](https://deep-paper.org/en/paper/file-3083/images/cover.png)
引言
想象一下你正在阅读下面这句话:
“I eat an apple while holding my iPhone.” (我手里拿着 iPhone 吃着 apple。)
作为人类,你的大脑会进行极其快速的计算。你瞬间就能明白这里的单词 “apple” 指的是水果,而不是那家科技巨头 Apple Inc.,尽管上下文中包含了 “iPhone” 这个词。这种根据上下文确定单词具体含义的能力被称为 词义消歧 (Word Sense Disambiguation, WSD) 。
很长一段时间以来,WSD 一直是自然语言处理 (NLP) 领域的圣杯。随着 BERT 和 GPT 等强大的预训练语言模型 (LMs) 的出现,社区在很大程度上宣布了胜利。这些配备了“上下文嵌入 (contextualized embeddings)”的模型似乎能轻松处理这些同形异义词,在标准基准测试中达到了近乎人类的表现。
但是,最近一篇题为 “FOOL ME IF YOU CAN!” 的论文提出了一个发人深省的问题: 这个问题真的解决了吗?还是说我们只是给了模型太简单的测试?
来自奥斯纳布吕克大学的研究人员认为,虽然模型擅长模式匹配,但它们可能缺乏真正的语境理解能力。为了证明这一点,他们创建了 FOOL , 这是一个旨在利用对抗性语境来欺骗模型的数据集。在这篇文章中,我们将剖析他们的方法,探索他们如何“攻破”最先进的模型,并分析这对 AI 鲁棒性的未来意味着什么。
背景: 同形异义词与上下文
要理解这篇论文,我们首先需要定义核心的语言学挑战: 同形异义词 (Homonyms) 。 这些词拼写和发音相同,但含义完全无关。
常见的例子包括:
- Bank: 金融机构 vs. 河岸。
- Bat: 夜行性飞行哺乳动物 (蝙蝠) vs. 运动器材 (球棒)。
- Crane: 鸟类 (鹤) vs. 建筑机械 (起重机)。
在 NLP 中,测试模型区分这些含义的能力主要有两种方式:
- 细粒度 WSD: 区分微妙的细微差别 (例如,“bank” 指建筑物 vs. “bank” 指机构本身) 。
- 粗粒度 WSD: 区分完全不同的含义 (河流 vs. 金钱) 。
这项研究侧重于 粗粒度 WSD 。 按照逻辑,这对现代 AI 来说应该很容易。毕竟,如果一个模型已经阅读了整个互联网,它应该知道“羽毛”通常与鸟类 “crane” 有关,而不是推土机。然而,研究人员怀疑模型过分依赖特定的“触发词”,而不是理解整个句子的结构。
核心方法: 构建 “FOOL” 数据集
这项研究的核心是数据集本身的构建。作者不仅仅想测试模型是否知道 “bat” 是什么;他们想测试当句子的其余部分试图欺骗模型时,模型是否还能保持对该含义的理解。
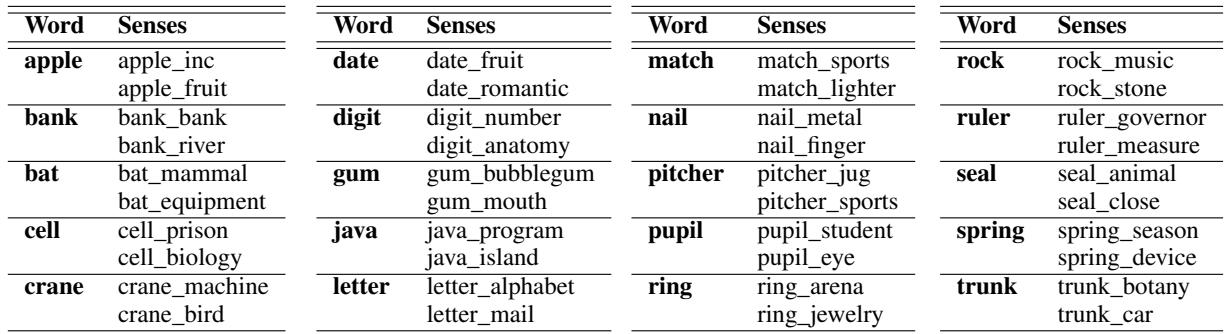
他们创建了一个包含 20 个不同同形异义词的数据集,并将其构建成四个难度递增的测试集。

如上方的 表 1 所示,测试集的复杂性显著增加:
- 集合 1 (常规): 基线。同形异义词用于标准的、预期的上下文中。
- *例子: * “The iPod is first introduced by apple.”
- 集合 2 (常规 + 形容词): 与集合 1 类似,但在目标词之前放置了一个辅助性的形容词。
- *例子: * “The surrounding area produces 20% of Patagonia’s apple…”
- 集合 3 (人工对抗): 这是设下“陷阱”的地方。作者选取一个单词含义为“水果”的句子,但在其中插入一个通常与“公司”含义相关的形容词 (反之亦然) 。
- *例子: * “An innovative apple is a refreshing snack…” (一个创新的苹果是令人耳目一新的零食…)
- 在这里,“innovative” 对统计模型极力暗示着 “Apple Inc.",但语法结构清楚地描述了一种水果。
- 集合 4 (现实对抗): 这些是包含相反语境词的自然、现实的句子。
- *例子: * “Holding an apple, I scrolled through news about rival tech companies.” (手里拿着一个 apple , 我浏览着关于竞争对手科技公司的新闻。)
- 这是最难的测试。句子谈论的是科技公司,但“holding (拿着)”这个物理动作暗示了它是水果。
研究人员策划了 20 个同形异义词来通过这些测试。你可以在下面的 表 2 中看到完整的单词列表及其双重含义。
实验 1: 探测编码器模型的“大脑”
研究人员测试了两类不同的 AI 模型。第一组由 编码器模型 (如 BERT 和 T5) 组成。这些模型同时 (双向) 处理整个句子,并为每个单词创建一个数学表示,即“嵌入 (embedding)”。
为了测试这些模型,研究人员不仅仅是问它们一个问题。他们提取了目标词的 嵌入向量——即模型的内部思维表示。然后,他们使用 k-近邻 (kNN) 算法来观察“Apple (水果)”的嵌入是否与“Apple (公司)”的嵌入分聚类。
如果模型真的理解这种差异,那么向量空间中的数学表示应该相距甚远。
可视化失败
嵌入分析的结果提供了论文中最引人注目的视觉证据。作者使用 t-SNE (一种将高维数据可视化为 2D 的技术) 绘制了模型区分这两种含义的效果。
请看下面的 图 1 。 第一行显示 BERT-base , 第二行显示 T5-base 。
- 橙色点: Crane (鸟)
- 蓝色点: Crane (机器)
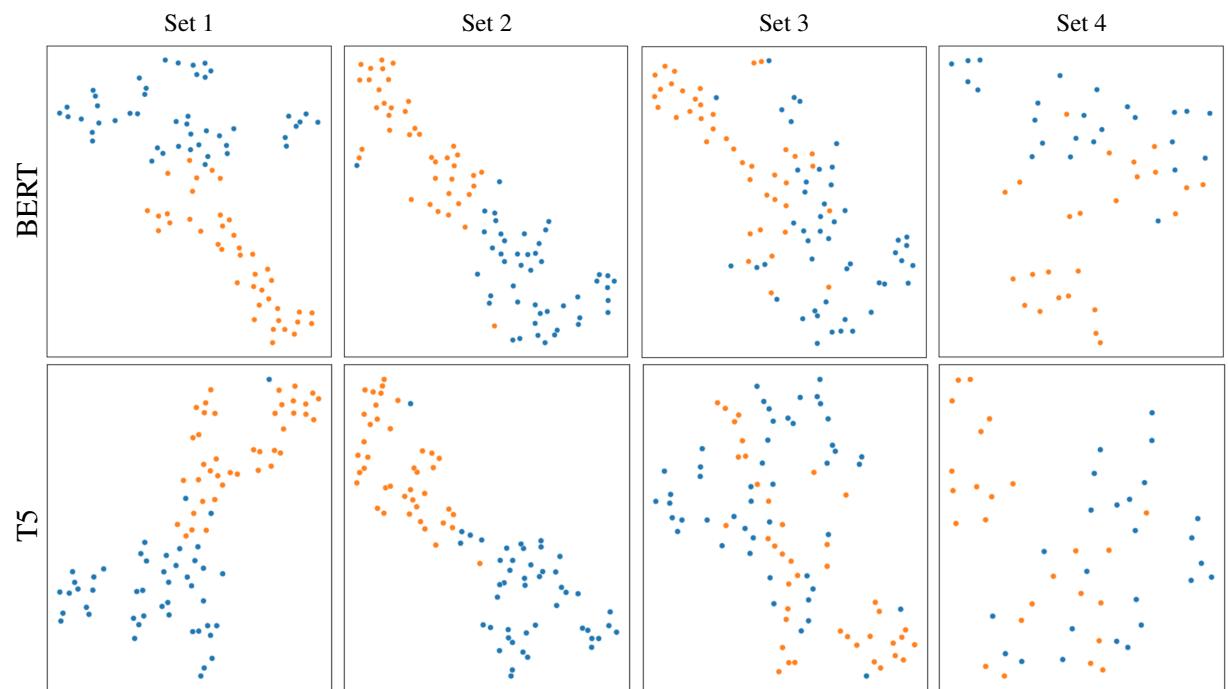
崩溃显而易见:
- 集合 1 & 2: 蓝色和橙色的聚类截然不同。模型清楚地区分了鸟和机器。
- 集合 3: 看看这混乱的场面。聚类开始融合。“对抗性形容词”正在混淆模型的内部表示。
- 集合 4: 在现实对抗设置中,聚类严重重叠。模型经常无法根据其内部几何结构区分词义。
编码器的量化结果
当我们查看原始准确率数据 (F1 分数) 时,趋势证实了视觉数据。 表 3 详细列出了各种 BERT 和 T5 模型的表现。
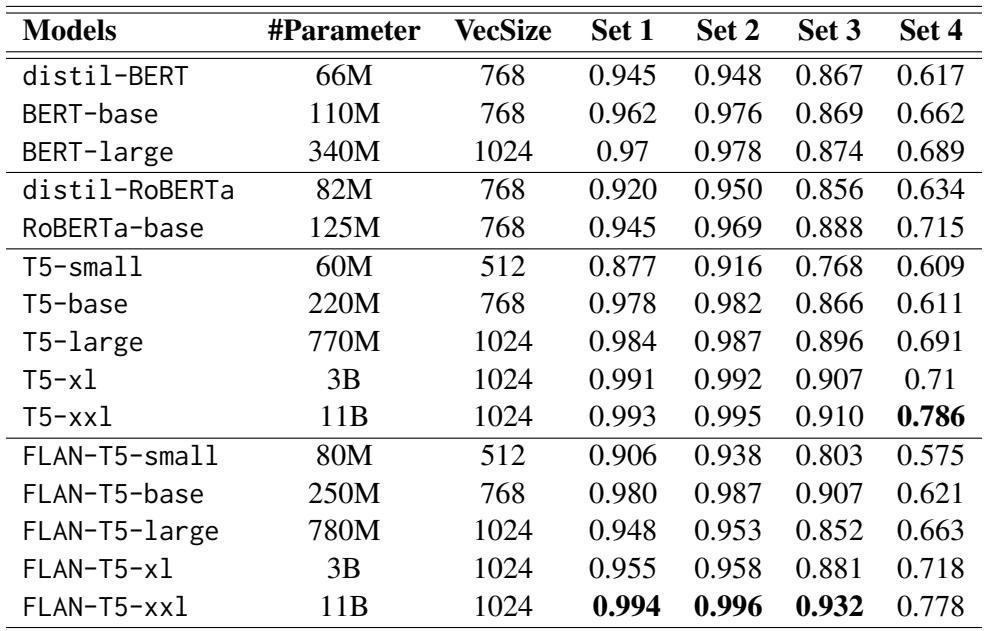
编码器的主要结论:
- 集合 1 & 2 很简单: 几乎每个模型的得分都在 95% 以上。
- “集合 4”的崩盘: 看看这个下降幅度。 BERT-base 从集合 1 的 96.2% 准确率下降到集合 4 的 66.2% 。
- 规模很重要: 更大的模型 (如 T5-xxl) 要稳健得多,在集合 4 上保持了 78% 的得分。这表明仅仅增加参数量有助于模型抵抗欺骗,这可能是因为它捕获了更细微的上下文。
实验 2: 提示大型解码器模型 (LLMs)
第二组测试的模型是 大型解码器模型 , 其中包括 GPT-4、GPT-3.5 Turbo 和 Llama 3 等重量级选手。由于这些模型是为生成文本而设计的,研究人员使用了 零样本提示 (Zero-Shot Prompting) 。
他们本质上是问模型: “将单词 ‘apple’ 的出现分类为水果或公司。”
巨人倒下了吗?
你可能期望 GPT-4 能在这次测试中拿满分。在很大程度上,它做到了——但并非没有跌跌撞撞。
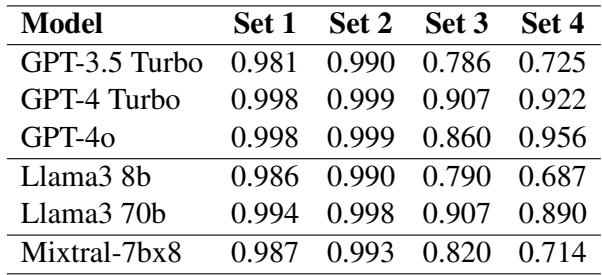
如 表 4 所示:
- GPT-4o 非常稳健,即使在困难的集合 4 上得分也高达 95.6% 。
- GPT-3.5 Turbo 则挣扎得很厉害。它从 98.1% (集合 1) 跌至 72.5% (集合 4)。
- Llama 3 (8b) , 一个较小的开源模型,在集合 4 上崩盘至 68.7% 。
一个有趣的悖论: 研究人员发现了一个迷人的差异。在 集合 3 (插入误导性形容词,如 “innovative apple”) 中,一些较小的编码器模型 (如 BERT-large) 实际上优于巨大的解码器模型。
- BERT-large (集合 3): 87.4%
- GPT-4o (集合 3): 86.0%
这表明双向编码器 (一次看到整个句子) 可能比自回归解码器 (从左到右阅读) 稍微不那么容易受简单“干扰词”的影响,即使解码器在整体上更聪明。
错误分析: 模型在哪里挣扎?
并非所有的词都是生而平等的。研究人员按特定单词细分了错误率,以查看某些概念是否更难以消歧。
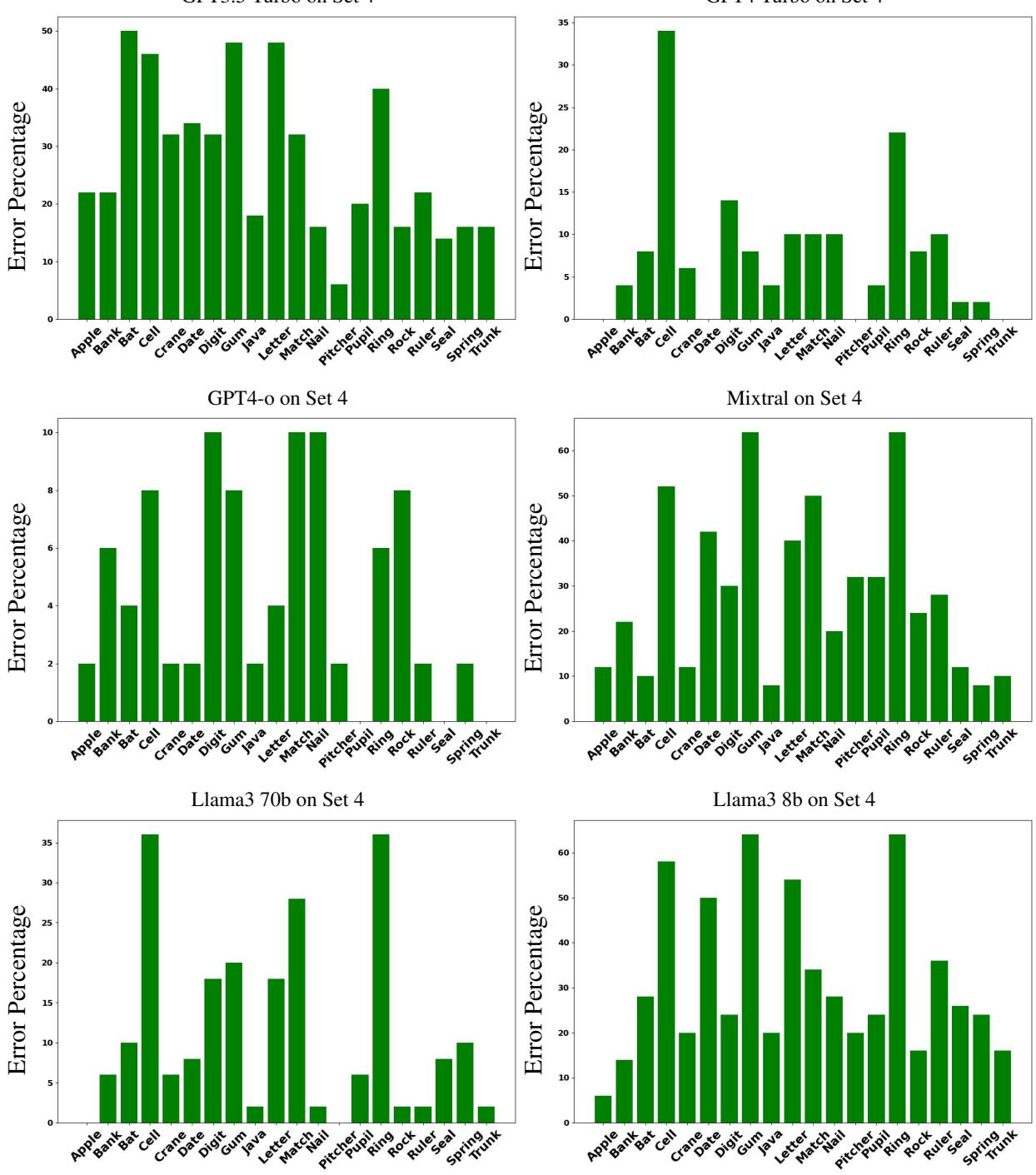
观察 图 9 (上图) ,它显示了困难的 集合 4 上的错误,我们看到某些单词出现了巨大的峰值:
- Digit (数字/手指): 模型很难区分数字 (numbers) 和手指/脚趾 (fingers/toes)。
- Ring (指环/擂台): 在对抗性语境中,竞技场 (Arena) vs. 珠宝 (Jewelry) 很难区分。
为什么是这些词?作者认为,像 “gum” (口香糖 vs. 牙龈) 这样的词共享非常相似的语境 (嘴、牙齿、咀嚼) ,这使得它们比 “Java” (岛屿 vs. 代码) 更难分离,因为后者的含义存在于完全不同的语义宇宙中。
结论与启示
“FOOL” 论文为 AI 行业提供了一个必要的现实检验。虽然我们惊叹于 GPT-4 和 Llama 3 的生成能力,但这项研究强调 鲁棒性问题尚未解决。
给学生和研究人员的要点:
- 不要盲目相信基准测试: 一个模型可能在标准测试 (集合 1) 中得分 99%,但仅仅改变一个形容词 (集合 3) 就会惨败。
- 上下文是脆弱的: 模型通常依赖“触发词” (比如看到 “iPhone” 就假设是 “Apple Inc.”) ,而不是解析句子的语法关系。
- 架构很重要: 编码器 (BERT/T5) 和解码器 (GPT) 以不同的方式失败。编码器在对抗简单的对抗性形容词时出奇地强硬,而巨大的解码器更擅长通过复杂的、现实的场景进行推理。
下次当你使用 LLM 时,请记住: 它看起来可能完全理解你,但它可能距离彻底的混乱仅仅只有一个“创新的形容词”之差。