UUParser): 一步步构建解析树。
- 基于图的解析器 (Biaffine): 对单词之间每条可能的边进行评分,并找出最佳树结构。
指标
使用的主要指标是 LAS (Labeled Attachment Score,带标签的依存连接分数) 。 这衡量了解析器正确预测 中心语 (父词) 和 标签 (关系类型) 的单词百分比。
对照组: 随机转换
这是研究设计的一个关键部分。由于 TUD 涉及合并许多标签 (合并操作) ,标签的总数减少了。通常,当可供选择的类别较少时,分类任务会更容易。
为了证明改进归功于 语言类型学 而不仅仅是因为 标签更少 , 研究人员创建了一个“随机” (RND) 基线。他们随机合并和拆分标签,以匹配 TUD 转换的统计“影响率”。如果 TUD 击败了 RND,我们就知道是语言学逻辑在提供价值,而不仅仅是数学概率。
结果: 类型学有帮助吗?
结果验证了 Croft 的类型学框架。转换后的 TUD 树库通常比原始 UD 树库更容易解析。
整体性能提升
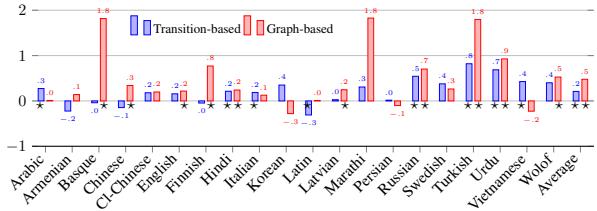
图 2 显示了测试语言中 LAS 的绝对提升 (或下降) 。蓝色条代表基于转移的解析器,红色条代表基于图的解析器。
- 正面影响: 对于绝大多数语言,条形图都是正向的,表明 TUD 提高了准确性。
- 基于图的收益: 基于图的解析器 (红色) 获得了显著的收益,某些语言的提升甚至达到了 2 个点。
- 统计显著性: 条形图旁边的数字代表 LAS 的变化。在印地语、意大利语和英语等语言中,这种提升具有统计学显著性。
- “预言机”潜力: 研究人员指出,如果转换能够被完美预测,潜在的收益高达 3.0 个 LAS 点。模型实际上实现了其中约 0.5 个点,这表明虽然该方案更好,但这种转换对机器来说学习起来仍很复杂。
与随机基线对比
至关重要的是,当与 RND (随机) 基线进行比较时,TUD 始终优于它。这证实了标签的 语义和功能分组 才是辅助解析器的关键。简单地合并随机标签并不能产生同样的效益,证明了类型学原则与 AI 试图学习的潜在结构是一致的。
为什么有效?分析规则
并非所有的转换都是生而平等的。该研究剖析了哪些具体的规则变更促成了成功,哪些损害了性能。
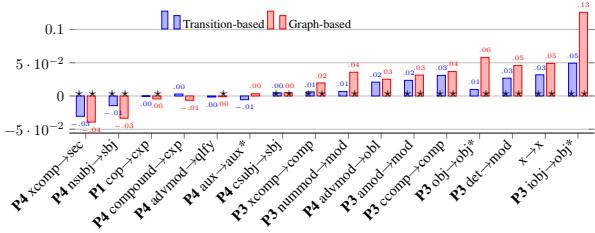
图 3 分解了单个转换规则的贡献。这张图表非常有启发性,因为它突出了 合并 和 分裂 之间的张力。
赢家: 合并规则
看图 3 的右侧。具有最高正向影响的规则几乎全是合并规则:
iobj -> obj*(+0.13): 合并间接宾语和直接宾语是最大的赢家。在许多语言中,这种区别是微妙且结构模糊的。消除这种区别使解析器能够专注于 它是一个宾语 这一事实,而不是它是哪种 类型 的宾语。ccomp -> comp: 合并从句补足语也提供了强大的推动力。det -> mod&amod -> mod: 将限定词和形容词简单地视为“修饰语”,显著帮助了基于图的解析器。
这些合并之所以有效,是因为它们减少了“噪声”。它们将功能相似的项目分组,使神经网络的决策边界更加清晰。
输家: 分裂规则
现在看图 3 的左侧。损害性能的是分裂规则:
advmod -> qlfy/xcomp -> sec: 这些规则试图将副词和补足语拆分为更细粒度的语义类别 (如区分方式副词和程度副词) 。- 问题所在: 虽然在语言学上是准确的,但仅凭句法很难预测这些区别。如果没有明确的形态标记 (这在数据中经常缺失或不一致) ,解析器很难猜测出现了哪种特定的副词子类型。
这这就产生了一个权衡。类型学建议我们 应该 做出这些区分,但如果没有更丰富的数据 (如广泛的形态特征) ,解析器会发现这些很难学习。
结论与启示
这项研究为语言学理论在现代 AI 中的作用提供了有力的论据。在这个“更多数据”通常被视为默认解决方案的时代,Basirat 的工作表明,“更好的数据设计”同样强大。
通过将通用依存库方案与语言类型学原则相一致——特别是通过基于功能和信息包装对标签进行分组——我们可以创建不仅在理论上更合理,而且在实践中更容易被机器解析的树库。
主要要点:
- 类型学很重要: 将标注方案与跨语言共性相对齐,可以提高计算性能。
- 合并有帮助: 合并具有相同功能的标签 (如不同类型的宾语或修饰语) 通过减少歧义显著提高了准确性。
- 分裂有风险: 如果底层数据缺乏形态线索来支持这些区分,拆分标签以捕捉语义细微差别 (如副词类型) 可能会损害性能。
论文最后建议,未来版本的通用依存库可以从采纳这些类型学见解中受益。虽然全面彻底地改革 UD 将是一项巨大的工程,但这项研究证明,理论语言学和计算解析之间的桥梁在结构上是坚固的——并且非常值得跨越。