](https://deep-paper.org/en/paper/file-3073/images/cover.png)
社交媒体平台是现代的城镇广场,但它们正日益被仇恨言论所污染。虽然内容审核 (封禁或删除) 是一种方法,但它经常与言论自由原则相冲突,且难以扩大规模。一种更自然、更具建设性的解决方案是反驳言论 (Counterspeech) : 直接回击仇恨言论,纠正错误信息,并试图缓和敌意。
然而,撰写有效的反驳言论很难。为了具有说服力,你不能仅仅说“你错了”。你需要证据,你需要清晰的论点,最重要的是,你需要事实准确。
像 GPT-4 或 Llama 这样的大型语言模型 (LLMs) 似乎是自动化这一过程的完美工具,但它们存在一个致命缺陷: 幻觉 (Hallucination) 。 它们可能会为了赢得争论而编造统计数据,或者偏离原本试图表达的观点。
在这篇文章中,我们将深入探讨 F2RL , 这是由中国国防科技大学和军事科学院的研究人员提出的一个新框架。这篇论文介绍了一种复杂的方法,教导 LLM 生成不仅具有说服力,而且事实正确且对证据忠实的反驳言论。
问题: 善意中的幻觉
在理解解决方案之前,我们需要剖析为什么标准 LLM 在这项任务上很吃力。当你要求 AI 反驳一条仇恨言论时,它会试图预测最可能的下一个词。它并不天生“知道”事实。
这导致了两种特定类型的失败:
- 事实性幻觉 (Factuality Hallucination) : 模型编造虚假证据。例如,声称某个特定群体捐赠了“1000 亿美元”,而真实数字并非如此。
- 忠实性幻觉 (Faithfulness Hallucination) : 模型忽略了提供给它的证据,或者写出的回复并没有真正针对输入的特定仇恨言论。
研究人员在下图中清楚地说明了这个问题。请看用户 2 (产生了数字幻觉) 、用户 3 (给出了不太符合语境的历史教训) 和用户 4 (提供了由可验证证据支持的清晰观点) 之间的区别。
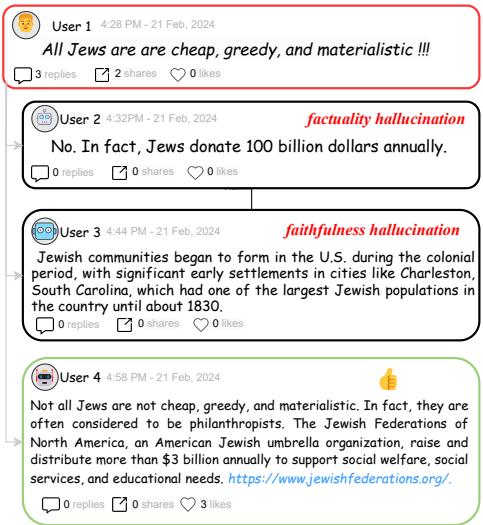
F2RL 框架的目标是持续产生如用户 4 所展示的高质量输出: 由清晰观点引导并有真实证据支持的回复。
解决方案: F2RL 框架
为了解决这些问题,研究人员不仅仅是调整了提示词 (Prompt) ;他们重新设计了整个生成流程。F2RL 代表事实性和忠实性强化学习 (Factuality and Faithfulness Reinforcement Learning) 。
该框架分三个不同阶段运作:
- 自评观点生成: 在争论之前先决定争论什么。
- 由粗到细的证据检索: 寻找正确的事实来支持该论点。
- 强化学习 (RL) : 使用复杂的奖励系统训练模型坚持事实。
让我们看看高层架构:
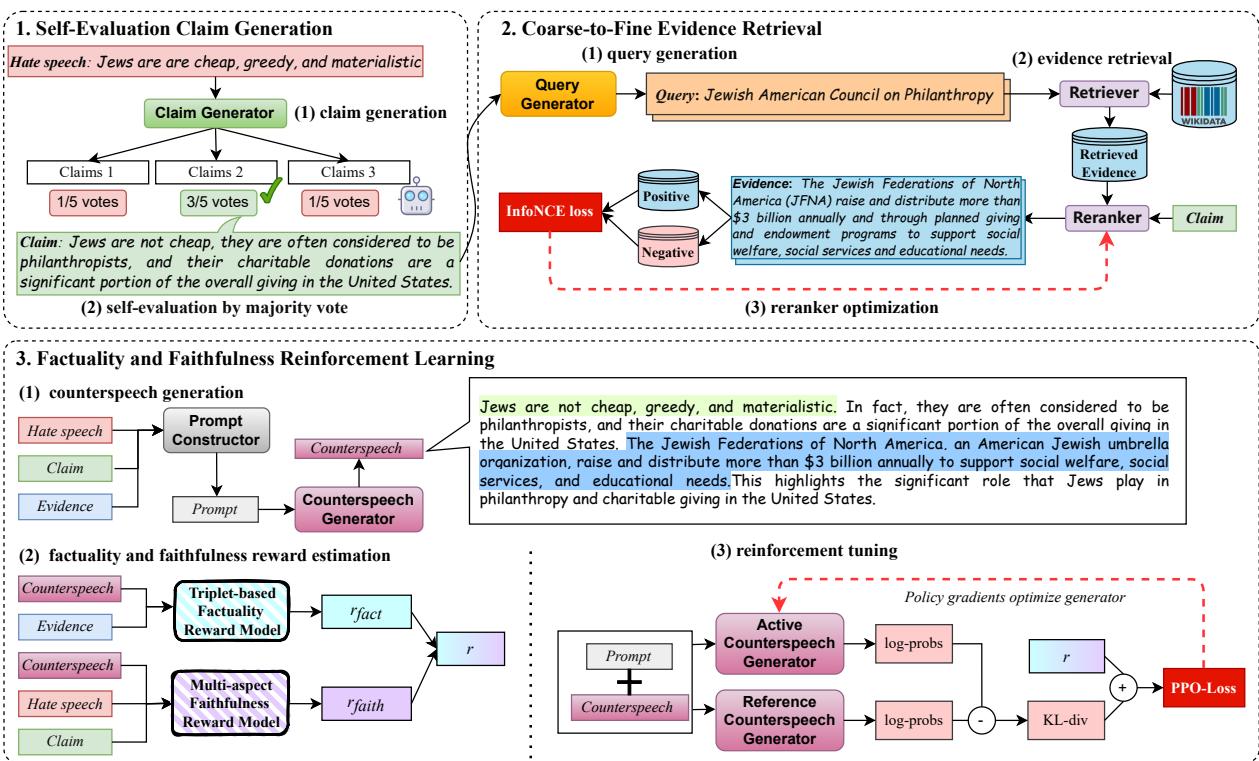
让我们分解每个模块,以理解这种方法背后的工程设计。
模块 1: 自评观点生成
标准方法通常试图直接基于仇恨言论检索证据。问题在于,仇恨言论往往是模糊或情绪化的。搜索“仇恨言论关键词”可能会返回不相关的数据。
F2RL 增加了一个中间步骤: 反驳观点 (The Counter-Claim) 。
在寻找事实之前,模型会生成一个特定的辩论策略。然而,LLM 可能会生成薄弱的论点。为了解决这个问题,作者实施了一个自评 (Self-Evaluation) 机制。
- 生成: LLM 生成多个潜在观点 (例如,5 种反驳该陈述的不同方式) 。
- 投票: LLM 充当法官,审查自己生成的观点,并投票选出最能有效反驳仇恨言论的那个。
这确保了反驳言论的基础——核心论点——在收集任何证据之前就是坚实的。
模块 2: 由粗到细的证据检索
一旦系统拥有了一个获胜的观点,它就需要证明。简单的谷歌搜索 (或数据库查找) 是不够的,因为“观点”和“证据”之间的鸿沟可能很大。
研究人员提出了由粗到细 (Coarse-to-Fine) 的策略:
- 查询生成: 模型基于选定的观点生成搜索查询。
- 粗略检索 (撒大网) : 使用名为 Contriever 的工具,系统从维基百科中提取大量可能相关的文档。这确保了多样性。
- 精细重排序 (过滤器) : 这是有趣的地方。第二个模型 (BGE M3) 查看检索到的文档,并根据它们对特定观点的支持程度进行打分。
优化重排序器
为了让重排序器变得聪明,他们使用对比学习 (Contrastive Learning) 来训练它。他们希望模型在向量空间中将“观点”和“正样本证据”拉得更近,同时推开“负样本证据”。
这是通过数学上的 InfoNCE 损失函数实现的。
首先,总损失函数聚合了所有观点和证据对的误差:
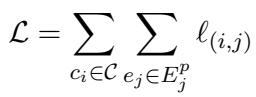
然而,核心机制在于 \(\ell_{(i,j)}\) 这一项。这个方程本质上是计算概率。它最大化观点 \(c_i\) 和正样本证据 \(e^p_j\) 之间的相似度得分 \(s\),同时最小化与负样本证据 \(e^n\) 的相似度:
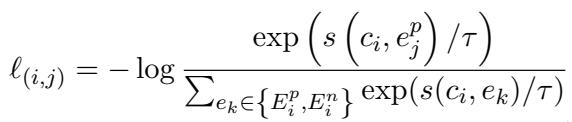
通过最小化这一损失,系统学会了过滤掉不相关的噪音,只保留真正支持该观点的证据。
模块 3: 事实性和忠实性强化学习
这是论文的核心。即使有好的证据,LLM 在最终的文本生成过程中仍可能忽略它或误用它。为了强制 LLM 守规矩,作者使用了强化学习 (RL) , 具体来说是近端策略优化 (PPO) 。
在 RL 中,你需要一个“奖励模型”——一个给学生打分的老师。如果分数高,模型就会学会重复这种行为。F2RL 使用了两个专门的奖励模型。
1. 基于三元组的事实性奖励
如何自动检查一个句子是否真实?作者将生成的文本分解为知识三元组 (主语、关系、宾语) 。
例如,如果生成的文本是“犹太人捐赠了 1000 亿”,三元组就是 (犹太人, 捐赠, 1000亿)。
系统随后检查这个三元组是否被检索到的证据所蕴含 (支持) 。如果证据说“犹太人捐赠了 30 亿”,蕴含得分就会很低,模型就会得到低奖励。
事实性奖励 (\(r_{fact}\)) 的公式计算了证据 (\(e\)) 与从反驳言论 (\(cs\)) 中提取的三元组 (\(t\)) 之间的平均蕴含概率:
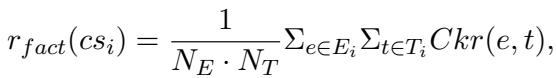
2. 多维度忠实性奖励
仅有事实性是不够的。你可以说一些完全真实但与论点无关的话。 忠实性 (Faithfulness) 确保回复不偏离轨道。作者从三个维度定义忠实性:
- 对仇恨言论的忠实性: 回复是否实际上反对了仇恨言论? (通过立场检测模型衡量) 。
- 对观点的忠实性: 回复是否遵循了选定的反驳观点? (通过语义相似度衡量) 。
- 对证据的忠实性: 回复是否利用了提供的证据? (通过相似度衡量) 。
这些被组合成一个单一的忠实性得分 (\(r_{faith}\)) :
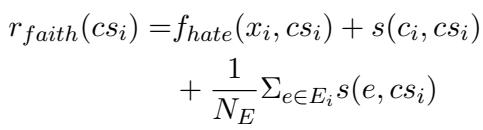
最终目标
系统将事实性和忠实性得分组合成最终奖励 \(r(cs_i)\),其中 \(\gamma\) 是平衡参数:
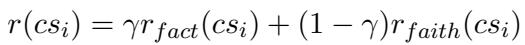
最后,生成器被训练为最大化这一奖励,同时不偏离其原本的语言能力太远 (以保持文本流畅) 。这是 PPO 目标函数,其中 \(D\) 代表 KL 散度 (对过度改变模型的惩罚) :
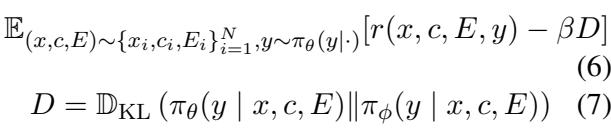
实验与结果
这一切复杂的设计真的有效吗?研究人员在三个基准数据集 (CONAN, MTCONAN, MTKGCONAN) 上测试了 F2RL,使用了不同的基础 LLM (GLM4, Qwen1.5, Llama3) 。
他们将自己的方法与以下方法进行了对比:
- IOP: 简单的输入-输出提示 (Input-Output Prompting) 。
- CoT: 思维链 (生成观点 -> 内部生成证据 -> 撰写回复) 。
- CoTR: 带检索的思维链 (检索证据 -> 撰写回复) 。
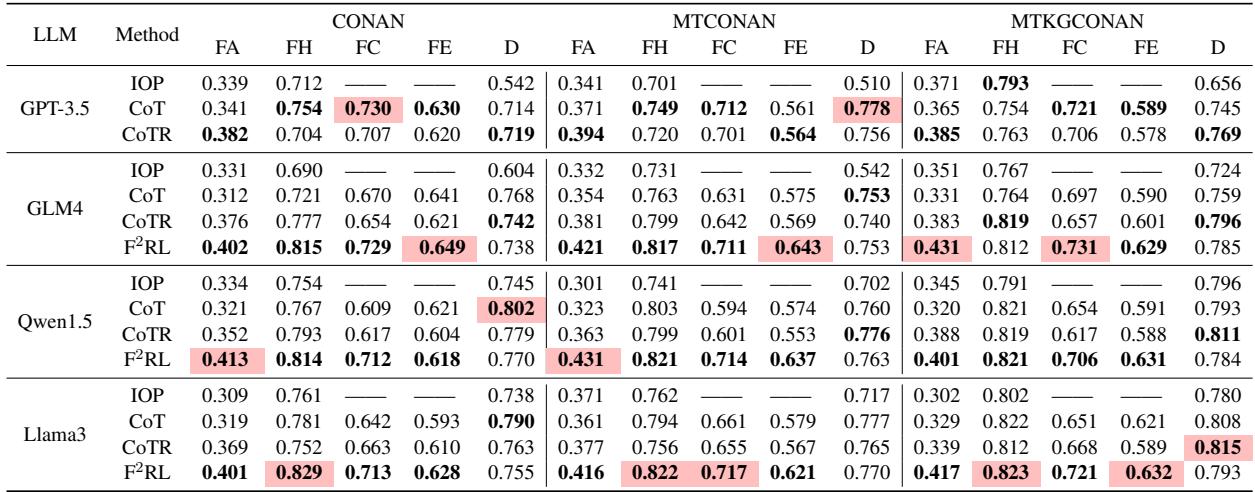
结果令人印象深刻。请看表 1:
数据中的关键结论:
- 事实性提升: 纵观全局,F2RL (带 “F2RL” 的行) 实现了最高的 FA (事实性) 得分。这证明了基于三元组的奖励是有效的。
- 忠实性: 该模型在对仇恨言论( FH )、观点( FC )和证据( FE )的忠实性方面也占据主导地位。
- 一致性: 无论是使用 Llama3 还是 Qwen,该框架都能提升性能,表明这是一个可泛化的方法。
多样性的权衡
这里有一个迷人的陷阱。如果你看上表中的 D (多样性) 一栏,或者下面的图表,你会发现 F2RL 的多样性通常略低于基线模型。
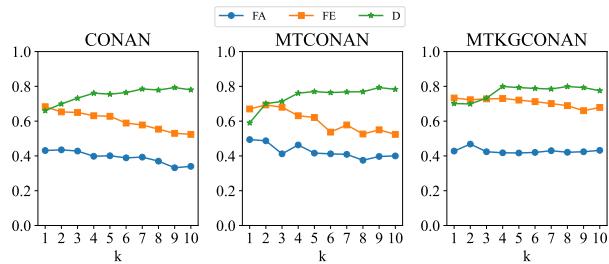
为什么多样性会下降?
- 严格的结构: 模型学习到某些句子结构 (例如,“事实上,[证据]…”) 会产生高回报,因此它会重复使用它们。
- 事实依赖性: 创造力往往需要偏离死板的事实。通过强迫模型坚持证据,“创意写作”的一面受到了限制。
然而,在打击错误信息的背景下, 无聊但真实远胜于有创意但虚假 。
人工评估
指标固然重要,但人类认为这些回复更好吗?作者招募了志愿者对生成的反驳言论进行评分。
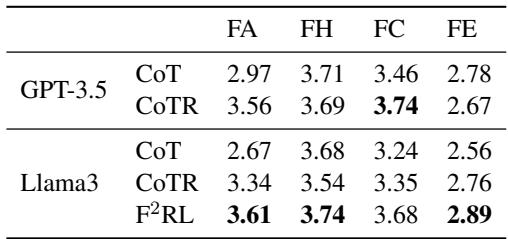
人工评估证实了自动化指标: F2RL 生成的回复被认为比标准提示方法更符合事实且更相关。
结论与启示
F2RL 框架代表了可控文本生成迈出的重要一步。它超越了简单地要求 LLM “提供帮助”,而是设计了一个强制严谨性的流程。
通过明确地将观点 (论点) 与证据 (证明) 分离,然后使用强化学习来惩罚幻觉,研究人员为更安全、更有效的自动化反驳言论创建了一份蓝图。
这项技术的影响不仅限于仇恨言论。同样的“观点引导、证据支持”框架可以应用于:
- 自动化客户支持 (引用具体的政策文件) 。
- 医疗建议摘要 (引用具体的医学期刊) 。
- 教育辅导 (严格遵守教科书材料) 。
虽然没有 AI 是完美的——作者也指出在发布反驳言论之前仍需人工审查——但 F2RL 让我们更接近这样一个世界: AI 帮助净化信息生态系统,而不是用幻觉污染它。