](https://deep-paper.org/en/paper/file-2933/images/cover.png)
在人工智能飞速发展的世界中,大型语言模型 (LLM) 似乎已成为解决万物的“锤子”。自然而然地,研究人员将目光投向了推荐系统 (RecSys) 。其前提令人兴奋: 如果不只是预测产品的 ID,而是让 LLM 通过自然语言理解用户意图并“生成”推荐,会怎么样?
然而,简单地将 LLM 嫁接到推荐任务上并非即插即用。大多数研究集中在如何训练或微调这些模型上。但一篇名为 “Decoding Matters: Addressing Amplification Bias and Homogeneity Issue for LLM-based Recommendation” 的新论文指出,我们忽略了一个关键组件: 解码策略 。
研究人员揭示,标准解码方法 (直接借用自自然语言处理) 实际上正在破坏推荐质量。他们引入了一种名为 去偏-多样化解码 (Debiasing-Diversifying Decoding, \(D^3\)) 的新方法,修复了两个主要缺陷: 放大偏差和同质化问题。
在这篇深度文章中,我们将探讨为何标准解码在 RecSys 中会失效,并逐步拆解 \(D^3\) 解决方案。
背景: 生成式推荐
要理解这个问题,我们首先需要了解 LLM 如何推荐物品。在“生成式推荐”的设置中,模型会收到一个包含用户交互历史的提示词 (例如: “用户喜欢: 黑客帝国、盗梦空间…”) 。然后,模型被要求生成下一部观看电影的标题。
LLM 逐个 Token (词元) 地生成这个标题。为此,它通常使用 集束搜索 (Beam Search) , 这是一种解码算法,通过同时探索多个潜在序列来找到概率最高的输出。
在标准的 NLP 任务 (如翻译 or 摘要) 中,我们通常会对最终得分应用 长度归一化 (Length Normalization) 。 为什么?因为一个序列的概率是其所有 Token 概率的乘积。由于概率小于 1,较长的句子自然得分较低。长度归一化通过将总分除以序列长度,给较长的句子一个公平竞争的机会。
\[ S(h) = S(h) / h_{L}^{\alpha} \]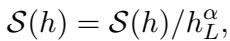
这个标准公式在翻译中效果奇佳。但正如我们即将看到的,它破坏了推荐机制。
两大元凶: 偏差与同质化
作者指出了生成自然语言与生成推荐物品之间的两个显著差异。当使用标准解码时,这些差异会导致严重的故障。
1. 放大偏差与“幽灵 Token”
第一个问题是 放大偏差 (Amplification Bias) 。 在自然语言中,词汇分布是巨大的。但在推荐中,模型通常是从一个受限的“物品空间”中生成特定的物品标题。
这导致了 幽灵 Token (Ghost Tokens) 现象。这些 Token 的生成概率接近 1。试想短语“Harry Potter and the Order of the…”,下一个 Token “Phoenix” 几乎是确定的。
在推荐系统中,许多物品包含这些幽灵 Token。它们对语义“得分”几乎没有贡献 (因为 \(\log(1) \approx 0\)) ,但它们确实增加了长度计数 (\(h_L\)) 。
陷阱就在这里:
- 一个物品包含许多幽灵 Token (它很长,但可预测) 。
- 它的原始概率得分没有下降多少,因为幽灵 Token 的概率很高。
- 然而 , 标准长度归一化将该得分除以了总长度。
- 结果呢?分母变大了,但分子保持不变。或者,如果归一化逻辑试图奖励长序列,这些物品仅仅因为啰嗦,得分就会被人为夸大。
作者将此称为 放大偏差 。 用于修复 NLP 中长度偏差的标准工具,实际上在 RecSys 中制造了新的偏差。
2. 同质化问题
第二个问题是 同质化 (Homogeneity) 。 LLM 是模式匹配机器。如果用户有与特定类型物品交互的历史,LLM 倾向于“复制”这些物品的文本特征。
例如,如果用户购买了“Sony PlayStation 3 手柄”,LLM 极有可能推荐“Sony PlayStation 4 手柄”或“Sony PlayStation 3 线缆”。虽然这些是相关的,但在文本上是重复的。集束搜索 (Beam Search) 加剧了这一点。因为相似的文本序列 (如 PS3 与 PS4) 共享许多高概率的初始 Token,“集束 (beams) ”都聚集在同一类型的物品周围。
结果是推荐列表缺乏多样性。用户得到的是同一产品的五个变体,而不是多样化的选择。
研究人员通过对比标准 RecSys 模型 (SASRec) 与基于 LLM 的模型 (BIGRec) ,可视化了这个问题。
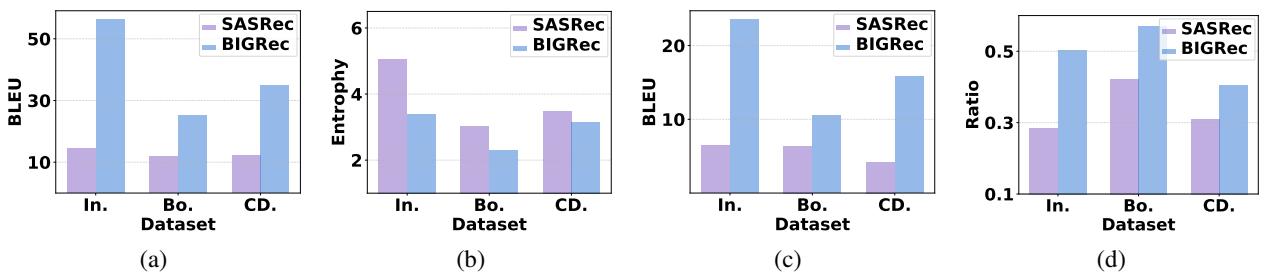
如上图 Figure 1 所示:
- (a) LLM 推荐 (蓝色柱) 的文本相似度 (BLEU 分数) 远高于传统模型 (紫色柱) 。
- (b) LLM 的类别多样性 (熵) 要低得多。
- (c & d) LLM 更倾向于重复用户历史记录中的文本和类别。
解决方案: 去偏-多样化解码 (\(D^3\))
为了修复这些问题,作者提出了一种新策略: 去偏-多样化解码 (Debiasing-Diversifying Decoding, \(D^3\)) 。 它从两个方面解决问题: 消除偏差和注入多样性。
第一步: 消除放大偏差 (去偏)
研究人员最初假设应该只对“非幽灵” Token 进行归一化。然而,经过分析,他们发现了一个有趣的现象: 如果忽略幽灵 Token,大多数物品的“信息长度”实际上非常均匀。
因此,如果幽灵 Token 是问题所在,那么对于推荐来说,实际上并不需要复杂的长度归一化公式。解决方案优雅而简单: 彻底移除长度归一化。
通过禁用归一化步骤 (公式 3) ,模型仅依赖原始累积概率。由于幽灵 Token 的概率接近 1 (对数概率接近 0) ,它们自然不会影响得分,也不再通过长度惩罚来扭曲排名。
第二步: 利用“无文本助手”修复同质化 (多样化)
消除偏差有助于提高准确性,但它不能解决 LLM 只是复制文本模式的“回声室”效应。为了解决这个问题,作者引入了一个 无文本助手 (Text-Free Assistant, TFA) 。
核心思想是将 LLM 与一个传统的、轻量级的推荐模型 (如矩阵分解或 SASRec) 配对,该模型对文本一无所知。这个模型只知道用户 ID 和物品 ID。它不会受到相似标题的偏见影响,因为它根本看不到标题。
\(D^3\) 方法在解码过程的每一步都混合了来自 LLM 和助手的得分。
首先,让我们看看助手如何对 Token 进行评分。由于助手预测的是物品而不是 Token,作者聚合了所有匹配当前 Token 前缀的物品的概率:
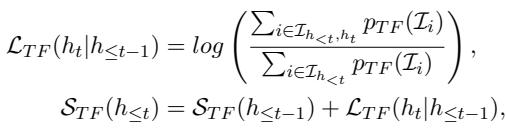
在上式中,\(\mathcal{L}_{TF}\) 代表无文本模型提供的得分。它计算当前 Token 序列通向一个好物品的可能性,这纯粹基于协同过滤信号 (用户行为) ,而非文本模式。
最后,用于集束搜索的总分是 LLM 得分和助手得分的加权和:
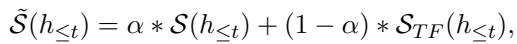
这里,\(\alpha\) 是控制平衡的超参数。
- 如果 \(\alpha = 1\),我们仅依赖 LLM (高文本偏差) 。
- 随着我们将 \(\alpha\) 调低,我们从协同过滤模型中引入了更多多样性。
这迫使 LLM 考虑那些行为上相关 (用户购买过) 但在文本上不相似 (拼写不同) 的物品。
实验与结果
作者在六个来自亚马逊的真实数据集 (乐器、CD、游戏、玩具、体育、书籍) 上测试了 \(D^3\)。他们将该方法与包括标准序列推荐模型 (SASRec) 和其他生成式 LLM 方法 (TIGER, BIGRec) 在内的强基线进行了比较。
准确性表现
结果令人印象深刻。通过简单地改变模型的解码方式 (无需重新训练庞大的 LLM) ,\(D^3\) 始终优于基线。
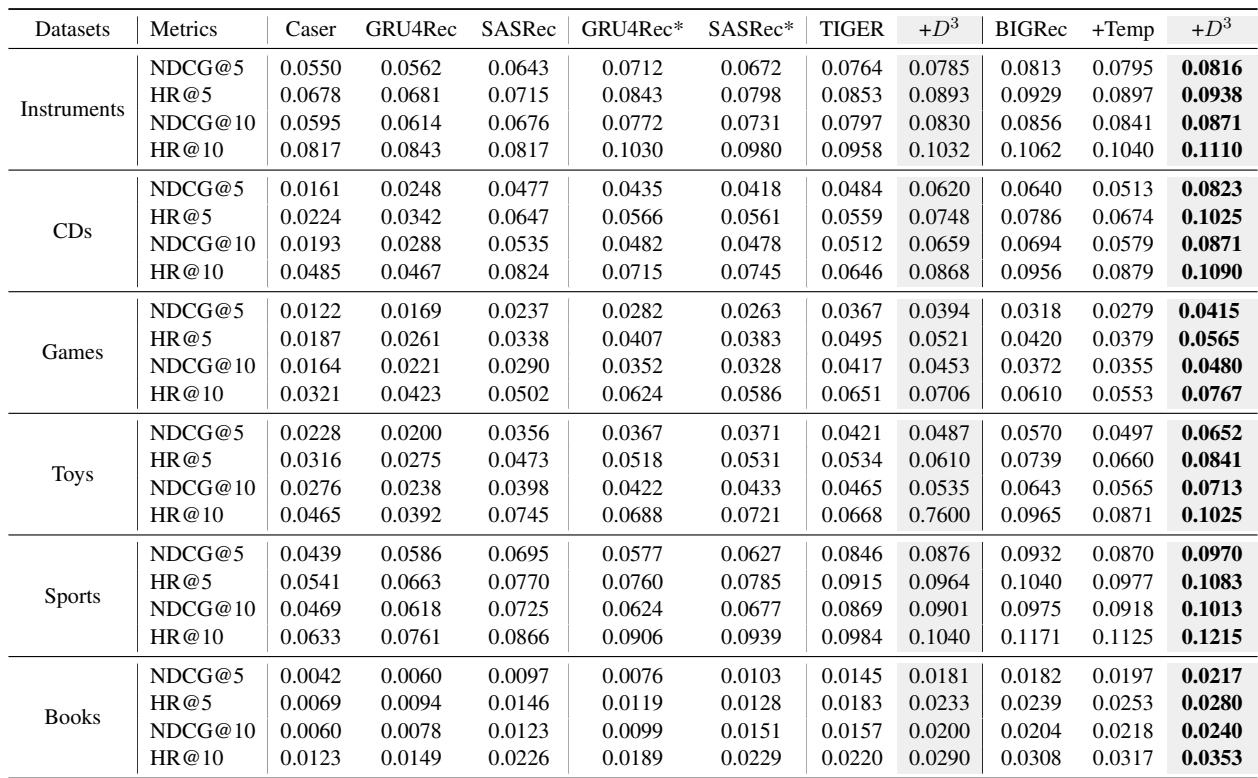
Table 1 强调了几个关键结论:
- 标准 LLM 的表现 (BIGRec) 不错,但 \(D^3\) 更好。 在所有数据集上,加入 \(D^3\) (
+D3列) 都提高了命中率 (HR) 和 NDCG 分数。 - 它适用于不同模型。 他们将 \(D^3\) 应用于 TIGER (另一种生成模型) 并看到了类似的增益,证明了该方法的通用性。
- 温度缩放是不够的。
+Temp列显示了他们试图仅通过增加 LLM 的随机性 (温度) 来增加多样性的结果。虽然这可能会提高多样性,但它损害了准确性。\(D^3\) 则两者兼得。
消融实验: 我们需要这两个部分吗?
仅仅移除长度归一化够吗?或者我们真的需要助手吗?作者进行了消融实验来找出答案。
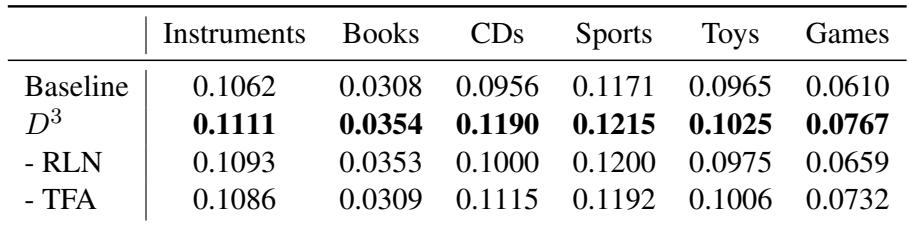
在 Table 2 中:
- - RLN (禁用“移除长度归一化”步骤) : 性能下降。这证实了放大偏差是真实的并且正在损害模型。
- - TFA (移除无文本助手) : 性能下降。这证实了来自助手的协同信号对于引导 LLM 找到更好的物品至关重要。
分析多样性
无文本助手的主要目标是解决同质化问题。它起作用了吗?
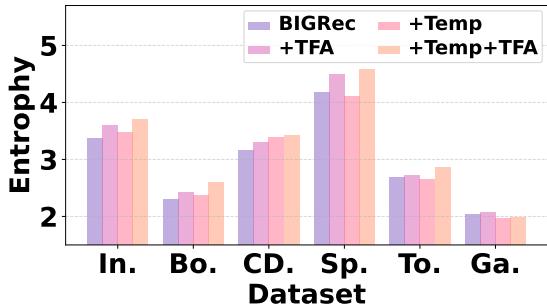
Figure 2 使用熵 (越高越好) 来衡量多样性。
- 紫色柱 (BIGRec): 标准模型的多样性最低。
- 粉色柱 (+TFA): 添加无文本助手显著提高了熵。
- 浅粉色柱 (+Temp+TFA): 将助手与温度缩放相结合产生了最多样化的结果。
这证实了 \(D^3\) 成功打破了基于文本生成的“回声室”。
超越准确性: 可控推荐
\(D^3\) 方法最迷人的含义之一是“引导”推荐的能力。因为解码过程混合了来自外部模型 (助手) 的得分,我们可以操纵该外部模型来实现特定目标。
例如,如果平台想要推广特定类别的商品 (例如,增加综合商店中“游戏”的曝光率) 怎么办?
作者进行了一项实验,他们让助手偏向特定类别。
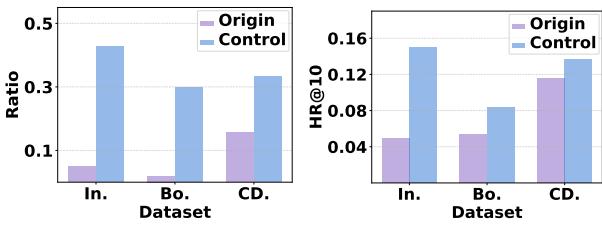
Figure 3 显示了该控制实验的结果。
- 左图 (Ratio): 蓝色柱显示,与原始 (紫色) 相比,目标类别出现在推荐中的比例大幅增加。
- 右图 (Accuracy): 令人惊讶的是,强制这种分布并没有只是用随机物品淹没用户;这些类别的准确性 (HR@10) 也有所提高。
这表明,\(D^3\) 对于那些需要平衡用户相关性与商业逻辑 (如推广曝光率低的流派) 而又不想重新训练基础 LLM 的平台来说,可能是一个强大的工具。
结论
将大型语言模型集成到推荐系统中是大势所趋,但这篇论文作为一个重要的提醒: 我们不能不加审视地复制粘贴 NLP 的方法论。
生成电影标题与生成故事中的句子有着根本的不同。通过识别 放大偏差 (幽灵 Token) 和 同质化问题 (文本重复) 的机制,作者阐明了为何 LLM 在某些情况下难以击败传统基线。
\(D^3\) 方法 提供了一个稳健的解决方案。通过剥离不必要的长度归一化并利用“无文本”助手来指导解码,我们获得了两全其美的效果: LLM 的语义理解能力和协同过滤的行为智慧。
对于学生和从业者来说,结论很明确: 当将生成式 AI 适应新领域时,请密切关注推理阶段。有时最大的改进并非来自更大的模型,而是来自更聪明的输出解码方式。