](https://deep-paper.org/en/paper/file-2988/images/cover.png)
在自然语言处理 (NLP) 的世界里,语境决定一切。请看这句话: *“食物相当不错,但服务太糟糕了。” (The food is pretty good, but the service is so horrific.) *
如果你让一个标准的情感分析模型对这句话进行分类,它可能会感到困惑。它是正面的?负面的?还是中性的?事实是它两者兼有——这完全取决于你问的是什么。如果你关注的是食物,它是正面的。如果你关注的是服务,它是负面的。
这就是基于属性的情感分析 (Aspect-Based Sentiment Analysis, ABSA) 的领域。其目标是预测句子中特定属性 (如“食物”或“服务”) 的情感极性 (正面、负面或中性) 。
多年来,解决这一问题的行业标准一直是注意力机制 (Attention Mechanism) 。 注意力机制允许模型在做出预测时“关注”句子的不同部分。然而,最近的研究表明,注意力机制可能关注了错误的地方。它经常被不相关的上下文或嘈杂的词汇分散注意力。
在这篇文章中,我们将深入探讨一篇题为 《面向基于属性情感分析的动态多粒度归因网络》 (Dynamic Multi-granularity Attribution Network for Aspect-based Sentiment Analysis) 的论文。研究人员提议从*注意力 (attention) 转向归因 (attribution) *——这是一种不仅仅观察相关性,而是通过挖掘模型的底层推理过程来达到最先进结果的方法。
问题所在: 注意力并不等于解释
要理解为什么我们需要一种新方法,我们首先需要了解当前主流方法的缺陷。大多数 ABSA 模型使用注意力分数来决定哪些词是重要的。理论上,如果模型给某个词分配了很高的注意力权重,那么这个词对预测就是至关重要的。
然而,众所周知,注意力机制充满了“噪声”。它经常高亮那些在句法上相关但在情感上无关的词。

请看上方的 图 1 (a) 。 模型试图判断关于属性 “service” (服务) 的情感。注意力机制 (蓝条) 给“pretty”和“good”分配了高分。这些词描述的是食物,而不是服务。如果模型依赖这些注意力分数,它可能会错误地预测服务是正面的。
此外,如 图 1 (b) 所示,研究人员发现,有时你可以打乱注意力权重或移除“重要”的词,而预测结果却不会改变。这表明注意力机制像一个“黑盒”——它并不总是反映神经网络真实的推理过程。
解决方案: 动态多粒度归因网络 (DMAN)
这篇论文的作者提出了动态多粒度归因网络 (Dynamic Multi-granularity Attribution Network, DMAN) 。 DMAN 不问“模型在看哪里?” (注意力) ,而是问“哪些词实际上导致了预测的变化?” (归因) 。
这种方法提供了三大创新:
- 多步归因 (Multi-step Attribution) : 它使用*积分梯度 (Integrated Gradients) *来动态计算词汇在理解的不同阶段的重要性。
- 多粒度 (Multi-granularity) : 它同时在单个词 (Token) 级别和短语 (Span) 级别分析文本。
- 动态句法聚焦 (Dynamic Syntax Concentration) : 它将这些归因分数与语法依存树相结合,过滤掉不相关的句子结构。
在详细拆解之前,让我们先看一下架构图。
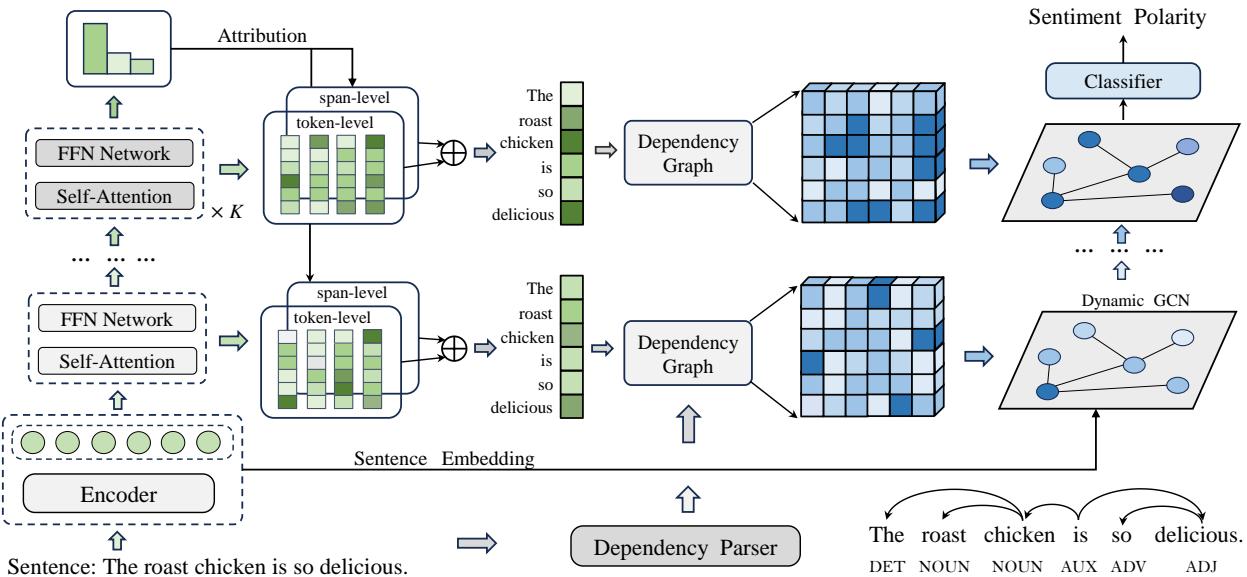
正如你在 图 2 中所见,该模型从一个标准的 BERT 编码器开始,进入一个专门的归因提取过程,分裂为 Token 级和 Span 级,最后通过一个基于句法的图卷积网络 (GCN) 对数据进行精炼。
第一步: 多步归因提取
该模型的核心引擎是积分梯度 (Integrated Gradients, IG) 。
在标准的深度学习中,我们通常查看“梯度”来了解如果我们微调输入,输出会有多大变化。然而,梯度在高值处可能会饱和 (变得平坦) ,从而掩盖特征的真实重要性。积分梯度通过计算从“基线” (如空白句子) 到实际输入的路径上的平均梯度来解决这个问题。
在数学上,第 \(i\) 维度的积分梯度定义为:
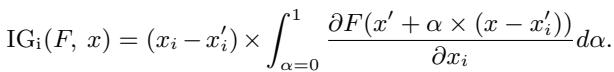
这里,\(x\) 是输入,\(x'\) 是基线。这个积分累加了梯度,提供了一个更准确的“归因分数”,代表了一个特定词对最终情感预测的贡献程度。
堆叠架构
研究人员并没有只在最后计算一次。他们堆叠了多个自注意力 (Self-Attention) 和前馈神经网络 (FFN) 模块。
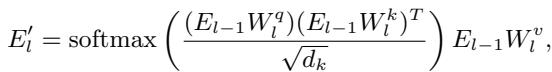
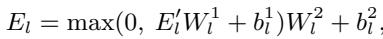
通过在每一层计算 IG,模型捕捉到了语义理解的动态本质。随着模型深入阅读句子,词汇的重要性会发生变化。
然而,为向量的每一个维度计算 IG 计算量巨大且充满噪声。为了解决这个问题,作者聚合了分数并使用了 Top-K 策略 。 他们只保留具有最高归因值的维度,有效地过滤掉了通常困扰注意力机制的噪声。
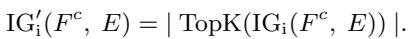
这产生了一个干净、纯粹的信号,准确指示哪些 Token 正在驱动情感分析。
第二步: 多粒度归因
语言很少是逐字处理的。我们以概念为单位进行思考。“New York” (纽约) 是一个单一的语义单元,而不仅仅是“New”和“York”。
现有方法通常只关注 Token (词) 级别。DMAN 引入了多粒度方法。它观察:
- Token 级: 细粒度的细节。
- Span 级: 短语和有意义的块。
模型使用 spaCy 工具包来识别句子中的 Span (短语) 。对于属于同一个 Span 的词,模型使用平均池化来平均它们的归因分数。
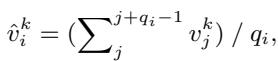
理想情况下,我们需要两全其美。我们需要 Token 的精确性和 Span 的概念完整性。模型使用一个可学习的参数 \(\alpha\) 将这两个视图融合在一起。
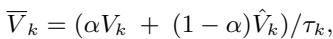
这种融合确保模型理解“horrific” (可怕) 是一个强有力的单个词,而“waste of time” (浪费时间) 是一个强有力的短语。
第三步: 动态句法聚焦
知道哪些词重要是第一步。第二步是理解它们如何与属性相关联。这就是句法 (语法) 发挥作用的地方。
许多现代 ABSA 模型使用依存树 (Dependency Trees) 。 这些是将词汇之间的语法关系 (例如,名词-形容词,主语-动词) 映射出来的图结构。使用它的标准方法是通过邻接矩阵 \(A\) 上的图卷积网络 (GCN) ,如果两个词在语法上相连,则 \(A_{ij}=1\)。
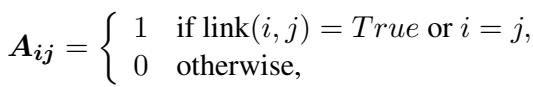
标准句法的缺陷
标准依存树的问题在于它们将所有语法连接视为同等重要。在句子 *“The food is good but the service is bad” (食物很好但服务很差) * 中,有一条语法路径将“food”连接到“bad” (通过连词“but”) 。标准的 GCN 可能会意外地让“bad”的负面情绪渗透到“food”上。
动态解决方案
DMAN 通过使用前几步计算出的归因分数 (\(V_k\)) 来对邻接矩阵进行加权 , 从而改进了这一点。
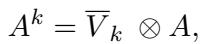
在这个公式中,句法图 \(A\) 实际上被归因分数 \(\overline{V}_k\) 掩码了。如果一个词的归因分数很低 (意味着它与情感无关) ,它在图中的连接就会被抑制。
然后,GCN 处理这个优化后的图。
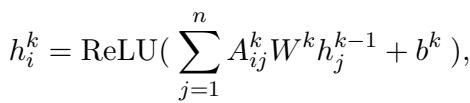
这使得模型能够动态聚焦于对正在分析的特定属性真正重要的句法结构,同时忽略语法噪声。
实验与结果
研究人员在五个标准基准数据集 (Laptop14, Restaurant14, Restaurant15, Restaurant16 和 MAMS) 上测试了 DMAN。他们将其与强大的基线模型进行了比较,包括 BERT-SPC 和各种基于图的模型,如 DualGCN 和 RGAT。
主要性能
结果令人信服。DMAN 在几乎所有指标上都达到了最先进 (SOTA) 的性能。
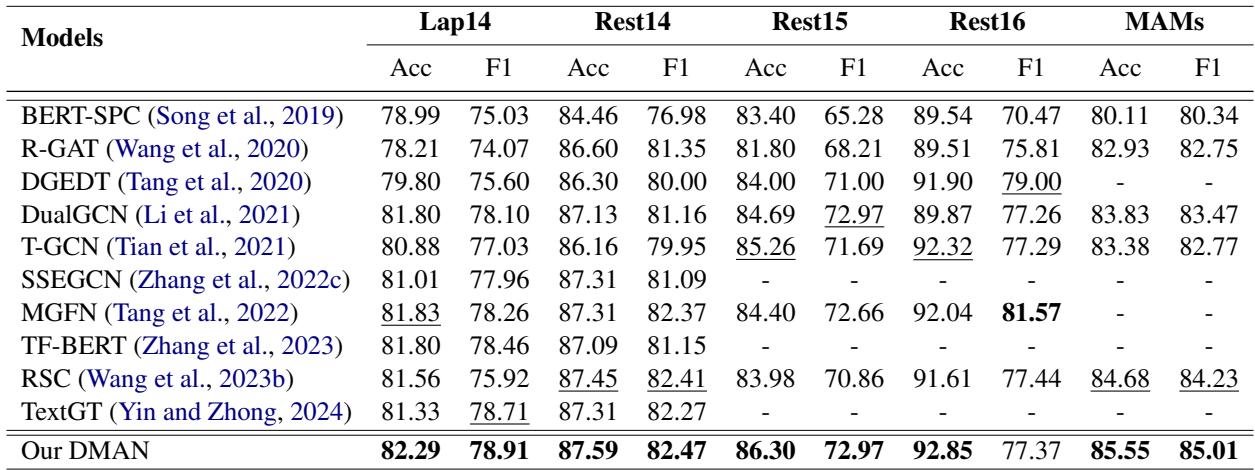
请注意 MAMS 数据集上的结果。MAMS 是一个特别困难的数据集,旨在同一句子中包含具有不同情感的多个属性。DMAN 在这里超越基线的能力 (准确率 85.55% vs 次优的 83.83%) 证明了归因机制成功地解开了复杂的语境。
消融实验
为了证明模型的每一部分都是必要的,作者进行了消融实验,逐一移除组件。
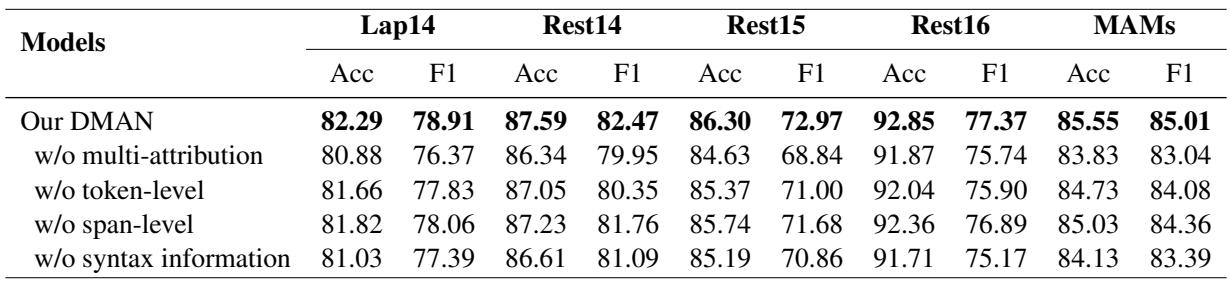
- w/o multi-attribution (无多重归因) : 移除归因机制导致准确率急剧下降 (例如,在 Lap14 上从 82.29% 降至 80.88%) 。这证实了标准注意力机制不如归因机制。
- w/o syntax information (无句法信息) : 移除依存树集成也损害了性能,表明语法仍然至关重要——只是它需要归因的引导。
可视化改进效果
最有力的证据来自于可视化模型实际的“思考”过程。
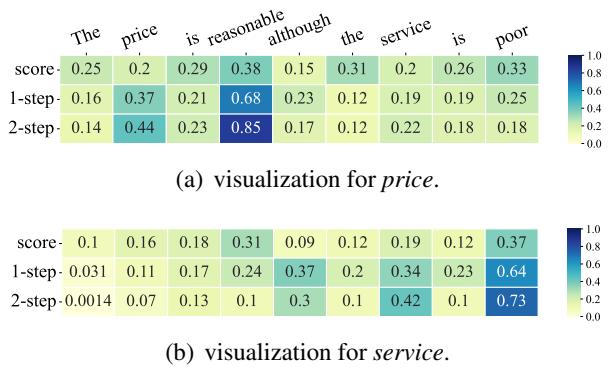
在 图 6 中,观察 \(\alpha\) score (标准注意力) 和 归因步骤 (Attribution steps) 之间的对比。
- 属性: Price (价格) 。 标准注意力 (顶行) 关注了“poor”,这是错误的 (服务很差,而不是价格) 。两步归因 (底行) 正确地几乎完全聚焦于“reasonable” (合理) 。
- 属性: Service (服务) 。 标准注意力被“reasonable”分散了注意力。归因机制正确地锁定了“poor”。
这种可视化证实了 DMAN 不仅仅是靠运气获得更好的分数;它真正像人类一样在对句子进行推理。
与大语言模型 (LLMs) 的对比
在 ChatGPT 时代,一个自然的问题是: “为什么不直接使用 LLM?”
作者将 DMAN 与 ChatGPT (零样本和少样本) 以及 LLaMa2-13b 进行了比较。
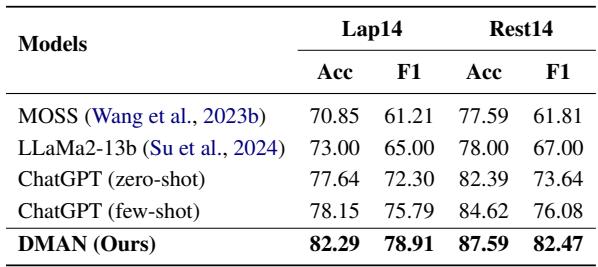
令人惊讶的是,在这些特定任务上,DMAN 的表现甚至显著优于少样本 (few-shot) 的 ChatGPT (在 Rest14 上 87.59% vs 84.62%) 。这凸显了虽然 LLM 是强大的通才,但像 DMAN 这样专门的、细粒度的架构在 ABSA 等特定的高精度任务上仍然更胜一筹。
结论
“动态多粒度归因网络”代表了情感分析领域向前迈出的重要一步。它通过用积分梯度归因取代注意力机制,解决了注意力机制根本的“黑盒”问题。
通过将这种归因与多粒度分析 (词 + 短语) 相结合,并利用它来优化句法图 , DMAN 达到了以前模型所缺乏的精度和可解释性水平。
对于 NLP 学生和研究人员来说,关键的启示很明确: 仅有注意力是不够的。 要真正理解复杂的情感,我们必须更深入地研究模型的梯度和推理路径。我们需要从仅仅观察相关性转向理解归因。这篇论文正是为此提供了一个强有力的蓝图。