](https://deep-paper.org/en/paper/file-3155/images/cover.png)
在自然语言处理 (NLP) 快速发展的领域中,仇恨言论检测 (HSD) 已成为内容审核的基石。我们已经非常擅长训练模型来标记明显的恶意评论。如果一句话充满了攻击性的脏话或明确的威胁,现代算法能以很高的准确率将其捕捉。
但语言很少如此简单。它是难以捉摸的、微妙的,并且深度依赖于语境。
想想“Oreo (奥利奥) ”这个词。在大多数语境下,它指的是一种流行的饼干。你可能会说: “我总是把奥利奥蘸牛奶吃。”然而,在另一种语境下,同一个词可能被当作针对黑人的种族歧视称谓,暗示他们“外黑内白”。
这种现象给人工智能带来了巨大的挑战。如果一个模型主要是在通用语言上训练的,它会将“奥利奥”视为零食。如果它仅仅依赖标准的字典定义,它看到的是“一种巧克力夹心饼干品牌”。这二者都无法帮助模型理解,在特定语境下,这个词正被用来传播仇恨。
在这篇文章中,我们将深入探讨一篇引人入胜的研究论文,题为 《Hateful Word in Context Classification》 (语境中的仇恨词分类) 。 该研究背后的研究人员引入了一项名为 HateWiC 的新任务。他们认为,我们需要超越分析整句的做法,开始关注特定词汇的含义如何根据说话者、听话者以及词汇出现的语境转变为仇恨性质。
问题所在: 当“描述性”含义不够用时
目前大多数仇恨言论检测系统都在话语层面 (utterance level) 运作。它们获取一条推文或评论,然后将整段内容分类为“仇恨”或“非仇恨”。虽然这种方法对明显的恶意言论有效,但它缺乏精确度。它往往无法指出究竟是哪个词导致了问题,尤其是当这些词本身并非标准的侮辱性词汇时。
研究人员确定了一类特殊的词,称之为 仇恨异质义 (hate-heterogeneous senses) 。 对于这些词,其描述性含义 (字典定义) 并不天生带有仇恨内涵,但其表达性含义 (说话者的态度) 根据用法的不同可能具有高度的仇恨色彩。
为了直观地展示这一点,请看下图。
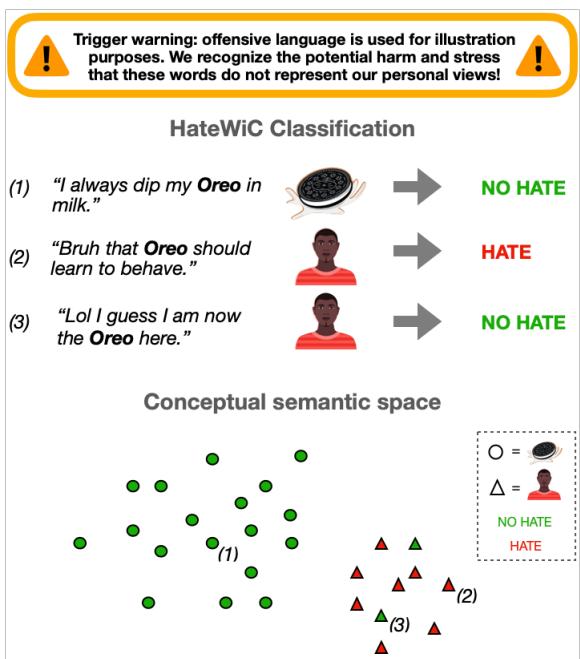
在 图 1 中,我们看到三个涉及“Oreo”的例子:
- “I always dip my Oreo in milk.” (我总是把奥利奥蘸牛奶吃。) (描述性: 饼干。分类: 无仇恨) 。
- “Bruh that Oreo should learn to behave.” (兄弟,那个‘奥利奥’应该学规矩点。) (描述性: 人。分类: 仇恨) 。
- “Lol I guess I am now the Oreo here.” (哈哈,我想我现在是这里的‘奥利奥’了。) (描述性: 人。分类: 无仇恨) 。
注意例 2 和例 3 的复杂性。在这两种情况下,“Oreo”都指代人 (在语义空间中由三角形表示) 。然而,用法 2 是贬义的,而用法 3 是戏谑或自我认同的。一本标准的“侮辱词字典”可能会错过这种区别,而一个标准模型可能会因为它们在语义上相似 (都指人) 而将 2 和 3 归为一类,并将它们与指代饼干的用法区分开。
研究人员认为,要解决这个问题,我们不能仅依靠定义。我们需要对听众的 主观性 和用法的具体 语境 进行建模。
构建 HateWiC 数据集
为了通过计算解决这个问题,作者首先必须构建一个反映这种复杂性的数据集。他们不能直接使用像牛津或韦氏这样的标准字典,因为仇恨言论通常依赖于俚语、新造词和快速演变的街头语言。
相反,他们抓取了 维基词典 (Wiktionary) 的数据。维基词典是用户生成的,这意味着它在非标准用法和攻击性术语方面通常比传统来源更新得更快。他们提取了标记为“冒犯性 (Offensive) ”或“贬义 (Derogatory) ”且属于“人 (People) ”类别的词条。
标注过程
这是该研究与传统数据集的分歧点。通常,研究人员试图找到单一的“基准真相 (ground truth) ”标签。这句话是仇恨言论吗?是或否?
但仇恨是主观的。一个人觉得冒犯的内容,另一个人可能觉得无害。研究人员利用一个名为 Prolific 的平台拥抱了这种主观性。他们召集了一组由 48 名不同年龄、性别和种族的标注者组成的多样化群体。
对于每个实例,标注者会看到:
- 例句。
- 目标词。
- 该词的定义 (确保他们理解预期的含义) 。
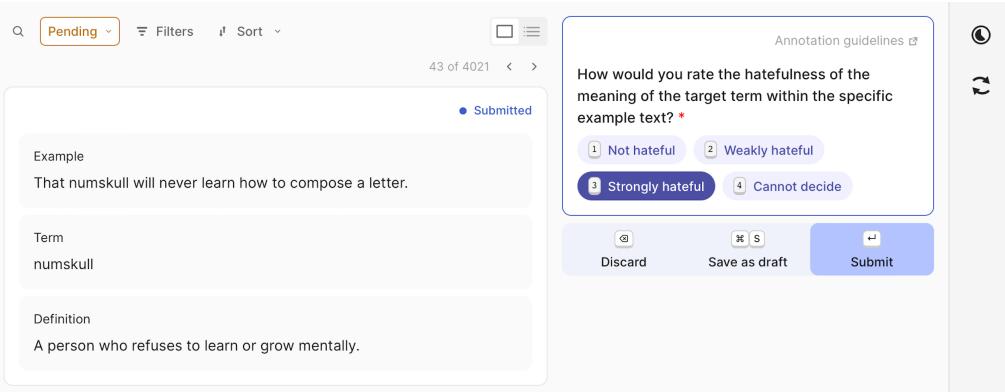
如 图 3 所示,标注者被要求按等级 (无仇恨、轻微仇恨、强烈仇恨) 评价该词在特定语境下含义的仇恨程度。
最终的数据集 HateWiC 包含大约 4,000 个实例。至关重要的是,它包含了标注者的 人口统计信息 。 这使得模型不仅能预测“这是否具有仇恨性?”,还能预测“一位 28 岁的黑人女性会觉得这具有仇恨性吗?”
计算方法
我们如何教机器识别这些变动的含义?研究人员设计了一个分类流程,允许他们尝试不同类型的输入信息。
他们方法的核心是 嵌入分类 (embedding classification) 。 他们采用预训练语言模型 (如 BERT) ,输入各种信息,提取目标词的数学表示 (嵌入) ,然后使用一个简单的分类器 (多层感知机或 MLP) 来做出最终决定。
让我们分解 图 2 中展示的架构。
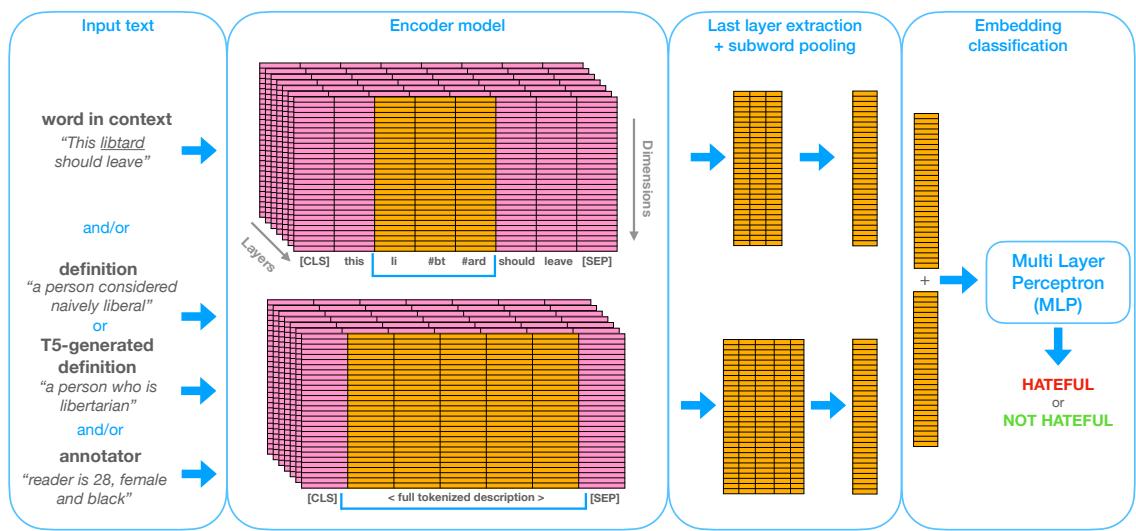
该流程非常灵活,允许研究人员混合和匹配不同类型的信息 (输入) ,以观察什么对模型帮助最大。
1. 输入 (The Inputs)
图中显示了四种潜在的信息来源:
- 语境中的词 (WiC) : 句子本身 (例如,“This libtard should leave”) 。模型关注该句子中特定目标词的嵌入。
- 定义 (Def) : 来自维基词典的字典定义 (例如,“一个被认为天真自由派的人”) 。这为模型提供了“描述性”含义。
- T5 生成的定义 (T5Def) : 这是一个聪明的补充。有时字典定义太死板。研究人员使用另一个 AI 模型 (Flan-T5) 根据具体语境生成一个新的定义。这充当了一个动态的、感知语境的释义。
- 标注者 (Ann) : 这是主观任务的游戏规则改变者。他们向模型提供标注者的文本描述,例如“读者是 28 岁、女性且黑人”。
2. 编码器 (The Encoder)
这些输入由基于 Transformer 的编码器处理。研究人员实验了三种基础模型:
- BERT (基础版) : NLP 的标准主力模型。
- HateBERT: 一个专门在 Reddit 大量辱骂性语言语料库上重新训练过的 BERT 版本。理论上,这应该能更好地理解仇恨言论。
- WSD 双编码器 (WSD Bi-encoder) : 一个专门为词义消歧 (区分不同含义) 训练的模型。
3. 分类 (Classification)
模型结合选定输入的嵌入,并将它们传递给 MLP,MLP 输出二分类结果: 仇恨 或 非仇恨 。
关键实验与结果
研究人员进行了两类主要实验: 预测 多数票标签 (共识观点) 和预测 个体标签 (主观观点) 。
实验 1: 预测共识 (多数票标签)
首先,他们仅仅想知道哪种输入组合能让模型最好地预测大多数人是否认为某个词的用法具有仇恨性。
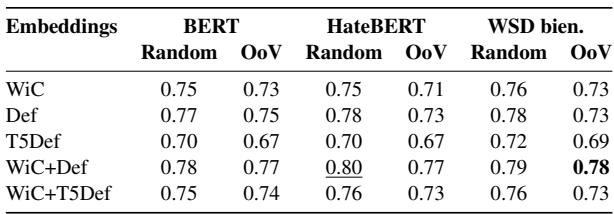
表 2 强调了几个有趣的发现:
- 定义有帮助: 看“随机 (Random) ”一列,加入定义( WiC+Def )通常比仅使用语境中的词( WiC )能提升性能。对于 BERT,准确率从 0.75 跃升至 0.78。这表明提供侮辱性词汇的“官方”含义有助于模型对其用法进行分类。
- HateBERT 并非灵丹妙药: 令人惊讶的是,特定的“HateBERT”模型并没有显著优于标准 BERT 或 WSD 模型。看来对于语境含义这一特定任务,通用的语言理解能力与接触辱骂性文本同样重要。
- 对词汇表外词 (OoV) 的鲁棒性: 标记为“OoV”的列显示了模型在未训练过的词上的表现。在这里, WiC+Def 的组合是明显的赢家。如果模型遇到了从未见过的侮辱性词汇,将定义与语境一起提供对于理解至关重要。
然而,这里有个陷阱。
研究人员进行了更深入的挖掘。还记得 仇恨异质义 (hate-heterogeneous senses) 的概念吗 (那些根据语境可以是仇恨或无辜的词) ?事实证明,在这些特定情况下依赖字典定义可能会适得其反。
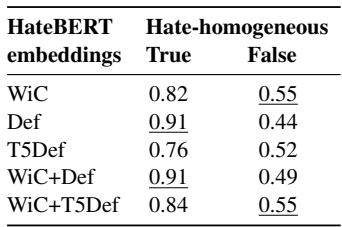
表 3 揭示了一个致命弱点。看 “仇恨同质性为假 (Hate-homogeneous False) ” 这一列。这些是棘手的词——数据集中那些含义会转变的“奥利奥”。
当词汇很简单 (仇恨同质性: 真) 时,加入定义( Def )能带来 0.91 的超高准确率。但当词汇很微妙 (仇恨同质性: 假) 时,使用定义的准确率骤降至 0.44。
为什么? 因为字典定义是静态的。如果定义是“一种巧克力饼干”,而模型严重依赖该描述,即使语境明显是种族歧视,它也很可能会预测为“无仇恨”。这证实了研究人员的假设: 标准定义不足以应对依赖语境的仇恨。
实验 2: 预测主观性 (个体标签)
接下来,研究人员试图预测特定个体的想法。这是一个更难的任务,因为人类对仇恨言论的一致性众所周知地低 (在这个数据集中大约只有 60% 的一致性) 。
这就是 标注者 (Ann) 嵌入发挥作用的地方。告诉模型谁在阅读这段文字能帮助它预测他们的反应吗?
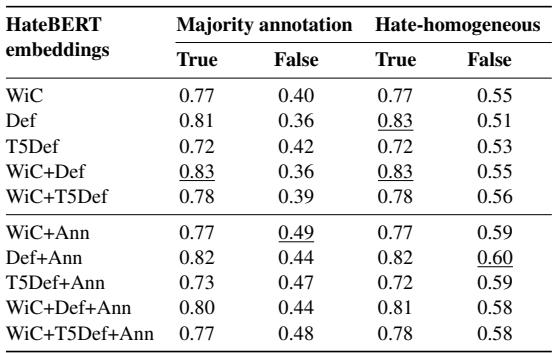
表 5 提供了答案。研究人员分析了个体标注者与多数票意见不一致的情况 (“Majority annotation: False”列) 。
- 仅使用语境中的词( WiC )准确率为 0.40。
- 加入标准定义( WiC+Def )实际上降低了准确率至 0.36。
- 但加入标注者信息 (WiC+Ann) 将准确率提升到了 0.49。
这是一个重大发现。它表明当仇恨言论具有主观性时——当它“取决于观察者”时——知道观察者的身份能让 AI 做出更好的预测。一句话可能对普通大众 (多数人) 来说并不冒犯,但对特定人口群体来说可能极具冒犯性。通过对标注者建模,系统承认了这一现实。
那么大型语言模型 (LLMs) 呢?
你可能会想: “为什么要费劲搞 BERT 和复杂的流程?难道我们不能直接问 ChatGPT 或 LLaMA 吗?”
作者预料到了这个问题。他们使用 LLaMA 2 (7B) 运行了一个零样本 (zero-shot) 实验。他们向模型提示句子和术语,并要求其对含义进行分类。
结果呢?LLaMA 2 达到了 0.68 的准确率。
将此与表 2 中的专用模型相比,后者达到了 0.78 - 0.80 的准确率。尽管大型语言模型被大肆宣传,但在没有微调的情况下,它们在这个特定类型的微妙、主观分类上表现挣扎。它们缺乏那些小型、经过训练的模型所发展出的对“HateWiC”任务的特定理解。
结论与启示
这项关于“语境中的仇恨词”的研究告诉我们,解决仇恨言论不仅仅是向更大的模型投喂更多数据。它需要我们对意义的表示方式进行根本性的转变。
以下是给该领域学生和从业者的主要启示:
- 字典是把双刃剑。 整合定义有助于模型理解新词 (OoV) ,但静态定义可能会让模型对无辜词汇的动态、仇恨用法视而不见。
- 语境为王。 一个仇恨词的含义很少完全包含在词本身之中。它存在于词、句子和说话者意图之间的张力中。
- 仇恨是主观的。 我们不能将仇恨言论检测视为简单的二元真理。包含关于谁在解读文本的人口统计信息,能显著提高在困难、有争议的例子上的表现。
- 生成式定义具有潜力。 实验表明,T5 生成的定义 (基于语境即时创建的定义) 在处理棘手的、异质性的案例时,比静态字典条目更稳健。
随着我们的前进,下一代内容审核系统很可能需要是 个性化 的。与其采用“一刀切”的过滤器,我们可能会看到系统能够理解: 同一个词在某个社区可能是为了重获称谓 (reclaiming a slur) ,而在另一个社区则是攻击。这篇论文为如何实现这一目标提供了一个严谨的架构蓝图。