](https://deep-paper.org/en/paper/file-3307/images/cover.png)
如果你是一名软件开发人员,或者正在学习成为一名开发人员,你可能对“周五下午的提交”并不陌生。你刚刚完成了一个复杂的错误修复,身心俱疲,最不想做的事情就是写一段详细的解释,说明 为什么 你修改了这十行代码。于是你输入 git commit -m "fix bug" 然后就下班了。
虽然这种做法可以理解,但它给代码的可维护性带来了噩梦。提交信息 (Commit messages) 是软件项目的历史记录。它们解释了变更背后的意图,使得未来的开发人员 (或者未来的你) 无需重读每一行代码就能理解代码库的演变。
因为这是一项极其枯燥的任务,研究人员长期以来一直试图将其自动化。然而,大多数现有的工具都面临着一个根本性的问题: 它们只关注 Diff——即实际添加或删除的代码行。它们缺乏 上下文 (Context) 。
在这篇文章中,我们将深入探讨一篇引人入胜的研究论文,题为 “Leveraging Context-Aware Prompting for Commit Message Generation” (利用上下文感知提示生成提交信息) 。我们将探索研究人员如何开发一种名为 COMMIT 的新模型,该模型使用代码属性图 (CPG) 来理解变更代码与周围程序之间的语义关系,在生成准确摘要方面显著优于甚至像 GPT-3.5 和 Code-Llama 这样的大型语言模型 (LLM) 。
问题所在: 为什么仅有 Diff 是不够的
要理解这里的创新,我们首先需要了解当前方法的局限性。大多数自动提交信息生成器将代码变更视为文本翻译任务。它们将“Diff”作为输入,试图将其“翻译”成英语。
问题在于,Diff 告诉你 什么 变了,但很少告诉你 为什么。
请看下面的例子。
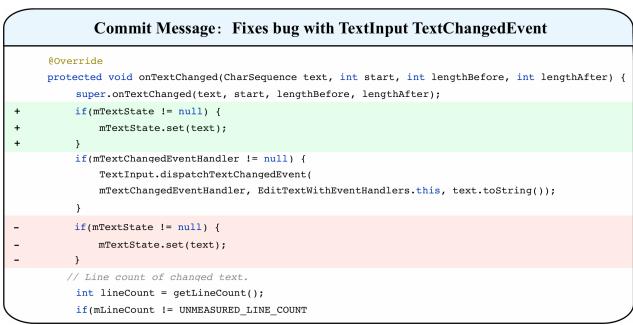
在图 1 中,注意这个变更。开发人员删除了对 mTextState != null 的检查,并添加了对 mTextState == null 的检查。从字面上看,添加和删除的代码非常相似。一个简单的基于文本的模型可能会看着这个并感到困惑,或者只是简单地说“更改了条件”。
然而,真正的逻辑——即这一更改修复了错误的 原因——依赖于 mTextState 如何与代码中 未 更改的其他部分进行交互。如果不分析这些依赖关系 (即上下文) ,AI 模型本质上就是在瞎猜。
现有的方法通常会陷入两个陷阱:
- 上下文盲区: 它们只看变更的行。
- 噪声: 它们抓取最近的 5-10 行代码,希望它们是相关的。通常情况下,它们并不相关,反而引入了混淆模型的噪声。
COMMIT 背后的研究人员认为,我们需要一种方法来像外科手术一样精确地提取 仅 相关的上下文——即在程序上依赖于这些变更的代码行。
背景: 代码属性图的力量
在理解解决方案之前,我们需要介绍本文中使用的一个核心概念: 代码属性图 (Code Property Graph, CPG) 。
在计算机科学中,我们有不同的方式将代码表示为图:
- 抽象语法树 (AST) : 表示代码的层次结构 (嵌套在函数中的循环等) 。
- 控制流图 (CFG) : 表示语句执行的顺序。
- 程序依赖图 (PDG) : 表示数据流向 (A 行使用的变量是在 B 行定义的) 和控制依赖 (仅当 A 行中的
if语句为真时,B 行才执行) 。
代码属性图 (CPG) 将所有这些结合成一个巨大的、信息极其丰富的图。通过遍历 CPG,你可以回答复杂的问题,例如: “具体是哪一行代码定义了这个在变更行中使用的变量?”
这就是 COMMIT 模型的秘密武器。它不猜测哪些上下文是重要的;它通过计算得出。
数据: 介绍 CODEC
机器学习模型的好坏取决于其训练数据。研究人员意识到,现有的提交信息生成数据集是不够的。有些太小,有些充满噪声 (包含机器人生成的信息) ,而且至关重要的是,没有一个包含图分析所需的丰富上下文数据。
为了解决这个问题,他们构建了 CODEC (COntext and metaData Enhanced Code dataset,上下文和元数据增强的代码数据集) 。
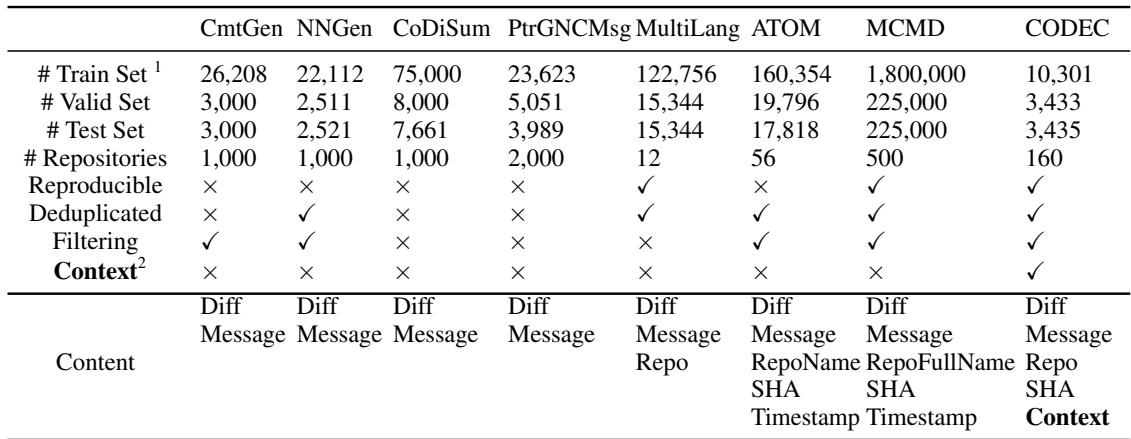
如表 1 所示,CODEC 不同于 NNGen 或 MCMD 等数据集。它不仅包含 Diff 和消息,还包含仓库名称、SHA,以及关键的 上下文 。
他们从 GitHub 上的顶级 Java 仓库收集数据,过滤掉巨大的变更 (超过 20 行) 和微小的信息 (少于 5 个单词) 以确保高质量。他们还使用了一个 Bi-LSTM 模型来过滤掉没有回答“为什么”或“是什么”的信息,确保训练数据由有意义的摘要组成。
核心方法: COMMIT
现在,让我们看看解决方案的架构。该模型被称为 COMMIT (Context-aware prOMpting based comMIt-message generaTion)。
工作流程涉及三个主要阶段:
- 图构建: 为变更前后的代码构建图。
- 上下文提取: 使用这些图来查找相关的依赖关系。
- 生成: 使用预训练模型 (CodeT5+) 和特定提示来编写信息。
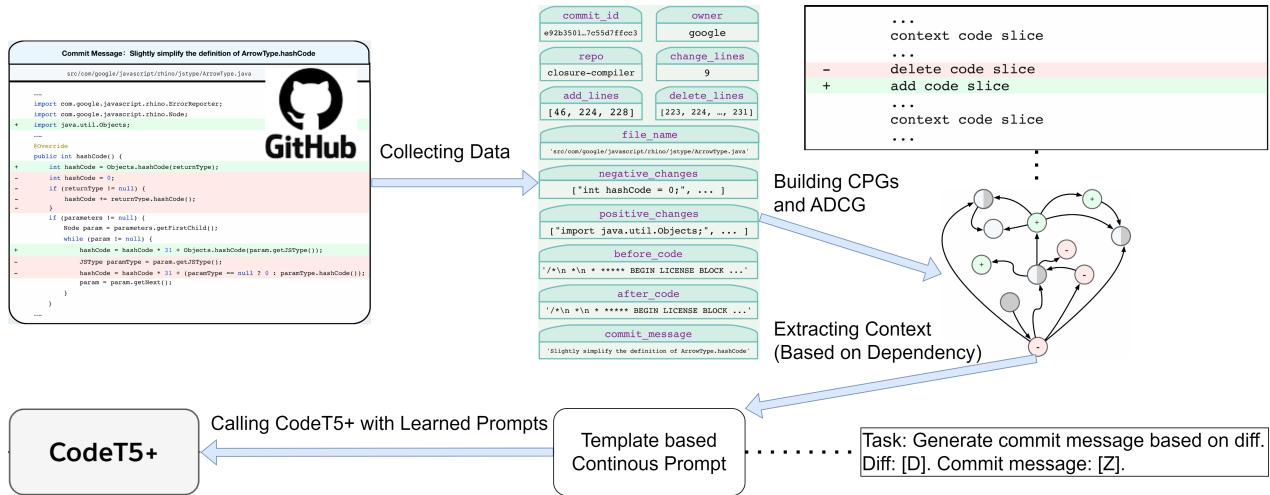
1. 构建增删上下文图 (ADCG)
这是论文中技术上最新颖的部分。当代码发生变更时,本质上你有两个版本的程序: “旧”版本 (行被删除的地方) 和“新”版本 (行被添加的地方) 。
研究人员使用一个名为 Joern 的工具为这两个版本构建 CPG。
- \(CPG_{delete}\) : 变更前文件的图。删除的节点标记为红色。
- \(CPG_{add}\) : 变更后文件的图。添加的节点标记为绿色。
然后,他们将这两个图合并成一个名为 增删上下文图 (Added-Deleted Context Graph, ADCG) 的超级图。
在 ADCG 中,未更改的节点 (代码行) 被合并。这个图现在包含了变更的历史。它允许系统追踪以下内容之间的关系:
- 被删除的行。
- 被添加的行。
- 与删除相关的上下文行。
- 与添加相关的上下文行。
2. 通过切片提取依赖
一旦构建了 ADCG,模型需要找到“恰到好处”的上下文——既不能太少,也不能太多。它通过 程序切片 (Program Slicing) 来实现这一点。
该算法查看变更的节点 (添加或删除) ,并追踪图中的边以找到连接的节点。它寻找两种特定类型的连接:
- 数据依赖 (Data Dependency) : “A 行定义了变量 X,而 B 行使用了变量 X。”
- 控制依赖 (Control Dependency) : “A 行是一个
if语句,而 B 行在该代码块内。”
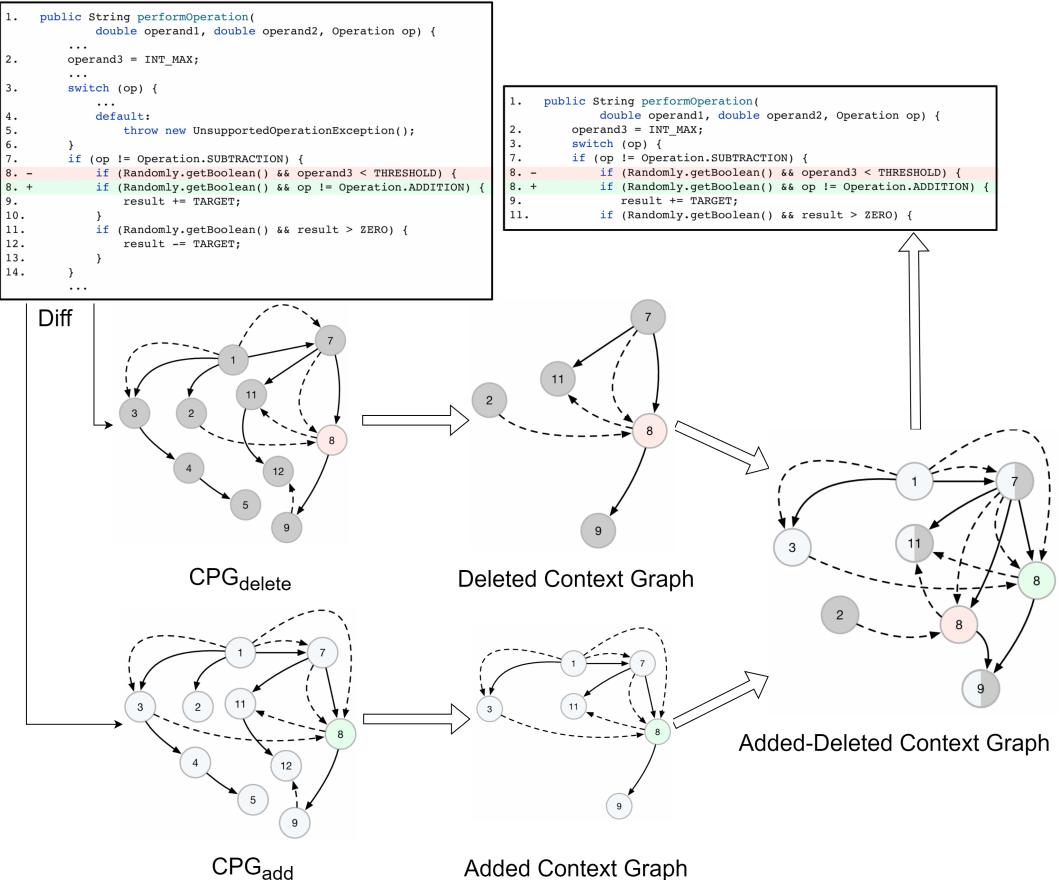
图 3 完美地展示了这一点。
- 红色节点 (-8): 被删除的行。
- 绿色节点 (+8): 被添加的行。
- 灰色节点: 上下文。
注意那些箭头。算法从变更处 (第 8 行) 回溯,发现第 7 行 (int lengthAfter) 和第 2 行 (CharSequence text) 是依赖项。这些行没有被更改,但不看它们你就无法理解第 8 行。
算法将此搜索限制在特定的 深度 (研究人员发现 3 跳的深度是最佳的) ,以防止提取整个文件。
3. 使用 CodeT5+ 进行上下文感知提示
现在系统拥有了 Diff 和数学上提取的 Context,它需要生成文本。
研究人员利用了 CodeT5+ , 这是一种在代码上预训练的最先进的编码器-解码器模型。他们没有简单地对其进行微调,而是采用了 提示微调 (Prompt Tuning) 。 他们设计了特定的模板来构建模型的输入结构。

如表 2 所示,他们尝试了不同的方式来要求模型进行总结。输入不仅仅是代码;它是一个包含任务描述和上下文增强 Diff 的结构化提示。
在数学上,他们将提示函数建模为:
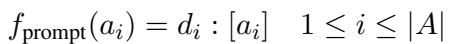
他们将任务描述、Diff 和目标信息槽连接起来:

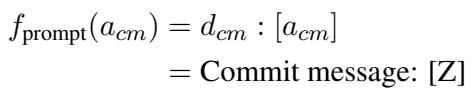
然后训练模型以最大化在给定输入 (\(X\)) 和提示 (\(f_{prompt}\)) 的情况下生成正确提交信息 (\(S\)) 的概率:
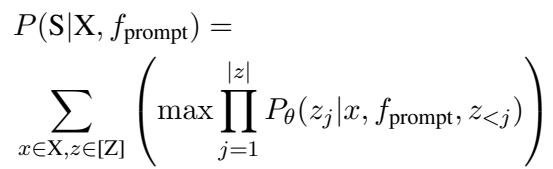
实验与结果
研究人员将 COMMIT 与其他 16 个模型进行了比较,范围从简单的信息检索系统到像 GPT-3.5 和 Code-Llama 这样的大型 LLM。
定量结果
结果是决定性的。COMMIT 在所有主要指标上都取得了最高分:
- BLEU-4: 衡量 n-gram 重叠 (精确度) 。
- METEOR: 比 BLEU 更符合人类判断。
- ROUGE-L: 衡量最长公共子序列 (召回率/结构) 。
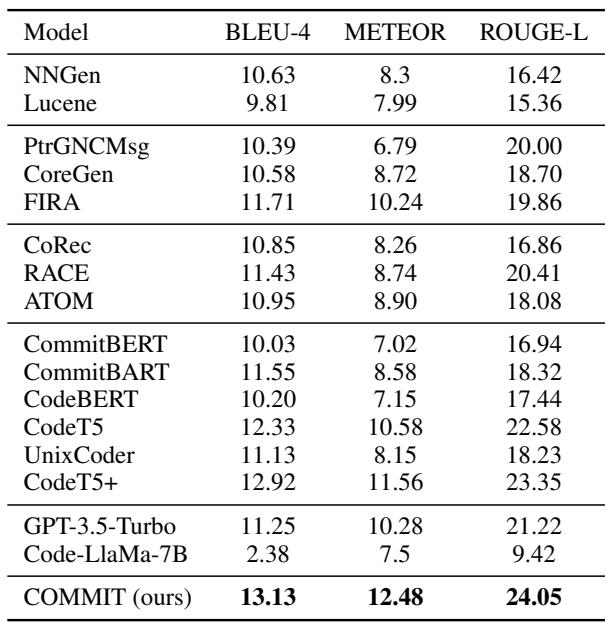
如表 3 所示, COMMIT (13.13 BLEU-4) 优于 CodeT5+ (12.92) , 并显著击败了 GPT-3.5 (11.25) 和 Code-Llama (2.38) 。
为什么 LLM 失败了? 值得注意的是 Code-Llama 的低分。研究人员发现 Code-Llama 倾向于过于啰嗦,生成解释代码的长段落,而不是提交信息所需的简洁的单句摘要。COMMIT 经过上下文感知提示的微调,学会了所需的特定风格。
CPG 的重要性
所有这些复杂的图构建值得吗?研究人员进行了一项消融实验,以比较不同的图类型。
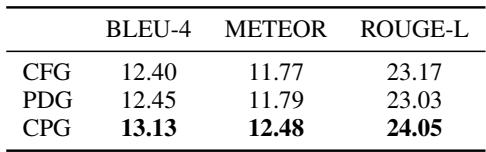
表 4 证实,与仅使用控制流图 (CFG) 或程序依赖图 (PDG) 相比, CPG 表示产生了更好的结果 (13.13 BLEU) 。结构信息和流信息的结合提供了最完整的图景。
人工评估
像 BLEU 这样的自动指标并不是质量的完美代表。一个句子可能单词重叠率低,但意思相同。为了解决这个问题,研究人员进行了人工评估。
他们要求参与者审查代码变更,并从不同模型生成的匿名输出列表中选择最佳的提交信息。
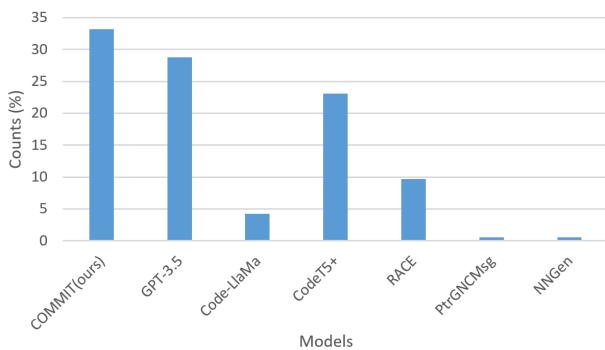
图 4 中的结果令人震惊。 COMMIT 在 33.2% 的案例中被首选 , 是所有模型中最高的。GPT-3.5 以约 28% 位居第二。这证实了该模型不仅仅是在刷指标;它正在生成开发人员实际上觉得有用的摘要。
案例研究: 看见差异
让我们看一个具体的输出示例,以此了解 为什么 COMMIT 效果更好。
在这个例子中,开发人员从名为 ValueTimestampTimeZone 的类中删除了 add 和 subtract 方法,因为不支持操作这些值。

- Reference (人工参考): “Remove unnecessary methods from ValueTimestampTimeZone” (从 ValueTimestampTimeZone 移除不必要的方法)
- COMMIT (我们的): “Remove unnecessary methods from ValueTimestampTimeZone” (完全匹配)
- NNGen: “remove redundant code… comparing a==b” (幻觉——完全不相关)。
- CodeT5: “Remove incorrect add/subtract…” (接近,但暗示它们是错误的,而不仅仅是不必要的)。
- GPT-3.5: “Remove unsupported operations…” (不错,但稍微啰嗦一点)。
基线模型难以把握 意图。它们看到代码删除就猜测是“修复”或“冗余”。COMMIT 看到了依赖关系和上下文中的特定异常类型,确切地理解了发生了什么。
结论与启示
COMMIT 论文为 AI 编码助手的时代展示了一个至关重要的教训: 模型大小并不是一切;上下文才是关键。
虽然像 GPT-4 和 Llama 这样的大型 LLM 是令人印象深刻的通才,但像生成提交信息这样的专业任务需要外科手术般的精准度。通过不仅将代码视为文本,而且将其视为逻辑依赖图,研究人员能够准确地向模型提供它所需的信息——不多也不少。
主要收获:
- 代码是一个图: 将代码视为扁平的文本序列忽略了其底层逻辑。CPG 解锁了这种逻辑。
- 上下文感知: “增删上下文图”允许模型理解原来的代码和替换代码之间的关系。
- 效率: 一个较小的、提示得当的模型 (CodeT5+) 配合 正确 的数据,可以胜过巨大的通用模型 (GPT-3.5) 。
这种方法为更智能的开发工具铺平了道路,这些工具不仅能自动补全文本,还能真正理解它们帮助构建的软件的结构和流程。未来的工作旨在将其扩展到 Python 和 C++ 等其他语言,有可能让“周五下午的提交”成为过去式。