](https://deep-paper.org/en/paper/file-3250/images/cover.png)
像 GPT-4 和 Llama 2 这样的大型语言模型 (LLM) 彻底改变了我们与技术交互的方式。它们能够总结文档、编写代码并回答复杂的问题。但它们有一个众所周知的“致命弱点”: 幻觉 (Hallucinations) 。
当 LLM 生成的内容听起来看似合理,但实际上事实错误或不忠实于源材料时,就会发生 LLM 幻觉。对于写论文的学生或构建聊天机器人的开发者来说,这是一个严重的可靠性问题。
我们要如何捕捉这些谎言?传统方法通常是一次性检查整个回复,或者逐句进行分解检查。然而,一篇题为 “Knowledge-Centric Hallucination Detection” (以知识为中心的幻觉检测) 的新研究论文认为,我们关注的细节层面是错误的。作者提出了 REFCHECKER , 这是一个通过将文本分解为“主张三元组 (Claim-Triplets) ”——即知识的原子单位——来捕捉幻觉的框架。
在这篇文章中,我们将拆解这篇论文,解释为什么“三元组”是事实核查的未来,并探讨 REFCHECKER 如何超越现有的最先进检测方法。
粒度问题
为了理解为什么检测幻觉很难,想象一下你是一名批改学生历史论文的老师。学生写道: “埃菲尔铁塔由建筑师古斯塔夫·埃菲尔于 1889 年在柏林建造。”
如果你将整个回复评为“错误”,那你并不完全公平。日期是对的。建筑师是对的。地点是错的。
如果你逐句评分,结果仍然是一个二元的“错误”,这掩盖了句子中哪一部分是错误的。
现有的研究通常在三个粒度级别上检查幻觉:
- 响应级 (Response Level) : 检查整个段落。 (太宽泛) 。
- 句子级 (Sentence Level) : 逐句检查。 (好一点,但仍然忽略了细微差别) 。
- 子句级 (Sub-sentence Level) : 提取短语。 (通常结构混乱且难以定义) 。
REFCHECKER 的作者提出了第四种、更优的选择: 知识三元组 (Knowledge Triplets) 。
为什么要用三元组?
知识三元组遵循特定的结构: (主语, 谓语, 宾语) 。
让我们看看论文中关于歌曲 “I Ran (So Far Away)” 的例子。

如图 1 所示,如果我们看这句话 “I Ran (So Far Away) was originally performed by A Flock of Seagulls in 1983,” (I Ran (So Far Away) 最初由 A Flock of Seagulls 于 1983 年演唱) ,句子级检查器可能会直接将其标记为错误。
然而,三元组提取器将其分解为:
- (I Ran, originally performed by, A Flock of Seagulls) -> 正确
- (I Ran, released in, 1983) -> 错误 (实际上是 1982 年)
- (A Flock of Seagulls, is, English new wave band) -> 正确
通过使用三元组,我们隔离了具体的事实错误 (“1983”) ,而没有丢弃正确的信息。这种粒度级别允许更精确的幻觉检测。
REFCHECKER 框架
研究人员开发了一个名为 REFCHECKER 的管道来自动化这一过程。它不仅依赖于专有模型;它被设计为既能与闭源模型 (如 GPT-4) 也能与开源模型 (如 Mistral) 一起工作。
该框架由两个主要阶段组成: 提取器 (Extractor) 和检查器 (Checker) 。
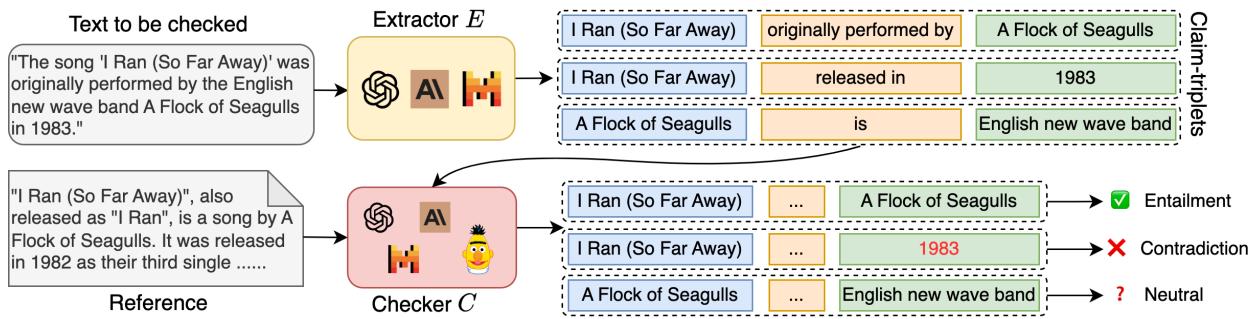
1. 提取器 (E)
提取器的工作是获取 LLM 的回复并将其分解为主张三元组列表。
- 输入: 原始文本回复。
- 过程: 模型 (例如 GPT-4 或微调过的 Mistral 7B) 识别陈述性语句并将其转换为 (主语, 谓语, 宾语) 格式。
- 输出: 三元组列表。
作者发现,虽然 GPT-4 是一个很好的提取器,但通过使用知识蒸馏对较小的开源模型 (Mistral 7B) 进行微调,他们可以获得相当的性能。
2. 检查器 (C)
检查器获取提取出的三元组,并根据参考 (Reference) (基本事实文本) 对其进行验证。
- 输入: 一个特定的三元组和参考文本。
- 过程: 检查器确定主张与参考之间的关系。
- 输出: 三个标签之一:
- 蕴含 (Entailment) : 参考确认三元组为真。
- 矛盾 (Contradiction) : 参考证明三元组为假。
- 中立 (Neutral) : 参考不包含足够的信息来验证三元组。
这个“中立”类别至关重要。许多以前的系统只使用二元标签 (事实 vs. 非事实) ,这混淆了直接的谎言与仅仅是无法验证的信息。
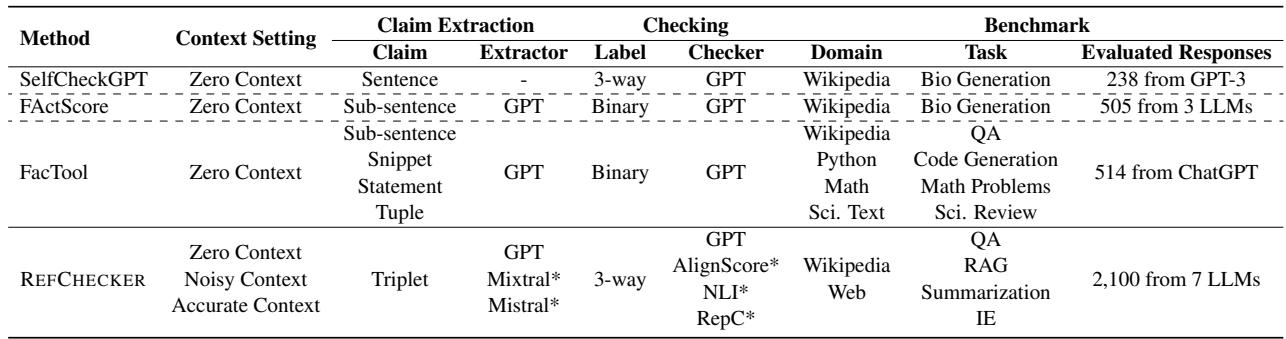
与以前方法的比较
下表 1 展示了 REFCHECKER 与其他流行工具 (如 SelfCheckGPT、FActScore 和 FacTool) 的区别。请注意 REFCHECKER 如何覆盖更广泛的上下文并使用独特的三元组粒度。
三种幻觉设定
并非所有的幻觉都发生在相同的语境中。聊天机器人编造历史事实与摘要工具错误引用文档是不同的。作者将这些情况分类为三种不同的设定,如图 3 所示。
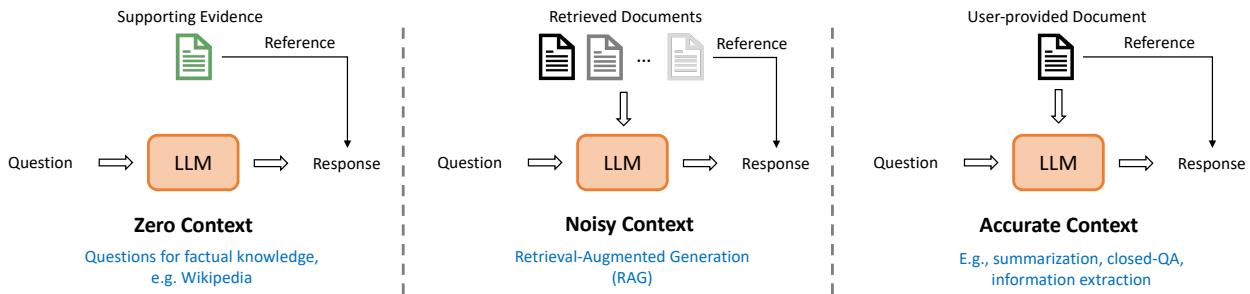
- 零上下文 (Zero Context, ZC) : 模型必须完全依赖其内部记忆 (例如,“谁赢得了 2010 年世界杯?”) 。提示中没有提供参考文档。
- 噪声上下文 (Noisy Context, NC) : 这代表了 检索增强生成 (RAG) 场景。模型被给予从搜索引擎检索到的几份文档,其中一些可能是不相关的,并且必须回答一个问题。
- 精确上下文 (Accurate Context, AC) : 模型被给予一份特定的、干净的文档,并被要求对其进行总结或提取信息。
构建基准: KNOWHALBENCH
为了测试他们的框架,研究人员不能依赖现有的数据集,因为它们在范围或粒度上都太有限了。他们建立了一个名为 KNOWHALBENCH 的新基准。
他们策划了 300 个“困难”示例 (每种上下文设定 100 个) ,并收集了 7 个不同 LLM (包括 GPT-4、Claude 2 和 Llama 2) 的回复。
至关重要的是,他们对这些回复进行了人工评估 。 标注员手动审查了从 2,100 个回复中生成的 11,000 个主张三元组 。 这创建了一个金标准数据集,用于查看 REFCHECKER 的自动裁决是否与人类判断一致。
实验结果
那么,三元组方法真的更有效吗?结果令人信服。
1. 粒度很重要
研究人员比较了检查器在响应级、句子级、子句级和三元组级别上运行时的性能。
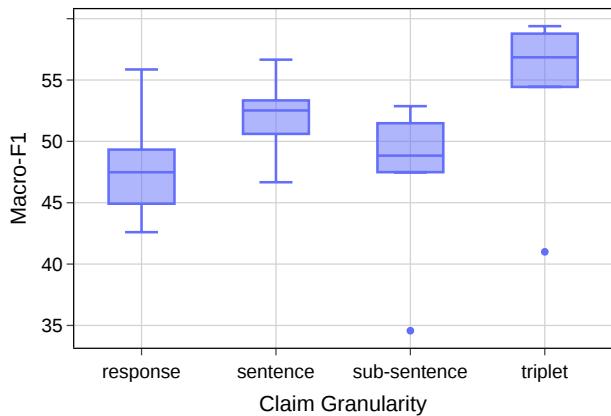
图 4 显示了 F1 分数 (准确度的一种度量) 的分布。
- 响应级检查 (最左侧) 的中位数分数较低。
- 句子级略有提高。
- 子句级实际上出现了性能下降,可能是因为提取一致的子句很困难。
- 三元组级 (最右侧) 实现了最高的中位数性能。
这证实了假设: 三元组是事实核查的最佳单位。
2. 击败基线
作者将 REFCHECKER 与流行的 SelfCheckGPT 方法进行了比较。SelfCheckGPT 是一种“零资源”方法,通过对多个回复进行采样并检查一致性来检测幻觉。
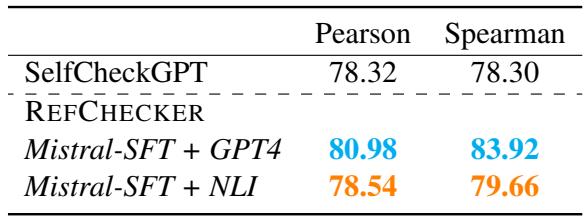
如表 3 所示,REFCHECKER 在与人类判断的相关性方面优于 SelfCheckGPT。值得注意的是,即使是开源配置 (Mistral-SFT + NLI) 也击败了标准的 SelfCheckGPT 设置。这表明,针对参考进行的单一逻辑检查通常比对多个随机回复进行统计比较更有效。
3. 开源模型 vs. 专有模型
对于学生和开发人员来说,最令人鼓舞的发现之一是,你不需要 GPT-4 就能构建一个好的幻觉检测器。
研究人员测试了提取器和检查器的各种组合。他们发现, 微调后的 Mistral 7B 模型 (Mistral-SFT) 在提取任务上的表现几乎与 GPT-4 一样好。
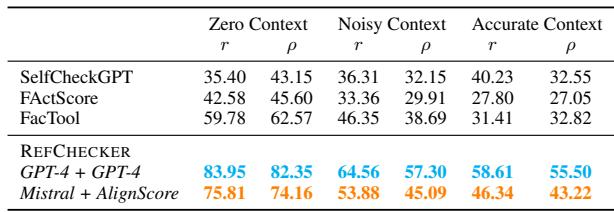
在表 5 中,观察 F1 分数, Mistral-SFT 模型 (86.4) 非常接近 GPT-4 (89.3),而且速度显著更快 (每次迭代 1.7 秒 vs 8.7 秒) 。
对于检查器组件,他们尝试了 NLI (自然语言推理) 模型和微调后的 Mistral 模型。
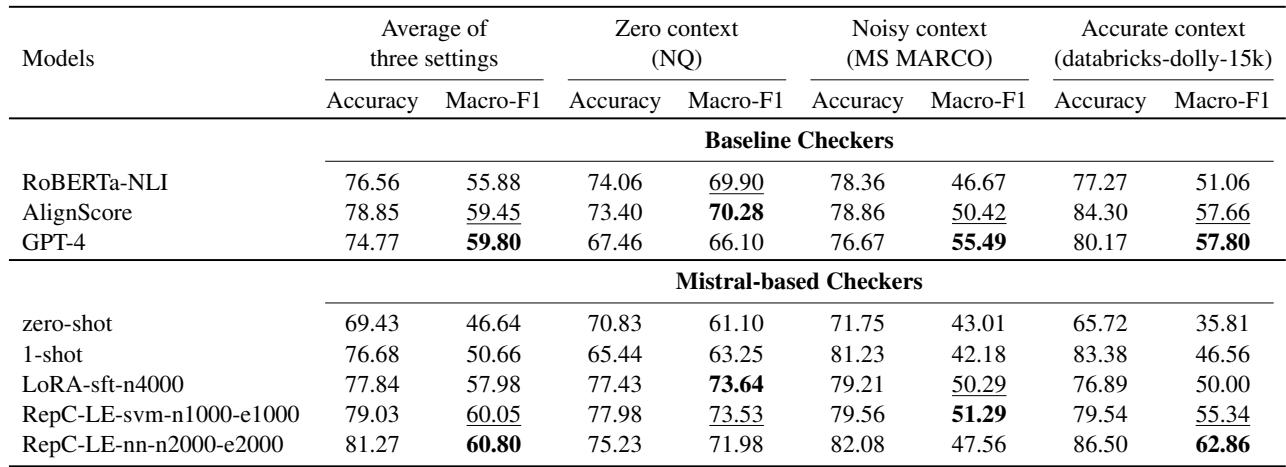
表 6 显示,虽然 GPT-4 是一个强大的检查器,但专门的小型模型 (如 AlignScore )和微调后的 Mistral 变体 (如 RepC-LE-nn )极具竞争力。这为在你自己的硬件上本地运行高质量的幻觉检测铺平了道路。
模型为什么会产生幻觉?来自数据的见解
除了工具本身,该论文还提供了关于这些模型为什么会失败的有趣见解。
“复制”安全网
研究人员分析了模型从源文本中“复制”多少内容与其真实性之间的关系。
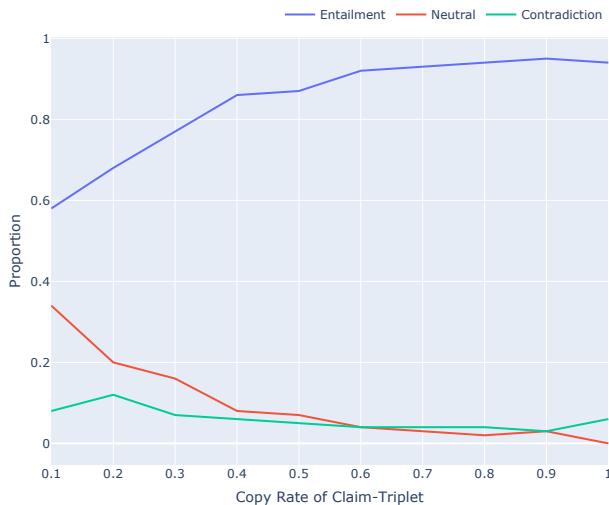
图 11 显示了一个清晰的趋势:
- 蓝线 (蕴含/真相) : 随着复制率的增加而上升。
- 绿/红线 (矛盾/中立) : 随着复制率的增加而下降。
本质上, 复制是安全的。 当模型试图过度解释或综合信息时,产生幻觉的风险就会激增。
内部知识偏差
团队还发现了一种他们称之为“内部知识偏差”的现象。即使你为 LLM 提供了一份特定的文档 (精确上下文) ,如果该文档与模型在预训练期间学到的内容相矛盾,模型往往会忽略它。
例如,如果你提供一篇说“地球是平的”的假新闻文章,并要求模型根据该文章提取事实,模型可能仍然会拒绝或幻觉出一个更正,因为它的内部权重“知道”地球是圆的。虽然这看起来很有帮助,但在严格的事实提取或摘要任务中,这在技术上属于未能遵循指令。
结论与启示
REFCHECKER 论文对 AI 安全领域做出了重大贡献。通过将焦点从句子转移到主张三元组 , 研究人员找到了一种以更高精度定位幻觉的方法。
给学生和开发者的关键启示:
- 粒度是关键: 在构建评估系统时,不要只看整个答案。将其拆解。
- 三元组很强大: 主语-谓语-宾语结构是用于机器验证知识的稳健方式。
- 开源是可行的: 你可以使用像 Mistral 7B 这样较小的微调模型构建最先进的检测系统,从而减少对昂贵 API (如 GPT-4) 的依赖。
- 上下文很重要: 幻觉检测策略必须根据模型是在进行闭卷问答、RAG 还是摘要而改变。
随着我们继续将 LLM 集成到关键工作流中,像 REFCHECKER 这样的工具将成为事实的必要“拼写检查器”,确保 AI 革命保持立足于现实。
本博客文章中使用的图片来源于 Hu 等人的论文 “Knowledge-Centric Hallucination Detection”。