](https://deep-paper.org/en/paper/file-3113/images/cover.png)
引言: 微调的沉重负担
我们正处于大语言模型 (LLMs) 的黄金时代。从 LLaMA 到 GPT-J,这些模型展示了令人难以置信的生成能力。然而,这里有一个巨大的陷阱: 规模。随着参数量飙升至数十亿,针对特定下游任务 (如数学推理或专业问答) 微调这些庞然大物所需的计算资源,让许多研究人员和学生望尘莫及。
为了解决这个问题,社区转向了参数高效微调 (Parameter Efficient Fine-Tuning, PEFT) 。 像 LoRA (低秩自适应) 和 Prefix Tuning (前缀微调) 这样的方法,通过冻结庞大的预训练模型并仅训练极少一部分新参数,发挥了巨大作用。这些技术已然成为了游戏规则的改变者。
但最近,来自北京邮电大学的研究人员提出了一个发人深省的问题: 我们是否过于平等地对待了这些庞大神经网络的所有层?
目前大多数 PEFT 方法在 Transformer 的每一层都应用相同的策略。然而,根据可解释性研究,我们知道不同的层扮演着不同的角色。底层处理语法和具体细节;顶层处理抽象语义。
在这篇文章中,我们将深入探讨一篇名为 “From Bottom to Top: Extending the Potential of Parameter Efficient Fine-Tuning” 的论文。我们将探索作者如何开发出两种新方法: HLPT 和 H\(^2\)LPT , 它们为不同的层分配不同的微调策略。最令人惊讶的是,我们将发现他们是如何通过完全忽略神经网络中间一半的层 , 在减少超过 70% 可训练参数的情况下,依然实现了最先进的结果。
背景: 并非所有层都生而平等
在深入了解新架构之前,我们需要了解这个配方中的“成分”: LoRA 和 Prefix Tuning,以及关于 Transformer 层作用的直觉。
成分
- LoRA (Low-Rank Adaptation): 这种方法将可训练的低秩矩阵注入模型中。它本质上是以一种非常高效的方式直接修改模型的权重。因为它调整的是权重,所以非常擅长调整特定信息的保留。
- Prefix Tuning: 这种方法在注意力机制的输入前添加可学习的“虚拟 token”。这就像是对模型耳语一个提示词 (prompt) 来引导其行为。它更像是上下文,使其适合引导抽象生成。
层的作用直觉
先前的研究 (如 BERTology 等) 表明,Transformer 在处理语言时存在层级结构:
- 底层 (Bottom Layers) : 关注句子级别的信息、语法和具体细节。
- 中间层 (Middle Layers) : 捕捉句法交互。
- 顶层 (Top Layers) : 存储抽象语义信息并处理高层推理。
作者假设,对每一层都应用相同的微调方法 (比如只用 LoRA 或只用 Prefix) 忽略了这种自然的层级结构。
调查: 位置重要吗?
为了验证他们的假设,研究人员使用 LLaMA-7B 进行了一项有趣的初步实验。他们将模型分为两半: 底层和顶层。然后他们测试了两种配置:
- LoRA + Prefix: 在底层应用 LoRA,在顶层应用 Prefix Tuning。
- Prefix + LoRA: 在底层应用 Prefix Tuning,在顶层应用 LoRA。
结果截然不同。

如上图 Figure 1 所示,排列方式至关重要。
- 左侧 (损失 Loss) : “Prefix+LoRA”设置 (蓝线) 难以有效收敛。而“LoRA+Prefix”设置 (橙线) 收敛得平滑且快速。
- 右侧 (生成) : 当被问及一个简单的数学应用题时,底层用 Prefix 而顶层用 LoRA 的模型完全失败了 (胡编乱造数字) 。而底层用 LoRA 且顶层用 Prefix 的模型回答正确。
结论是什么? LoRA 更适合底层的“具体细节”,而 Prefix Tuning 有助于引导顶层的“抽象概念”。
寻找黄金比例
一旦确定了“底层 LoRA / 顶层 Prefix”是最佳组合,他们需要找到最佳比例。多少层应该是 LoRA,多少层应该是 Prefix?
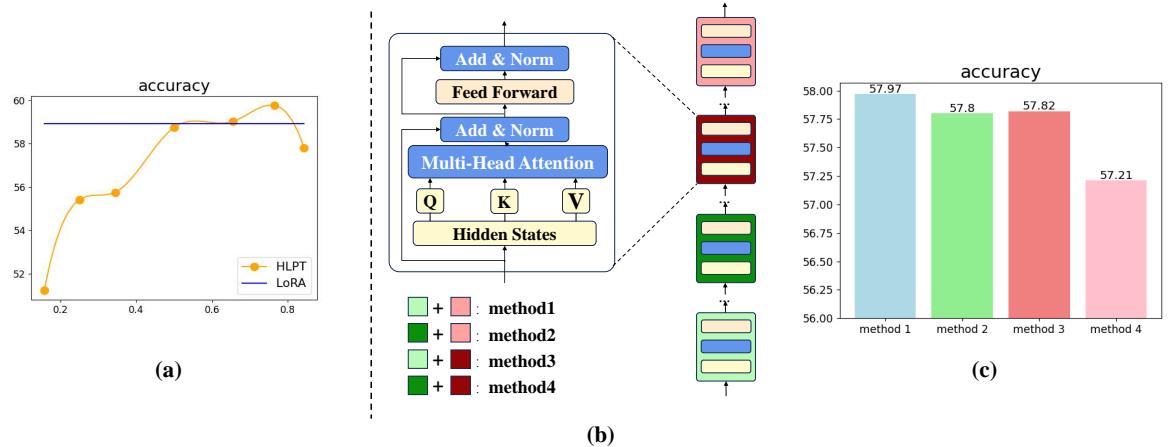
在 Figure 2(a) 中,橙色线追踪了随着比例变化时的准确率。他们发现,大约 3:1 的比例 (即在底部 3/4 的层应用 LoRA,在顶部 1/4 的层应用 Prefix) 能产生最佳性能。
“减半”假设
这才是论文真正有趣的地方。研究人员注意到,微调每一层可能是多余的。如果中间层只是在底层的句法和顶层的语义之间传递信息,我们真的需要微调它们吗?
他们测试了四种减少参数的方法 (如 Figure 2(b) 所示) , Figure 2(c) 中的结果证实了这一点: 你可以跳过微调中间层,而不会造成显著的性能损失。 事实上,这样做有时甚至能通过防止这些过渡层的过拟合或噪声来提高结果。
核心方法: HLPT 和 H\(^2\)LPT
基于这些见解,作者提出了两种独特的架构。
1. HLPT (Hybrid LoRA-Prefix Tuning)
这种方法在底层应用 LoRA (专门针对前馈网络 FFN) ,在顶层应用 Prefix Tuning (针对注意力机制) 。这将微调方法与存储在这些层中的信息类型对齐。
2. H\(^2\)LPT (Half Hybrid LoRA-Prefix Tuning)
这是更激进且更高效的版本。它采用 HLPT 架构,但完全忽略中间层 。 它只微调最底部和最顶部的模块。
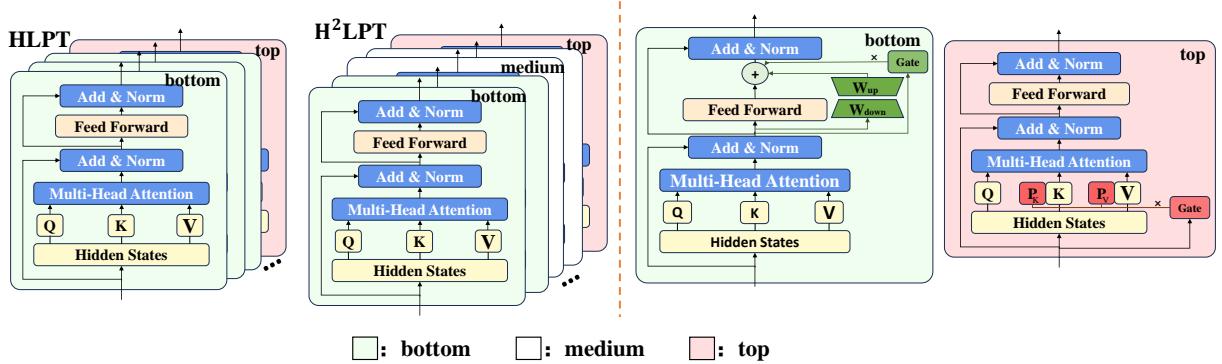
Figure 3 展示了这种差异:
- 左侧 (HLPT): 绿色块 (LoRA) 覆盖底部,粉色块 (Prefix) 覆盖顶部。
- 右侧 (H\(^2\)LPT): 我们看到中间有一个巨大的“空白区域”。这些层被冻结且未被触及。这极大地减少了可训练参数的数量。
幕后机制: 数学原理
让我们看看数学实现。作者不仅是简单地使用了标准的 LoRA 和 Prefix,还增加了一个门控机制 (Gating Mechanism) 对其进行了增强。
基础
首先,回顾一下 Transformer 中的标准注意力 (Attention) 和前馈网络 (FFN) 计算:

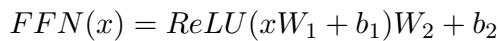
对于 LLaMA,FFN 略有不同 (使用 Swish 激活函数) :
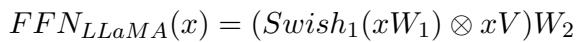
自适应 Prefix Tuning (顶层)
对于顶层,作者使用 Prefix Tuning。他们在键 (Keys) 和值 (Values) 中添加虚拟 token (\(P_k, P_v\)) 。
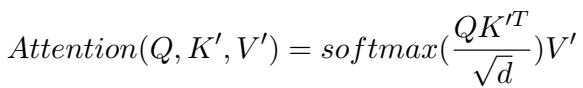
然而,他们引入了一个门控单元 (Gating Unit) (\(g_p\)) 。模型不是添加静态前缀,而是根据输入 \(x\) 计算一个 0 到 1 之间的值。这个门控会对前缀向量进行缩放,允许模型动态决定提示词 (prompt) 应该在多大程度上影响当前的 token 生成。
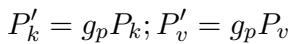
自适应 LoRA (底层)
对于底层,他们应用 LoRA。标准的 LoRA 通常针对注意力机制 (\(W_Q, W_V\)) 。然而,为了进一步区分角色 (因为他们在顶层的注意力上使用了 Prefix) ,作者在底层将 LoRA 应用于前馈网络 (FFN) 。
标准 LoRA 更新规则:
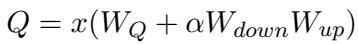
将其应用于 FFN 权重 \(W_2\):
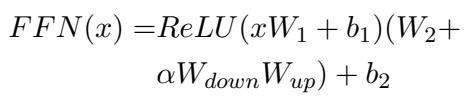
具体针对 LLaMA 架构:
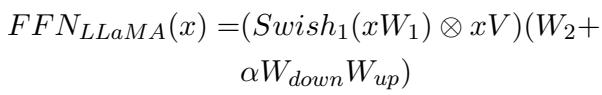
就像 Prefix 层一样,LoRA 层也获得了一个门控单元 (\(g_l\)) 。这允许模型根据 FFN 的输入特征 (\(h_{FN}\)) 动态缩放 LoRA 权重 (\(\alpha\)) 的影响。
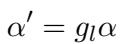
这种自适应门控机制是一个至关重要的补充。这意味着微调不是对模型行为的“硬性”覆盖;而是一种上下文感知的调节。
实验与结果
为了验证这些方法,作者使用 LLaMA-7B、LLaMA-13B 和 GPT-J 在严格的数学推理数据集 (如 GSM8K、SVAMP 和 AQuA) 上进行了测试。这些任务需要严密的逻辑,使其成为测试生成能力的绝佳基准。
主要性能
结果令人印象深刻。让我们看看 Table 1 。
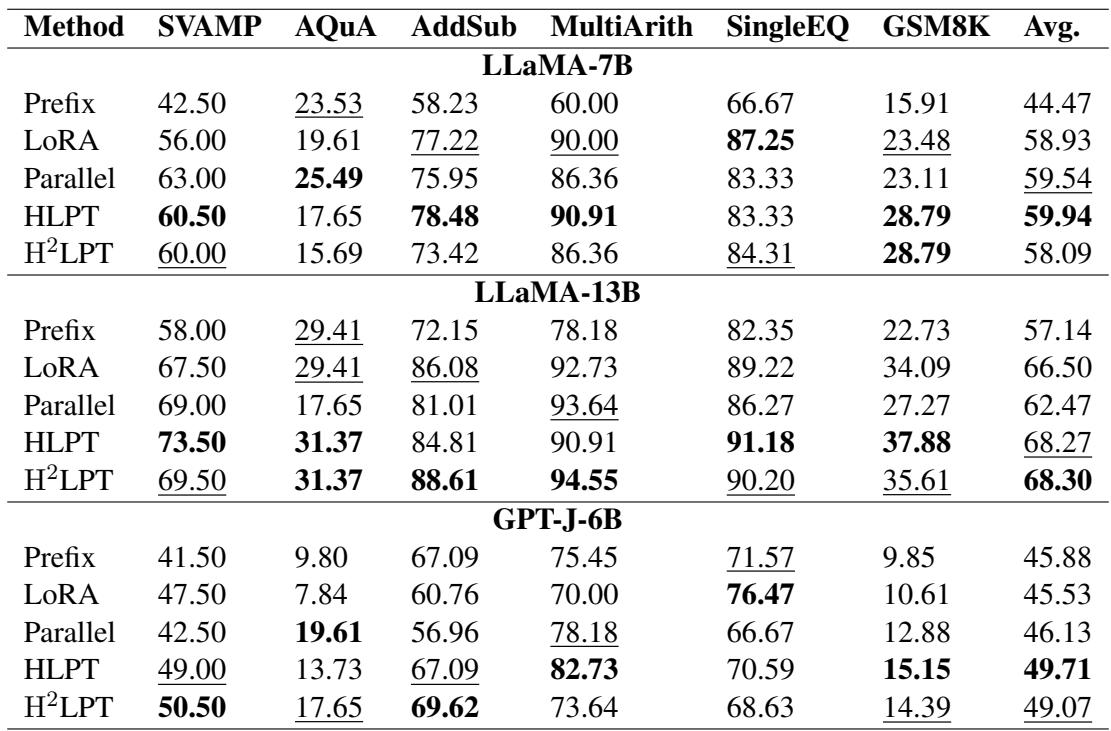
Table 1 的关键结论:
- HLPT vs. 基线: HLPT (混合方法) 在几乎所有数据集上都始终优于标准的 Prefix 和 LoRA 微调。例如,在使用 LLaMA-7B 的 SVAMP 数据集上,HLPT 得分为 60.50 , 而 LoRA 为 56.00 。
- H\(^2\)LPT 的威力: 看一下 H\(^2\)LPT 这一行。尽管它微调的层数少得多 (忽略了中间层) ,但它依然保持了竞争力,甚至经常击败完整的 HLPT 和标准 LoRA 模型。
- 规模扩展: 这种优势在更大的 LLaMA-13B 模型上依然存在,HLPT 取得了 68.27 的最高平均分。
鲁棒性与效率
这种方法最有力的论据之一是其在训练过程中的表现。
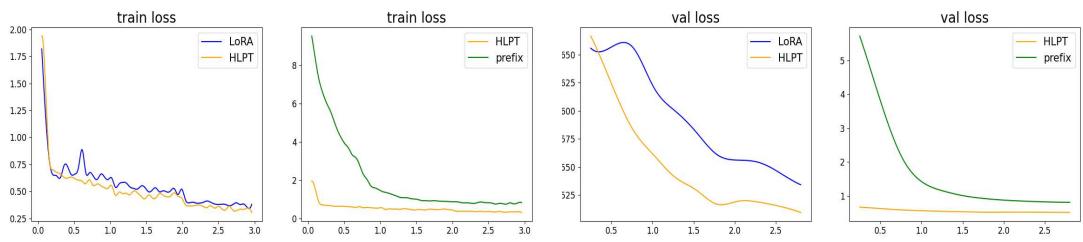
Figure 4 比较了训练损失 (左) 和验证损失 (右) 。
- 蓝线 (LoRA): 注意其波动性。损失跳来跳去,表明训练不稳定。
- 橙线 (HLPT): 曲线非常平滑。混合方法结合门控机制,带来了更加稳定的收敛。
此外,参数效率也极高。

- (注: 虽然完整的表格未在图片组中显示,但文本总结了这些发现) *。与标准 LoRA 和 HLPT 相比,H\(^2\)LPT 将参数量减少了近 50% , 但仍实现了相当或更好的准确率。这意味着更低的存储成本和稍快的训练时间。
消融实验: 我们真的需要门控吗?
你可能会问,“究竟是层分割起的作用,还是那些花哨的门控机制?”作者进行了消融研究来找出答案。
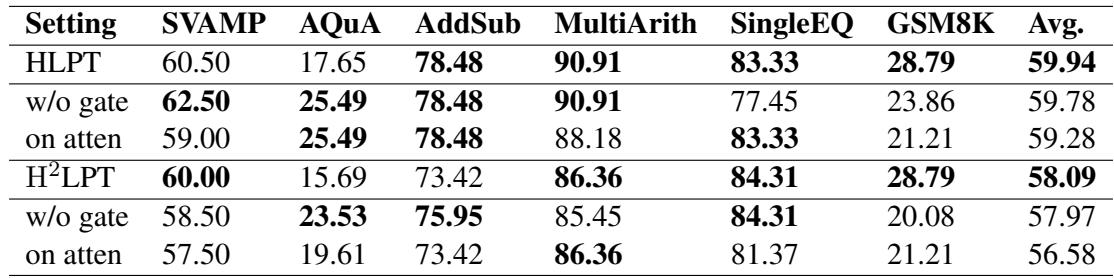
Table 3 展示了移除组件后的情况:
- w/o gate (无门控) : 移除门控机制会导致性能下降 (HLPT 的平均分从 59.94 降至 59.78) 。门控确实有帮助,但它们不是成功的唯一原因。
- on atten (在注意力层) : 将 LoRA 移回注意力层 (而不是 FFN) 也会损害性能。这证实了分离“位置” (LoRA 在 FFN,Prefix 在注意力层) 是有益的。
结论: 少即是多
论文 “From Bottom to Top” 为我们如何看待大语言模型提供了一个全新的视角。作者不再将模型视为每一层都平等的整体,而是证明了尊重信息的层级结构——底层的句法,顶层的语义——可以释放出更好的性能。
H\(^2\)LPT 的引入对于硬件有限的学生和研究人员来说可能是最令人兴奋的贡献。它证明了我们可以有效地“关闭”对巨型模型中间一半层的微调,并且在复杂的推理任务上仍然能够实现最先进的结果。
主要收获:
- 拆分策略: 对底层 (细节) 使用 LoRA,对顶层 (抽象) 使用 Prefix Tuning。
- 针对性组件: 将 LoRA 应用于 FFN,将 Prefix 应用于注意力机制,以实现最大的关注点分离。
- 跳过中间层: Transformer 的中间层对于微调往往是多余的。跳过它们可以节省大量内存而不损害准确性。
- 自适应门控: 让模型决定何时使用微调后的参数可以稳定训练过程。
随着模型不断变大,像 H\(^2\)LPT 这样智能、精准的手术式方法对于保持 AI 的可访问性和高效性将至关重要。