](https://deep-paper.org/en/paper/file-3153/images/cover.png)
引言
想象一下,一位律师走进法庭,对自己的案件充满信心,结果却因为引用的法律判例根本不存在而受到法官的制裁。或者试想一家公司的股票市值瞬间蒸发 1000 亿美元,只因为其 AI 演示错误地声称詹姆斯·韦伯太空望远镜拍摄了第一张系外行星的照片 (事实并非如此) 。
这些并非假设的场景,而是 大型语言模型 (LLM) 幻觉 带来的真实后果。随着 LLM 被整合进搜索引擎、客户服务机器人和专业工作流中,“胡编乱造”的代价变得越来越高昂。
问题在于,自动检测这些错误极其困难。简单的关键词检查是不够的,因为 AI 可以用语法完美且听起来合理的语言说出事实错误的内容。
在这篇文章中,我们将深入探讨 HalluMeasure , 这是亚马逊研究人员提出的一种新研究框架。这篇论文介绍了一套复杂的流程,它不仅会问“这是真的吗?”,还会将 AI 的回答分解为原子级的声明,并使用 思维链 (Chain-of-Thought, CoT) 推理 来评估它们。我们将探索这种方法是如何工作的,为什么“展示推理过程”能帮助 AI 捕捉其他 AI 的谎言,以及它与当前最先进的检测工具相比表现如何。
自动检测的挑战
要理解为什么需要 HalluMeasure,我们首先需要看看目前是如何评估 AI 真实性的。
传统上,测量幻觉通常涉及使用 N-gram 重叠 (ROUGE 分数) 或嵌入相似度 (BERTScore) 等指标来检查生成文本与参考文档之间的相似性。然而,这些指标衡量的是 相似度,而不是 真实性。摘要可以使用与源文本不同的词汇且内容真实,或者使用相似的词汇但内容虚假。
较新的方法使用“自然语言推理” (NLI) 模型将句子分类为“蕴含” (支持) 、“矛盾”或“中立”。虽然这种方法更好,但它们通常在句子层面上运作。来自 LLM 的单个句子可能包含三个不同的事实: 其中两个可能是真的,一个可能是幻觉。如果你一次性评估整个句子,就会失去精确度。
HalluMeasure 通过引入两个重大的策略转变来解决这些问题:
- 细粒度的声明提取: 将回答分解为尽可能小的信息单元。
- 思维链验证: 使用 LLM 在分配标签之前对证据进行推理。
HalluMeasure 架构
HalluMeasure 的核心逻辑是一个多步流水线。系统不是输出分数的“黑盒”,而是模仿人类事实核查员的工作方式: 识别声明、检查来源并推理每个声明的有效性。
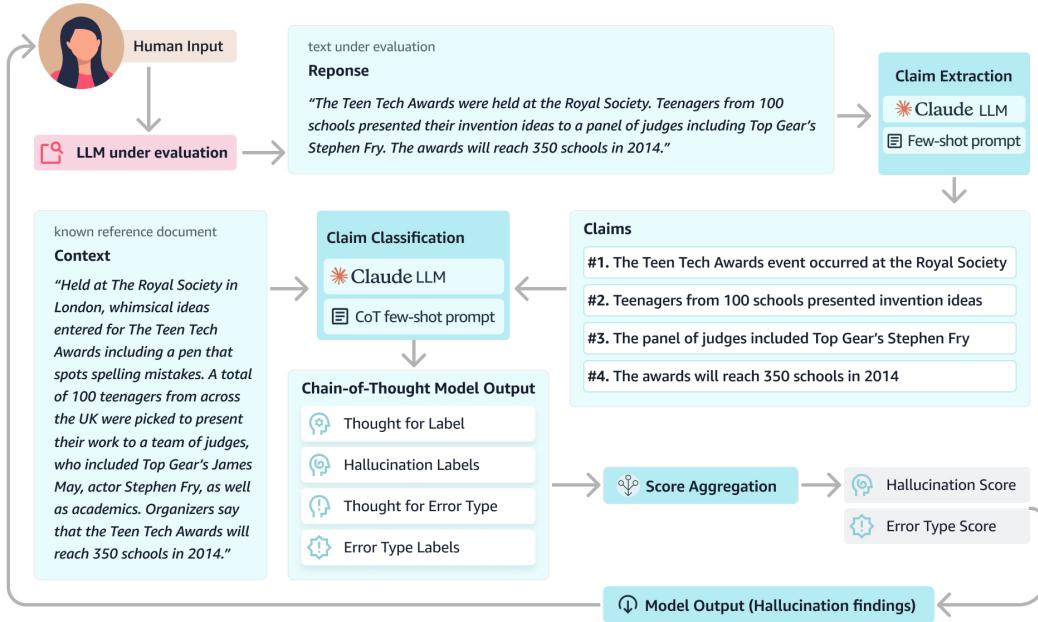
如 图 1 所示,该过程包括三个主要阶段:
- 声明提取: 一个 LLM 将回答分解为原子声明列表。
- 分类: 另一个 LLM (分类器) 将每个声明与参考上下文进行比较。
- 聚合: 系统根据未通过检查的声明数量计算最终的幻觉分数。
第一步: 原子声明提取
第一步至关重要。如果一个 LLM 生成了一个复杂的句子,比如 “三星的 Gear Blink 可能有一个投影键盘,允许你在空中打字,” 如果产品名称是对的但功能是错的,标准的评估器可能难以查明错误。
HalluMeasure 将该响应传递给提取模型 (基于 Claude 2.1 构建) ,该模型将该句子分解为原子声明:
- 三星有一款名为 Gear Blink 的产品。
- Gear Blink 可能有一个投影键盘。
- Gear Blink 的投影键盘将允许在空中打字。
通过隔离这些事实,系统可以将第一个声明标记为“真”,如果上下文不支持,则将第二个标记为“幻觉”。这种粒度防止了一个小错误否定整个原本正确的段落,同时也防止了一个大部分正确的段落掩盖一个危险的谎言。

用于此提取的提示词 (如上方的 图 3 所示) 指示模型创建不包含代词的独立句子,确保每个声明都可以被独立验证。
第二步: 带推理的分类
一旦提取了声明,就必须对其进行分类。这就是 HalluMeasure 与 RefChecker 或 AlignScore 等先前方法不同的地方。
研究人员将声明分类为 5 个高级标签 :
- 支持 (Supported): 上下文确认了该声明。
- 矛盾 (Contradicted): 上下文说法相反 (内在幻觉) 。
- 缺失 (Absent): 上下文未提及此信息 (外在幻觉) 。
- 部分支持 (Partially Supported): 声明大部分正确,但有轻微错误 (如缺少归因) 。
- 无法评估 (Unevaluatable): 声明不是事实陈述 (例如,一个问题) 。
然而,简单地要求 LLM 选择一个标签通常会导致性能不佳。模型可能会根据自己的训练数据而不是提供的上下文进行“猜测”。为了解决这个问题,研究人员利用了 思维链 (CoT) 提示 。
“思考”的力量
在 CoT 配置中,分类器不仅仅被要求提供标签;它被要求先生成一个“想法” (Thought) 。在分配标签之前,它必须解释 为什么 一个声明与文本相符或冲突。
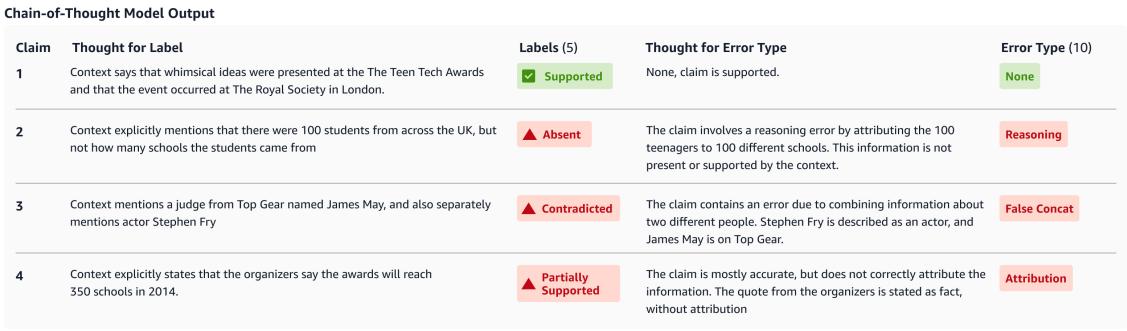
图 2 提供了这种机制运作的完美示例。请看图片中的声明 2:
- 声明 (Claim): “……学生来自 100 所不同的学校。”
- 想法 (Thought): “上下文明确提到有 100 名来自英国各地的学生,但没有提到学生来自多少所学校。”
- 标签 (Label): 缺失 (Absent)。
通过强迫模型阐明差异 (100 名学生 vs. 100 所学校) ,系统降低了模型掩盖细微数字错误的可能性。
细粒度的错误类型
除了主标签外,系统还尝试对错误的 类型 进行分类。这对于试图调试其 LLM 的开发人员至关重要。模型是数学不好吗?还是它搞混了实体?
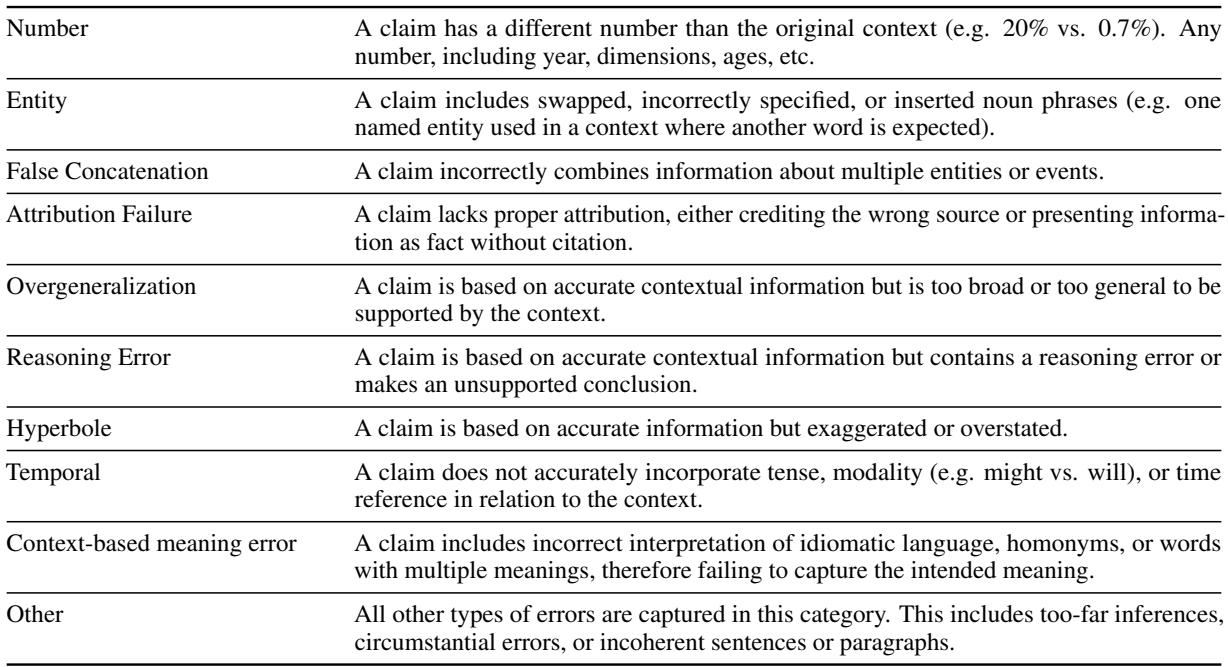
如 表 2 所列,该模型识别 10 种特定的错误子类型,包括:
- 实体错误 (Entity Errors): 交换名称 (例如,说是“Google”而不是“Amazon”) 。
- 错误拼接 (False Concatenation): 将两个独立的事件合并为一个。
- 过度概括 (Overgeneralization): 将特定事实变成一般规则。
- 推理错误 (Reasoning Error): 前提是真的,但 LLM 得出的结论是有缺陷的。
第三步: 提示工程策略
研究人员并没有只满足于一种提示词。他们尝试了四种不同的配置,以在准确性和成本之间找到最佳平衡:
- 无 CoT vs. 有 CoT: 推理步骤真的有帮助吗?
- 全声明评估 (All-claims-eval) vs. 单声明评估 (One-claim-eval): 我们应该在一个提示词中将所有 10 个声明发送给 LLM (批处理) ,还是逐个发送 (单独) ?
下面是 有 CoT + 单声明评估 设置的提示词。这是计算成本最高但理论上最准确的配置。请注意要求模型在决定之前“彻底分析”的详细说明。

相反,下面的提示词显示了 无 CoT 版本。它跳过了推理要求,要求模型直接给出标签。

实验与结果
为了测试 HalluMeasure,作者策划了一个名为 TechNewsSumm 的新数据集 (科技新闻文章摘要) ,并使用了已有的 SummEval 基准。他们将自己的方法与行业基准进行了比较:
- Vectara HHEM
- AlignScore
- RefChecker
思维链有效吗?
结果是决定性的。添加思维链推理显著提升了性能。
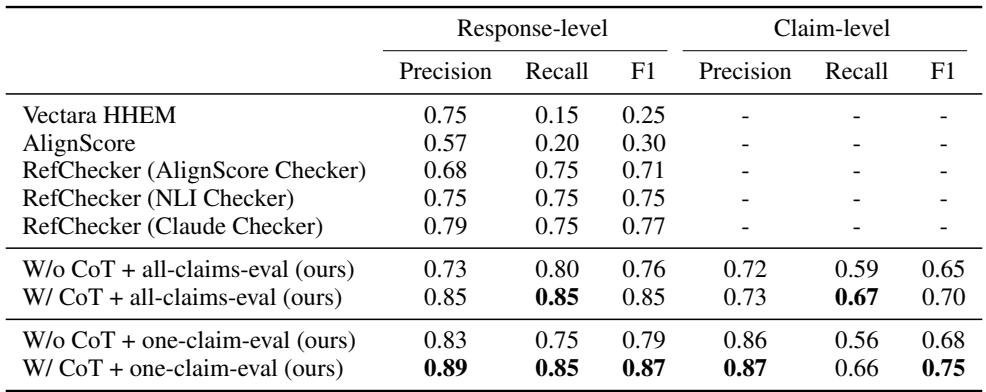
在 表 4 中,查看二元分类 (支持 vs. 不支持) 的 F1 分数。
- RefChecker (Claude) 获得了 0.77 的 F1 分数。
- HalluMeasure (无 CoT) 获得了 0.79 。
- HalluMeasure (有 CoT + 单声明评估) 获得了 0.87 。
TechNewsSumm 数据集上 F1 分数 10 个点的提升 表明,当强迫模型解释其推理过程时,它在检测幻觉方面会变得好得多。
同样,在公共 SummEval 基准测试中,HalluMeasure 优于所有基准。
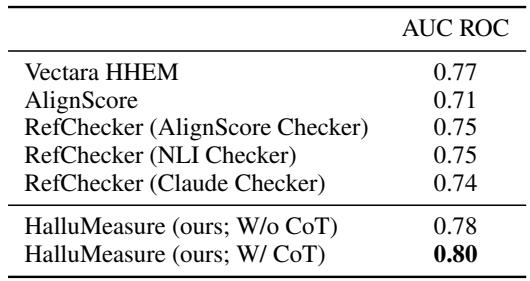
如 表 7 所示,HalluMeasure 的 AUC ROC 达到了 0.80 , 超过了 Vectara (0.77) 和 AlignScore (0.71)。
权衡: 准确性 vs. 效率
虽然使用思维链逐个检查声明能产生最佳准确性,但这既缓慢又昂贵。

表 5 强调了这种权衡。“全声明评估” (批量处理声明) 大约耗时 9.45 秒 (无 CoT) ,而“单声明评估”耗时 42.24 秒 。 当添加 CoT 时,延迟和 Token 数量会进一步增加。
然而,对于准确性至关重要的应用——如法律摘要或医疗建议——“单声明评估 + CoT”方法带来的额外计算成本可能是一笔必要的投资。
它能诊断错误 类型 吗?
虽然 HalluMeasure 擅长检测错误 已经 发生,但它在准确识别究竟是 哪种类型 的错误方面仍很吃力 (例如,区分“推理错误”与“基于上下文的语义错误”) 。
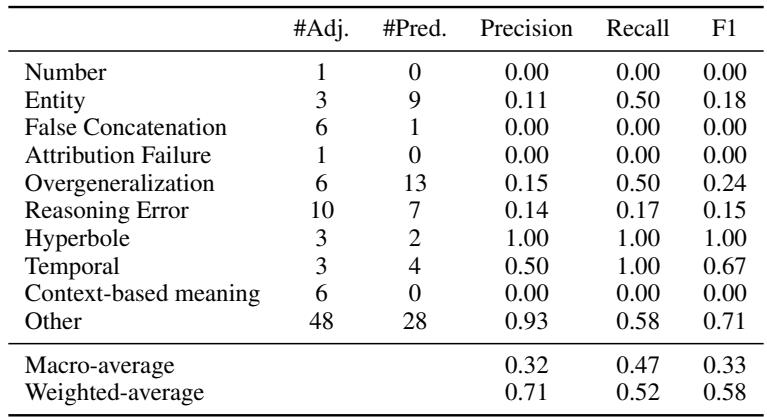
表 6 显示特定子类型的精确率和召回率较低。研究人员将此归因于任务的难度——即使是人类也很难在这些特定标签上达成一致 (标注者间的一致性仅为中等) 。某些类别,如“推理错误”,本质上是主观的,并与其他类别重叠。
泛化到其他 LLM
主要实验使用了 Claude 3 Sonnet。研究人员还测试了该方法在使用 Mistral Large 或 Cohere Command R+ 等开放权重模型时是否有效。
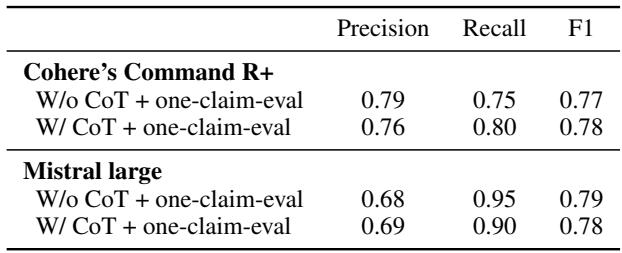
有趣的是, 表 8 显示 Mistral Large 表现相当不错,在 SummEval 上实现了 0.81 的 AUC ROC (实际上在该特定指标上略微超过了 Claude) ,证明了这种 CoT 方法并不局限于单一的专有模型。
结论
“HalluMeasure” 论文提出了一个令人信服的论点,即从简单的相似度评分转向 代理式评估 (agentic evaluation) 。 通过将复杂的文本分解为原子声明,并迫使评估者通过思维链推理“展示其工作过程”,我们可以在幻觉检测方面实现更高的可靠性。
主要收获:
- 分解是关键: 如果不将段落分解为声明,你就无法准确判断它。
- 推理减少错误: 当 LLM 在投票前被提示解释其逻辑时,它们是更好的裁判。
- 逐个分析更胜一筹: 逐个评估声明比批量评估更准确,尽管成本要高得多。
随着 LLM 的不断发展,我们要用来验证它们的工具也必须并行发展。HalluMeasure 代表了向前迈出的重要一步,为构建自动事实核查器提供了蓝图,这些核查器也许有一天会变得足够可靠,从而防止下一次 AI 法律灾难或股市崩盘。