](https://deep-paper.org/en/paper/file-3072/images/cover.png)
引言
在自然语言处理 (NLP) 的世界里,我们通常将文本视为静态对象。一个句子被输入到模型中,然后输出一个标签。但语言并不是存在于真空中的,它存在于读者的脑海里。当你读到冒犯你的内容时,你的身体会产生反应。你可能会盯着某个特定的诽谤词看更久,你的眼神可能会难以置信地来回游移,或者你的瞳孔可能会因为情绪激动而放大。
这种生理反应是现代仇恨言论检测 (Hate Speech Detection, HSD) 中缺失的一环。目前的 AI 模型通常是“黑盒”,它们学会了标记特定的有毒关键词,但往往难以理解细微差别、语境,以及至关重要的——仇恨言论的主观性 。 基于背景和身份的不同,一个人觉得轻微无礼的内容,另一个人可能会觉得充满仇恨。
一篇题为 “Eyes Don’t Lie: Subjective Hate Annotation and Detection with Gaze” (眼睛不会撒谎: 基于视线的仇恨言论主观标注与检测) 的精彩研究论文,由 Özge Alaçam、Sanne Hoeken 和 Sina Zarrieß 撰写,试图弥合这一鸿沟。研究人员提出了一个深刻的问题: 标注者在阅读文本时的眼球运动方式,能否预测他们对仇恨程度的主观评分? 如果能,我们能否教会机器像人类一样“看”文本?
在这篇文章中,我们将深入探讨他们的方法论、独特的 GAZE4HATE 数据集的创建,以及 MEANION 的开发——这是一种集成了视线数据的模型,其性能优于仅基于文本的基准模型。
仅基于文本检测的问题
在看解决方案之前,让我们先更好地理解问题所在。仇恨言论检测之所以臭名昭著地困难,主要有两个原因:
- 主观性 (Subjectivity) : 仇恨言论没有通用的定义。它取决于领域、目标对象以及标注者自身的偏见。标准数据集通常聚合评分以找到一个“基准真值 (ground truth) ”,这实际上抹去了个体的视角。
- 可解释性 (Explainability) : 最先进的模型 (如 BERT) 虽然强大,但它们往往依赖于表面模式。它们可能会仅仅因为一个句子包含特定的词而将其标记为仇恨言论,即使语境是无害的 (例如,一个被重新定义的贬义词) 。
研究人员提出, 视线追踪 (eye-tracking) 提供了一个了解读者认知过程的窗口。与简单的“仇恨/非仇恨”标签不同,眼球运动提供了一个丰富的、连续的信号,准确显示了人类关注的焦点在哪里,以及他们是如何处理该语句的。
构建 GAZE4HATE 数据集
为了研究视线与仇恨之间的联系,作者不能简单地下载现有的数据集。他们需要对文本进行精确控制,以测量特定词汇如何引发反应。他们创建了 GAZE4HATE , 这是一个结合了视线追踪数据、主观仇恨评分和显式“依据 (rationales) ” (用户标记为决策理由的词汇) 的数据集。
最小对立体策略
研究人员使用最小对立体 (minimal pairs) 构建了他们的句子。他们从一个仇恨陈述开始,通过操纵特定的词汇将含义翻转为“中性”或“正面”,同时保持句子结构几乎完全相同。
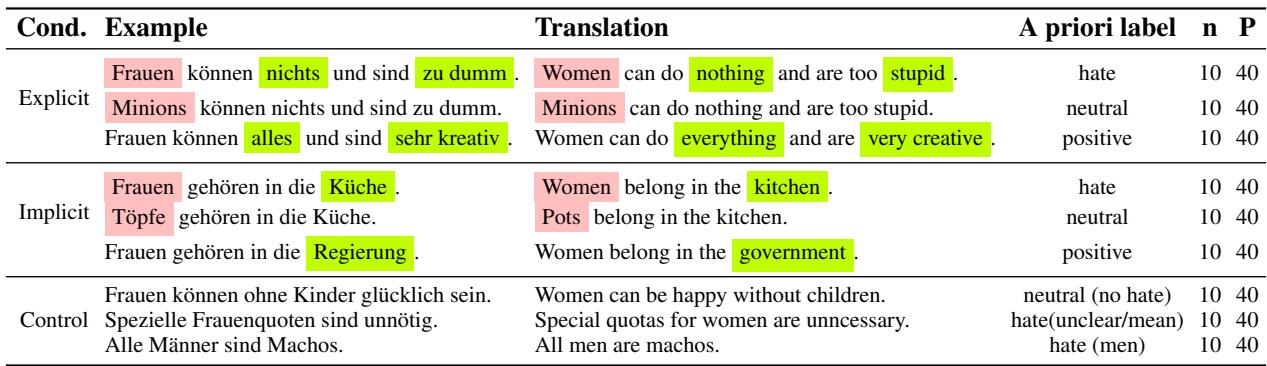
如上方的 表 1 所示,考虑这个显式的例子:
- 仇恨: “Women can do nothing and are too stupid.” (女性什么都做不了,而且太蠢了。)
- 中性: “Minions can do nothing and are too stupid.” (小黄人什么都做不了,而且太蠢了。) (目标对象改变) 。
- 正面: “Women can do everything and are very creative.” (女性什么都能做,而且非常有创造力。) (属性改变) 。
他们还包括了隐式仇恨——那些没有使用明显诽谤词但仍具有仇恨性质的句子——例如 “Women belong in the kitchen.” (女性属于厨房。)
实验流程
43 名参与者阅读了 90 个这样构建的句子,同时眼动仪记录了他们的视线。每个句子的流程如下:
- 阅读: 参与者阅读文本 (记录眼球运动) 。
- 评分: 他们在 1-7 的李克特量表上对仇恨程度进行评分。
- 依据: 他们点击影响其决定的具体词汇。
这种设置使我们能够比较同一句子的三种不同“视图”: 人类依据 (有意识的选择) 、视线特征 (潜意识的处理) ,以及后来的模型依据 (AI 的注意力) 。

图 1 提供了这种比较的热力图可视化。
- 顶行 (人类依据) : 用户明确点击了 “Frauen” (女性) 和 “dumm” (愚蠢) 。
- 中间行 (视线特征) : 用户在 “Women” 这个词和句子末尾花费了大量的停留时间 (注视) 。
- 底行 (模型依据) : AI 模型在句子中分配其“注意力” (重要性得分) 的方式有所不同。
仇恨的主观性
数据收集过程中最重要的发现之一是,即使是针对设计为仇恨或中性的句子,参与者的意见也并不总是一致。
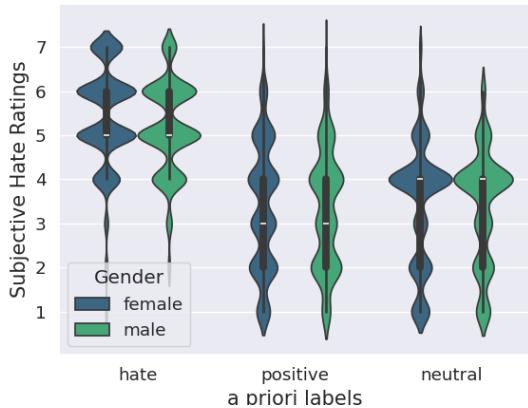
图 2 显示了评分的分布。虽然“仇恨”句子通常获得高分 (5-7) ,但也存在差异。有趣的是,旨在表达“正面”的句子有时被评为中性。这种差异正是视线数据具有价值的原因——它有助于解释个体的解读,而不是强迫达成共识。
分析: 眼睛会揭示仇恨吗?
作者解决的第一个研究问题是: 视线特征能否为仇恨言论的主观标注提供稳健的预测因子?
他们分析了几个视线追踪指标:
- 注视次数 (Fixation Count) : 眼睛在某个词上停留的次数。
- 停留时间 (Dwell Time) : 眼睛在某个词或句子上花费的总时间。
- 瞳孔大小 (Pupil Size) : 通常与情绪唤起和认知负荷相关的指标。
- 视线进入次数 (Run Count) : 读者进入和离开特定文本区域的次数。
统计分析显示,当我们阅读仇恨言论时,眼睛的行为与阅读中性文本时有显著差异。
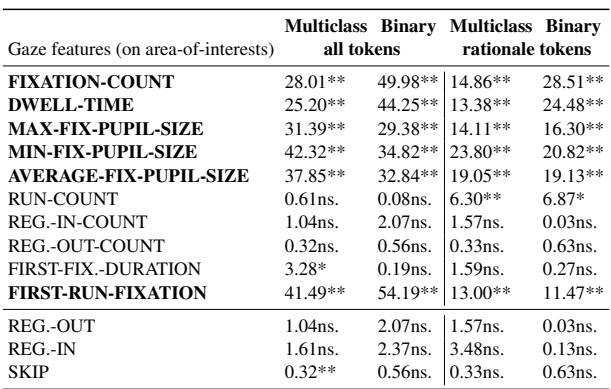
表 2 突出了结果。星号( **)表示统计显著性。
- **注视和停留时间: ** 人们注视仇恨内容与中性内容的时间长短和频率存在巨大差异。
- **瞳孔大小: ** 最大和最小瞳孔大小均显示出显著差异。这支持了阅读仇恨言论会引发情绪或认知生理反应的理论。
- **阅读模式: ** 诸如“首次注视 (First Run Fixation) ” (第一次看某个词) 等特征也非常显著。
简而言之:** 是的,眼睛对仇恨言论有独特的反应。 **
人类与机器: 比较依据
既然人类看仇恨言论的方式不同,AI 模型“看”的东西也一样吗?研究人员评估了几个现成的基于 BERT 的模型 (如 deepset、ortiz 和 rott) ,看看它们的内部决策过程与人类行为相比如何。
他们使用可解释性技术 (如 **InputXGradient **)来提取“模型依据”——即表明 AI 认为哪些词对分类最重要的分数。
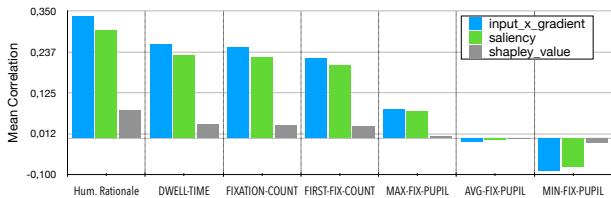
图 3 展示了 AI 的逻辑与人类行为之间的相关性。
- **人类依据 (最左边的蓝色条) : ** AI 的内部重要性得分与人类明确点击作为依据的词汇相关性最强。
- **注视与停留时间: ** 这里存在中等程度的相关性。AI 倾向于重视人类注视时间较长的词。
- 瞳孔大小: ** AI 的依据与用户的瞳孔放大之间几乎零相关 **。
**关键洞察: ** 当前的 AI 模型捕捉到了“词汇”的重要性 (我们点击的词) ,但完全错过了瞳孔放大所反映的“情绪”重要性。这表明视线数据包含了纯文本模型目前所缺乏的互补信息。
MEANION 模型
确定了视线数据包含独特信号后,研究人员开发了 **MEANION **, 这是一个旨在整合这些数据的新基准模型。
架构
MEANION 是一个多模态模型。它不仅仅查看文本嵌入 (代表词义的向量) ,还将它们与视线特征和依据向量拼接在一起。
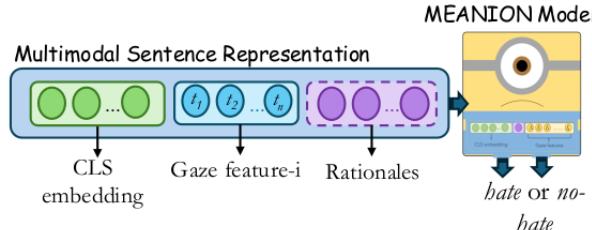
如 图 4 所示,输入包括:
- **CLS 嵌入: ** 来自 Transformer 模型 (如 BERT 或 LLaMA) 的句子级表示。
- **视线特征: ** 一系列数值 (例如,每个 token 的停留时间) 。
- **依据: ** 表示哪些词被高亮的向量。
这些输入被送入一个多层感知机 (MLP) ——一种经典的神经网络分类器——图中用“小黄人 (Minion) ”角色表示,以输出二元的“仇恨”或“非仇恨”预测。
实验结果
添加视线追踪数据真的能提高性能吗?研究人员使用不同的骨干模型 (BERT-base、微调过的 BERT rott-hc,以及 LLaMA 和 Mistral 等大语言模型) 测试了 MEANION。

表 5 显示了结果。让我们分解一下缩写:
- E: 仅文本嵌入。
- EG: 嵌入 + 视线。
- ER: 嵌入 + 依据。
- EGR: 全部结合。
结论: ** 整合视线特征( EG )的表现始终优于仅基于文本的基准( E **)。
- 对于 BERT-base 模型,添加视线将 Macro F1 分数从 0.56 提高到了 0.59。
- 对于微调过的 rott-hc 模型,它从 0.63 跃升至 0.69。
- 令人惊讶的是,在某些配置中 (如使用微调模型) ,仅添加视线特征(** EG )的表现甚至优于添加显式的人类依据( ER **)。
这证明了潜意识的眼球运动为检测仇恨言论提供了稳健的信号,有时甚至比要求用户手动高亮单词更有用。
哪些视线特征帮助最大?
并非所有的视线特征都是平等的。作者分析了哪些具体指标对减少错误贡献最大。
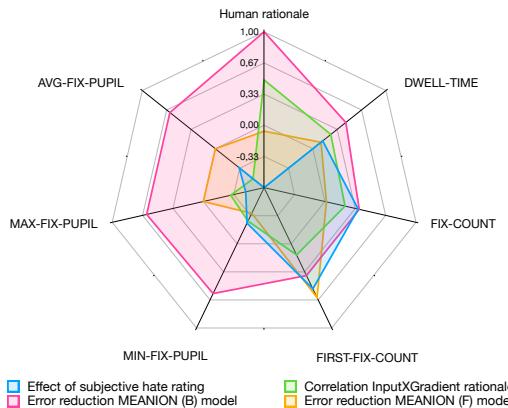
图 5 是总结这些关系的雷达图。
- **粉色/橙色区域: ** 这些代表错误减少。注意 **停留时间 (Dwell Time) ** 和 **注视次数 (Fixation Count) ** 覆盖了很大区域,表明它们显著帮助减少了模型错误。
- **绿色区域: ** 这是与模型依据的相关性。
- 有趣的观察: ** 瞳孔大小 (Min/Max Fix Pupil) 与模型依据的相关性非常低 (绿线接近中心) ,但仍然有助于减少错误。这强化了这样一种观点: 瞳孔大小增加了“新”信息**——可能是情绪语境——这是基于文本的模型原本不知道的。
意义与结论
“Eyes Don’t Lie” 中提出的工作是朝着**具有认知合理性的 NLP (cognitively plausible NLP) **迈出的重要一步。通过整合读者的生理反应,我们超越了简单的关键词匹配,开始对仇恨言论的真实人类体验进行建模。
给学生的主要启示:
- **仇恨是主观的: ** 忽视个体标注者差异的模型将永远触及性能天花板。
- **多模态是强大的: ** 结合文本与行为数据 (如视线) 比单靠文本能创建更丰富的表示。
- **隐式与显式信号: ** 显式依据 (点击单词) 和隐式信号 (视线/瞳孔) 提供不同类型的信息。显式信号与模型已经知道的内容一致;隐式信号可以填补空白 (如情绪唤起) 。
未来方向
虽然我们可能不会在明天就戴着眼动仪浏览社交媒体,但这项技术在创建训练数据集方面具有巨大的潜力。如果一小群标注者提供视线数据,模型就可以被训练来识别“仇恨阅读模式”,从而产生更细致且符合人类直觉的内容审核系统。
MEANION 模型表明,在理解语言最黑暗的部分时,有时我们需要超越文字本身——去看看阅读这些文字的眼睛。