](https://deep-paper.org/en/paper/file-2930/images/cover.png)
想象一下,你的朋友告诉你: “我跟邻居挥手,但他没回我。他一定很讨厌我。”作为人类,你可能会意识到这在逻辑上有点跳跃——也许邻居只是没看见。在心理学中,这被称为认知扭曲 (Cognitive Distortion, CoD) ——一种夸大或非理性的思维模式,它会延续负面情绪,通常与焦虑和抑郁有关。
虽然识别这些扭曲是认知行为疗法 (CBT) 的关键部分,但理解这些扭曲背后的推理过程才是真正实现突破的关键。
在最近的一篇论文中,来自印度理工学院巴特那分校 (IIT Patna) 和焦特布尔分校 (IIT Jodhpur) 的研究人员介绍了一个突破性的框架,称为 ZS-CoDR (零样本认知扭曲检测与推理) 。这个系统不仅仅是将一个句子标记为“扭曲”;它会观察患者的面部表情,倾听他们的声音,阅读对话记录,然后解释为什么这种想法是扭曲的。
在这篇文章中,我们将详细剖析这个多模态大语言模型 (LLM) 框架是如何工作的,为什么它优于纯文本模型,以及它如何重塑心理健康分析。
问题所在: 仅有检测是不够的
在心理健康自然语言处理 (NLP) 领域,现有的模型大多侧重于分类。它们获取像“我彻底失败了”这样的句子,然后输出一个二元标签: 认知扭曲: 是。
虽然这有帮助,但对于临床环境来说还不够。治疗师需要了解背景。患者是否在灾难化思维?他们是否陷入了“非黑即白”的思考模式?是什么触发了这个想法?
为了弥合人工智能与临床应用之间的鸿沟,我们需要能够提供可解释性的系统。如下图所示,一个真正有用的系统不仅能识别情绪、检测扭曲,还能提供一个推理模块,解释患者是将缺乏证据的情况解读为对自己不利的偏见确认。
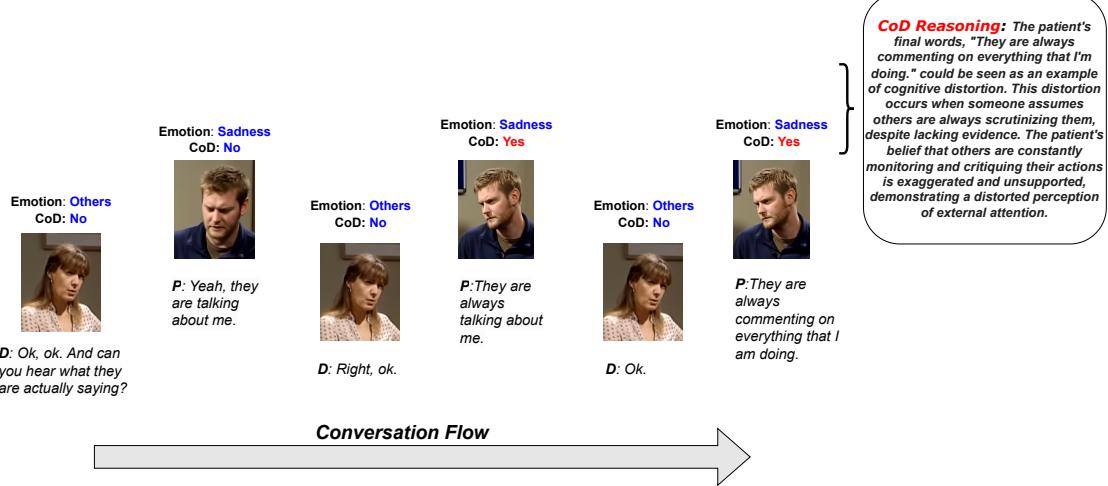
研究人员解决了两个巨大的挑战来实现这一目标:
- 数据匮乏: 缺乏包含医生与患者对话的大规模数据集,且这些数据需要同时标注扭曲及其背后的推理。
- 模态鸿沟: 讽刺、犹豫和痛苦通常存在于声音的语调或面部表情中,而不仅仅是文字。纯文本模型会遗漏一半的信息。
解决方案: ZS-CoDR 框架
提出的解决方案是 ZS-CoDR 。 顾名思义,它代表: 零样本 (Zero-Shot) 认知扭曲检测 (Cognitive Distortion detection) 与推理 (Reasoning) 。 “零样本”意味着该模型无需针对每种可能的扭曲场景进行成千上万个特定样本的训练,而是依靠其泛化的理解能力来执行这些任务。
架构
该框架非常复杂,集成了三种不同类型的数据 (模态) : 视频、音频和文本 。 在深入拆解之前,让我们先通过可视化来了解其架构。

1. 编码器: 处理感官信息
系统首先需要“看”到和“听”到对话。它使用了三个独特的编码器:
- 文本编码器 (LLaMA-7B): 处理对话的文字记录。
- 音频编码器 (WHISPER): 研究人员使用了 WHISPER 模型,这是一种最先进的多语言语音识别模型。它将声波转换为丰富的特征表示。
- 视频编码器 (3D-ResNet-50): 这部分很有趣。为了理解面部表情和肢体语言,系统使用了一个 3D-ResNet。
为了使视频编码器有效工作,研究人员利用了时空对比学习 (Spatiotemporal Contrastive Learning) 框架。简单来说,模型通过比较视频片段进行学习。如果两个片段来自同一个视频段,而模型认为它们不同,就会受到惩罚;如果模型识别出它们相似,就会得到奖励。这是通过 InfoNCE 损失函数实现的:
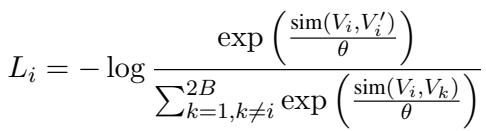
这种数学压力迫使视频编码器学习随时间变化的患者视觉行为的稳健表示。
2. 模态对齐: 讲同一种语言
这是最大的技术障碍: 声波和视频帧在数学上与文本 token 截然不同。你不能简单地将原始视频数据输入到设计用于处理文本的大语言模型中。
为了解决这个问题,研究人员采用了交叉注意力 (Cross-Attention) 机制。该机制将音频和视频特征与 LLM 的文本嵌入空间对齐。它本质上是将“视觉上的悲伤”或“声音的颤抖”转化为 LLM 能够与文字一起理解的向量格式。
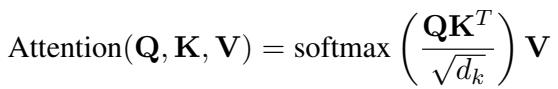
音频和视频特征 (\(h'_a\) 和 \(h'_v\)) 与 LLM 的嵌入矩阵 (\(E\)) 进行对齐。
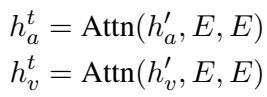
一旦对齐,这些特征会被连接 (concatenated) 在一起,形成一个多模态上下文 (Multimodal Context) 。 这个上下文向量包含了对话的内容 (文本) 、方式 (音频) 和外观 (视频) 。
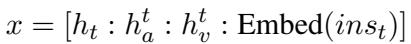
3. 分层过程
ZS-CoDR 框架并没有试图一次性完成所有工作。它通过分层方法模仿人类的认知过程:
- 任务 1: 检测与情绪: 多模态上下文被输入到第一层 LLM。它预测:
- 是否存在认知扭曲? (是/否)
- 情绪是什么? (例如,悲伤、恐惧、愤怒)
- 任务 2: 推理生成: 如果检测到扭曲,系统会将上下文、预测标签和预测情绪传递给第二层 LLM。这一层被提示生成“原因”。
这种分离确保了推理生成建立在准确检测的基础上,从而改善了输出的逻辑流。
数据: 创建 CoDeR
没有基准事实 (ground truth) 就无法验证推理模型。研究人员从现有的名为 CoDEC 的数据集开始,该数据集有扭曲标签,但缺乏解释。
他们对其进行了扩充,创建了 CoDeR (认知扭曲检测与推理) 数据集。他们聘请了专家标注员,针对为什么特定话语是扭曲的编写了详细理由。
这项任务的复杂性可以从数据集生成的词云中看出。推理词汇 (图 5) 充满了心理学术语,如“信念 (belief) ”、“感知 (perception) ”、“负面 (negative) ”和“证据 (evidence) ”。

实验与结果
添加视频和音频真的有帮助吗?分层结构有效吗?研究人员将 ZS-CoDR 与多个基线进行了比较,包括标准的纯文本模型和其他多模态系统。
定量成功
结果令人信服。ZS-CoDR 在几乎所有指标上都优于基线。
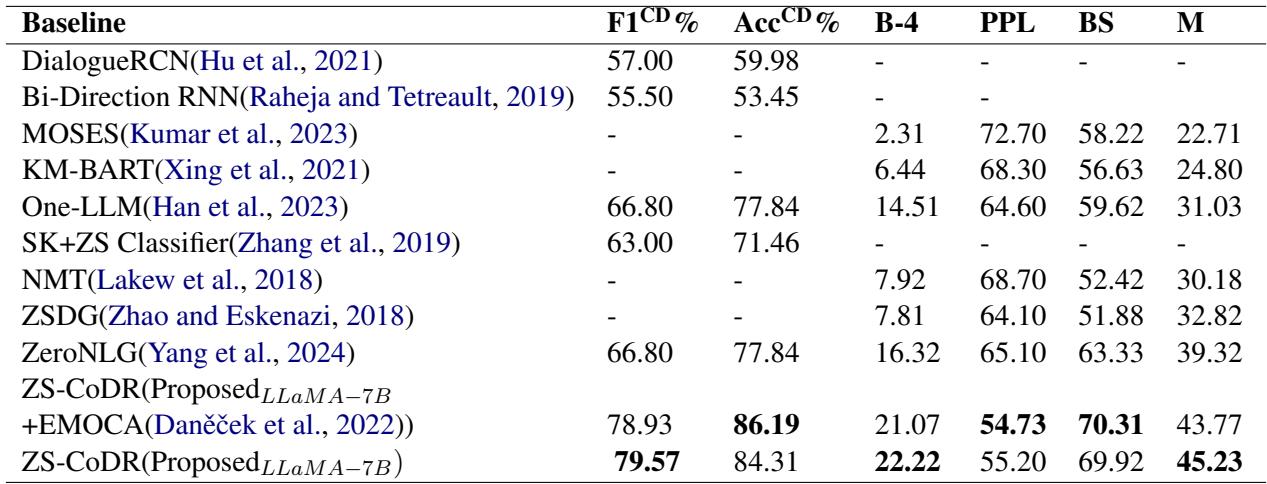
在上表中,请关注 F1 分数 (用于检测准确性) 和 BLEU-4/BERTScore (用于生成的推理质量) 。提出的多模态方法 (底部几行) 显着击败了像 ZeroNLG 这样的标准基线。
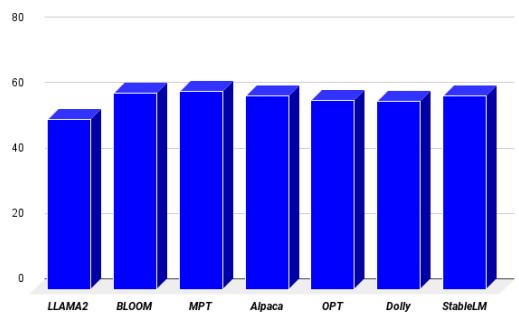
研究人员还测试了不同的 LLM 主干 (如 OPT、Bloom 和 Alpaca) ,看看哪个“大脑”效果最好。 LLaMA-7B 证明是执行此任务的卓越引擎,实现了最低的困惑度 (perplexity,衡量模型的“困惑”程度;越低越好) 。
定性分析: “人性化”的触感
数字固然重要,但在心理健康领域,语言的细微差别最为关键。让我们看看基准事实、ZS-CoDR 模型和基线 (ZeroNLG) 之间的比较。
在下面的例子中,患者对信件和人们的欲望做出了逻辑跳跃。
- ZeroNLG 给出了一个模糊、通用的回应。
- ZS-CoDR (多模态) 生成了一个具体的解释: “由于仅基于字母排列的不准确解释,将同一话语识别为认知扭曲。”

事实证明,包含视频和音频至关重要。在消融研究 (研究人员移除一种模态以观察结果) 中,移除视频导致性能显着下降。这证实了面部线索——紧锁的眉头、缺乏眼神交流——是诊断思维扭曲的重要信号。
上下文长度很重要
另一个有趣的发现是对话历史的重要性。模型需要“回忆”多久以前的内容才能给出好的解释?
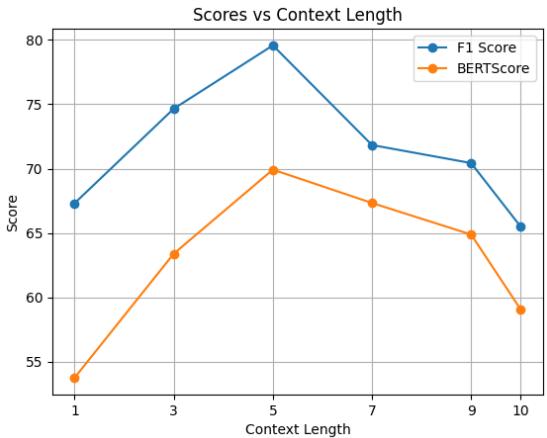
如图 7 所示,当模型考虑前 5 个话语时,性能达到峰值。如果上下文太短 (1 个话语) ,模型缺乏背景信息。如果太长 (10 个话语) ,模型会被无关的噪音分散注意力。
推理案例研究
为了充分欣赏该系统的能力,我们可以看看模型生成的具体推理示例。
在使用 OPT 主干的一个例子中,一位患者说: “我只是想自救。” 模型将其识别为扭曲,并解释说患者正在合理化他们的行为,以淡化更深层次的问题。

在使用 Alpaca 主干的另一个例子中,模型明确识别了 “情绪化推理 (emotional reasoning) ” (一种特定类型的扭曲,即认为如果自己感觉到了某种东西,那它一定是真的) 。患者说: “我现在知道那是真的”,指的是人们拿他们开玩笑。模型正确地识别出,患者仅基于自己的感受将玩笑解读为事实。

结论
ZS-CoDR 框架代表了情感计算领域向前迈出的重要一步。通过超越简单的文本分类,拥抱人类交流中复杂、多模态的本质,人工智能可以成为心理健康专业人士更有效的辅助工具。
这项研究的主要收获:
- 上下文是多模态的: 仅靠阅读文字记录无法完全理解患者的精神状态。视频和音频至关重要。
- 可解释性即安全性: 在医疗保健领域,“黑盒”人工智能是危险的。能够解释其推理过程的系统 (例如,“我标记这个是因为患者基于单一事件进行了过度概括”) 能建立信任。
- 分层设计行之有效: 将检测和推理分离成不同的步骤,模仿了人类的临床诊断过程,并产生了更好的结果。
随着大语言模型的不断发展,像 ZS-CoDR 这样的框架为人工智能助手铺平了道路,这些助手不仅能倾听,而且能真正理解我们思想背后复杂的“原因”。