](https://deep-paper.org/en/paper/file-3002/images/cover.png)
想象一下你正在更新维基百科页面。你需要修改一个关键事实: “莱昂内尔·梅西 (Lionel Messi) 现在是荷兰公民。”
如果你只是在数据库中更新这一个数据点,那没问题。但大型语言模型 (LLM) 不是数据库;它们是建立在相关性网络之上的推理引擎。如果你强迫 LLM 在没有上下文的情况下相信梅西是荷兰人,就会引发一连串的混乱。当你问“梅西出生在哪里?”时,模型现在可能会产生幻觉回答“阿姆斯特丹”,因为在它对世界的统计认知中,荷兰公民通常出生在荷兰。
这就是知识编辑 (Knowledge Editing, KE) 的核心问题。我们如何在不破坏其逻辑推理能力的情况下更新 LLM 的知识?
在这篇文章中,我们将深入探讨一篇引人入胜的论文 “EVEDIT: Event-based Knowledge Editing for Deterministic Knowledge Propagation” (EVEDIT: 用于确定性知识传播的基于事件的知识编辑) 。 研究人员认为,目前编辑简单事实 (三元组) 的标准做法存在根本性缺陷。他们引入了一种新的范式——基于事件的编辑 (Event-Based Editing) ——以及一种名为 Self-Edit (自我编辑) 的新颖方法,帮助模型在更新信念的同时保持逻辑上的合理性。
问题所在: “梅西悖论”与缺失的锚点
要理解为什么编辑 LLM 如此困难,我们需要先看看目前的做法。大多数最先进的方法都是基于三元组进行操作的: (主语, 关系, 宾语)。
例如,要更新一个模型,我们可能会输入三元组: (梅西, 公民身份, 荷兰)。
问题在于模糊性。当一个事实发生变化时,一些相关信息应该随之改变,但另一些信息应该保持不变。那些为了保证逻辑推演必须保持真实的信息被称为推理锚点 (Deduction Anchor) 。
在梅西的例子中,锚点是什么?
- 可能性 A: 锚点是“人们通常出生在他们拥有公民身份的国家”。如果模型坚持这一点,将梅西的国籍更新为荷兰就意味着他的出生地也变成了荷兰。 (逻辑错误)
- 可能性 B: 锚点是“出生地是不可改变的事实”。如果模型坚持这一点,它就会理解梅西可以是荷兰人,但仍然出生在阿根廷。 (正确推理)
目前的编辑方法未能定义这个锚点。它们只是将新事实 (梅西, 公民身份, 荷兰) 塞进权重中。结果呢?模型变得困惑不解。
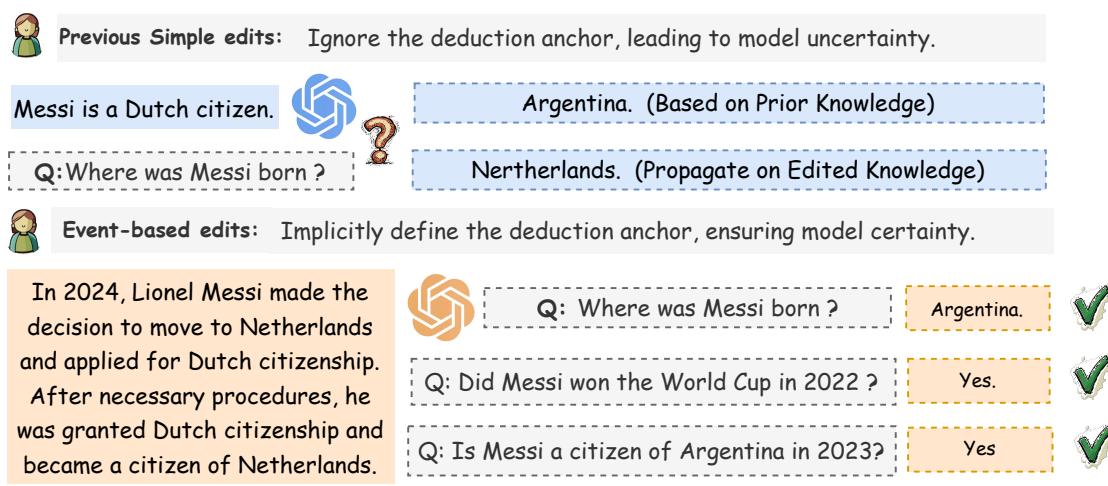
如上方的 图 1 所示,纯粹基于三元组的编辑会导致不确定性。左侧的模型仅用一个简单事实进行编辑后,错误地推断出梅西出生在荷兰。
然而,图 1 的右侧展示了解决方案: 事件 (Events) 。 在现实世界中,事实不会凭空翻转。事件导致了变化。如果我们告诉模型,“2024 年,梅西申请并获准成为荷兰公民,” 模型就会隐式地理解这个锚点。它知道获得公民身份是一个发生在出生之后的过程,因此他的出生地 (阿根廷) 保持不变。
困惑的形式逻辑
论文作者不仅仅依靠直觉;他们用数学证明了这一点。他们使用形式逻辑对知识编辑进行了公式化描述。
他们将模型的知识 (\(\mathcal{K}\)) 定义为模型认为是一组真实的命题。
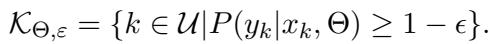
当我们编辑模型时,我们试图创建一个新的知识集 (\(\mathcal{K}'\))。这个过程的关键部分是推理锚点 (\(\mathcal{K}^{\mathcal{E}}\))——即在编辑过程中假定为真的现有知识子集。
论文指出了当前研究中的两个主要谬误:
- 无锚点谬误 (No-Anchor Fallacy) : 假设我们根本不需要定义锚点。
- 最大锚点谬误 (Max-Anchor Fallacy) : 假设所有不直接与编辑内容冲突的东西都是锚点。
这两者都会导致逻辑矛盾。当模型遇到这些矛盾时,其置信度就会崩溃。
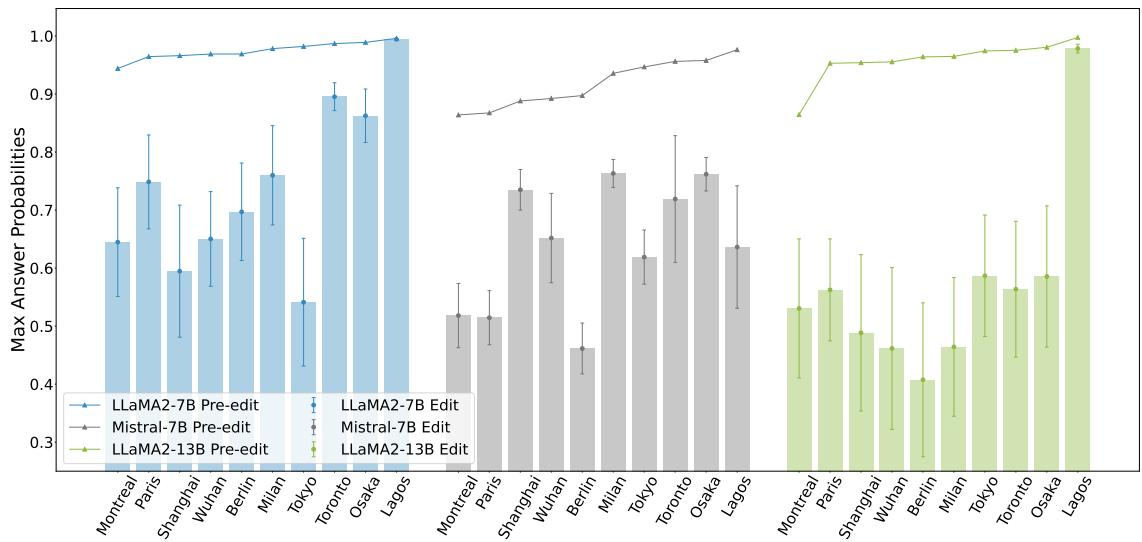
图 2 描绘了这种确定性的崩溃。图表对比了“编辑前 (Pre-edit) ”的置信度 (柱状图) 与“编辑后 (Edit) ”的置信度 (折线/形状) 。当标准的反事实编辑 (如更改城市所属的国家) 在没有适当上下文的情况下被引入时,模型生成正确答案的概率在不同规模的模型 (LLaMA-7B, Mistral-7B, LLaMA-13B) 中均显著下降。
解决方案: 基于事件的知识编辑
研究人员建议将该领域的研究重心从基于三元组的编辑转移到基于事件的编辑 。
我们不应该向模型输入 (主语, 关系, 宾语),而应该输入一段事件描述 (Event Description) 。 这是一段简短的叙述,解释了变化是如何以及为何发生的。
为什么这行之有效?因为事件描述包含了隐式的推理锚点 。
- 三元组: “梅西是荷兰人。” (模棱两可)
- 事件: “在欧洲生活多年后,梅西于 2024 年申请了荷兰公民身份。” (清晰: “在欧洲生活”和“申请”的语境充当了锚点) 。
实证证据: 事件恢复信心
增加这种叙事语境真的有助于模型吗?研究人员进行了一项实验,比较了使用三元组编辑与使用事件编辑的模型的“确定性” (置信度) 。
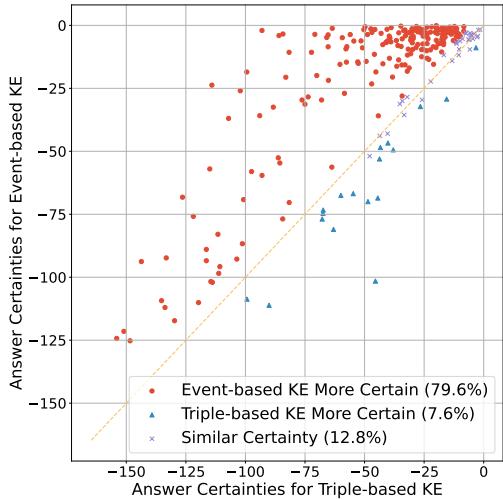
图 3 显示了结果。每个点代表一个编辑案例。
- X 轴 是使用基于三元组编辑的确定性。
- Y 轴 是使用基于事件编辑的确定性。
- 红点 (占数据的近 80%) 代表基于事件的方法导致模型置信度更高的情况。
数据很清楚: 给模型提供“故事” (事件) 可以缓解困惑并恢复对其推理的信心。
EVEDIT 基准测试
为了使这一新方法标准化,作者创建了 EVEDIT 。 他们采用了流行的 COUNTERFACT 数据集 (用于测试三元组编辑) 并对其进行了升级。
他们使用 GPT-3.5 将枯燥的事实扩展为现实的未来事件。他们还过滤掉了“不可能”的编辑。例如,改变历史人物的母语是不可能的,因为他们已经去世了。基于事件的方法尊重因果逻辑。
下面是 EVEDIT 数据集的一个样本:

如 图 7 所示,该数据集提供:
- 事件描述: 解释变化的段落 (例如,Toko Yasuda 从小提琴转向钢琴) 。
- 三元组分解: 将事件分解为三元组 (用于与旧方法进行比较) 。
- 评估任务: 文本补全和问答对,用于测试模型是否真正“理解”了这种变化。
方法: Self-Edit (自我编辑)
既然我们有了更好的知识表示方法 (事件) ,我们该如何实际更新模型的权重呢?
现有的方法如 ROME (Rank-One Model Editing) 或 MEMIT (Mass-Editing Memory in a Transformer) 都是为三元组设计的。它们试图定位与主语相关的特定神经元并重写它们。
研究人员发现,试图将事件强行套用进这些“定位并编辑”的方法中效果不佳。模型很难保持自然度 (naturalness) ——生成的文本往往变得重复或混乱。
相反,作者提出了一个新的框架: Self-Edit (自我编辑) 。
Self-Edit 如何工作
Self-Edit 背后的逻辑简单而绝妙: 利用模型来教它自己。
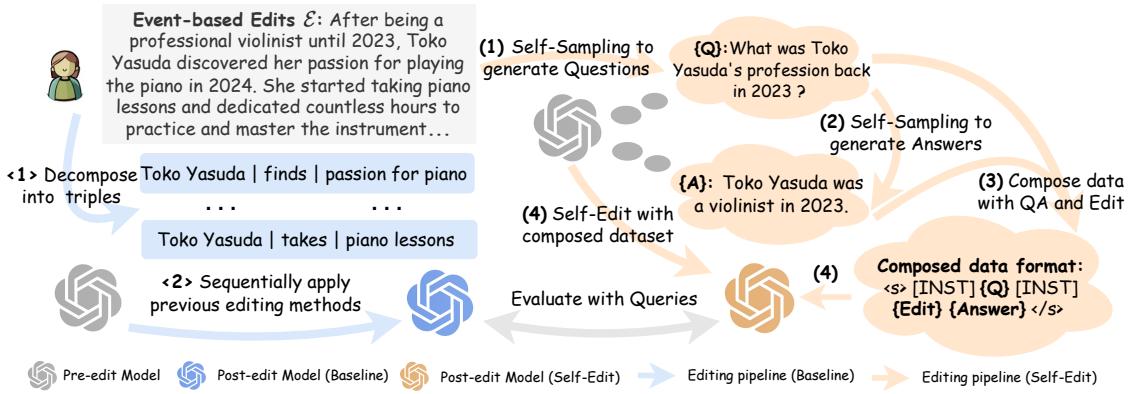
参考 图 4 , 这是 Self-Edit 的流程 (如右侧所示) :
- 问题生成: 将新的事件描述输入给模型,并提示其生成相关的问题 (\(Q\))。
- 答案生成: 模型使用事件描述作为上下文来回答自己的问题 (\(A\))。至关重要的是,如果一个问题无法通过事件来回答 (例如,“她早餐吃了什么?”) ,模型被教导输出“我不知道”,这有助于定义编辑边界 (Editing Boundary) 。
- 数据集构建: 我们现在拥有了一个由
(问题, 事件 -> 答案)对组成的微型数据集。 - 微调 (Fine-Tuning) : 在这个数据集上对模型进行微调。
这种方法确保模型不仅仅是在死记硬背一串文本。在权重被永久更新之前,它正在练习对新信息进行推理。
实验与结果
研究人员将 Self-Edit 与几个基线方法进行了比较:
- 事实关联方法: ROME, MEMIT, PMET (专为三元组设计) 。
- 上下文学习 (ICL) : 仅仅将事件粘贴到提示词中 (不更新权重) 。
- GRACE: 一种使用隐藏状态代码本的方法。
他们测量了两个关键指标:
- 一致性 (Consistency) : 编辑生效了吗?模型能回答相关问题吗?
- 自然度 (Naturalness) : 模型说话还像正常人类吗,还是我们破坏了它的语言能力?
结果表
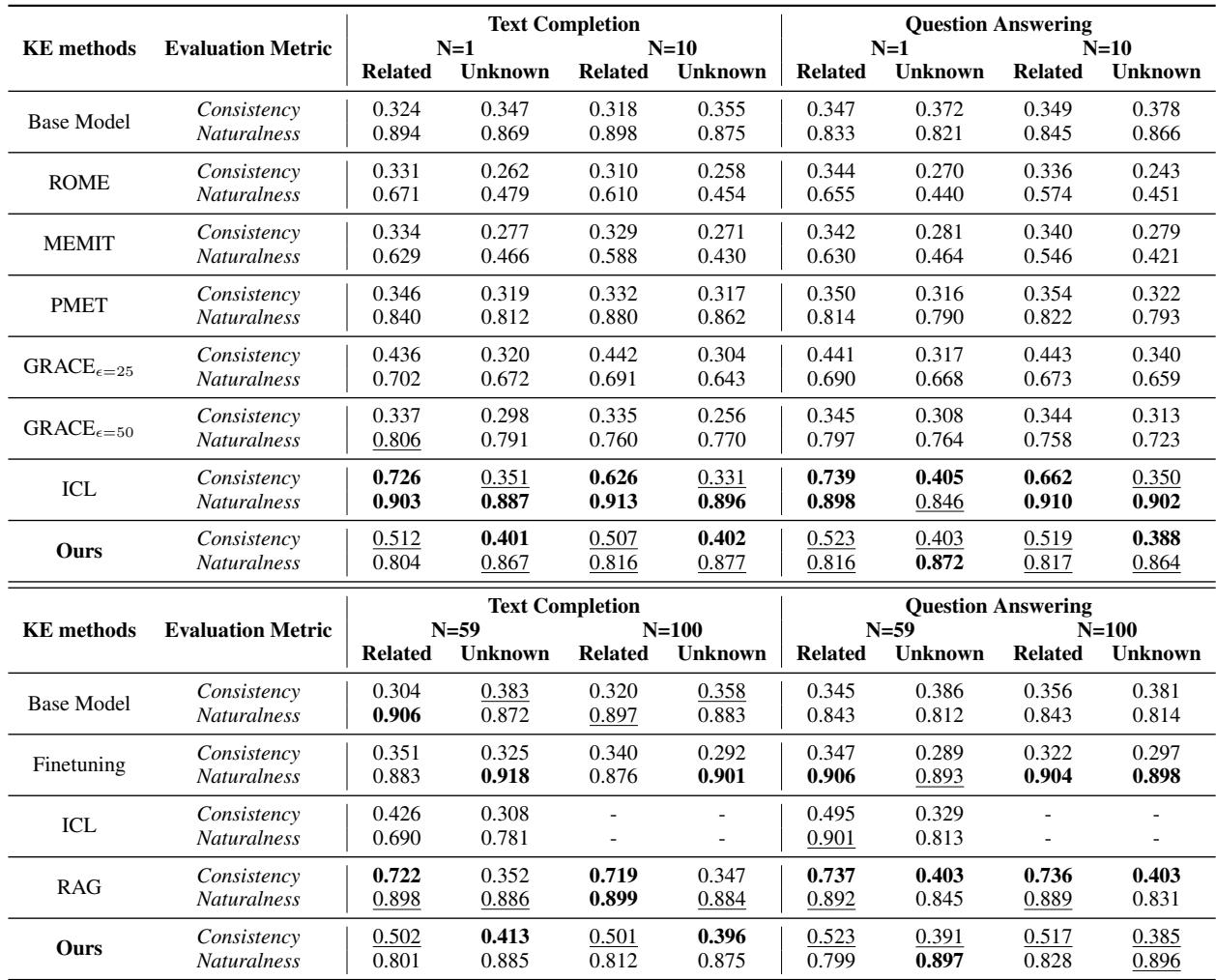
表 1 揭示了几个关键见解:
- 事实关联方法失败了: 像 ROME 和 MEMIT 这样的方法表现挣扎。它们的“自然度”得分显著下降 (例如,ROME 从 ~0.89 降至 ~0.67) 。这证实了当知识是复杂的事件而不是简单的事实时,对特定神经元进行“手术”是困难的。
- ICL 很强但受限: 简单地将事件放入上下文窗口 (ICL) 效果极佳 (高一致性和自然度) 。然而,它无法扩展。你不能永远把 1000 个事件粘贴到提示上下文窗口中。
- Self-Edit 在更新方面胜出: 在实际更新模型参数的方法 (微调) 中, Self-Edit 取得了最佳平衡。它达到了 ~0.52 的一致性 (相比之下标准微调仅为 ~0.34) ,同时保持了较高的自然度 (~0.81)。
“未知”类别
Self-Edit 方法最令人印象深刻的特性之一是其处理未知 (Unknown) 信息的能力。

如 表 2 所示,Self-Edit 方法具有识别编辑边界的特定能力。如果你问一个与事件无关的问题,模型产生错误连接幻觉的可能性较小。虽然 F1 分数 (~0.30) 表明仍有提升空间,但这朝着让模型知道自己不知道什么迈出了重要一步。
结论与启示
这篇“EVEDIT”论文强调了大型语言模型迈向成熟的关键一步。我们正在从将 LLM 视为静态数据库 (认为只需“翻转一个比特位”即可更改事实) 的阶段中走出来。
作者证明了知识是相互关联的。为了确定性地编辑一个事实,我们必须提供事件——即解释变化的因果背景。这提供了模型正确推理所需的推理锚点 。
此外, Self-Edit 方法表明,更新模型的最佳方式不一定是侵入性的神经元手术 (如 ROME) ,而是一种模仿人类学习方式的微调过程: 通过提问、对新事件进行推理,并将其整合到我们的世界观中。
核心要点:
- 三元组是不够的: 更新
(主语, 关系, 宾语)会产生歧义。 - 事件具有鲁棒性: 叙事提供了稳定推理的锚点。
- Self-Edit 行之有效: 对自生成的问答对进行微调,可以在确保新知识被记住的同时保留模型的流畅性。
随着我们继续将 LLM 集成到动态的现实世界应用中,像基于事件的编辑这样的技术对于在不破坏模型逻辑大脑的前提下保持模型更新将至关重要。